说一下MyBatis执行流程?
MyBatis是一款优秀的基于Java的持久层框架,它内部封装了JDBC,使开发者只需要关注SQL语句本身,而不需要花费精力去处理加载驱动、创建连接等的过程,MyBatis的执行流程如下:
- 加载配置文件:MyBatis的执行流程从加载配置文件开始。通常,MyBatis的配置文件是一个XML文件,其中包含了了数据源配置,SQL映射配置、连接池配置
- 构架SqlSessionFactory:在配置文件加载后,MyBatis使用配置信息来构建SqlSessionFactory,这是MyBatis的核心工厂类。SqlSessionFactory是线程安全的,它用于创建SqlSession对象
- 创建SqlSession:应用程序通过SqlSessionFactory床渐渐SqlSession对象。SqlSession代表依次数据库会话,它提供了执行SQL操作的方法。通常情况下,每个线程都应该由自己的SqlSession对象
- 执行SQL查询:在SqlSession种,开发人员可以执行SQL查询你,这可以通过两种方式实现:
- 使用注解加SQL:Mybatis提供了注解加执行SQL的实现方式,MyBatis会为Mapper接口生成实现类的代理对象,实际执行SQL查询
- 使用XML映射文件:开发人员可以在XML映射文件中定义SQL查询语句和映射关系。然后,通过SqlSession执行这些SQL擦汗寻,将结果有映射到Java对象上
- SQL解析和执行:MyBatis会解析SQL查询,执行查询操作,并获取查询结果
- 结果映射:MyBatis使用配置的结果映射规则,将查询结果映射到Java对象上。这包括将数据库列映射到Java对象的属性上,并处理关联关系
- 返回结果:查询结果被返回给应用程序,开发热恩于那可以对结果进行进一步处理、展示或之旧话
- 关闭SqlSession:完成数据库操作后,关闭SqlSession释放资源
${}和#{}有什么区别?什么情况下一定要使用${}?
${}和#{}都是MyBatis种用来代替参数的特殊标识,如下:
但是二者的区别二还是很大的,主要区别如下:
- 含义不同:${}是直接替换(运行时已经替换成具体的执行SQL了),而#{}是预处理(运行时只设置了占位符"?",之后通过声明器(statement)来替换占位符)
- 使用场景不同:普通参数使用#{},如果传递的是SQL命令(如desc还是asc)或者SQL关键字的时候,需要使用${},但是使用之前一定要做好安全验证
- 安全性不同:使用${}存在安全性问题,#{}不存在安全性问题
也就是说,为了防止安全问题,所以大部分场景都要使用 #{} 替换参数,但是如果传递的是 SQL 关键字,例如order by xxx asc/desc 时(传递 asc 后 desc),一定要使用 $,因为它需要在执行时就被替换成关键字,而不能使用占位符替代(占位符不用应用于 SQL 关键字,否则会报错)。
在传递 SOL 关键字时,一定要使用 ${},但使用前,一定要进行过滤和安全检査,以防止 SQL 注入。
什么是SQL注入?如何防止SQL注入?
SQL注入就是指应用程序对用户输入的数据的合法性没有判断或过滤不严,攻击者可以在应用程序中事先定义好查询语句的结尾上添加额外的SQL语句,在管理员不知情的情况下实现非法操作,依次来实现欺骗数据库服务器执行非授权的热议操作,从而进一步得到相应的数据信息
也就是说所谓的 SQL 注入指的是,使用某个特殊的 SQL 语句,利用 SQL 的执行特性,绕过 SQL 的安全检查,查询到本不该查询到的结果
如以下代码:
<select id="doLogin" resultType="com.example.demo.model.User">select *from userinfo where username='${name}' and password='${pwd}
</select>sql注入以下代码 :"'or 1='1",如下图所示:
从上述结果可以看出,以上程序在应用程序不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的敏感数据
如何防止SQL注入
预编译语句与参数化查询:使用 PreparedStatement 可以有效防止 SQL 注入,因为它允许你先定义 SQL 语句的结构,然后将变量作为参数传入,数据库驱动程序会自动处理这些参数的安全性,确保它们不会干扰 SQL 语句的结构,如下代码所示:
String sql ="SELECT * FROM users WHERE username = ? AND password = ?";
PreparedStatement pstmt= connection.prepareStatement(sql);
pstmt.setString(1,userInputUsername);
pstmt.setstring(2,userInputPassword);
ResultSet rs=pstmt.executeQuery();输入验证和过滤:对用户输入的信息进行验证和过滤,确保其符合预期的类型和格式
说一下MyBaits中的二级缓存?
MyBatis二级缓存是用于提高MyBatis查询数据库的性能和减少访问数据库的机制。MyBatis的二级缓存总共由两个缓存机制:
- 一级缓存:SqlSession级别的,MyBatis自带的缓存功能。并且无法关闭,因此当有两个SqlSession访问相同的SQL时,一级缓存也不会生效,也需要查询两次数据库。在一个service调用两个相同的mapper方法的时候,依然是查询两次,因为他会创建那两个SqlSession进行查询(为了提高查询性能)
- 二级缓存:Mapper级别的,只要是同一个Mapper,无论是使用多少个SqlSession来操作,数据都是共享的。也就是说,一个sessionFactory下的多个session之间是共享缓存的,它的作用范围更大,生命周期更长,可以减少数据库的查询次数,提高系统性能。但是MyBatis二级缓存时默认关闭的需要手动开启
二级缓存默认是不开启的,手动开启MyBatis步骤如下:
- 在mapper.xml中添加<cache/>标签
- 在需要缓存的标签上添加usrCache="true"(新版本可以忽略,为了兼顾老版本,保留)
完整示例如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIc "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.demo.mapper.StudentMapper"><cache/><select id="getStudentCount" resultType="Integer" usecache="true">select count(*)from student</select>
</mapper>编写单元测试代码:
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest; @SpringBootTest
public class StudentMapperTest { @Autowired private StudentMapper studentMapper; @Test void testGetStudentCount() { int count = studentMapper.getStudentCount(); System.out.println("查询结果:" + count); int count2 = studentMapper.getStudentCount(); System.out.println("查询结果2:" + count2); }
}运行结果: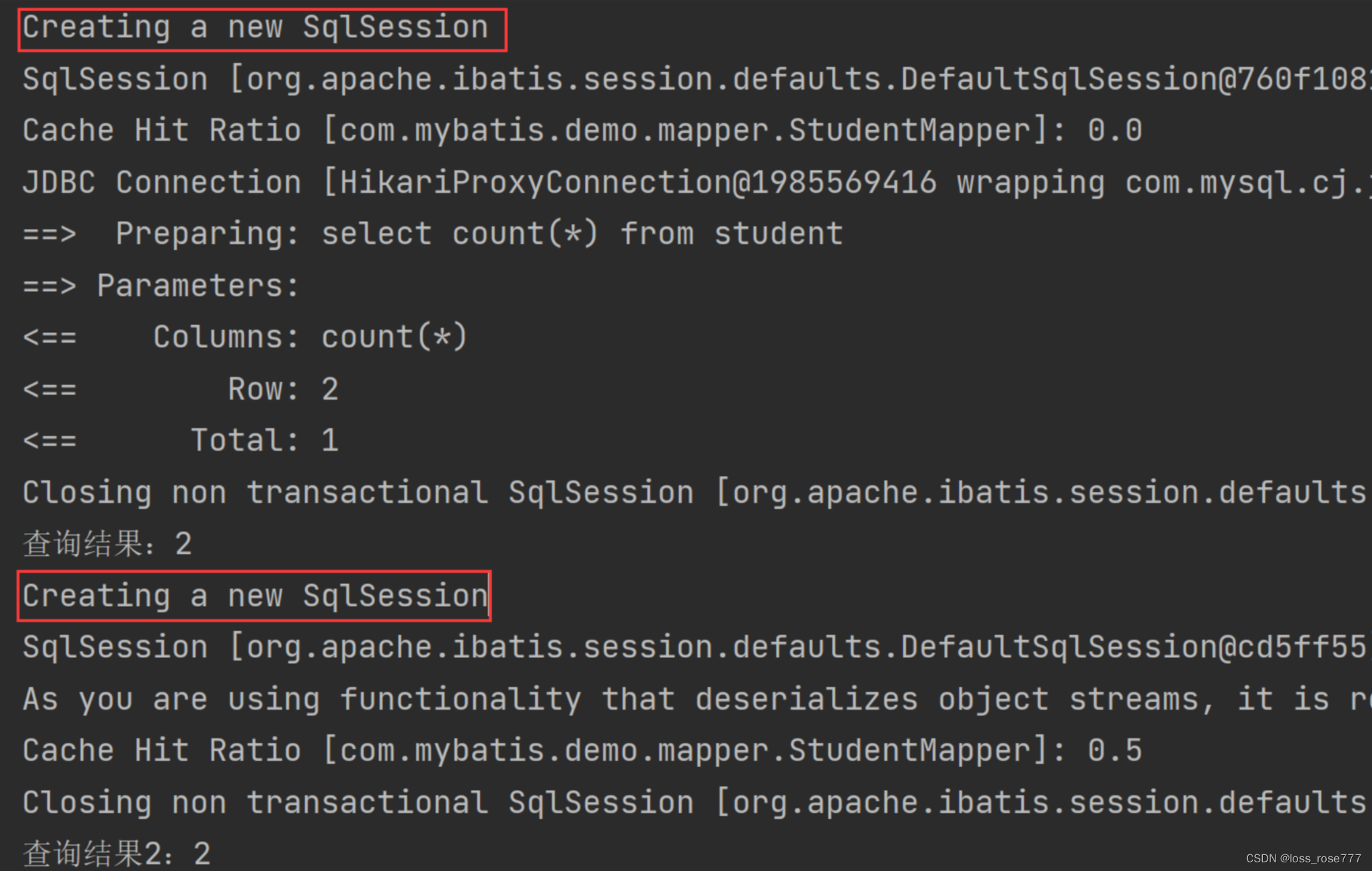
从以上结果可以看出,两次查询虽然使用了不同的 SqlSession,但第二次查询使用了缓存,并未查询数据库
ORM项目中类属性名和数据库字段名不一致会导致什么问题?它的解决方案有哪些?
在ORM项目中,如果类的属性名称和数据库字段名不一致会场导致插入、修改时设置的这个不一致字段为null,查询的时候即使数据库有数据,但是查询的结果也是为null。它的常见解决方法如下:
- 更改程序中属性名或数据库的字段名,使其一致
- 使用结果映射,使用<resultMap>映射对应的字段
-
<!-- 在 XML 配置文件中定义 resultMap --> <resultMap id="userResultMap" type="com.example.User"><!-- 指定 id 字段映射 --><id property="id" column="id"/><!-- 指定 username 字段映射 --><result property="username" column="username"/><!-- 指定 email 字段映射 --><result property="email" column="email"/> </resultMap> //在SQL映射文件中,可以使用这个<resultMap>来进行查询结果的映射: <select id="selectUser" resultMap="userResultMap">SELECT id, username, emailFROM userWHERE id = #{id} </select>
-
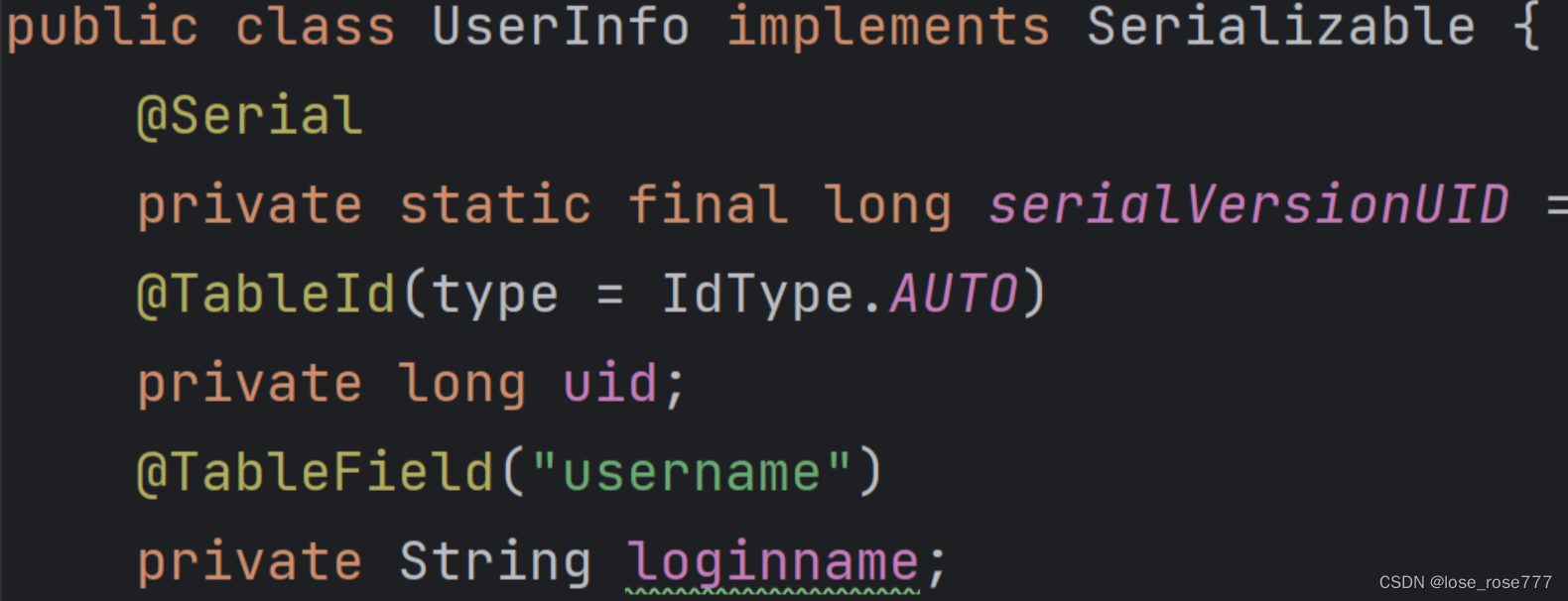
- 使用MyBatis Plus框架中的@TableFild注解映射二者的字段,如下图:
-
- 如果是查询操作 ,可以使用as重命名字段名,这样查询也就不会为null了
MyBatis中如何实现分页?它有几种实现分页的方式?
MyBatis中实现分页主要是一下两种实现方式:
- 物理分页:物理上是使用SQL擦哈寻语句,在数据库引擎层面实现的,如MySQL的LIMIT语法进行分页
- 逻辑分页:逻辑分页时在应用程序层面进行的分页,通常是先查询出所有符合条件的数据,然后在内存中对数据进行分页操作
物理分页
使用limit实现分页
物理分页是可以直接在XML中拼加SQL进行分页:
<select id="getUserList"resultType="User">select *from userlimit #{limit} offset #{offset}
</select>使用PageHelper插件实现分页
实现代码如下:
PageHelper.startPage(1,10);
//1 表示要查询的页码为第一页,10 表示每页显示的记录数为 10 条
List<User>list=userMapper.selectIf(1);PageHelper实现原理分析
PageHelper底层是使用MyBatis的拦截器(Interceptor)机制,在MyBatis进行查询时,拦截并对SQL语句进行动态修改(添加limit等分页查询操作),之后查询数据库、并对查询结果进行包装,包装成分页对象(如包含数据列表、总记录数、总页数等信息的分页对象),最后再将这个分页对象返回给客户端
逻辑分页
MyBatis自带的RowBounds进行分页就是逻辑分页,它的一次性查询很多数据,然后在数据中在进行检索,实现代码如下:
RowBounds rowBounds = new RowBounds(offset, limit);
List<User> users = sqlSession.selectList("getUserList", null, rowBounds);
其中 offset 为起始行偏移量,limit 是每页数据量,虽然设置了这两个值,但在使用 RowBounds 时,它会一次性查询多条数据,然后再在内存中进行 offset 和 limit 的筛选,最后在返回符合结果的数据
MyBaits二级缓存有几种淘汰策略?如何设置缓存淘汰策略?
- LRU-最近最少使用:移除最长时间不被使用的对象
- FIFO-先进先出:按照对象进入缓存的顺序来移除对象
- SOFT-软引用:基于垃圾回收器状态和软引用规则移除对象
- WEAK-弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象
默认的缓存淘汰策略时LRU
可以通过eviction属性来设置淘汰策略,如下:
<cache eviction="FIFO"/>MyBatisPlus如何实现分页功能?它的底层是如何实现的?
MyBatis-Plus 是 MyBatis 的增强工具,在 MyBatis 的基础上提供了更多方便的功能,包括分页功能。在 MyBatis-Plus 中,实现分页功能非常简单,主要使用 Page 类进行分页操作。
以下是使用 MyBatis-Plus 实现分页功能的基本步骤:
- 在 Mapper 接口中定义查询方法,并接收一个
Page类型的参数,用于分页
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;public interface UserMapper extends BaseMapper<User> {Page<User> selectUserPage(Page<User> page);
}
- 在 Mapper XML 文件中编写对应的 SQL 查询语句
<select id="selectUserPage" resultType="com.example.User">select * from user
</select>
- 在 Service 层调用 Mapper 中定义的查询方法,并传入一个
Page对象作为参数
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;@Service
public class UserServiceImpl implements UserService {@Autowiredprivate UserMapper userMapper;@Overridepublic Page<User> selectUserPage(int pageNum, int pageSize) {Page<User> page = new Page<>(pageNum, pageSize);return userMapper.selectUserPage(page);}
}
这样就完成了分页功能的实现。MyBatis-Plus会自动将查询结果封装到Page对象中,其中包含了分页的相关信息,比如当前页码、每页大小、总记录数等
MyBatis-Plus底层是通过拦截器实现分页的,它会在执行SQL语句前进行拦截,并根据传入的分页参数自动生成对应的分页SQL语句,然后执行分页查询。最后将查询结果封装到Page对象中返回给调用方。这样,开发人员不需要手动编写分页的SQL语句,简化了开发流程
MyBatis中使用了哪些设计模式?举例说明一下
- 工厂模式:工厂模式是Java中最常见的设计模式之一。工厂模式就是它提供一个工厂,当有客户需要调用的时候,只调用这个工厂类就可以得到自己想要的结果,从而无需关注某类的具体实现过程。工厂模式在MyBatis中典型的代表就是SqlSessionFactory。SqlSession是MyBatis中的重要而Java接口,可以通过该接口来执行SQL语句,获取映射器示例和管理事务,而SqlSessionFactory正在用来产生SqlSession对象的,所以它在MyBatis中是比较核心的接口
- 建造者模式:建造者模式就是将一个复杂对象的构建与它的表示分离,使得的同样的构建过程可以创建不同的表示。也就是说建造者可以通过多个模块一步一步实现对象的构建,相同的构建过程可以创建不同产品。建造者模式在MyBatis中典型代表就是SqlSessionFactoryBuilder。普通的对象都是通过new关键字直接创建的,但是如果创建对象需要构造参数很多,且不能保证每个参数都是正确的或者不能一次性得到构建所需的所有参数,那么就需要将构建逻辑从对象本身抽离出来,让对象只关注功能,把构建交给构建类,这样就可以简化对象的构建,也可以达到分布构建对象的目的
- 单例模式:单例模式是Java中最简单的设计模式之一,此模式保证某个类在运行期间,只有一个实例对外提供服务,而这类被称为单例类。单例模式在MyBatis中典型的代表就是ErrorContext。ErrorContext是线程级别的单例,每一个线程有一个此对象的单例,用于记录该现成的执行环境的错误信息
- 代理模式:代理模式是指给某个对象提供一个代理对象,并由代理对象控制原对象的调用。代理模式在MyBatis中典型的代表就是MapperProxyFactory。MapperProxyFactory的newInstance()方法就是生成一个具体的代理类来实现某个功能