文章目录
- 引言:什么是新视角合成任务
- 定义
- 一般步骤
- NeRF的做法
- NeRF的三维重建
- NeRF的渲染
- 3DGS的三维重建
- 从一组图片估计点云
- 高斯点云模型
- 球谐函数
- 参数优化
- 损失函数和协方差矩阵的优化
- 高斯点的数量控制(Adaptive Density Control)
- 新的问题
- 3DGS的渲染:快速可微光栅化
- 3DGS的限制
引言:什么是新视角合成任务
定义
新视角合成(Novel View Synthesis),属于计算机视觉领域,该任务要求:
- 输入源图像(Source)
- 输入源姿态(Source Pose)
- 输入目标姿态(Target Pose)
最终获得:
- 目标姿态对应的的图片(Target)
无论是2020ECCV的best paper,NeRF,还是2023年爆火的3DGS,都是为了完成NVS任务。
一般步骤
-
三维重建: 从已有视角的图像中推断出场景的三维几何信息,包括物体的形状和位置。
-
渲染: 利用三维重建的信息,通过渲染技术生成新视角下的图像,考虑光照和纹理等因素。
这两个步骤是新视角合成的基本框架,涵盖了几何重建和图像合成的关键概念。在实践中,可以根据具体应用的需求进一步细化这些步骤,例如加入光照模型、深度合成等处理,以提高合成图像的质量和真实感。
NeRF的做法
让我们来以NeRF为例子,更加深刻地了解一个新视角合成任务的步骤。当然,笔者不会写的特别详细,否则这篇文章就变成NeRF的介绍了。如果对NeRF特别感兴趣,可以阅读笔者的另一篇文章。

NeRF的三维重建
NeRF成功最大因素就在于它借用了深度学习的东西去进行三维重建。简单地说,NeRF利用多层感知机(MLP)创建了一个函数。

这个函数接受一个向量 ( x , y , z , θ , ϕ ) (x,y,z,\theta,\phi ) (x,y,z,θ,ϕ)作为输入,其中, ( x , y , z ) (x,y,z) (x,y,z)表示这个点在空间中的坐标, ( θ , ϕ ) (\theta,\phi ) (θ,ϕ)表示观察角度(俯仰角pitch和偏航角yaw)。它的输出是 ( R G B , σ ) (RGB,\sigma ) (RGB,σ)。RGB很好理解,就是这个点的颜色。而 σ \sigma σ,是一个被称为体素密度的计算量。这两个输出的量是为了后面的体渲染做准备。
有了这个函数之后,对于三维空间中指定坐标的任何一点,都可以知道它的 ( R G B , σ ) (RGB,\sigma ) (RGB,σ)。而且,由于使用的是MLP来表示这个函数,那么这个函数就是连续的、可微分的,也就可以用反向传播去优化。
NeRF的渲染

NeRF的渲染方式采用经典的体渲染。具体的算法本文不再赘述。总而言之,体渲染需要三个参数作为输入:
- 目标位姿
- 空间中每个位置的体素密度
- 空间中每个位置的RGB颜色值
然后输出:
- 目标位姿对应的图片
当然,这种方法也是可微的。
这种体渲染的方式需要以像素为单位生成光线,然后在光线上对空间内的点进行采样,因此,每个像素点在渲染时都需要计算对应的光线,成本相当高昂,在渲染高分辨率图像时帧率非常低下,无法做到实时渲染。
同样基于这个原因,NeRF优化参数时,在源图像与生成图像上只会选择一些像素点,去计算RGB颜色值的损失,进行反向传播,优化MLP的参数,而不是将所有像素点都拿来计算损失。
3DGS的三维重建
从一组图片估计点云
3DGS使用SFM(Structure from Motion)方法完成了从一组图片估计点云的步骤,甚至不需要给出相机的位姿就可以获得点云。这是一种非常成熟的方法,由Schönberger和Frahm等人于2016年提出,已经封装在COLMAP库中,在3DGS开源的代码中可以直接调用。


此方法的具体内容不是本文要探讨的,可阅读原文献。
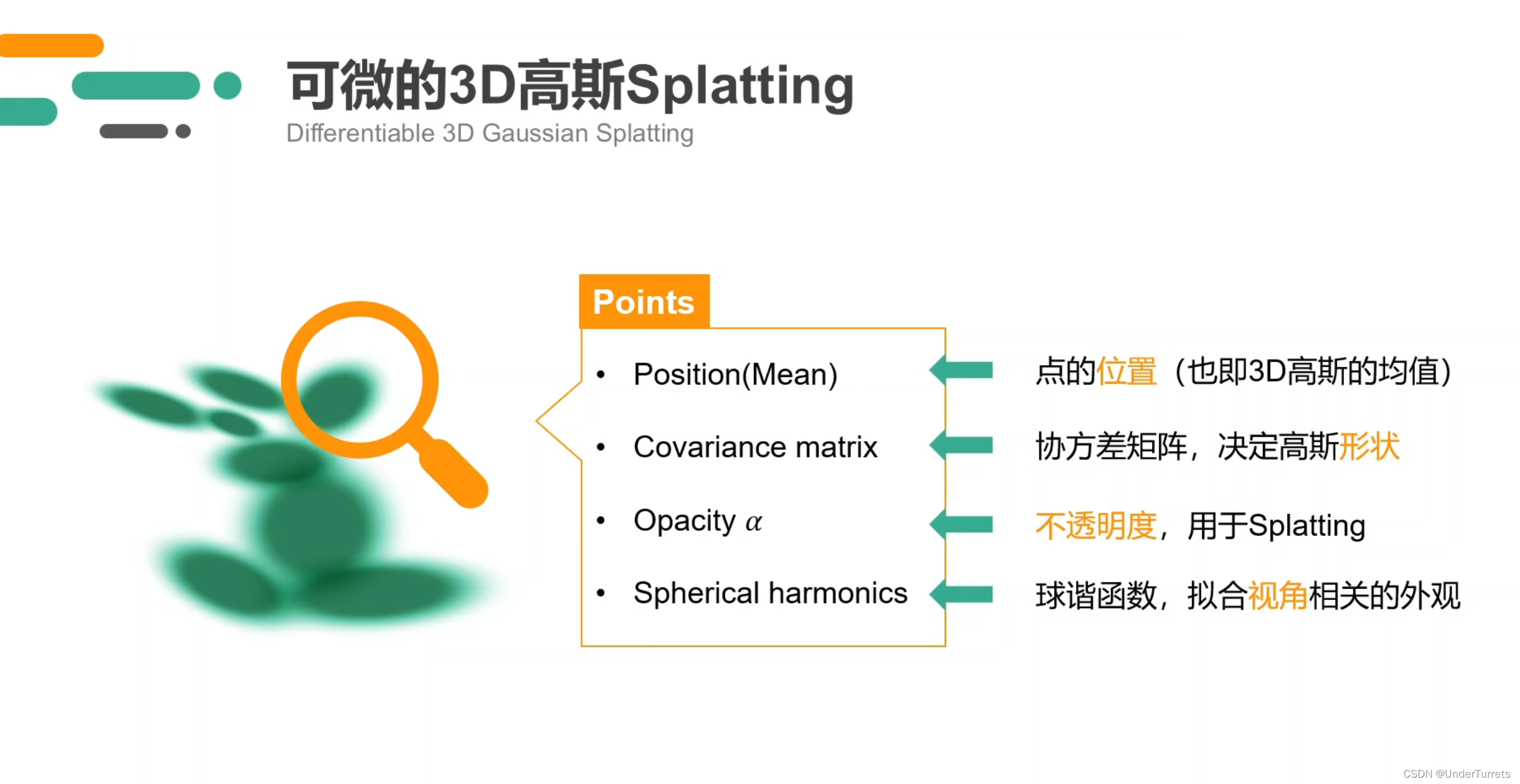
高斯点云模型
3DGS从获得的稀疏点云开始,创建并且优化高斯点云。每个高斯点包含以下几个用来渲染的重要属性:
- 点的坐标,Position,即3D高斯函数的均值(Mean)
- 协方差矩阵,Covariance matrix,决定这个高斯点的形状
- 不透明度,Opacity α \alpha α,在渲染时用到
- 球谐函数,Spherical harmonics,在3DGS中表示这个高斯点在任意视角下的颜色
球谐函数
球谐函数(Spherical Harmonics, SH)是一组定义在球面上的特殊函数,通常用来表示球面上的函数。球谐函数在图形学、计算机图形学和计算机图像等领域中广泛应用。在3DGS中,球谐函数用于近似光照和颜色分布。
虽然球谐函数是定义在球面上,但是这个函数的输入并不是坐标 ( x , y , z ) (x,y,z) (x,y,z),而是视角 ( θ , ϕ ) (\theta,\phi ) (θ,ϕ),它的输出是RGB颜色值。
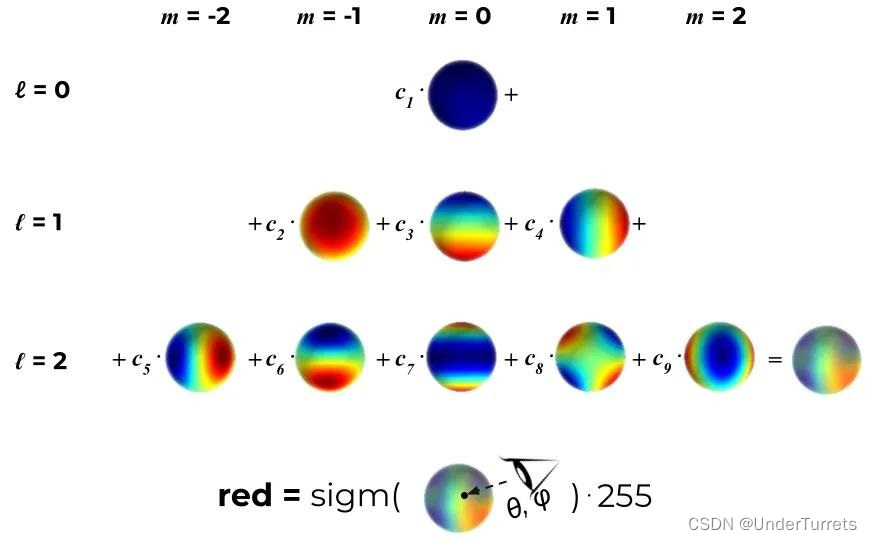
只要给定了欲生成图片的目标位姿之后,就可以知道这个点对应的视角 ( θ , ϕ ) (\theta,\phi ) (θ,ϕ),从而根据这个函数计算这个点在图片上应该呈现出的颜色。因此,球谐函数的参数也是优化的目标之一。
参数优化

- 使用所有的高斯点,使用源图像的位姿,渲染出图像
- 根据源图像和渲染图像,计算损失,并反向传播进行优化。优化的对象有:
- 协方差矩阵,Covariance matrix
- 不透明度,Opacity α \alpha α
- 球谐函数,Spherical harmonics
- 对高斯点的数量进行控制,即进行克隆、分裂或者删除
损失函数和协方差矩阵的优化
TODO.
高斯点的数量控制(Adaptive Density Control)
-
删除:在优化预热之后,每一百次迭代,就会删除几乎透明的高斯点,即不透明度 α \alpha α小于阈值 ϵ α \epsilon_\alpha ϵα的高斯。 ϵ α \epsilon_\alpha ϵα是个超参数,经验上设置为0.0002。
-
克隆和分裂
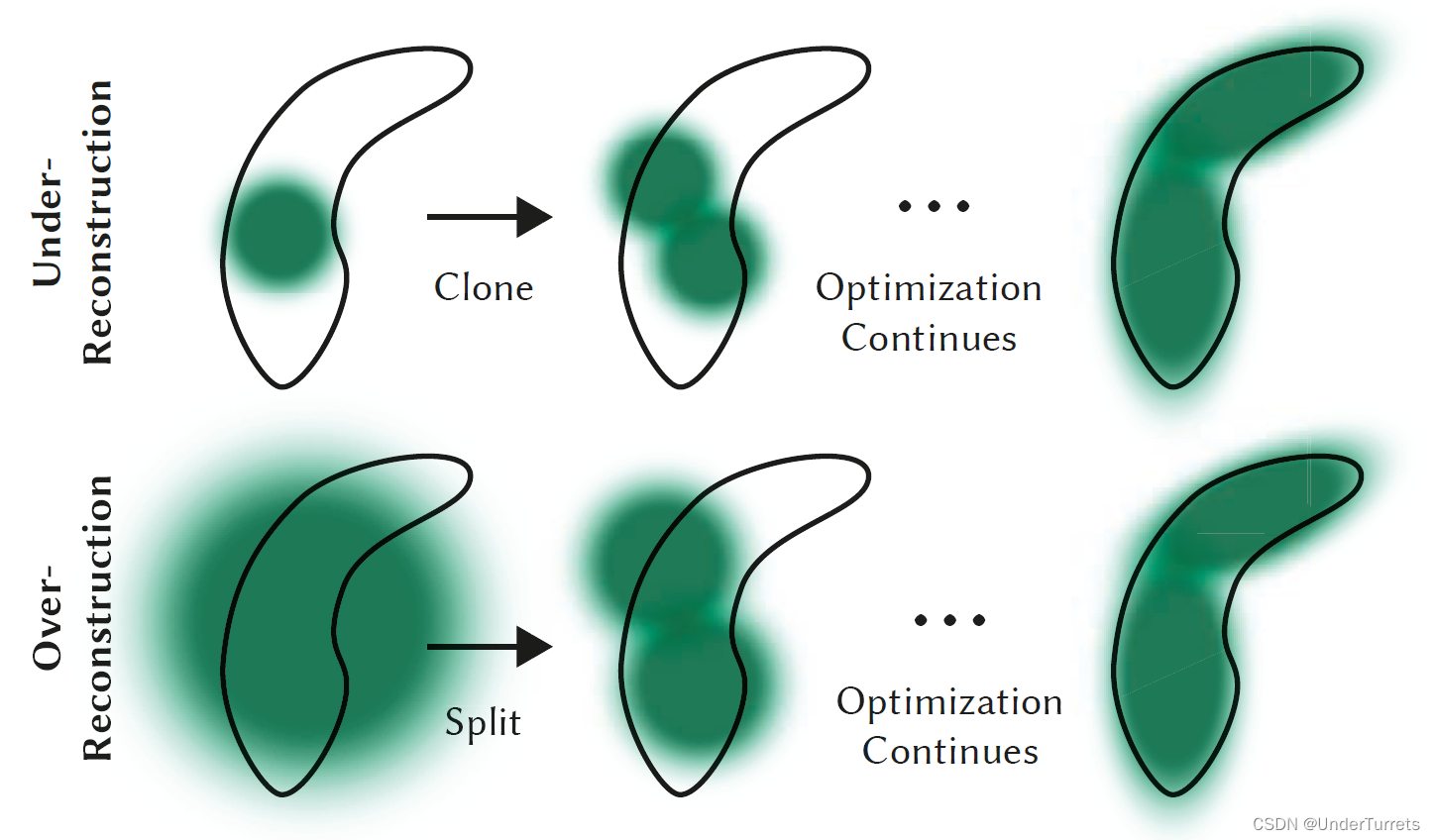
-
对于重建不足的高斯点,克隆一个相同大小的副本,并且沿着位置梯度方向移动。
-
对于过度重建的高斯点,对它进行分裂,分裂时还需要确定比例,经验上以超参数 ϕ = 1.6 \phi=1.6 ϕ=1.6作为这个比例。
新的问题
论文中,作者提出分裂高斯点的方法可能会导致密度的不合理增加。
In the first case we detect and treat the need for increasing both the total volume of the system and the number of Gaussians, while in the second case we conserve total volume but increase the number of Gaussians. Similar to other volumetric representations, our optimization can get stuck with floaters close to the input cameras; in our case this may result in an unjustified increase in the Gaussian density.
于是,作者设置了以下策略:
- 每迭代N=3000次,将所有高斯点的透明度 α \alpha α修改为接近0的一个值。在优化时, α \alpha α会在需要时增加。同时,先前的
阈值删除策略也可以很好地剔除几乎透明的高斯点。这里的N同样是个超参数。
3DGS的渲染:快速可微光栅化
笔者主要参考了此篇综述。
NeRF通过体渲染去生成新的图像,这要求为每个像素都采样很多空间点。这种方法在高分辨率的图像合成中计算成本非常高昂,难以实现实时渲染速度。
与之形成鲜明对比的是,3DGS首先将空间中的3D高斯投影到基于像素的图像平面上,这个过程被称为泼溅(splatting)。随后,3DGS对这些高斯进行排序并计算每个像素的值。
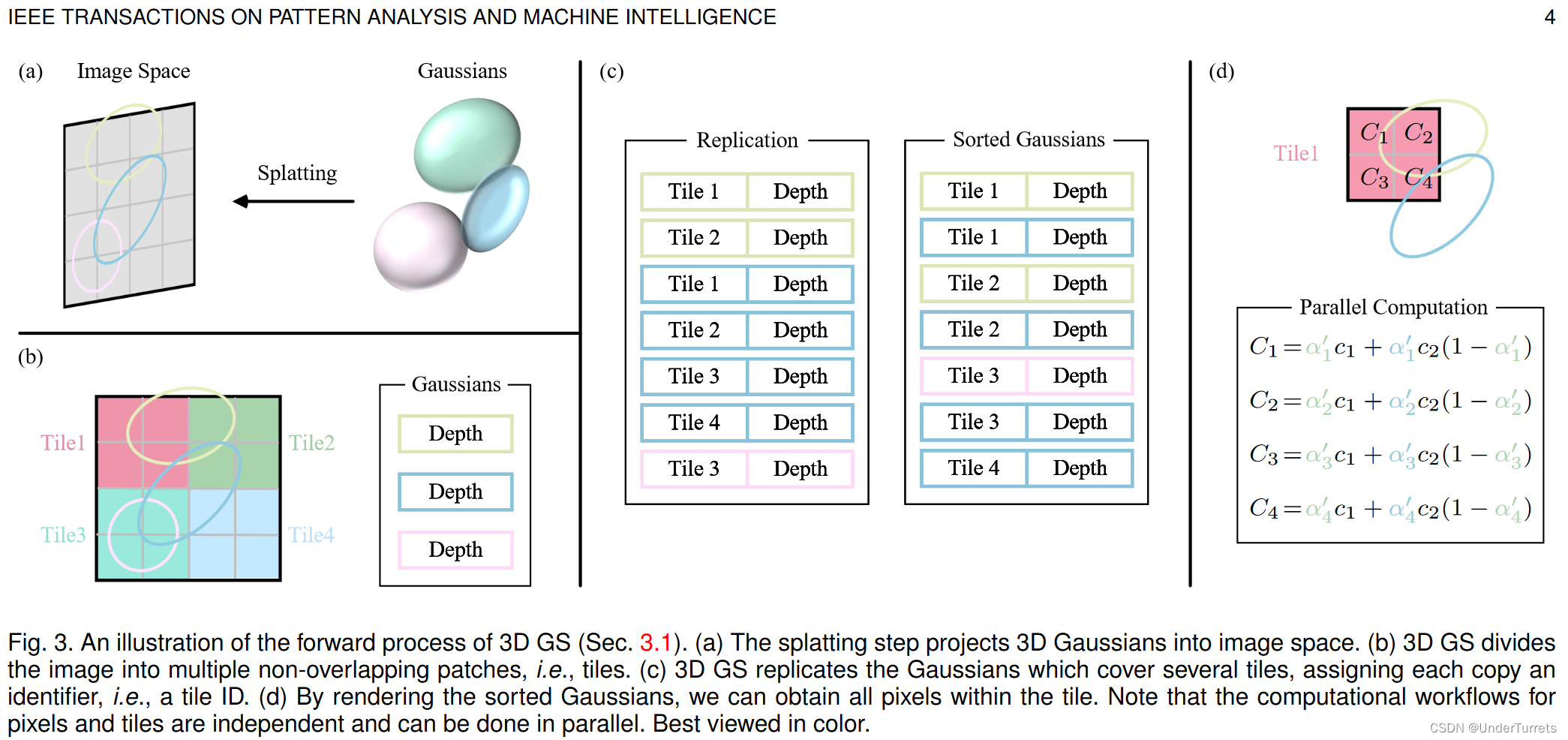
- (a)泼溅步骤将 3D 高斯投射到图像空间。
- (b)3D高斯将图像划分为多个不重叠的块(tiles)。
- (c)3DGS复制覆盖多个块的高斯,为每个副本分配一个标识符 ID。
- (d)通过渲染有序高斯,我们可以获得所有像素的值。渲染过程相互独立。
3DGS的渲染分为以下几步:
-
视锥剔除:给定指定的相机姿势,此步骤确定哪些高斯点位于相机的视锥体之外。这样做可以确保在后续计算中不涉及给定视图之外的高斯点,从而节省计算资源。对应代码。
-
泼溅(splatting)。在这一步骤中,高斯点被投影到2D图像空间中进行渲染,如图(a)所示。
给定视图变换 W \boldsymbol{W} W和3D协方差矩阵 Σ \Sigma Σ ,那么投影的2D协方差矩阵 Σ ′ \Sigma^{\prime} Σ′的计算公式如下:
Σ ′ = J W Σ W ⊤ J ⊤ \Sigma^{\prime}=\boldsymbol{J} \boldsymbol{W} \Sigma \boldsymbol{W}^{\top} \boldsymbol{J}^{\top} Σ′=JWΣW⊤J⊤
其中, J \boldsymbol{J} J是射影变换的仿射近似的雅可比矩阵。对应代码。 -
以像素为单位进行渲染。在深入讨论使用多种技术来提升并行计算的最终版本的3D GS之前,我们首先阐述其更简单的形式,以提供对其工作机制的洞察。给定像素的位置 x x x,可以通过视图变换 W \boldsymbol{W} W计算出它与所有重叠高斯的距离,即这些高斯的深度,形成一个排序的高斯列表 N \mathcal{N} N(对应代码)。然后,采用alpha合成(对应代码)来计算这个像素的最终颜色,对应公式如下:
C = ∑ i ∈ N c i α i ′ ∏ j = 1 i − 1 ( 1 − α j ′ ) C=\sum_{i\in\mathcal{N}}c_i \alpha_i^{\prime}\prod_{j=1}^{i-1}\left(1-\alpha_j^{\prime}\right) C=i∈N∑ciαi′j=1∏i−1(1−αj′)
其中, c i c_i ci是球谐函数输出的颜色,最终的不透明度 α i ′ \alpha_i^{\prime} αi′是学习到的不透明度 α i \alpha_i αi和高斯分布的乘积结果(对应代码),对应计算公式如下:
α i ′ = α i × exp ( − 1 2 ( x ′ − μ i ′ ) ⊤ Σ i ′ − 1 ( x ′ − μ i ′ ) ) \alpha_i^{\prime}=\alpha_i\times\exp\left(-\frac12(x^{\prime}-\boldsymbol{\mu}_i^{\prime})^{\top}\boldsymbol{\Sigma}_i^{\prime{-1}}(\boldsymbol{x}^{\prime}-\boldsymbol{\mu}_i^{\prime})\right) αi′=αi×exp(−21(x′−μi′)⊤Σi′−1(x′−μi′))
其中, x ′ x^{\prime} x′和 μ i ′ \boldsymbol{\mu}_i^{\prime} μi′是投影空间中的坐标。
值得担忧的是,与NeRFs相比,上述的渲染过程可能更慢,因为生成所需的有序列表难以并行化。实际上,这种担忧是合理的;当使用这种简单的逐像素方法时,渲染速度可能会受到显著影响。为了实现实时渲染,3DGS做出了几个妥协,以适应并行计算。 -
Tiles(图像块)。为了避免为每个像素计算有序列表的计算成本,3DGS将精度从像素级别转移到块级别细节,如(b)所示。3DGS最初将图像划分为多个不重叠的图像块,这些图像块在原始论文中被称为tiles。每个块包含16x16像素。3DGS进一步确定哪些图像块与这些投影的高斯(椭圆)相交。考虑到一个投影的高斯可能覆盖多个块,一种合理的方法是复制高斯,为每个副本分配一个标识符(即块ID),如(c)所示。 -
并行化渲染。复制后,3DGS会将各自的块ID与每个高斯视图变换得到的深度值结合起来。这样就得到了一个未排序的字节列表,其中高位代表块ID,低位表示深度。这样,排序后的列表就可以直接用于渲染。(c)(d)提供了该概念的直观演示。值得强调的是,每个块和像素的渲染都是独立进行的,因此这一过程非常适合并行计算。另外一个好处是,每个块的像素都可以访问一个公共的共享内存,并保持一个统一的读取序列,从而提高渲染的并行执行效率。在原论文的官方实现中,该框架将块和像素的处理分别视为类似于CUDA编程架构中的block和thread。
3DGS的限制
一般来说,一个复杂场景需要由数百万个高斯点表示。因此,3DGS的每个场景都需要GB级别的存储空间。相比之下,NeRF的一个场景只需要MB级别的空间。


![BUUCTF-Real-[PHP]XXE](https://img-blog.csdnimg.cn/direct/e6c9ec3e656e466581df7cd3330c1030.png)