说明:
- 面试群,群号: 228447240
- 面试题来源于网络书籍,公司题目以及博主原创或修改(题目大部分来源于各种公司);
- 文中很多题目,或许大家直接编译器写完,1分钟就出结果了。但在这里博主希望每一个题目,大家都要经过认真思考,答案不重要,重要的是通过题目理解所考知识点,好应对题目更多的变化;
- 博主与大家一起学习,一起刷题,共同进步;
- 写文不易,麻烦给个三连!!!
前面1-15已经是C/C++,但是由于前面写的比较混乱,把八股文和题目混在了一起,所以从这一篇开始重新整理重新写,前面1-15也就可以选看了,希望多多支持!
1.在C++中,set 和 map 的数据结构
答案:
在C++中,set 和 map 分别提供以下三种数据结构,其底层实现以及优劣如下表所示:
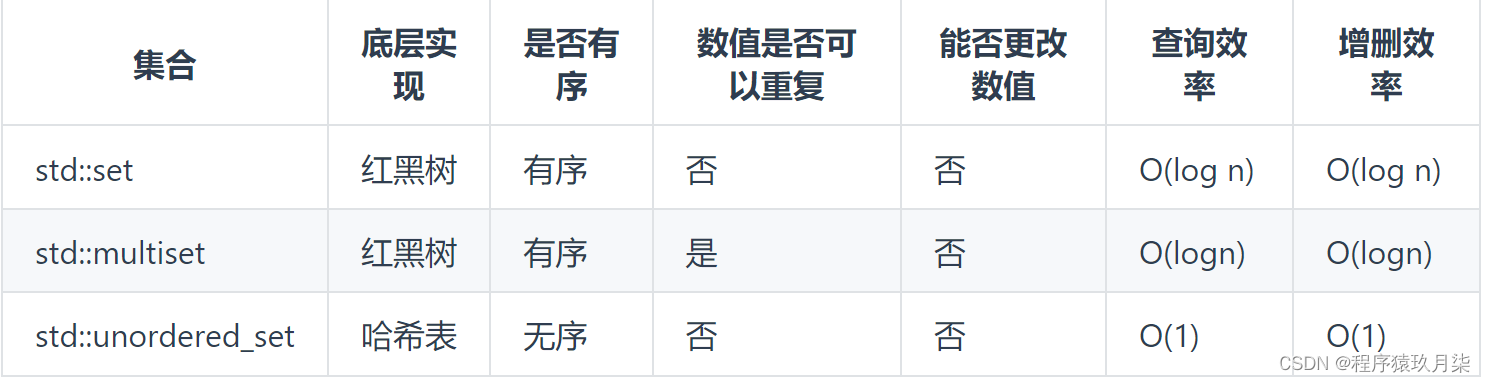
std::unordered_set底层实现为哈希表,std::set 和std::multiset 的底层实现是红黑树,红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。
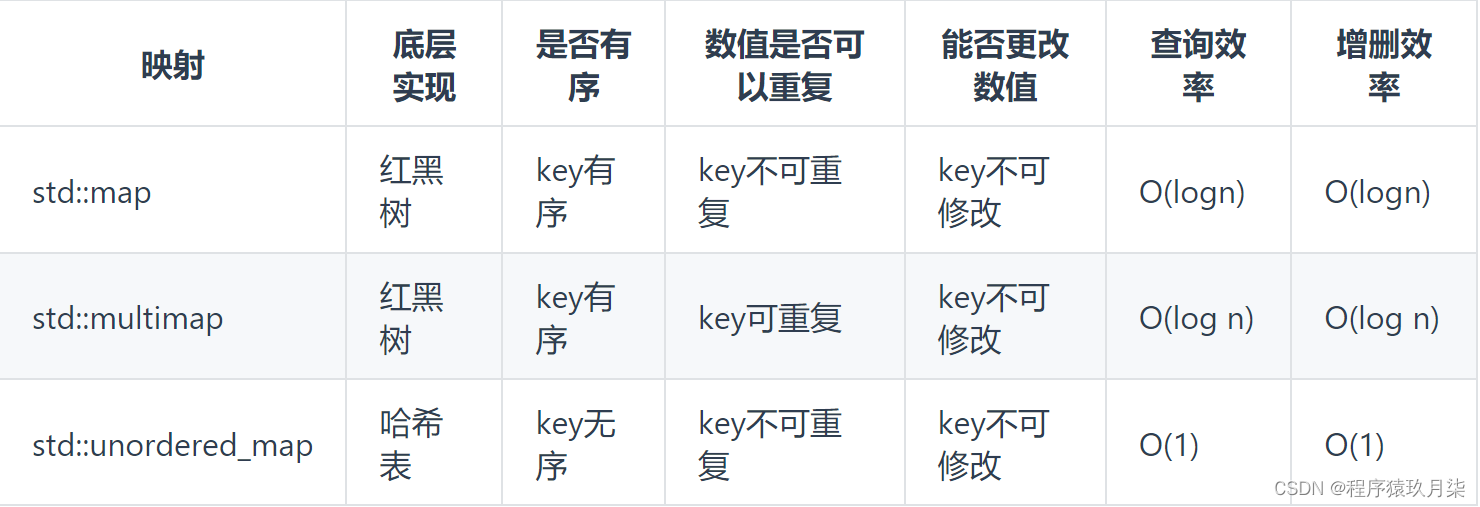
2.hashtable中解决冲突有哪些方法?
答案:
线性探测:使用hash函数计算出的位置如果已经有元素占用了,则向后依次寻找,找到表尾则回到表头,直到找到一个空位
开链:每个表格维护一个list,如果hash函数计算出的格子相同,则按顺序存在这个list中
再散列:发生冲突时使用另一种hash函数再计算一个地址,直到不冲突
二次探测:使用hash函数计算出的位置如果已经有元素占用了,按照$1^2$、$2^2$、$3^2$...的步长依次寻找,如果步长是随机数序列,则称之为伪随机探测
公共溢出区:一旦hash函数计算的结果相同,就放入公共溢出区
3.C++的多态如何实现
答案:
C++的多态性,简单说:
在基类的函数前加上virtual关键字,在派生类中重写该函数,运行时将会根据所指对象的实际类型来调用相应的函数,如果对象类型是派生类,就调用派生类的函数,如果对象类型是基类,就调用基类的函数。
4.为什么析构函数一般写成虚函数
答案:
由于类的多态性,基类指针可以指向派生类的对象,如果删除该基类的指针,就会调用该指针指向的派生类析构函数,而派生类的析构函数又自动调用基类的析构函数,这样整个派生类的对象完全被释放。
如果析构函数不被声明成虚函数,则编译器实施静态绑定,在删除基类指针时,只会调用基类的析构函数而不调用派生类析构函数,这样就会造成派生类对象析构不完全,造成内存泄漏。
所以将析构函数声明为虚函数是十分必要的。在实现多态时,当用基类操作派生类,在析构时防止只析构基类而不析构派生类的状况发生,要将基类的析构函数声明为虚函数。
5.构造函数、析构函数、虚函数可否声明为内联函数
答案:
构造函数和析构函数声明为内联函数是没有意义的
即编译器并不真正对声明为inline的构造和析构函数进行内联操作,因为编译器会在构造和析构函数中添加额外的操作(申请/释放内存,构造/析构对象等),致使构造函数/析构函数并不像看上去的那么精简。其次,class中的函数默认是inline型的,编译器也只是有选择性的inline,将构造函数和析构函数声明为内联函数是没有什么意义的。
将虚函数声明为inline,要分情况讨论
当是指向派生类的指针(多态性)调用声明为inline的虚函数时,不会内联展开;当是对象本身调用虚函数时,会内联展开,当然前提依然是函数并不复杂的情况下。
6.C++模板是什么,你知道底层怎么实现的?
答案:
1. 编译器并不是把函数模板处理成能够处理任意类的函数;编译器从函数模板通过具体类型产生不同的函数;编译器会对函数模板进行两次编译:在声明的地方对模板代码本身进行编译,在调用的地方对参数替换后的代码进行编译。
2. 这是因为函数模板要被实例化后才能成为真正的函数,在使用函数模板的源文件中包含函数模板的头文件,如果该头文件中只有声明,没有定义,那编译器无法实例化该模板,最终导致链接错误。
7.一个指针可以是 volatile 吗
答案:
可以,因为指针和普通变量一样,有时也有变化程序的不可控性。常见例:子中断服务子程序修改
一个指向一个 buffer 的指针时,必须用 volatile 来修饰这个指针。
说明: 指针是一种普通的变量,从访问上没有什么不同于其他变量的特性。其保存的数值是个整型数据,和整型变量不同的是,这个整型数据指向的是一段内存地址。
8.C 语言的关键字 static 和 C++ 的关键字 static 有什么区别
答案:
在 C 中 static 用来修饰局部静态变量和外部静态变量、函数。
而 C++中除了上述功能外,还用来定义类的成员变量和函数。即静态成员和静态成员函数。
注意: 编程时 static 的记忆性,和全局性的特点可以让在不同时期调用的函数进行通信,传递信息,而 C++的静态成员则可以在多个对象实例间进行通信,传递信息。
9.你知道Debug和Release的区别是什么吗
答案:
1、调试版本,包含调试信息,所以容量比Release大很多,并且不进行任何优化(优化会使调试复杂化,因为源代码和生成的指令间关系会更复杂),便于程序员调试。Debug模式下生成两个文件,除了.exe或.dll文件外,还有一个.pdb文件,该文件记录了代码中断点等调试信息;
2、发布版本,不对源代码进行调试,编译时对应用程序的速度进行优化,使得程序在代码大小和运行速度上都是最优的。(调试信息可在单独的PDB文件中生成)。Release模式下生成一个文件.exe或.dll文件。
3、实际上,Debug 和 Release 并没有本质的界限,他们只是一组编译选项的集合,编译器只是按照预定的选项行动。事实上,我们甚至可以修改这些选项,从而得到优化过的调试版本或是带跟踪语句的发布版本。
10.什么是纯虚函数,与虚函数的区别
答案:
虚函数是为了实现动态编联产生的,目的是通过基类类型的指针指向不同对象时,自动调用相应的、和基类同名的函数(使用同一种调用形式,既能调用派生类又能调用基类的同名函数)。虚函数需要在基类中加上virtual修饰符修饰,因为virtual会被隐式继承,所以子类中相同函数都是虚函数。当一个成员函数被声明为虚函数之后,其派生类中同名函数自动成为虚函数,在派生类中重新定义此函数时要求函数名、返回值类型、参数个数和类型全部与基类函数相同。
纯虚函数只是相当于一个接口名,但含有纯虚函数的类不能够实例化。纯虚函数首先是虚函数,其次它没有函数体,取而代之的是用“=0”。
既然是虚函数,它的函数指针会被存在虚函数表中,由于纯虚函数并没有具体的函数体,因此它在虚函数表中的值就为0,而具有函数体的虚函数则是函数的具体地址。
一个类中如果有纯虚函数的话,称其为抽象类。抽象类不能用于实例化对象,否则会报错。抽象类一般用于定义一些公有的方法。子类继承抽象类也必须实现其中的纯虚函数才能实例化对象。