本篇博客是本人参加Datawhale组队学习第五次任务的笔记
【教程地址】https://github.com/datawhalechina/joyrl-book
【强化学习库JoyRL】https://github.com/datawhalechina/joyrl/tree/main
【JoyRL开发周报】 https://datawhale.feishu.cn/docx/OM8fdsNl0o5omoxB5nXcyzsInGe?from=from_copylink
【教程参考地址】https://github.com/datawhalechina/easy-rl
文章目录
- 介绍
- 重要性采样
- PPO算法
- 核心思想
- 与TRPO方法的联系
- 公式推导
- 一个常见的误区
- 代码实战
- 1. 定义算法
- 2. 定义训练
- 3. 定义环境
- 训练可视化
- 练习
- 总结
介绍
| 算法 | 适用范围 | 提出时间 | 主要思想 |
|---|---|---|---|
| DQN | 只适用于离散动作 | 2013/2015 | 在Q-learning的基础上引入了深度神经网络 |
| A3C | 既适用于连续动作空间,也适用于离散动作空间 | 2016 | 引入了优势函数,引入多进程 |
| DDPG | 只适用于连续动作空间 | 2015 | 将选择动作的过程变成一个直接从状态映射到具体动作的函数 |
| TD3 | 只适用于连续动作空间 | 2018 | 双 Q 网络,延迟更新和躁声正则 |
| PPO | 既适用于连续动作空间,也适用于离散动作空间 | 2017 | 通过在策略梯度的优化过程中引入一个重要性权重来限制策略更新的幅度,从而提高算法的稳定性和收敛性 |
重要性采样
- 概念:一种估计随机变量的期望或者概率分布的统计方法
- 算法直觉:在复杂问题中利用已知的简单分布进行采样,从而避免了直接采样困难分布的问题
- 公式理解:

PPO算法
核心思想
通过重要性采样来优化原来的策略梯度估计
与TRPO方法的联系
- TRPO方法中通过使用约束而非惩罚项来保证策略更新的稳定性,主要原因是作为惩罚项的话会引入权重因子,而这个参数难以调节。
- TRPO中为了解优化问题,先线性近似目标函数,二阶近似约束,最后通过conjugate gradient算法和line search求解。
- PPO算法尝试通过一阶优化的方法来解。与TRPO中用约束来限制策略更新幅度不同,PPO中采用了惩罚项
公式推导
文中提出了基于clipped probability ratio的目标函数
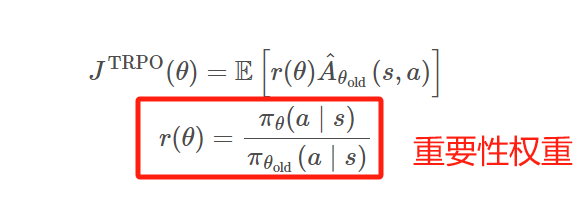
重要性权重最好尽可能地等于1,而在训练过程中这个权重它是不会自动地约束到1 附近的,因此我们需要在损失函数中加入一个约束项或者说正则项,保证重要性权重不会偏离 1 太远。具体的约束方法有很多种,比如 KL 散度、JS 散度等等,但通常我们会使用两种约束方法,一种是 clip 约束,另一种是KL 散度
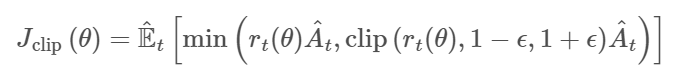
直观上,当策略更新的偏移超出预定区间而获得更大的目标函数值时,这个clip项就会产生影响
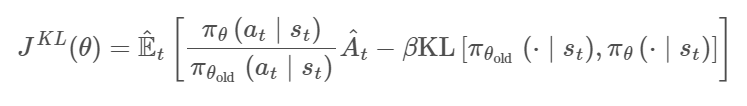
当策略更新前后KL散度小于预定值时,惩罚项系数β减小到原来的一半;当大于预定值时,系数增加一倍。如果使用神经网络和共享策略和值函数参数的话,就需要在损失函数中结合策略优化目标和值函数误差项。
一个常见的误区
- on-policy :使用当前策略生成样本,并基于这些样本来更新该策略
- on-policy 算法的数据利用效率较低因为每次策略更新后,旧的样本或经验可能就不再适用,通常需要重新采样
- off-policy 算法:可以使用过去的策略采集样本来更新当前的策略
- off-policy 算法由于可以利用历史经验,一般使用经验回放来存储和重复利用之前的经验,数据利用效率则较高,因为同一批数据可以被用于多次更新。但由于经验的再利用,可能会引入一定的偏见,但这也有助于稳定学习
在需要即时学习和适应的环境中,on-policy 算法可能更为适合,因为它们直接在当前策略下操作。
那么 PPO 算法究竟是 on-policy 还是 off-policy 的呢?
有读者可能会因为 PPO 算法在更新时重要性采样的部分中利用了旧的 Actor 采样的样本,就觉得PPO 算法会是 off-policy
的。实际上虽然这批样本是从旧的策略中采样得到的,但我们并没有直接使用这些样本去更新我们的策略,而是使用重要性采样先将数据分布不同导致的误差进行了修正,即是两者样本分布之间的差异尽可能地缩小。换句话说,就可以理解为重要性采样之后的样本虽然是由旧策略采样得到的,但可以近似为从更新后的策略中得到的,即我们要优化的
Actor 和采样的Actor 是同一个,因此 PPO 算法是 on-policy 的。
代码实战
PPO实现CarPole-v1(离散动作空间)
1. 定义算法
定义模型
import torch.nn as nn
import torch.nn.functional as F
class ActorSoftmax(nn.Module):def __init__(self, input_dim, output_dim, hidden_dim=256):super(ActorSoftmax, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, hidden_dim)self.fc3 = nn.Linear(hidden_dim, output_dim)def forward(self,x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))probs = F.softmax(self.fc3(x),dim=1)return probs
class Critic(nn.Module):def __init__(self,input_dim,output_dim,hidden_dim=256):super(Critic,self).__init__()assert output_dim == 1 # critic must output a single valueself.fc1 = nn.Linear(input_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, hidden_dim)self.fc3 = nn.Linear(hidden_dim, output_dim)def forward(self,x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))value = self.fc3(x)return value
定义经验回放
import random
from collections import deque
class ReplayBufferQue:'''DQN的经验回放池,每次采样batch_size个样本'''def __init__(self, capacity: int) -> None:self.capacity = capacityself.buffer = deque(maxlen=self.capacity)def push(self,transitions):'''_summary_Args:trainsitions (tuple): _description_'''self.buffer.append(transitions)def sample(self, batch_size: int, sequential: bool = False):if batch_size > len(self.buffer):batch_size = len(self.buffer)if sequential: # sequential samplingrand = random.randint(0, len(self.buffer) - batch_size)batch = [self.buffer[i] for i in range(rand, rand + batch_size)]return zip(*batch)else:batch = random.sample(self.buffer, batch_size)return zip(*batch)def clear(self):self.buffer.clear()def __len__(self):return len(self.buffer)class PGReplay(ReplayBufferQue):'''PG的经验回放池,每次采样所有样本,因此只需要继承ReplayBufferQue,重写sample方法即可'''def __init__(self):self.buffer = deque()def sample(self):''' sample all the transitions'''batch = list(self.buffer)return zip(*batch)
定义智能体
import torch
from torch.distributions import Categorical
class Agent:def __init__(self,cfg) -> None:self.gamma = cfg.gammaself.device = torch.device(cfg.device) self.actor = ActorSoftmax(cfg.n_states,cfg.n_actions, hidden_dim = cfg.actor_hidden_dim).to(self.device)self.critic = Critic(cfg.n_states,1,hidden_dim=cfg.critic_hidden_dim).to(self.device)self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=cfg.actor_lr)self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=cfg.critic_lr)self.memory = PGReplay()self.k_epochs = cfg.k_epochs # update policy for K epochsself.eps_clip = cfg.eps_clip # clip parameter for PPOself.entropy_coef = cfg.entropy_coef # entropy coefficientself.sample_count = 0self.update_freq = cfg.update_freqdef sample_action(self,state):self.sample_count += 1state = torch.tensor(state, device=self.device, dtype=torch.float32).unsqueeze(dim=0)probs = self.actor(state)dist = Categorical(probs)action = dist.sample()self.log_probs = dist.log_prob(action).detach()return action.detach().cpu().numpy().item()@torch.no_grad()def predict_action(self,state):state = torch.tensor(state, device=self.device, dtype=torch.float32).unsqueeze(dim=0)probs = self.actor(state)dist = Categorical(probs)action = dist.sample()return action.detach().cpu().numpy().item()def update(self):# update policy every n stepsif self.sample_count % self.update_freq != 0:return# print("update policy")old_states, old_actions, old_log_probs, old_rewards, old_dones = self.memory.sample()# convert to tensorold_states = torch.tensor(np.array(old_states), device=self.device, dtype=torch.float32)old_actions = torch.tensor(np.array(old_actions), device=self.device, dtype=torch.float32)old_log_probs = torch.tensor(old_log_probs, device=self.device, dtype=torch.float32)# monte carlo estimate of state rewardsreturns = []discounted_sum = 0for reward, done in zip(reversed(old_rewards), reversed(old_dones)):if done:discounted_sum = 0discounted_sum = reward + (self.gamma * discounted_sum)returns.insert(0, discounted_sum)# Normalizing the rewards:returns = torch.tensor(returns, device=self.device, dtype=torch.float32)returns = (returns - returns.mean()) / (returns.std() + 1e-5) # 1e-5 to avoid division by zerofor _ in range(self.k_epochs):# compute advantagevalues = self.critic(old_states) # detach to avoid backprop through the criticadvantage = returns - values.detach()# get action probabilitiesprobs = self.actor(old_states)dist = Categorical(probs)# get new action probabilitiesnew_probs = dist.log_prob(old_actions)# compute ratio (pi_theta / pi_theta__old):ratio = torch.exp(new_probs - old_log_probs) # old_log_probs must be detached# compute surrogate losssurr1 = ratio * advantagesurr2 = torch.clamp(ratio, 1 - self.eps_clip, 1 + self.eps_clip) * advantage# compute actor lossactor_loss = -torch.min(surr1, surr2).mean() + self.entropy_coef * dist.entropy().mean()# compute critic losscritic_loss = (returns - values).pow(2).mean()# take gradient stepself.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()actor_loss.backward()critic_loss.backward()self.actor_optimizer.step()self.critic_optimizer.step()self.memory.clear()
2. 定义训练
import copy
def train(cfg, env, agent):''' 训练'''print("开始训练!")rewards = [] # 记录所有回合的奖励steps = []best_ep_reward = 0 # 记录最大回合奖励output_agent = Nonefor i_ep in range(cfg.train_eps):ep_reward = 0 # 记录一回合内的奖励ep_step = 0state = env.reset() # 重置环境,返回初始状态for _ in range(cfg.max_steps):ep_step += 1action = agent.sample_action(state) # 选择动作next_state, reward, done, _ = env.step(action) # 更新环境,返回transitionagent.memory.push((state, action,agent.log_probs,reward,done)) # 保存transitionstate = next_state # 更新下一个状态agent.update() # 更新智能体ep_reward += reward # 累加奖励if done:breakif (i_ep+1)%cfg.eval_per_episode == 0:sum_eval_reward = 0for _ in range(cfg.eval_eps):eval_ep_reward = 0state = env.reset()for _ in range(cfg.max_steps):action = agent.predict_action(state) # 选择动作next_state, reward, done, _ = env.step(action) # 更新环境,返回transitionstate = next_state # 更新下一个状态eval_ep_reward += reward # 累加奖励if done:breaksum_eval_reward += eval_ep_rewardmean_eval_reward = sum_eval_reward/cfg.eval_epsif mean_eval_reward >= best_ep_reward:best_ep_reward = mean_eval_rewardoutput_agent = copy.deepcopy(agent)print(f"回合:{i_ep+1}/{cfg.train_eps},奖励:{ep_reward:.2f},评估奖励:{mean_eval_reward:.2f},最佳评估奖励:{best_ep_reward:.2f},更新模型!")else:print(f"回合:{i_ep+1}/{cfg.train_eps},奖励:{ep_reward:.2f},评估奖励:{mean_eval_reward:.2f},最佳评估奖励:{best_ep_reward:.2f}")steps.append(ep_step)rewards.append(ep_reward)print("完成训练!")env.close()return output_agent,{'rewards':rewards}def test(cfg, env, agent):print("开始测试!")rewards = [] # 记录所有回合的奖励steps = []for i_ep in range(cfg.test_eps):ep_reward = 0 # 记录一回合内的奖励ep_step = 0state = env.reset() # 重置环境,返回初始状态for _ in range(cfg.max_steps):ep_step+=1action = agent.predict_action(state) # 选择动作next_state, reward, done, _ = env.step(action) # 更新环境,返回transitionstate = next_state # 更新下一个状态ep_reward += reward # 累加奖励if done:breaksteps.append(ep_step)rewards.append(ep_reward)print(f"回合:{i_ep+1}/{cfg.test_eps},奖励:{ep_reward:.2f}")print("完成测试")env.close()return {'rewards':rewards}
3. 定义环境
import gym
import os
import numpy as np
def all_seed(env,seed = 1):''' 万能的seed函数'''if seed == 0:returnenv.seed(seed) # env confignp.random.seed(seed)random.seed(seed)torch.manual_seed(seed) # config for CPUtorch.cuda.manual_seed(seed) # config for GPUos.environ['PYTHONHASHSEED'] = str(seed) # config for python scripts# config for cudnntorch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = Falsetorch.backends.cudnn.enabled = False
def env_agent_config(cfg):env = gym.make(cfg.env_name) # 创建环境all_seed(env,seed=cfg.seed)n_states = env.observation_space.shape[0]n_actions = env.action_space.nprint(f"状态空间维度:{n_states},动作空间维度:{n_actions}")# 更新n_states和n_actions到cfg参数中setattr(cfg, 'n_states', n_states)setattr(cfg, 'n_actions', n_actions) agent = Agent(cfg)return env,agent
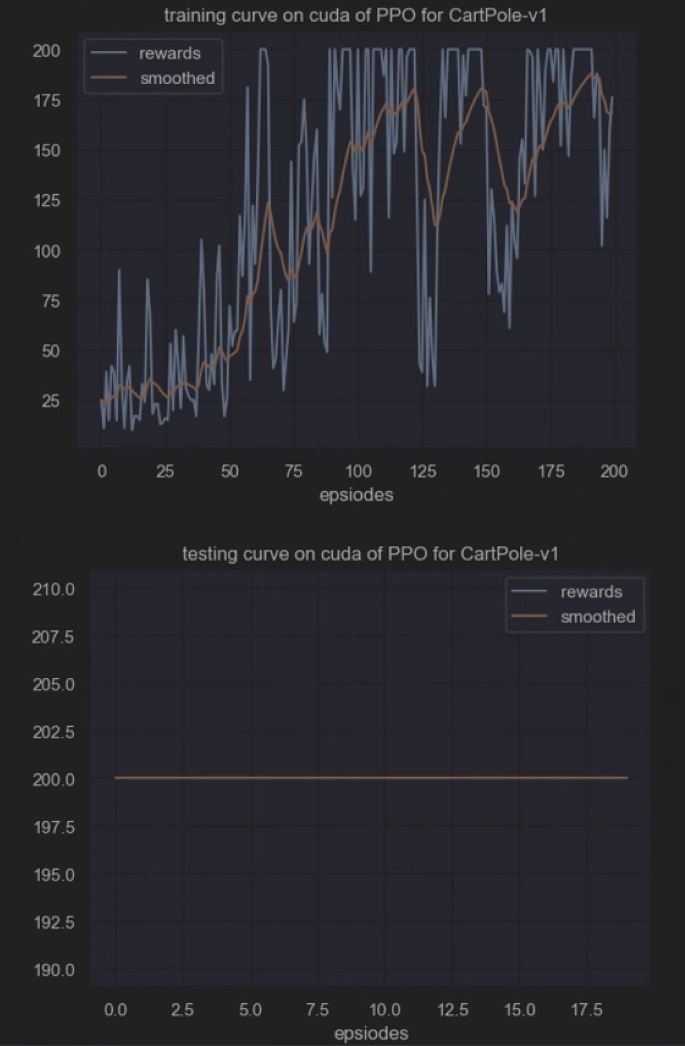
训练可视化
import matplotlib.pyplot as plt
import seaborn as sns
class Config:def __init__(self) -> None:self.env_name = "CartPole-v1" # 环境名字self.new_step_api = False # 是否用gym的新apiself.algo_name = "PPO" # 算法名字self.mode = "train" # train or testself.seed = 1 # 随机种子self.device = "cuda" # device to useself.train_eps = 200 # 训练的回合数self.test_eps = 20 # 测试的回合数self.max_steps = 200 # 每个回合的最大步数self.eval_eps = 5 # 评估的回合数self.eval_per_episode = 10 # 评估的频率self.gamma = 0.99 # 折扣因子self.k_epochs = 4 # 更新策略网络的次数self.actor_lr = 0.0003 # actor网络的学习率self.critic_lr = 0.0003 # critic网络的学习率self.eps_clip = 0.2 # epsilon-clipself.entropy_coef = 0.01 # entropy的系数self.update_freq = 100 # 更新频率self.actor_hidden_dim = 256 # actor网络的隐藏层维度self.critic_hidden_dim = 256 # critic网络的隐藏层维度def smooth(data, weight=0.9): '''用于平滑曲线,类似于Tensorboard中的smooth曲线'''last = data[0] smoothed = []for point in data:smoothed_val = last * weight + (1 - weight) * point # 计算平滑值smoothed.append(smoothed_val) last = smoothed_val return smootheddef plot_rewards(rewards,cfg, tag='train'):''' 画图'''sns.set()plt.figure() # 创建一个图形实例,方便同时多画几个图plt.title(f"{tag}ing curve on {cfg.device} of {cfg.algo_name} for {cfg.env_name}")plt.xlabel('epsiodes')plt.plot(rewards, label='rewards')plt.plot(smooth(rewards), label='smoothed')plt.legend()
# 获取参数
cfg = Config()
# 训练
env, agent = env_agent_config(cfg)
best_agent,res_dic = train(cfg, env, agent)plot_rewards(res_dic['rewards'], cfg, tag="train")
# 测试
res_dic = test(cfg, env, best_agent)
plot_rewards(res_dic['rewards'], cfg, tag="test") # 画出结果
状态空间维度:4,动作空间维度:2
开始训练!
回合:10/200,奖励:11.00,评估奖励:29.20,最佳评估奖励:29.20,更新模型!
回合:20/200,奖励:68.00,评估奖励:25.00,最佳评估奖励:29.20
回合:30/200,奖励:60.00,评估奖励:26.20,最佳评估奖励:29.20
回合:40/200,奖励:105.00,评估奖励:27.60,最佳评估奖励:29.20
回合:50/200,奖励:26.00,评估奖励:60.60,最佳评估奖励:60.60,更新模型!
回合:60/200,奖励:122.00,评估奖励:113.40,最佳评估奖励:113.40,更新模型!
回合:70/200,奖励:65.00,评估奖励:38.00,最佳评估奖励:113.40
回合:80/200,奖励:175.00,评估奖励:135.40,最佳评估奖励:135.40,更新模型!
回合:90/200,奖励:200.00,评估奖励:177.20,最佳评估奖励:177.20,更新模型!
回合:100/200,奖励:115.00,评估奖励:173.60,最佳评估奖励:177.20
回合:110/200,奖励:200.00,评估奖励:183.20,最佳评估奖励:183.20,更新模型!
回合:120/200,奖励:196.00,评估奖励:173.60,最佳评估奖励:183.20
回合:130/200,奖励:46.00,评估奖励:61.40,最佳评估奖励:183.20
回合:140/200,奖励:200.00,评估奖励:166.40,最佳评估奖励:183.20
回合:150/200,奖励:172.00,评估奖励:154.40,最佳评估奖励:183.20
回合:160/200,奖励:61.00,评估奖励:84.80,最佳评估奖励:183.20
回合:170/200,奖励:127.00,评估奖励:181.60,最佳评估奖励:183.20
回合:180/200,奖励:152.00,评估奖励:173.20,最佳评估奖励:183.20
回合:190/200,奖励:200.00,评估奖励:200.00,最佳评估奖励:200.00,更新模型!
回合:200/200,奖励:176.00,评估奖励:190.20,最佳评估奖励:200.00
完成训练!
开始测试!
回合:1/20,奖励:200.00
回合:2/20,奖励:200.00
回合:3/20,奖励:200.00
回合:4/20,奖励:200.00
回合:5/20,奖励:200.00
回合:6/20,奖励:200.00
回合:7/20,奖励:200.00
回合:8/20,奖励:200.00
回合:9/20,奖励:200.00
回合:10/20,奖励:200.00
回合:11/20,奖励:200.00
回合:12/20,奖励:200.00
回合:13/20,奖励:200.00
回合:14/20,奖励:200.00
回合:15/20,奖励:200.00
回合:16/20,奖励:200.00
回合:17/20,奖励:200.00
回合:18/20,奖励:200.00
回合:19/20,奖励:200.00
回合:20/20,奖励:200.00
完成测试
练习
- 为什么 DQN \text{DQN} DQN 和 DDPG \text{DDPG} DDPG 算法不使用重要性采样技巧呢?
DQN \text{DQN} DQN 和 DDPG \text{DDPG} DDPG 是 off-policy \text{off-policy} off-policy算法,它们通常不需要重要性采样来处理不同策略下的采样数据。相反,它们使用目标网络和优势估计等技巧来提高训练的稳定性和性能。
- PPO \text{PPO} PPO 算法原理上是 on-policy \text{on-policy} on-policy 的,但它可以是 off-policy \text{off-policy} off-policy 的吗,或者说可以用经验回放来提高训练速度吗?为什么?(提示:是可以的,但条件比较严格)
跟 A2C \text{A2C} A2C 一样,可以将经验回放与 PPO \text{PPO} PPO 结合,创建一个 PPO with Experience Replay (PPO-ER) \text{PPO with Experience Replay (PPO-ER)} PPO with Experience Replay (PPO-ER) 算法。在 PPO-ER \text{PPO-ER} PPO-ER中,智能体使用经验回放缓冲区中的数据来训练策略网络,这样可以提高训练效率和稳定性。这种方法通常需要调整PPO的损失函数和采样策略,以适应 off-policy \text{off-policy} off-policy 训练的要求,需要谨慎调整。
- PPO \text{PPO} PPO 算法更新过程中在将轨迹样本切分个多个小批量的时候,可以将这些样本顺序打乱吗?为什么?
将轨迹样本切分成多个小批量时,通常是可以将这些样本顺序打乱的,这个过程通常称为样本随机化( sample shuffling \text{sample shuffling} sample shuffling ),这样做的好处有降低样本相关性、减小过拟合风险以及增加训练多样性(更全面地提高探索空间)。
- 为什么说重要性采样是一种特殊的蒙特卡洛采样?
估计期望值:蒙特卡洛方法的核心目标之一是估计一个随机变量的期望值。蒙特卡洛采样通过从分布中生成大量的样本,并求取这些样本的平均值来估计期望值。重要性采样也是通过从一个分布中生成样本,但不是均匀地生成样本,而是按照另一个分布的权重生成样本,然后使用这些带权重的样本来估计期望值。
改进采样效率:重要性采样的主要目的是改进采样效率。当我们有一个难以从中采样的分布时,可以使用重要性采样来重新调整样本的权重,以使估计更准确。这类似于在蒙特卡洛采样中调整样本大小以提高估计的精确性。
权重分布:在重要性采样中,我们引入了一个额外的权重分布,用于指导采样过程。这个权重分布决定了每个样本的相对贡献,以确保估计是无偏的。在蒙特卡洛采样中,权重通常是均匀分布,而在重要性采样中,权重由分布的比率(要估计的分布和采样分布之间的比例)决定。
总结
PG方法的缺点是数据效率和鲁棒性不好。同时TRPO方法又比较复杂,且不兼容dropout(在深度神经网络训练过程中按照一定概率对网络单元进行丢弃)和参数共享(策略和值函数间)。这篇论文提出了PPO算法,它是对TRPO算法的改进,更易于实现,且数据效率更高。TRPO方法中通过使用约束而非惩罚项来保证策略更新的稳定性,主要原因是作为惩罚项的话会引入权重因子,而这个参数难以调节。TRPO中为了解优化问题,先线性近似目标函数,二阶近似约束,最后通过conjugate gradient算法和line search求解。而这篇文章尝试通过一阶优化的方法来解。与TRPO中用约束来限制策略更新幅度不同,PPO中采用了惩罚项。

![[力扣 Hot100]Day20 旋转图像](https://img-blog.csdnimg.cn/direct/c286c3e66fb64dd9be08f15b7f2f59a5.png)