Auto-GPT
Auto-GPT 是一个实验性的开源项目,基于 GPT-4。你给出 Auto-GPT 一个的任务,它不会立即输出答案,而会先自己通过多轮对话来琢磨、验证、决策,从而自己找出一条达成目标的路,整个过程完全不需要人类插手!
作为 GPT-4 完全自主运行的示例开源项目,Auto-GPT 正在“突破” AI 的界限,这意味着 AI 正逐渐向更加自主化和智能化的方向发展。
开源地址:https://github.com/Significant-Gravitas/Auto-GPT
GPT 3.5 平替开源项目Alpaca
Alpaca 是由 Meta 的 LLaMA 7B 微调而来的全新模型,仅用了 52k 数据,低成本训练,性能约等于 GPT-3.5,是一个不错的 GPT 3.5 平替开源项目,目前该开源项目已经获得了 22k 的 Star。

开源项目:https://github.com/tatsu-lab/stanford_alpaca
复旦大模型 MOSS!
国内首个对话式大语言模型开源了!复旦大学发布的大模型 MOSS 正式开源,相关代码、数据、模型参数已在 Github 平台开放,供科研人员下载。
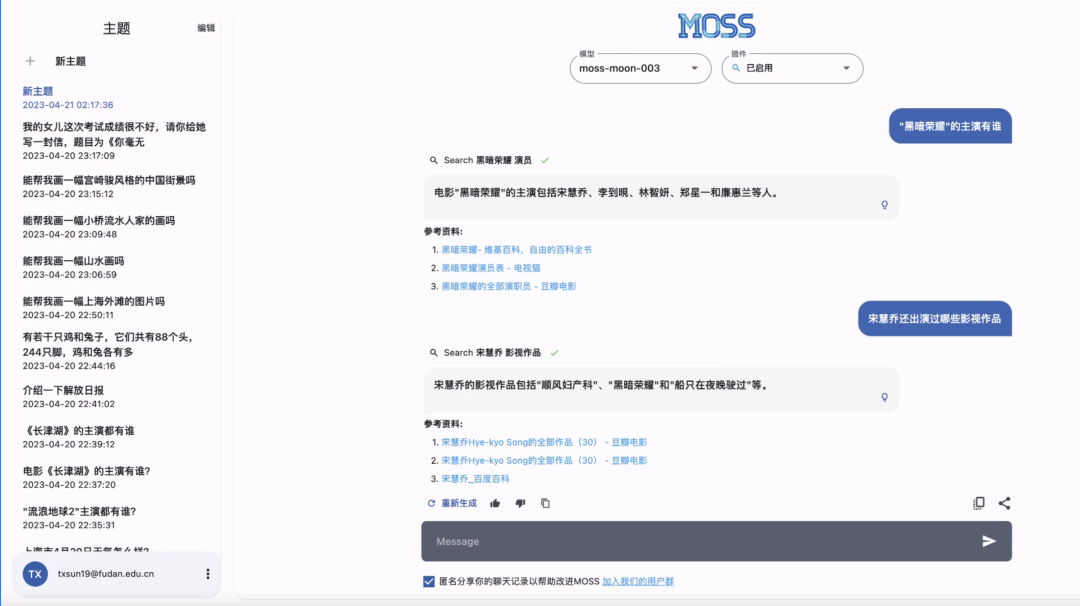
开源项目:https://github.com/OpenLMLab/MOSS
国人开源的免费教程
该项目目前获得了近 4k 的 Star,包括 ChatGPT 教程和Midjourney 教程两部分,通过一些案例和技巧,教你深入的使用 ChatGPT 和 Midjourney 。
即使是小白,看完教程后,也能够快速上手!
开源地址:https://github.com/thinkingjimmy/Learning-Prompt
大模型论文、开源项目整理
这个开源项目整理了大模型领域的论文、工具、教程、视频、相关开源项目等等。
开源地址:https://github.com/promptslab/Awesome-Prompt-Engineering

提示工程指南中文版
源自于 Prompt 工程师指南英文版, AIGC 国内爱好者翻译成了中文。
开源地址:https://github.com/wangxuqi/Prompt-Engineering-Guide-Chinese
通义千问
基于 ModelScope 以及 Hugging Face均开源的 Qwen-7B 系列模型,这是是阿里云研发的通义千问大模型系列的70亿参数规模的模型。
Qwen-7B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。
开源地址:https://github.com/QwenLM/Qwen-7B
中文对话式大语言模型
Firefly(流萤) 是一个开源的中文大语言模型项目,在 Open LLM 排行榜排名第 10。该开源项目提供了 6 个版本的开源项目进行下载,还提供了 5 个数据集。
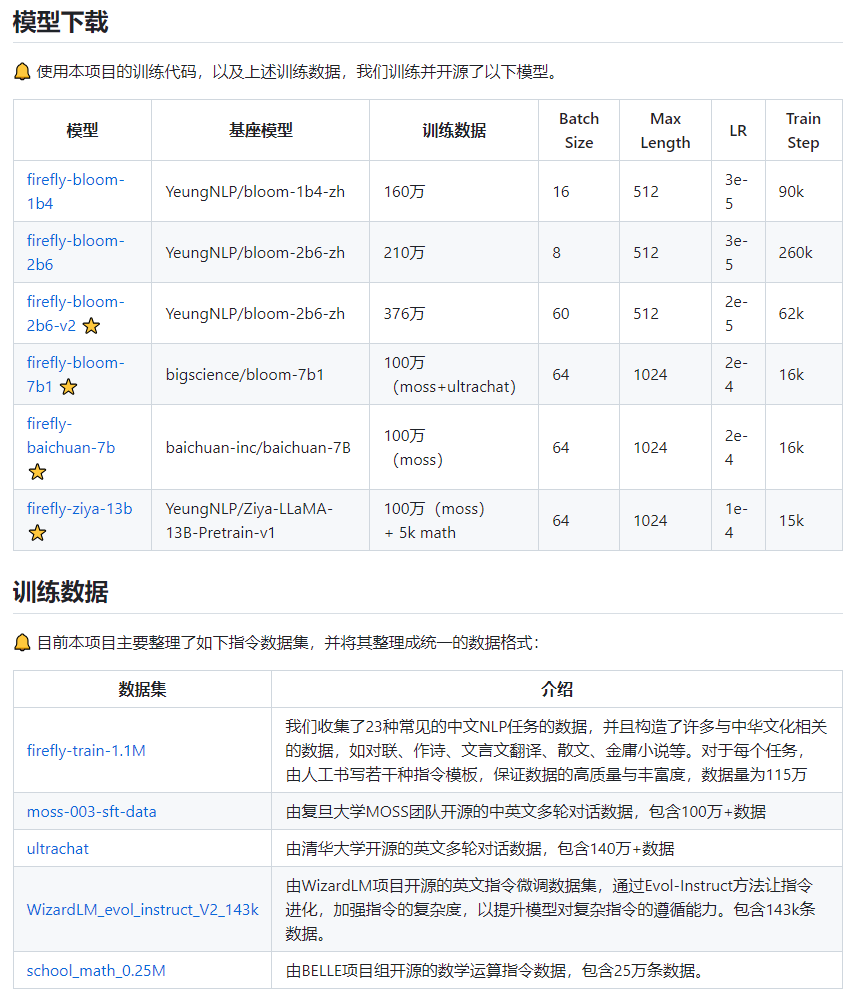
开源地址:https://github.com/yangjianxin1/Firefly

模拟人类行为的小镇
这是一篇论文的源码,论文讨论内容很有意思。在一个小镇住着 25 个小人,每天一个小人都是基于 GPT,他们能在这个小镇自由活动、交流。
给这个 25 人设置了一种行为模式,既感知、记忆、检索、反思、计划、行动等等,由于是基于 GPT,这个 25 个小人可以按照这种设置的行为模式自由。成长
通过这种方式,来观察这个小镇中的人会不会出现很有意思的行为,在这个小镇中最终出现了三种社会行为:信息传播、关系记忆、协作。
开源地址:https://github.com/joonspk-research/generative_agents

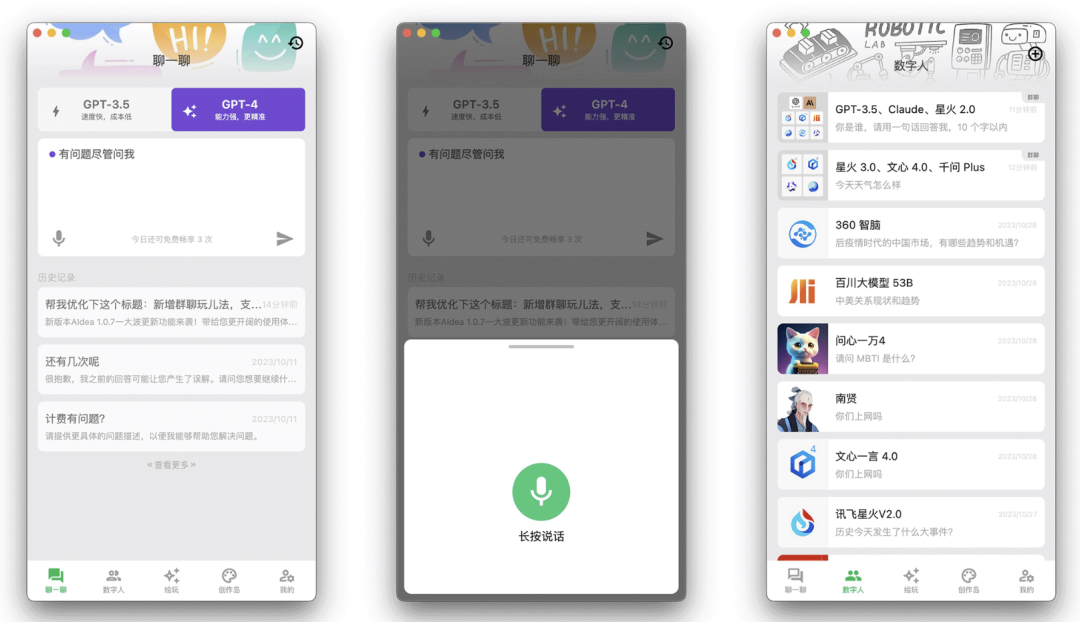
集成了主流模型的 APP
一款集成了主流大语言模型以及绘图模型的 APP, 采用 Flutter 开发,代码完全开源,支持以下功能:文生图、图生图、超分辨率、黑白图片上色,集成了 Stable Diffusion 模型
支持 GPT-3.5/4 问答聊天、接入了通义千问,文心一言、讯飞星火等大模型
客户端:https://github.com/mylxsw/aidea
服务端:https://github.com/mylxsw/aidea-server

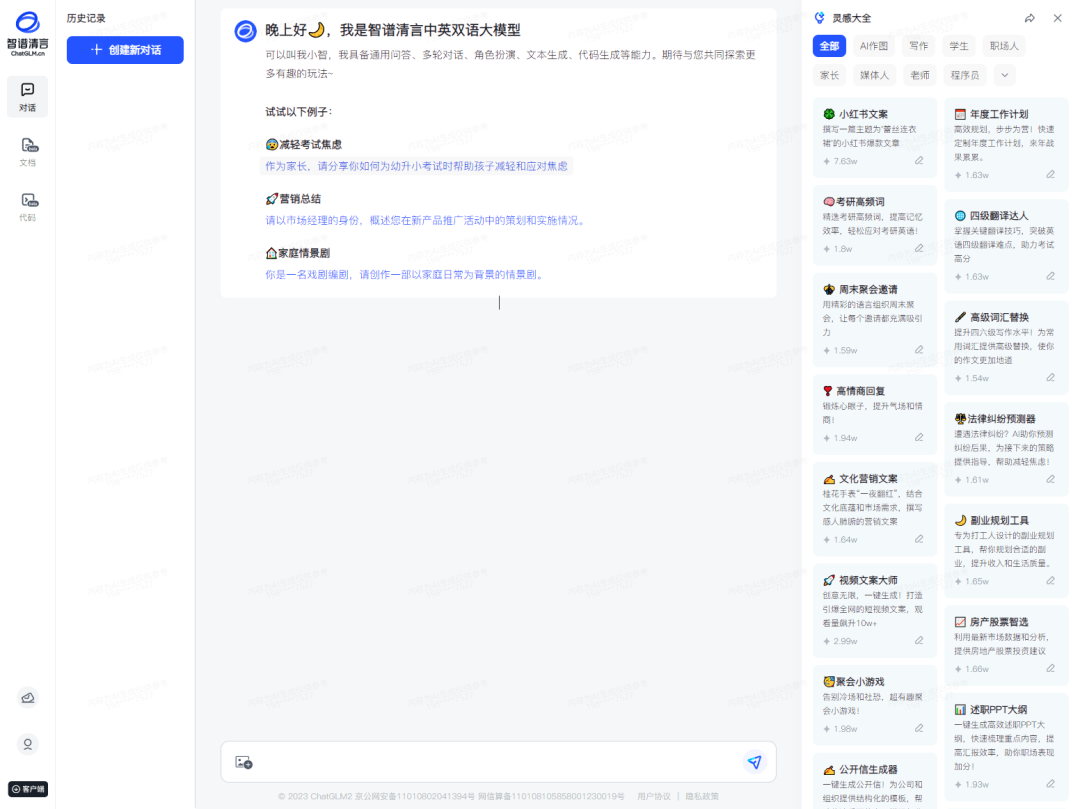
ChatGLM3
ChatGLM3 是由智谱AI和清华大学KEG实验室联合发布的新一代对话预训练模型。ChatGLM3-6B是其中的开源模型,带有多种新特性:
1) ChatGLM3-6B-Base在训练数据、训练步数和训练策略上进行了改进,在不同数据集上表现强劲。
2) 引入了Prompt格式,支持工具调用、代码执行和Agent任务等复杂场景。
3) 除了对话模型,还开源了基础模型和长文本对话模型,允许学术研究并允许免费商业使用。
提供了多种模型及评测结果,示例了模型调用的方式和低成本部署方式,包括模型量化、CPU部署、Mac部署、多卡部署等。
开源地址:https://github.com/THUDM/ChatGLM3
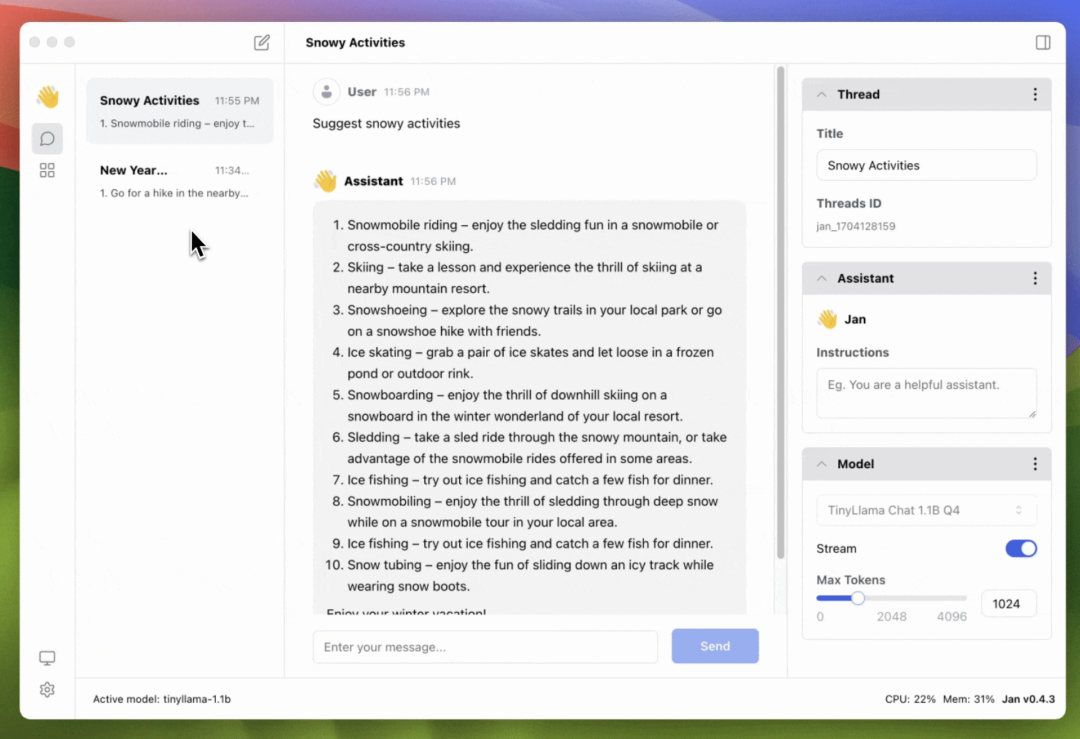
将 AI 大模型带入你的桌面-Jan
Jan 是近一个月开源的项目,目前已经获得了近 6K 的 Star,号称 ChatGPT 的开源替代品,可在你的计算机上离线且私密的运行大模型。
目前在 Windows、Mac、Linux 上提供了客户端可以下载。从 PC 到 GPU,Jan 可以在任何硬件上进行运行。比如英伟达 GPU、Apple M系列芯片、Inter。

开源地址:https://github.com/janhq/jan
对话
基于该开源项目,你可以创建多个对话,每一个对话基于的大模型、最大的 Tokens 可以自行配置。
下载大模型
Jan 有一个 Hub 模块,里面提供了 20 个大模型可以下载,在这里你可以选择你的客户端想要使用的大模型。
除了 Llama 此类开源大模型,也支持接入 Open AI GPT 3.5、4的接口。
小羊驼
TinyLlama 一个拥有 11 亿参数的 Llama 模型,采用了与 Llama 2 完全相同的架构和分词器,可以在许多基于 Llama 的开源项目中即插即用。
此外,TinyLlama 只有1.1B的参数,体积小巧,适用于需要限制计算和内存占用的多种应用。该开源项目的代码可以给初学者做一个入门预训练的简洁参考。
开源地址:https://github.com/jzhang38/TinyLlama

Yi 大模型
Yi 是零一万物(李开复带队孵化的 AI 公司)从零开始训练的大型语言模型。这些模型是双语(英语/中文)基础模型,参数规模分别为 6B 和 34B。
它们都是使用 4K 序列长度进行训练的,且在推理时可以扩展到32K。Yi 系列模型在语言理解、常识推理、阅读理解等方面表现出了强大的能力。
Yi 系列模型在 2023 年 12 月的 AlpacaEval 排行榜上排名第二(仅次于 GPT-4),超过了其他大型语言模型(如 LLaMA2-chat-70B、Claude 2 和 ChatGPT)。
对于中文语言能力,Yi 系列模型在 2023 年 10 月的 SuperCLUE 排行榜上排名第二(仅次于 GPT-4),超过了其他大型语言模型(如百度的 ERNIE、Qwen 和百川)。
此外,Yi 系列模型完全开放供学术研究和免费商业使用,帮助开发者快速构建自己的“ChatGPT”助手
开源地址:https://github.com/01-ai/Yi