本文为🔗365天深度学习训练营 中的学习记录博客
原作者:K同学啊|接辅导、项目定制
我的环境:
1.语言:python3.7
2.编译器:pycharm
3.深度学习框架Pytorch 1.8.0+cu111
论文地址
一、理论理解
半监督生成对抗网络(SGAN)的鉴别器是多分类器(不单单只是区分哪些是生成器生成的,哪些是真实数据)而是学会区分N+1类,其中N是训练数据集中的类别数,生成器生成的伪样本增加了一个类。
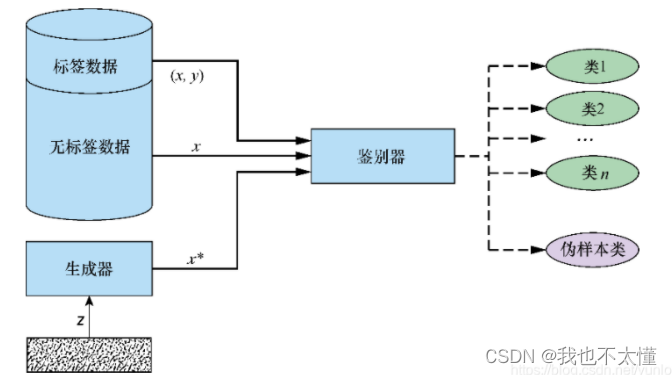
这种方法可以得到训练效果更好的判别器,并且可以比普通的GAN产生更高质量的样本。
SGAN生成器的目的与原始GAN相同:接收一个随机数向量并生成伪样本,力求使伪样本与训练数据集别无二致。但是,SGAN鉴别器与原始GAN实现有很大不同。它接收3种输入:生成器生成的伪样本X*、训练数据集中无标签的真实样本X和有标签的真实样本X,y。其中y表示给定样本X的标签。
1.1、SGAN 优点:
1,我们对GANs做了一个新的扩展,允许它同时学习一个生成模型和一个分类器。我们把这个扩展叫做半监督GAN 或SGAN
2,我们表明SGAN在有限数据集上比没有生成部分的基准分类器 提升了分类性能。
3,我们证明,SGAN可以显著地提升生成样本的质量并降低生成器的训练时间。
1.2、训练特点:
SCAN有两种损失值:有监督损失和无监督损失。
在SGAN中主要关心的是鉴别器。训练过程的目标是使该网络成为仅使用一小部分标签数据的半监督分类器,其准确率尽可能接近全监督的分类器(其训练数据集中的每个样本都有标签)。生成器的目标是通过提供附加信息(它生成的伪数据)来帮助鉴别器学习数据中的相关模式,从而提高其分类准确率。训练结束时,生成器将被丢弃,而训练有素的鉴别器将被用作分类器。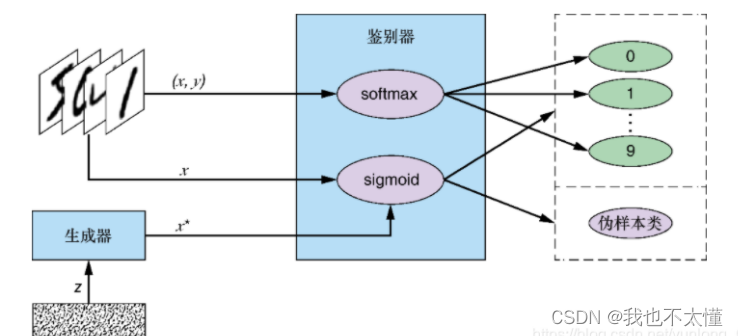
为了解决区分真实标签的多分类问题,鉴别器使用了softmax函数,该函数给出了在给定数量的类别(本例中为10类)上的概率分布。给一个给定类别标签分配的概率越高,鉴别器就越确信该样本属于这一给定的类。为了计算分类误差,使用了交叉熵损失,以测量输出概率与目标独热编码标签之间的差异。
1.3、结果:
生成结果:

在MNIST数据集上实验来看SGAN 是否可以比一般GAN得到更好的生成样本。用一个与DCGAN类似的结构训练SGAN ,训练时用了真实的MNIST标签和只有real和fake的两种标签。注意,第二种配置与通常的GAN 语义上完全相同。图1包含了GAN和SGAN 两者生成的样本。SGAN 的输出明显比GAN 的输出更清晰。这看起来对于不同的初始化和网络架构中都是正确的,但是很难对不同的超参数进行样本质量的系统评估。
分类结果:
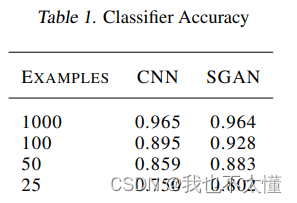
在MNIST 上进行实验,看SGAN 的分类器部分在有限的训练集上是否可以比一个独立的分类器表现得更好。为了训练baseline(基线),我们在训练SGAN时没有更新G 。SGAN 胜过baseline,我们越缩减训练集,优势越明显。这表明强制D和C共享权重提高了数据效率。表1展示了详细的性能数据。为了计算正确率,我们选择了与"FAKE"标签不对应的输出中的最大值。对于每个模型,我们对学习率进行了随机搜索,并呈现出最佳结果。
二、代码
import argparse
import os
import numpy as np
import mathimport torchvision.transforms as transforms
from torchvision.utils import save_imagefrom torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variableimport torch.nn as nn
import torch.nn.functional as F
import torchos.makedirs("images", exist_ok=True)parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=50, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--num_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)cuda = True if torch.cuda.is_available() else Falsedef weights_init_normal(m):classname = m.__class__.__name__if classname.find("Conv") != -1:torch.nn.init.normal_(m.weight.data, 0.0, 0.02)elif classname.find("BatchNorm") != -1:torch.nn.init.normal_(m.weight.data, 1.0, 0.02)torch.nn.init.constant_(m.bias.data, 0.0)class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.label_emb = nn.Embedding(opt.num_classes, opt.latent_dim)self.init_size = opt.img_size // 4 # Initial size before upsamplingself.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))self.conv_blocks = nn.Sequential(nn.BatchNorm2d(128),nn.Upsample(scale_factor=2),nn.Conv2d(128, 128, 3, stride=1, padding=1),nn.BatchNorm2d(128, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2),nn.Conv2d(128, 64, 3, stride=1, padding=1),nn.BatchNorm2d(64, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),nn.Tanh(),)def forward(self, noise):out = self.l1(noise)out = out.view(out.shape[0], 128, self.init_size, self.init_size)img = self.conv_blocks(out)return imgclass Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()def discriminator_block(in_filters, out_filters, bn=True):"""Returns layers of each discriminator block"""block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]if bn:block.append(nn.BatchNorm2d(out_filters, 0.8))return blockself.conv_blocks = nn.Sequential(*discriminator_block(opt.channels, 16, bn=False),*discriminator_block(16, 32),*discriminator_block(32, 64),*discriminator_block(64, 128),)# The height and width of downsampled imageds_size = opt.img_size // 2 ** 4# Output layersself.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())self.aux_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, opt.num_classes + 1), nn.Softmax())def forward(self, img):out = self.conv_blocks(img)out = out.view(out.shape[0], -1)validity = self.adv_layer(out)label = self.aux_layer(out)return validity, label# Loss functions
adversarial_loss = torch.nn.BCELoss()
auxiliary_loss = torch.nn.CrossEntropyLoss()# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()if cuda:generator.cuda()discriminator.cuda()adversarial_loss.cuda()auxiliary_loss.cuda()# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(datasets.MNIST("../../data/mnist",train=True,download=True,transform=transforms.Compose([transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]),),batch_size=opt.batch_size,shuffle=True,
)# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor# ----------
# Training
# ----------for epoch in range(opt.n_epochs):for i, (imgs, labels) in enumerate(dataloader):batch_size = imgs.shape[0]# Adversarial ground truthsvalid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)fake_aux_gt = Variable(LongTensor(batch_size).fill_(opt.num_classes), requires_grad=False)# Configure inputreal_imgs = Variable(imgs.type(FloatTensor))labels = Variable(labels.type(LongTensor))# -----------------# Train Generator# -----------------optimizer_G.zero_grad()# Sample noise and labels as generator inputz = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))# Generate a batch of imagesgen_imgs = generator(z)# Loss measures generator's ability to fool the discriminatorvalidity, _ = discriminator(gen_imgs)g_loss = adversarial_loss(validity, valid)g_loss.backward()optimizer_G.step()# ---------------------# Train Discriminator# ---------------------optimizer_D.zero_grad()# Loss for real imagesreal_pred, real_aux = discriminator(real_imgs)d_real_loss = (adversarial_loss(real_pred, valid) + auxiliary_loss(real_aux, labels)) / 2# Loss for fake imagesfake_pred, fake_aux = discriminator(gen_imgs.detach())d_fake_loss = (adversarial_loss(fake_pred, fake) + auxiliary_loss(fake_aux, fake_aux_gt)) / 2# Total discriminator lossd_loss = (d_real_loss + d_fake_loss) / 2# Calculate discriminator accuracypred = np.concatenate([real_aux.data.cpu().numpy(), fake_aux.data.cpu().numpy()], axis=0)gt = np.concatenate([labels.data.cpu().numpy(), fake_aux_gt.data.cpu().numpy()], axis=0)d_acc = np.mean(np.argmax(pred, axis=1) == gt)d_loss.backward()optimizer_D.step()batches_done = epoch * len(dataloader) + iif batches_done % opt.sample_interval == 0:save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %d%%] [G loss: %f]"% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), 100 * d_acc, g_loss.item()))






![[嵌入式软件][启蒙篇][仿真平台] STM32F103实现SPI控制OLED屏幕](https://img-blog.csdnimg.cn/direct/3b8a63cbce9e4990862adfcc484a0bf8.gif#pic_center)