首选,为了防止后期docker满,Docker容器 - 启动报错:No space left on device,更换一下docker存储位置
1、停止Docker服务
首先停止Docker守护进程,可以使用以下命令:
sudo systemctl stop docker
备份现有的Docker数据:在进行目录更改之前,建议你备份当前Docker的数据,以防止意外数据丢失。
2、创建新的存储目录,这个盘有28TB,足够了
使用以下命令在/home目录下创建一个名为docker的新目录:
sudo mkdir /media/cys/c4e58bbe-a73a-4b02-ae9e-2b310ee884fb/docker
3、编辑Docker配置文件
修改Docker的启动配置文件/etc/docker/daemon.json,如果文件不存在则创建该文件。在文件中添加以下内容(如果文件已存在,则添加"data-root"一行即可):
{
"data-root": "/media/cys/c4e58bbe-a73a-4b02-ae9e-2b310ee884fb/docker"
}
4、启动Docker服务
保存并关闭编辑器后,启动Docker服务以应用更改:
sudo systemctl start docker
5、验证更改
运行以下命令验证Docker的数据存储目录是否已经更改:
docker info | grep "Docker Root Dir"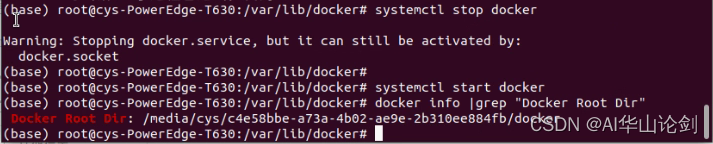
然后按照教程一步步来,
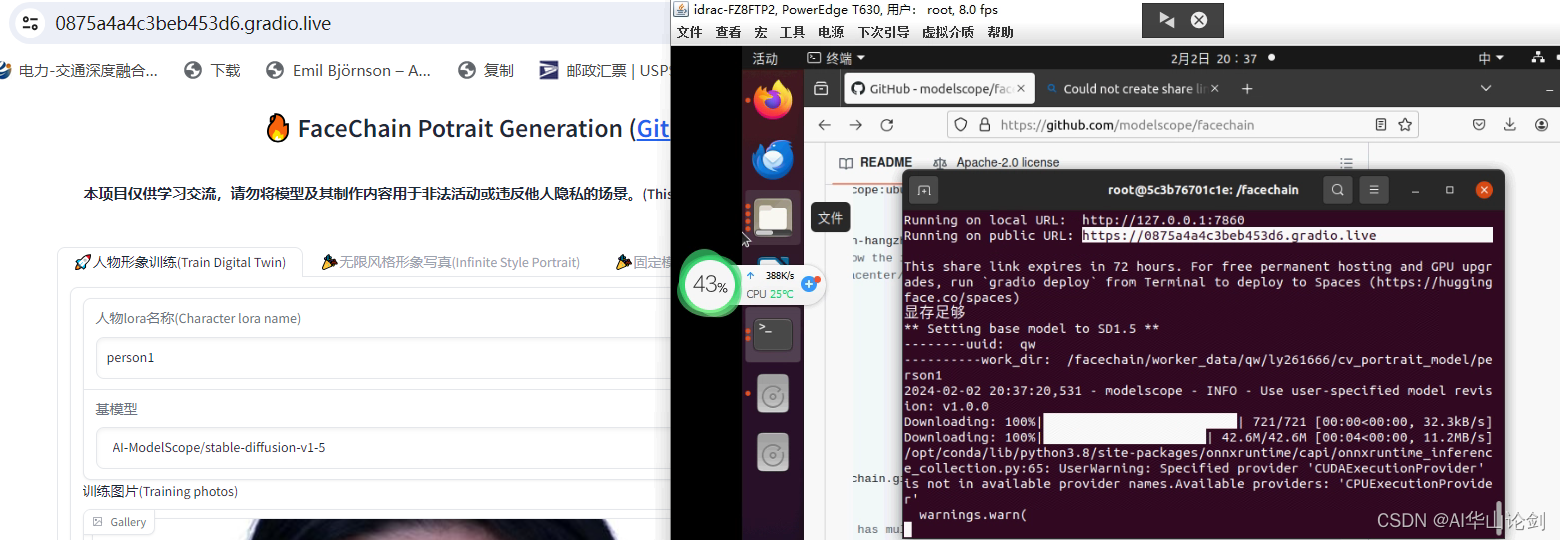
GitHub - modelscope/facechain: FaceChain is a deep-learning toolchain for generating your Digital-Twin.
1.需要docker支持GPU
sudo docker run --help | grep -i gpus | wc -L
# run the second instruction only if the output of the first instruction is equal to 0
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) && curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg && curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-docker2
sudo systemctl restart docker
sudo docker run -it --rm --gpus all ubuntu nvidia-smi
最后一句话不用执行
2.# For China Mainland users:我们执行:
docker pull registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.8.0-py38-torch2.0.1-tf2.13.0-1.9.43.这一步官方是这个命令,但这种情况智能gradio产生外链进行访问,无法访问docker内的127.0.0.1
# Step3: run the docker container
docker run -it --name facechain -p 7860:7860 --gpus all registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.8.0-py38-torch2.0.1-tf2.13.0-1.9.4 /bin/bash如果要本地也能访问127.0.0.1:7860,要执行如下代码:
docker run -it --name facechain --network host -p 7860:7860 --gpus all registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.8.0-py38-torch2.0.1-tf2.13.0-1.9.4 /bin/bash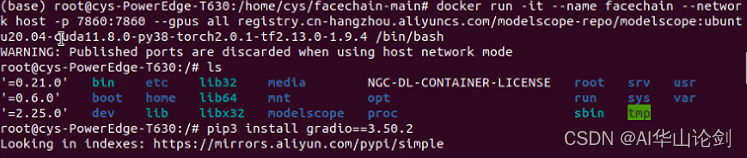
这一步如果说已经存在facechain容器,那就docker ps -a看看,存在的话,
那就docker close facechain
docker rm facechain,然后再执行一下step3
或者systemctl restart docker,需要稍微等等
4.进到docker里,执行
# Step4: Install the gradio in the docker container:
pip3 install gradio==3.50.2
pip3 install controlnet_aux==0.0.6
pip3 install python-slugify
pip3 install onnxruntime==1.15.1
pip3 install edge-tts
pip3 install modelscope==1.10.0# Step5 clone facechain from github
GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
cd facechain
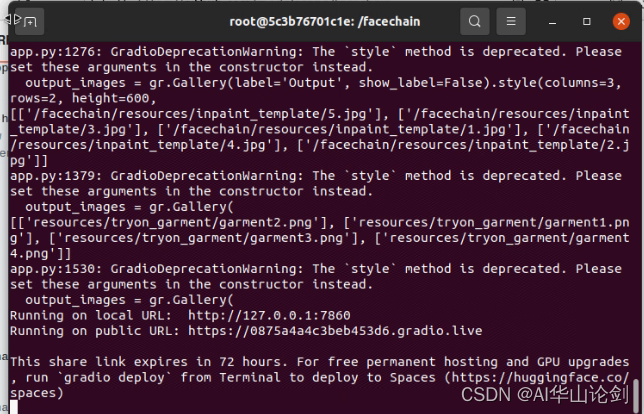
CUDA_VISIBLE_DEVICES=0 python3 app.pyCUDA_VISIBLE_DEVICES=0 python3 app.py
不知道为什么,使用python3 app.py程序一开始是起得来的,但是之后训练汇报训练失败的错误,然后就会显示在四张卡上都错误,可能是我过程中 CUDA_VISIBLE_DEVICES=0,1,2,3了,但是后面我清空掉docker,按理说不该默认四卡调的,后面看到有说法这LDM主要是循环迭代耗时,放多卡意义不大,所以还是单卡了。这个错误排查了一个晚上和一个上午才搞定
使用 CUDA_VISIBLE_DEVICES=0 python3 app.py是没有问题的!
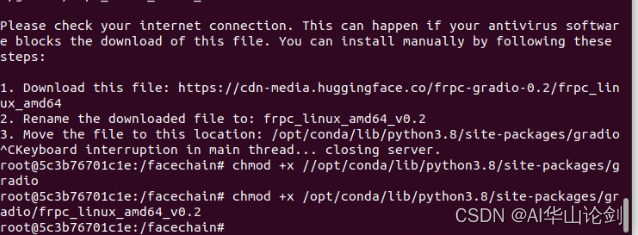
会报没有share link,缺文件,下载一下
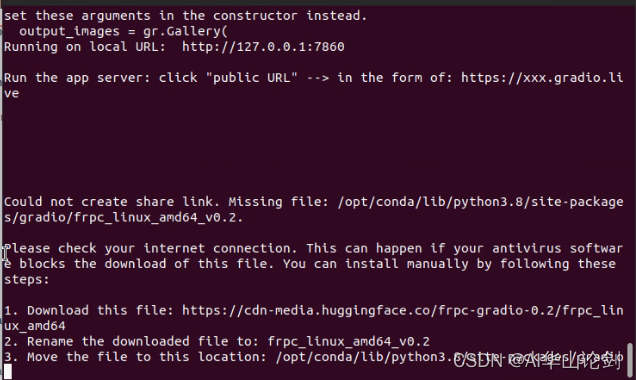
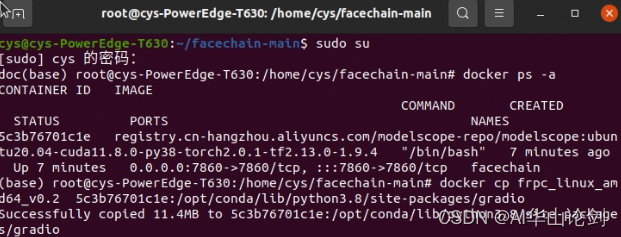
下载一下frpc_linux_amd64,改名字为frpc_linux_amd64_v0.2,
然后docker cp frpc_linux_amd64_v0.2 <container名字>:/opt/conda/lib/python3.8/site-packages/gradio,
还需要赋权限:chmod +x /opt/conda/lib/python3.8/site-packages/gradio/frpc_linux_amd64_v0.2