目的:查询数据1和数据2中,red与red列相同 并且blue与blue列相同的,情况有多少。
(备注:两个数据中格式不一致,需要经过json提取等处理步骤)
思路步骤:
1、读取数据1,筛选需要的行,从expert_reco_num_stage_5 (json)提取red和blue数据,做为结果A
2、读取数据2,也提取red和blue数据,格式和上面一样(便于比较),作为结果B
3、A、B用指定列进行左连接,最终查询A和B中的red和blue是一样的数量有多少
步骤
- 1、获得结果A
- 1-1 读取数据并筛选,查看expert_reco_num_stage_5 格式
- 1-2 提取red和blue作为新列,备用,得到结果A
- 2、获得结果B
- 2-1 读取数据,查询相应列格式
- 2-2 提取red和blue作为新列,备用,得到结果B
- 3、统计结果
- 3-1 左连接
- 3-2 统计结果
1、获得结果A
1-1 读取数据并筛选,查看expert_reco_num_stage_5 格式
import pandas as pd
import json# 读取智能大师号码信息
path1 = r'./expert_recommend (1).csv'
df_data = pd.read_csv(path1)# 筛选数据 : lottery_id是1001 并且recommend=1 的
data_ssq = df_data[(df_data['lottery_id']==1001) & (df_data['recommend']==1)].reset_index() # 重置索引# 查看数据
print(data_ssq[['expert_id','issue_no','expert_reco_num_stage_5']].head())
data_ssq['expert_reco_num_stage_5'][0]

1-2 提取red和blue作为新列,备用,得到结果A
# 每次针对一种key进行提取,并 按升序排序后,重新形成字符串
# 参数:
# thecolume 对应的json列,
# color指要处理的key,即red或blue,不传默认取red
def getnum_ssq(thecolume, color): # 字符串处理one_data=eval(thecolume) # 获取要处理的keykey1 = ''if one_data.get(color): # 如果color有值,则取colorkey1=colorelse:key1='red'# print('key1:',key1)# pd.json_normalize() 提取json中的指定key# 提取并按照升序排序(axis=0按照数据大小排序;=1按照索引中数据大小排序)expert_num_1 = pd.json_normalize(one_data.get(key1)).sort_values(by='$numberInt', axis=0, ascending=True) expert_num_list1 = expert_num_1.values.tolist() # 转为list# 列表保存值list_t = []for i in range(expert_num_1.shape[0]):list_t.append(expert_num_list1[i][0]) # 因为结果只有1列# print(list_t)# 列表内容用逗号连接,转成字符串expert_num1_res = ','.join(list_t)return expert_num1_res# 处理结果作为新的一列,结果A
# 注意此数据中如果真实数据是4,4,5,表中只会存 4,5,即red中不会出现相同的数字,blue一样
data_ssq['num5_red'] = data_ssq['expert_reco_num_stage_5'].apply(lambda x: getnum_ssq(x, 'red')) # reco_issue_no为文章预测的期次号
data_ssq['num5_blue'] = data_ssq['expert_reco_num_stage_5'].apply(lambda x: getnum_ssq(x, 'blue')) # reco_issue_no为文章预测的期次号
# data_ssq.head() # 结果A
# 查看第一条expert_reco_num_stage_5的处理结果
print(data_ssq[['expert_id','issue_no','expert_reco_num_stage_5','num5_red','num5_blue']].iloc[0])

2、获得结果B
2-1 读取数据,查询相应列格式
path3 = r'./号码.csv'
kj_data_ssq = pd.read_csv(path3)
kj_data_ssq[['s_issue_no','s_result_area_1','s_result_area_2']].head()# red对应在area_1,blue在area_2
# 查看数据
print(kj_data_ssq['s_result_area_1'][0])
print(kj_data_ssq['s_result_area_2'][0])

2-2 提取red和blue作为新列,备用,得到结果B
# 功能:把字符串转为数组后,重新排序,形成新的字符串
# 参数:
# str1 字符串,是字符串类型的数值 03,19,02
# sep1 原来的分割符
# sep2 新字符串的分隔符def str_sort_2(str1, sep1, sep2): # 去除无用的0,利用int类型a = str1.split(sep1)b = [int(x) for x in a]list1 = [str(x) for x in b]# 注意:结果A中,如果是4,4,5,表中只会存 4,5。为了和 结果B便于比较,结果B也要做类似处理list2 = list(set(list1)) # 利用集合去重list2.sort() # 升序排序,可以改变源数据,降序时设置 reverse=Truestr2 = sep2.join(list2)return str2print('函数测试:',str_sort_2('03,2,6,3,8', ',', ','))# 号码排序,统一为str类型
# red、blue提取(s_result_area_2只有一个,只要也转换成字符串即可)
kj_data_ssq['win_number_red_res'] = kj_data_ssq['s_result_area_1'].apply(lambda x : str_sort_2(x, ',', ','))
kj_data_ssq['win_number_blue_res'] = kj_data_ssq['s_result_area_2'].astype(str)# s_issue_no重命名为issue_no,便于和 后续连接时使用.永久修改
kj_data_ssq.rename(columns={'s_issue_no': 'issue_no'}, inplace=True) # rename可以在修改部分列时使用# 查看结果B
kj_data_ssq[['s_result_area_1','s_result_area_2','win_number_red_res','win_number_blue_res','issue_no']].head()

3、统计结果
3-1 左连接
merge_ssq = pd.merge(data_ssq, kj_data_ssq, how='left', on='issue_no')# 筛选出 两者相同/不同 的 df[df['某一列'] != df['某一列']]
# merge_ssq[merge_ssq['num5_new'] == merge_ssq['win_number_res']]
# merge_ssq
3-2 统计结果
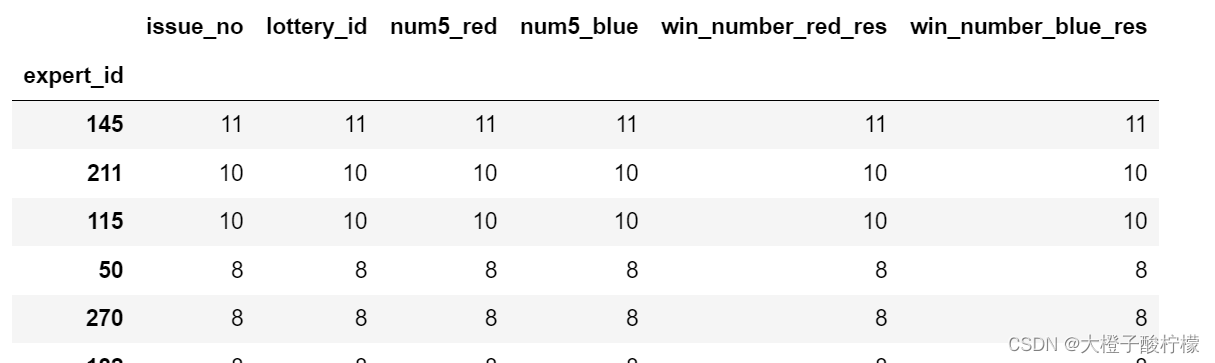
# 查找哪个expert_id的"红球一样,蓝球也一样"这种数据最多
find_ssq = merge_ssq.loc[ (merge_ssq['num5_red'] == merge_ssq['win_number_red_res']) & (merge_ssq['num5_blue'] == merge_ssq['win_number_blue_res']),['expert_id', 'issue_no', 'lottery_id', 'num5_red', 'num5_blue', 'win_number_red_res', 'win_number_blue_res']]res3 = find_ssq.groupby(by='expert_id').count()
res3.sort_values(by='lottery_id', ascending=False)