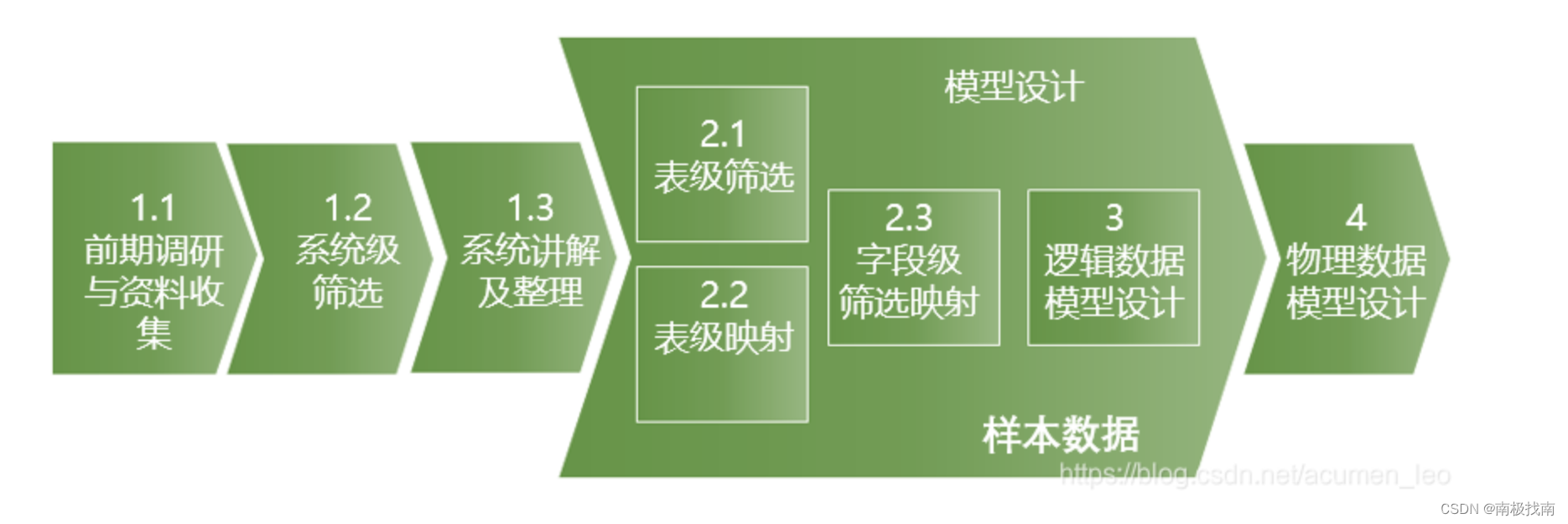
主数据区域中保留了数据仓库的所有基础数据及历史数据,是数据仓库中最重要的数据区域之一,那主数据区域中主要分为近源模型区和整合(主题)模型区。上一节讲到了模型的设计流程如下图所示。那近源模型层的设计在第2.3和3这两个步骤中相对简化,模型表设计的结构同源系统的表结构,字段也一一映射即可。那下面以整合(主题)模型的设计步骤来进行介绍:
整合(主题)模型层主要按主题进行数据整合,以第3范式为主进行表设计,有以下优点:
(1)主题模型从全行角度对客户、产品、交易、账户等进行分类梳理,获得全行业务数据视图;
(2)数据模型比较稳定,只要业务实体关系没有大的变化,不会因为源系统替换或升级导致整合模型出现大的变动。对于数据使用系统和集市来说比较稳定。
(3)模型灵活易扩展,在增加功能的时可扩展模型,不需要重构数据模型,不影响已有数据实体。
当然主题模型梳理设计比较耗费人力,同时规则需要全行认可,需要由一个管理全行数据的业务部门来统筹,可以和数据治理项目一起进行,将数据治理的数据标准等成果在数据仓库主题模型进行落地。
1、主题模型设计步骤
1.1系统调研及筛选
(1)前期调研与资料收集:调研全行或全公司的系统,从架构、业务数据及流程方面概略了解系统,需要和架构师、各系统负责人进行前期调研沟通,获取系统说明书、表结构、主要流程说明等资料。
(2)系统级筛选:确定需要入数据仓库的系统范围,筛选条件主要考虑系统是否自己产生业务数据或者是业务流程中的一个部分,另外也考虑以下几方面:
1)系统是否很快会被其他系统替代,是的话需要考虑对接新系统;
2)系统数据结构现阶段是否稳定,业务是否有大改造,是的话可以考虑改造完接入;
3)系统与其他系统的关系,是否关联系统也需要入仓;
4)分布式系统是否数据结构统一,业务全流程包括哪些系统;
5)纯外购系统是否能够得到提供商的支持,因为需要供应商配合调研和分析;
(3)系统讲解及整理:
确定入仓的系统后需要与系统负责人进行深入的调研和数据分析,主要步骤包括:
1)系统整体调研:包括系统整理介绍、系统在行内的架构定位、主要功能、和其它系统的上下文关系、以及重要的业务流程和业务规则,同时也要了解系统夜间的切日和日终处理情况,便于后续系统数据采集,那最后产出物为详细的《XX系统调研报告》,同时也需要获取源系统的数据库设计文档及数据字典,建立和源系统调研问题跟进机制。
1.2确定入仓表及字段
(1)系统数据表筛选映射、代码整理:
根据系统数据字典中的表清单进行各个表的功能、数据进行梳理,并确定是否入主数据区(入仓),同时对于确定入仓的表进行主题模型映射和代码字段的整理。那对于表是否入仓主要了解表中数据的业务含义,同时尽量保留粒度比较细的数据。那对于以下情况的表可以不进行入仓:
1)系统控制类和业务流程控制类表:如系统中的序号生成器、系统开门时间、批处理控制表、数据包接收和拆分的记录;
2)为未来业务拓展预留的表:部分业务系统设计了一些目前尚未开展的业务数据表;未来的业务规则和处理流程存在不确定性,因此暂不入仓。可以在未来进行扩展和补充;
3)中间表和临时表:在源业务系统中记录业务操作中间状态的表;
4)统计和报表类数据:部分系统中有大量的统计或报表类数据,可以使用入仓的明细数据在明确的逻辑和规则下自行进行加工;
5)数据备份表:一般情况下,数据备份表不入仓;
那本步骤产出结果为《XX系统表清单分析》及《XX系统代码整理》,以下参考模板:

(2)字段级筛选映射
该步骤主要分析,逐一调研分析数据库表中每个栏位的业务含义,向业务及源系统人员了解并使用样本数据确认数据质量和数据信息,并确定是否入整合模型。一般近源模型层除了敏感字段、二进制字段外会全部入仓,整合模型除了这两类还会进行筛选,一般以下类型字段也不进入整合模型:
1)无分析意义的字段:加载时间戳,密码
2)业务系统操作流程相关字段:下一打印行数,当前页号,帐页打印标志、批处理标志,
3)中间计算结果字段:积数,本月累计积数,本期累计贷方发生额
4)未启用字段:预留字符,预留数值、全空值字段
5)长文本信息,需要明确业务上不使用的舍弃:备注,经办人,批准人
6)冗余字段:活期账户中的客户名称,行业类型,经济性质
那对确定入仓的字段需要进行数据范围以及关联字段(主外键)分析,看是否符合调研信息,对异常数据需要进行跟进分析,确定原因。这部分工作需要源系统人员在生产环境配合跑验证SQL。最终产出物为《XX系统字段分析》、《XX系统字段数据质量调研》。

1.3逻辑模型设计
逻辑数据模型(Logical Data Model)是一种图形的展现方式,采用面向主题的方法有效组织来源多样的各种业务数据,全面反映银行复杂的业务规则,它使用统一的逻辑语言描述银行业务,通过实体和关系勾勒出企业的数据蓝图。有实体、属性、关系概念,每个主题都是由多个表来实现的,表之间依靠主题的公共码键联系在一起,形成一个完整的主题。逻辑模型设计工具有商用的EWIN、POWERDESIGN等,目前开源的也有些,但功能和体验稍差些。
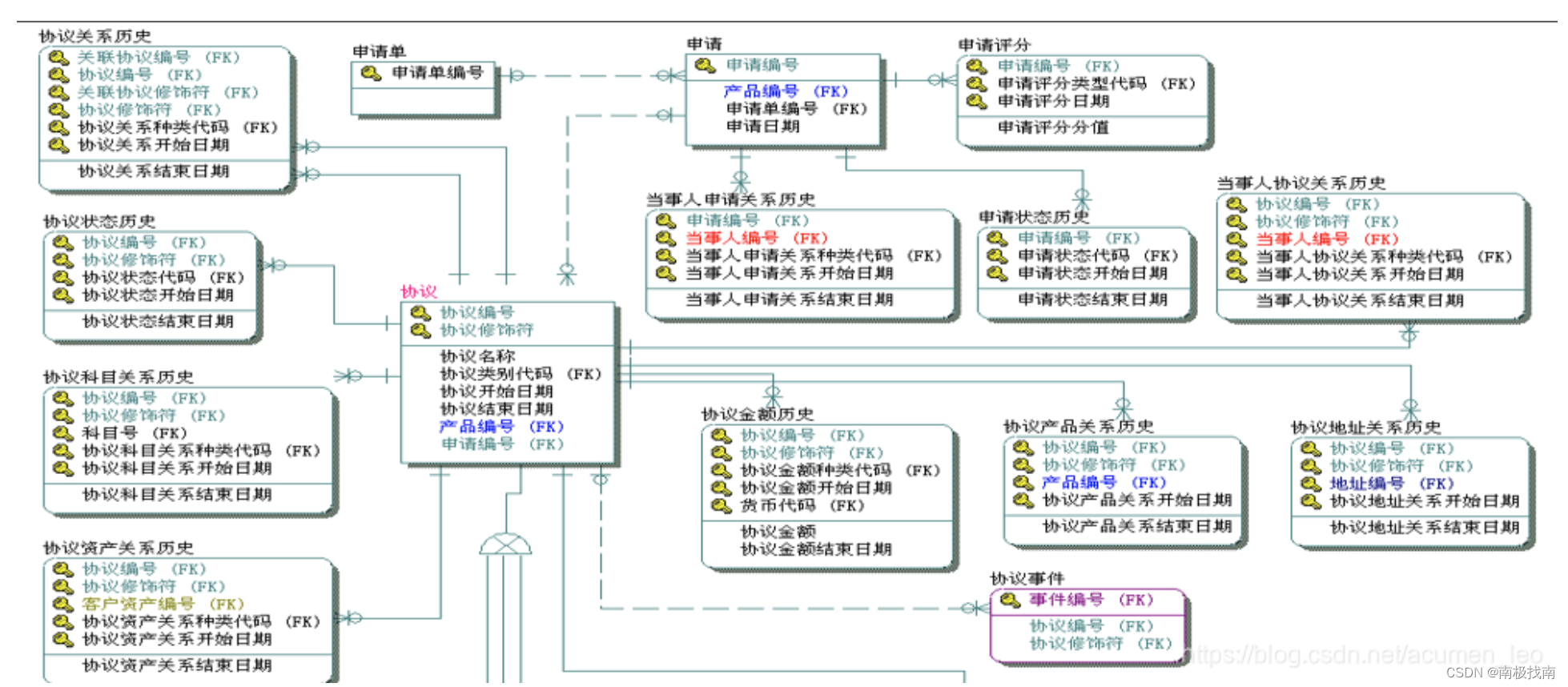
那逻辑模型设计可以由2种路径,一是银行根据以往的业务经验提炼本行业务的关键主题,设计出本行的概念模型;二是依托成熟产品进行客户化,即根据一些数据模型实施公司的产品针对本行实际数据情况进行适应。许多行使用第二种方式,速度较快,项目风险小。那基于已有成熟产品的方案在项目初期就需要选择好模型产品,一般可以调研其它行的模型落地情况,在我国银行落地实施较多的产品一般成熟度较高,适用性也经得起实战。那逻辑模型的客户化主要有以下步骤:
(1)业务定义整合:主要包括客户识别、产品定义、内部机构等。客户识别整合即整合各系统客户信息,定义唯一客户号,识别同一客户。产品定义即在全行角度设置一套产品树并赋予唯一编号,内部机构也是确定一套内部机构,同时各系统的产品、内部机构都能映射到全行定义的产品和内部机构中。
(2)确定各主题准入、分类、数据整合、历史处理的主题设计原则,比如客户分类包括对公、对私、同业等,历史数据采用拉链方式;
(3)基于字段级映射的产出,根据主题设计原则再次检视各主题梳理入仓字段的所属主题以及模型中的实体关系是否和源系统实体关系一致,然后将字段映射或新增到现有的主题基础模型中。
(4)代码整合:需要根据入仓的代码字段整合一套数仓的标准代码,并确定各系统代码字段映射到数仓标准代码的规则。一般这个工作也是数据治理数据标准的部分内容,最好先确定全行数据标准,以它作为数仓的代码标准基础并进行补充。
(5)模型评估和验证:通过REVIEW会议由各主题设计人员进行主题设计的讲解,由模型组人员进行模型架构、业务规则、实体关系等方面进行评审,修正。模型的验证是一个持续的过程,特别是在提供数据给应用系统以及数据集市后,还会发现设计的问题,因此需要定期总结和优化。
1.4物理模型设计
逻辑模型适用于多个数据库实现,也就是可以有多个物理模型。物理模型设计主要将逻辑模型转化成可具体实施的数据表及关系并优化应用设计,优化存储以及提高数据访问效率,主要考虑点有:
(1)考虑删除没有数据来源的实体和属性,增加公共字段如数据新增和修改日期。
(2)考虑删除只有主键的实体,对于表较少的表或主题考虑合并到其它表或主题中,如渠道主题表和字段较少,可以考虑合并。
(3)选择和调整主索引和分区字段,使数据均匀分布,提高性能。
(4)对重要主题域的关键实体给予更多关注,一般客户、协议、事件会占用80%的数据空间,需要重点关注这几个主题的设计,如对事件表和近源层对应源表变化不大,可按视图实现,节省空间。
(5)根据应用需求和关键字段适当增加关键的冗余字段(反范式),提高数据访问效率,比如在客户主表、协议主表增加常用查询字段的冗余可以减少关联,提高效率。
(6)考虑大表的分拆和多表的合并,提高效率。
(7)确定字段的英文命名和数据类型,按命名规范对模型字段、索引、表等进行命名。特别对于字段长度和精度,物理模型中的字段设计比源系统要长,需要考虑后续的扩展,因为源系统经常会增加字段长度或精度,在物理模型中需要提前考虑,以免后续影响数据使用系统。
(8)分区、压缩和其它类索引:需要对常用的查询字段或条件建立索引,提高查询效率。
基于逻辑模型生成的物理表,并考虑上述优化点,可以得到最终的数据仓库主题模型的物理模型并进行后续维护优化。
版权声明:本文为acumen_leo博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/acumen_leo/article/details/95670279