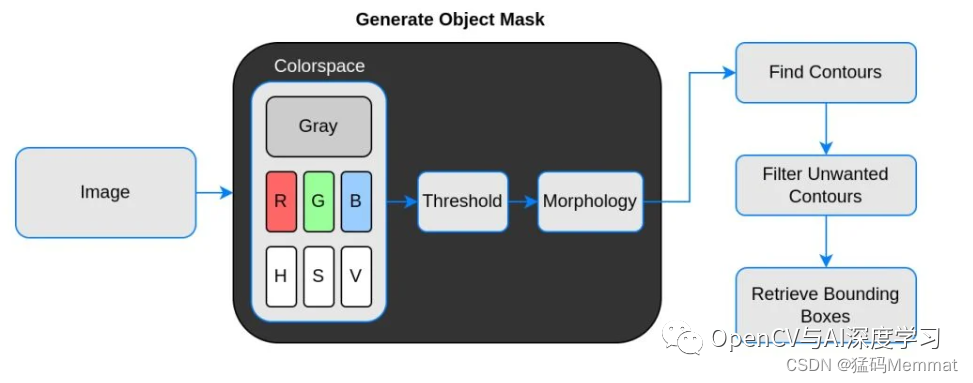
简介:
前两天,TaoTao发布了一篇关于“获取抖音评论”的文章。但是之前的那一篇包涵的代码呢仅仅只能获取一级评论。虽然说抖音的一级评论挺精彩的了,但是其实二级评论更加有意思,同时二级评论的数量是很多。所以二级评论是非常值得我们关注的。因此TaoTao花了一些时间写了一下这块的代码。接下来就让TaoTao带着大家来看一下整个过程是怎样的吧!
视频讲解如下:
【爬虫实战】全过程详细讲解如何使用python获取抖音评论,包括二级评论
环境:
代码执行环境如下:
Vscode
Windows10
Anaconda
request
csv
fake_useragent
需要执行代码的同学,按照上面的环境检查自己的环境。如果不满足的话,安装一下即可。安装方法,也很简单,pip安装指定的库。如果因为网络的原因没有办法安装,使用清华镜像站进行安装即可。
安装命令如下:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple fake_useragent
代码执行:
首先需要登录到抖音,注意这里是需要登录的哦,不然获取不到cookie值。
然后点击评论区,之后我们再按F12,接着再将评论区往下拉。看到list/?/device_platform
这个文件,就可以了。然后点击Preview中的任何一个comments。可以看到这里就有aweme_id的字段,然后给这个复制下来。
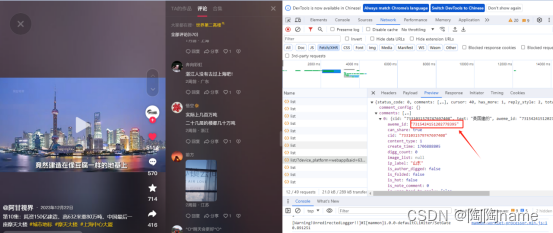
复制下来以后,就可以给这个数据粘贴到代码中的aweme_id了,具体如下:
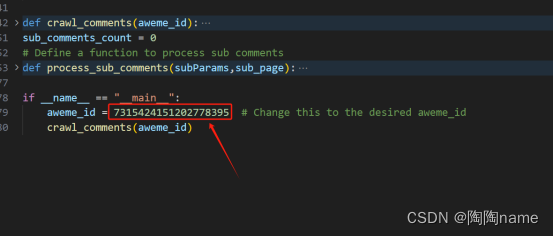
同样的方法,还需要给cookie的值替换成自己的。
Cookie值获取的方式,依然是在list/?/device_platform文件中找,但是它是在Headers中,具体的如下图所示:
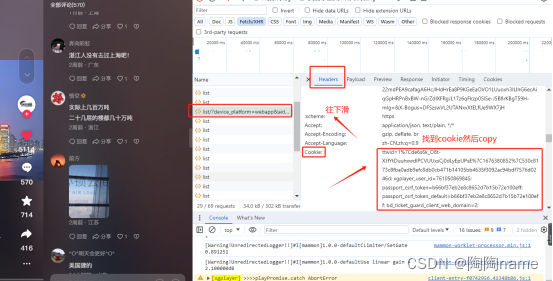
获取到了这个值以后呢,需要给这个cookie的替换到代码中,具体替换位置如下所示:
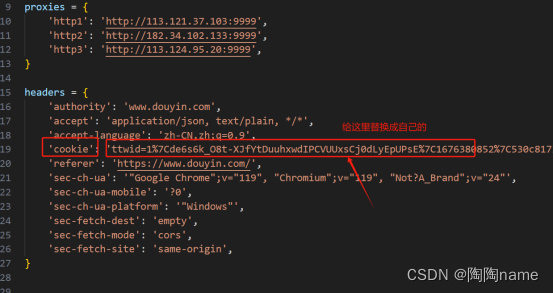
完成了上述的操作以后,就可以Run代码了。还是需要提一嘴,Run代码的方式大体上就两种,一种是在idea中如:pycharm中直接点击Run键;另外一种就是我下面的方式,直接在命令行中使用命令的方式执行。执行命令:python douyinSecondComments.py
执行过程如下所示:
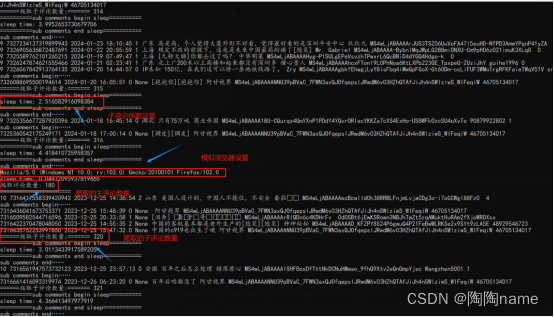
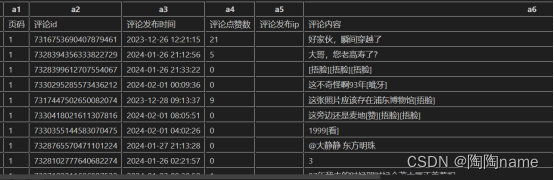
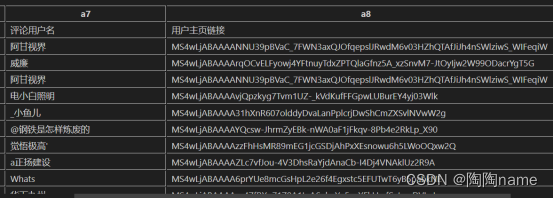
最终的数据如下所示:
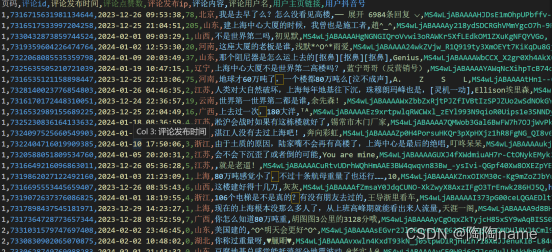
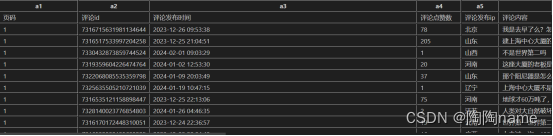
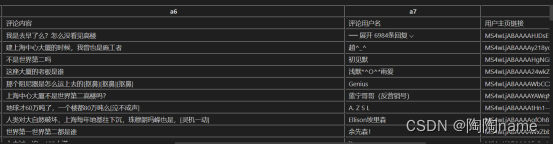
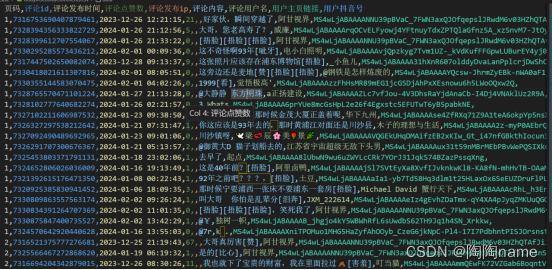
主要包括:‘页码’, ‘评论id’, ‘评论发布时间’,‘评论点赞数’,‘评论发布ip’, ‘评论内容’,‘评论用户名’,‘用户主页链接’,‘用户抖音号’
详细如下所示:
主评论:
子评论:
代码讲解:
我们可以看到,终端命令行中的输出信息有很多,具体上可以分为两类:一类是评论信息,这里的话主要就是:主评论还有子评论了。另一类就是一些相关信息的输出,主要是:浏览器的模拟,还有就是休眠。至于为什么要模拟浏览器以及设置主、子评论的休眠,主要是为了防止被反爬。
然后代码设置的话,如下所示:
user_agent = UserAgent() random.seed() headers['user-agent'] = user_agent.random response = requests.get(url, params=params, headers=headers, proxies=proxies)print(headers['user-agent']) sleep_time = random.uniform(0, 5) print("sleep time:", sleep_time) print("爬取评论数量:", comments_count) print("======================") time.sleep(sleep_time)
同时,我们从抖音请求到的数据时间,是一个时间戳,所以我这里又写了一个将时间戳转换成普通时间的代码,具体如下所示:
def timestampToNormalTime(timestamp):return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(timestamp))
然后就是数据的持久化保存了。持久化的方式有很多:比如数据库、文件保存等等。我这里采用的就是直接保存在csv中。因为这样的话,在后续的数据可视化使用是非常方便的。
使用csv保存呢,主要分为两步,一步是进行csv文件的创建,另一个就是对csv文件的数据追加。具体的代码如下所示:
with open("douyinComments.csv", mode="a", newline='', encoding="utf-8-sig") as f:csv_write = csv.writer(f)csv_write.writerow(['页码', '评论id', '评论发布时间','评论点赞数','评论发布ip', '评论内容','评论用户名','用户主页链接','用户抖音号'])with open("douyinSecondComments.csv", mode="a", newline='', encoding="utf-8-sig") as f:csv_write = csv.writer(f)csv_write.writerow(['页码', '评论id', '评论发布时间','评论点赞数','评论发布ip', '评论内容','评论用户名','用户主页链接','用户抖音号'])with open("douyinComments.csv", mode="a", newline='', encoding="utf-8-sig") as f:csv_write = csv.writer(f)csv_write.writerow([page, cid, create_time, digg_count, ip_label, text, nickname, sec_uid, unique_id])with open("douyinSecondComments.csv", mode="a", newline='', encoding="utf-8-sig") as f:csv_write = csv.writer(f)csv_write.writerow([sub_page,cid,create_time,digg_count,ip_label,text,nickname,sec_uid,unique_id])更加详细的讲解请看上面的视频!
源码链接:【爬虫实战】全过程详细讲解如何使用python获取抖音评论,包括二级评论
由于笔者能力有限,在某些表述方面难免有些不准确,还请多多包涵!


![详解洛谷P2912 [USACO08OCT] Pasture Walking G(牧场行走)(lca模板题)](https://img-blog.csdnimg.cn/direct/b373e33186b043ac86e3a7a5566a4a7f.png)