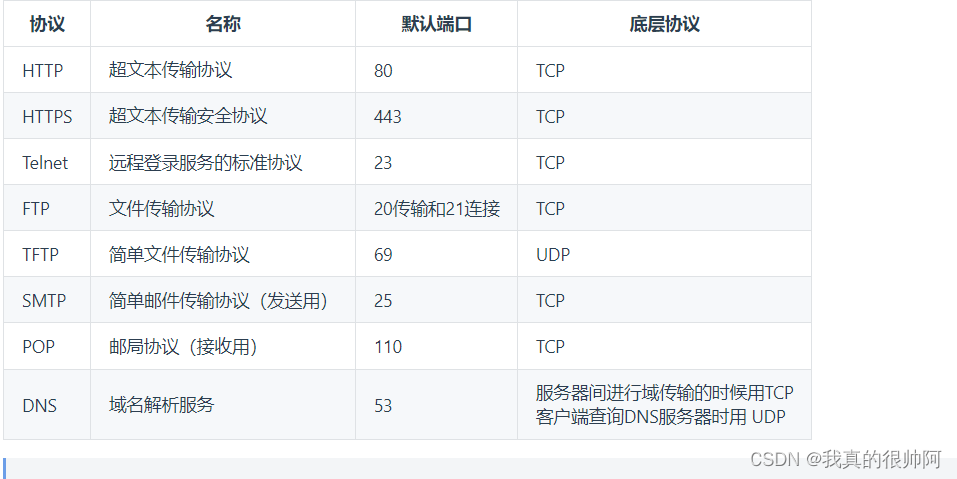
支持向量机(Support Vector Machine,SVM)是一个非常优雅的算法,具有非常完善的数学理论,常用于数据分类,也可以用于数据的回归预测中。支持向量机在许多领域都有广泛的应用,如文本分类、图像识别、生物信息学、金融预测等。
支持向量机的应用:
(1)文本分类:支持向量机可以用于文本分类任务,如垃圾邮件过滤、情感分析、主题分类等。通过对文本数据进行预处理,提取特征,然后使用支持向量机进行训练和预测,可以实现对文本数据的自动分类。
(2)图像识别:支持向量机可以用于图像识别任务,如手写数字识别、人脸识别、物体检测等。通过对图像数据进行预处理,提取特征,然后使用支持向量机进行训练和预测,可以实现对图像数据的自动识别。
(3)生物信息学:支持向量机在生物信息学领域有广泛应用,如基因表达数据分析、蛋白质结构预测、药物设计等。通过对生物数据进行预处理,提取特征,然后使用支持向量机进行训练和预测,可以帮助研究者发现新的生物学知识。
(4)金融预测:支持向量机可以用于金融预测任务,如股票价格预测、信用评分、风险评估等。通过对金融数据进行预处理,提取特征,然后使用支持向量机进行训练和预测,可以帮助投资者和金融机构做出更好的决策。
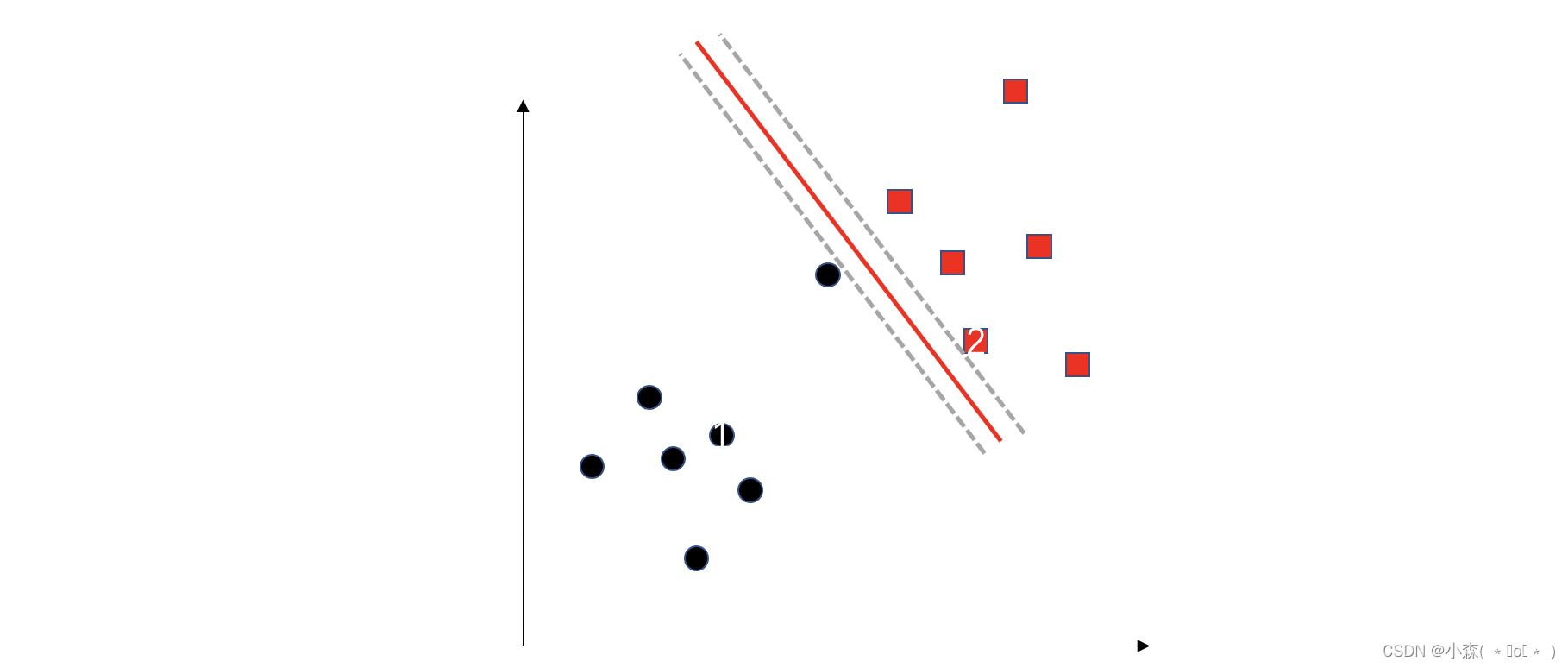
用一根棍分开不同颜色小球,在放更多球之后,仍然适用。
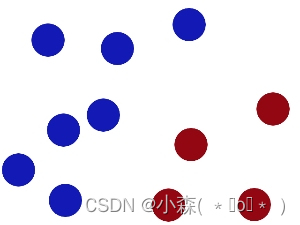
我们可以在中间斜放一根直线将其分开,随后又在桌上放了更多的球,有一个球站错了类别。
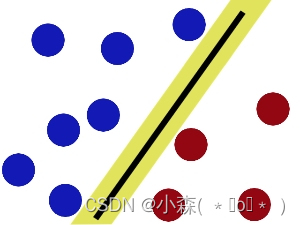
这样放置我们以后在加其他小球这依然是一个良好的分割线,因为我们有了容错的间隔(margin)。
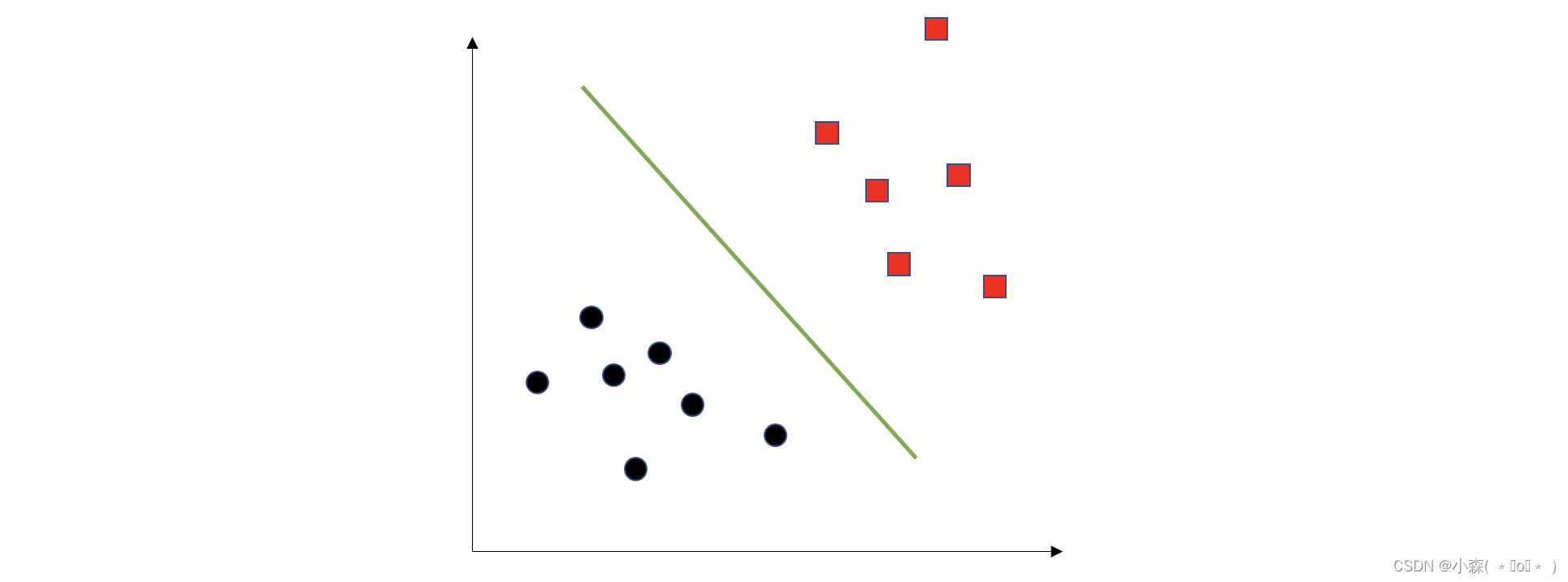
我们再改变小球的位置
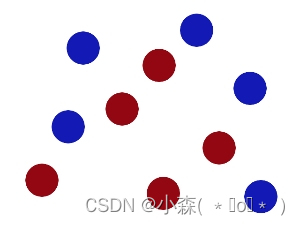
这样我们不能很好的分开两种球了,可以使用SVM,将维度提升
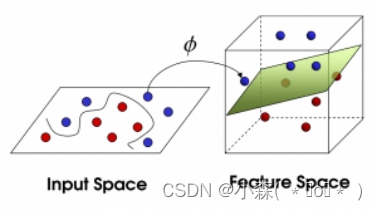
这样我们就可以通过svm分开两种类别。在 SVC 中,我们可以用高斯核函数来实现这个功能:kernel='rbf'
支持向量机的基本模型是定义在特征空间上的间隔最大的线性分类器。它是一种二分类的模型,当采用了核技巧之后,支持向量机可以用于非线性分类。
- 当训练数据线性可分的时候,通过硬间隔最大化,学习得到一个线性可分支持向量机。
- 当训练数据近似线性可分时,通过软间隔最大化,学习一个线性支持向量机。
- 当训练数据不可分的时候,通过使用核技巧以及软间隔最大化,学一个非线性支持向量机。
左图的边际不及右边的边际margin大,我们选择右边的图作为边界最好的划分。因为在有新的点出现的时候左边图的边际会错误分类一些点,而右侧就能很好的分类。
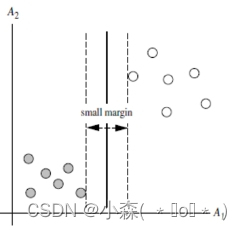
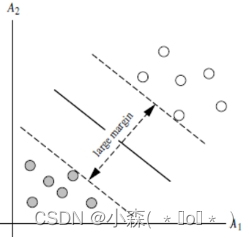
SVM学习的目的在于找到具有最大边缘的超平面。
SVM 是 N 维空间的分类超平面,它将空间切分成两部分。对于二维空间,它是一条线,对于三维空间,它是一个平面,对于更高维空间,它是超平面。
为了得到泛化性更好的分类器,分类平面应该应该不偏向于任何一类,并且距离两个样本都尽可能远,这种以最大化分类间隔为目标的线性分类器就是支持向量机。
硬间隔指的是让所有的样本都不在最大间隔之间,并位于正确的一边,如果出现异常值、或者样本不能线性可分,硬间隔无法实现。
软间隔指的是我们容忍一部分样本在最大间隔之内,甚至在错误的一边。软间隔可以应用在一些线性不可分的场景。
惩罚参数 C
C越大说明违反限制间隔的样本点带来的损失就越大,就要减少这些样本的数量,所以间隔就要越小。
C越小说明违反限制间隔的样本点带来的损失就越小,可以适当增大间隔,以增加模型的泛化能力。
Demo实践 我们利用sklearn直接调用 SVM函数进行实践尝试
库函数导入
import numpy as np ## 导入画图库
import matplotlib.pyplot as plt
import seaborn as sns## 导入逻辑回归模型函数
from sklearn import svm构建数据集并进行模型训练
x_fearures = np.array([[-1, -2], [-2, -1], [-3, -2], [1, 3], [2, 1], [3, 2]])
y_label = np.array([0, 0, 0, 1, 1, 1])## 调用SVC模型 (支持向量机分类)
svc = svm.SVC(kernel='linear')## 用SVM模型拟合构造的数据集
svc = svc.fit(x_fearures, y_label)模型参数查看
svc.coef_
svc.intercept_# [0.33364706 0.33270588]
# [-0.00031373]模型预测
y_train_pred = svc.predict(x_fearures)
y_train_pred# [0 0 0 1 1 1]可视化
x_range = np.linspace(-3, 3)w = svc.coef_[0]
a = -w[0] / w[1]
y_3 = a*x_range - (svc.intercept_[0]) / w[1]# 可视化决策边界
plt.figure()
plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis')
plt.plot(x_range, y_3, '-c')
plt.show()当存在线性不可分的场景时,我们需要使用核函数来提高训练样本的维度、或者将训练样本投向高维。
高斯核(RBF):一般是通过将样本投射到无限维空间,使得原来不可分的数据变得可分。
SVM 默认使用 RBF 核函数,将低维空间样本投射到高维空间。
支持向量机的总结:
优点:
- 可以解决高维数据问题,因为支持向量机通过核函数将原始数据映射到高维空间。
- 对非线性问题具有较好的处理能力,通过引入核函数,支持向量机可以处理非线性可分的数据。
- 鲁棒性较好,支持向量机只关心距离超平面最近的支持向量,对其他数据不敏感,因此对噪声数据具有较强的抗干扰能力。
缺点:
- 对于大规模数据集,支持向量机的训练时间较长,因为需要求解一个二次规划问题。
- 对参数和核函数的选择敏感,不同的参数和核函数可能导致模型性能差异较大,需要进行参数调优。
- 对于线性不可分的数据,需要引入核函数,但选择合适的核函数并不容易。
支持向量机是一种强大的机器学习算法,具有广泛的应用前景。在实际应用中,需要根据具体问题选择合适的核函数和参数,以达到最佳的预测性能。





![XCTF:warmup[WriteUP]](https://img-blog.csdnimg.cn/direct/33a1b03297744e6db6fddc3d3e739300.png)