1.什么是相关子查询
相关子查询是一个嵌套在外部查询中的查询,它使用了外部查询的某些值。每当外部查询处理一行数据时,相关子查询就会针对那行数据执行一次,因此它的结果可以依赖于外部查询中正在处理的行。
2.为什么要使用相关子查询
为什么相关子查询很关键呢?因为它解决了某些情况下group by所本身自带的一些限制——只能查询分组字段和聚合字段,但是有时候这些字段并不能够满足我们的需求,所以,需要用相关子查询来突破这样的限制
3.例题
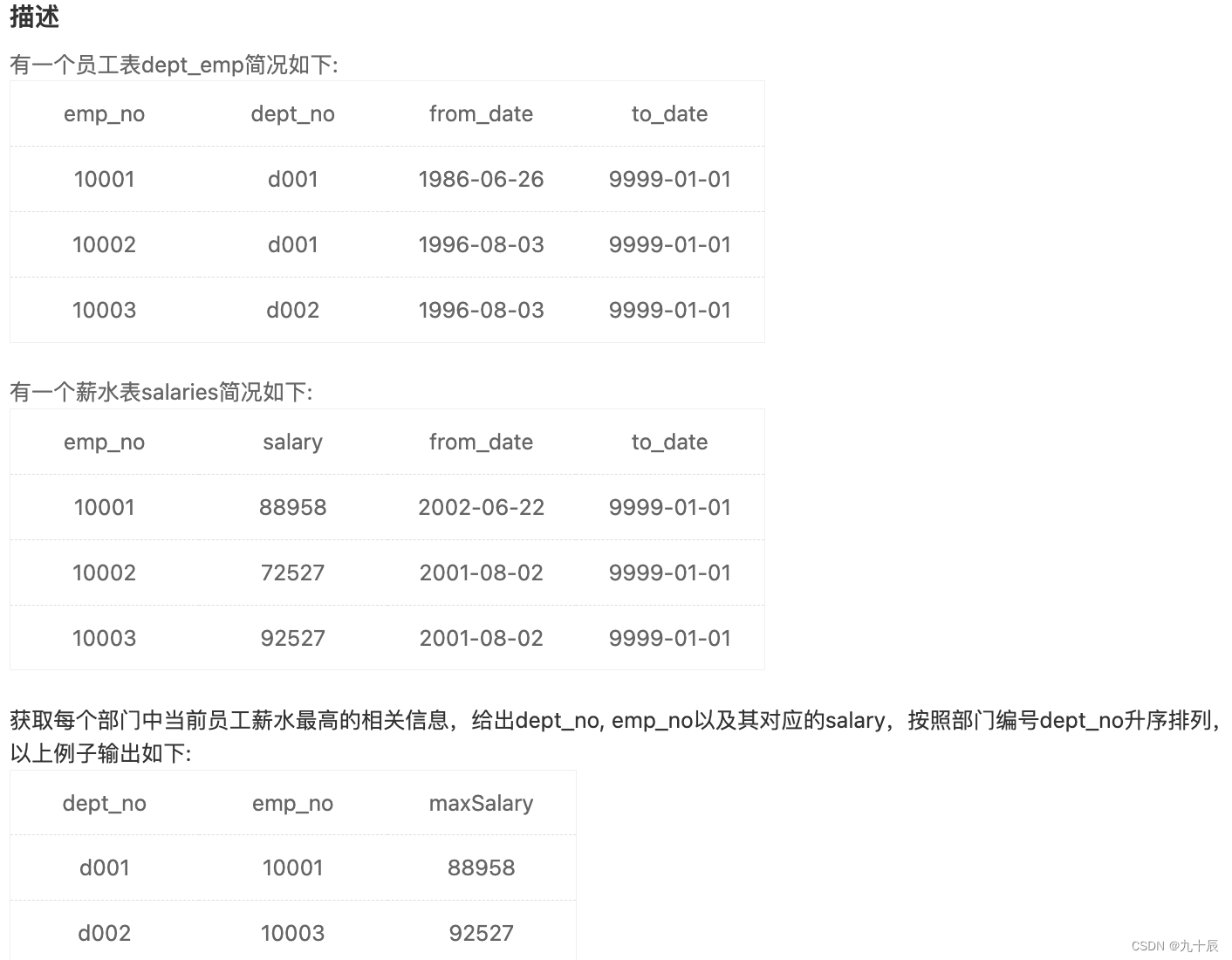
这个例题的最终需要获取的信息如果只是dept_no和maxSalary,那很简单了,只需要将两个表连起来,然后对部门进行分组,计算max(salary)就可以了,但是现在除了这两个字段之外还要求emp_no字段,这个字段不是分组字段,所以直接查询是不正确的,所以使用group by的方式是不成立的,就需要使用相关子查询
先上答案:
SELECT d1.dept_no, d1.emp_no, s1.salary
FROM dept_emp as d1
INNER JOIN salaries as s1
ON d1.emp_no=s1.emp_no
AND d1.to_date='9999-01-01'
AND s1.to_date='9999-01-01'
WHERE s1.salary in (SELECT MAX(s2.salary)FROM dept_emp as d2INNER JOIN salaries as s2ON d2.emp_no=s2.emp_noAND d2.to_date='9999-01-01'AND s2.to_date='9999-01-01'AND d2.dept_no = d1.dept_no --这里是关键
)
ORDER BY d1.dept_no;
在这个SQL例子中,子查询依赖于外层查询中的d1.dept_no值。
外层查询开始从dept_emp和salaries表进行内连接,基于emp_no和to_date字段。这个连接旨在选择每个员工的部门编号、员工编号和工资,但只限于当前有效记录,即to_date为'9999-01-01'的记录。
其where子句定义了查询的条件,在这个例子中,也就是说,每一行数据都要经过这个where的筛选,主查询的每一行都要依赖子查询。
那么!d1.dept_no就是外部主查询当前这一行数据的部门号,这个dept_no传到子查询中去,那么子查询在联表的时候,就只会联是这个部门号的数据行,所以子查询的联表得到的暂时表只是当前这一个部门的数据,没有其他部门的数据;并且主查询中有多少行数据需要用where筛选,子查询就会生成多少次暂时表,也就是说如果主查询中有10个同样dept_no的人,那么这个部门的薪资最高的这个值会被计算出10次(生成10次暂时表)
也就是说,内部的子查询通过在联表的条件中引用外部的主查询中的字段,实现了“外部固定dept_no,内部根据dept_no来操作”的效果
4.知识点归纳
- 对于外层查询的每一行结果,子查询(相关子查询)都会执行一次。
- 子查询可以使用外部查询中定义的任何字段,但是这些字段必须在子查询被引用时在外部查询中是可见的或者有效的。
- 相关子查询可能会导致性能问题,因为对于外层查询返回的每一行数据,数据库可能需要重新执行子查询。

![[opencvsharp]C#基于Fast算法实现角点检测](https://img-blog.csdnimg.cn/direct/6c1273dc2d514826b2c0623d9a60ca97.jpeg)