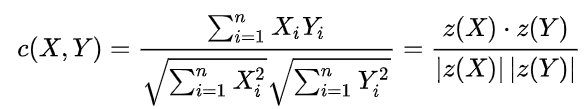实验资源
u.user
u.item
u.data
实验环境
VMware Workstation
Ubuntu 16.04
Jupyter Notebook
Pyspark
实验内容
本实验使用其中三个文件,用户信息、影片信息、评分数据
用户信息 (u.user)
| 用户id | 年龄 | 性别 | 职业 | 邮政编码 |
|---|---|---|---|---|
影片信息(u.item)
| 影片id | 影片名称 | 发行日期 | 链接 | other |
|---|---|---|---|---|
评分数据(u.data)
| 用户id | 影片id | 评分值 | 时间戳(UTC) |
|---|---|---|---|
根据读入的三个文件,利用协同过滤算法,向用户推荐电影 。
实验步骤
1、读取u.user,生成DataFrame,并创建临时表
#读取用户数据
user_df=spark.read.text('/home/test/u.user')
user_df.show(10)
#为用户数据添加 schema
from pyspark import Row
user_rdd=user_df.rdd.map(lambda x:x[0].split('|')).map(lambda x:Row(id=x[0],age=x[1],sex=x[2],job=x[3],code=x[4]))
user_rdd.take(5)
#创建用户 dataframe
user_df=spark.createDataFrame(user_rdd)
#注册临时表
user_df.registerTempTable("user")
spark.sql('select id,age,sex,job,code from user').show()

2、读取u.data,生成DataFrame,并创建临时表
#读取评分数据
rating_df=spark.read.text('/home/test/u.data')
rating_df.show(5)
#为评分数据添加 schema
rating_rdd=rating_df.rdd.map(lambda x:x[0].split()).map(lambda x:Row(user_id=x[0],film_id=x[1],rating=x[2],time=x[3]))
rating_rdd.take(5)
#创建评分 dataframe
rating_df=spark.createDataFrame(rating_rdd)
#注册评分临时表
rating_df.registerTempTable('rating')
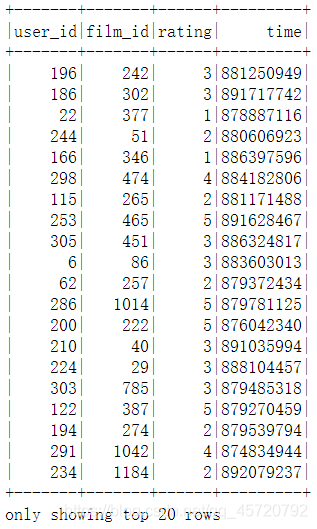
spark.sql("select user_id,film_id,rating,time from rating").show()
3、读取u.item,生成DataFrame,并创建临时表
#读取电影信息
film_df=spark.read.text('/home/test/u.item')
film_df.show(5)
#为电影数据添加 schema
film_rdd=film_df.rdd.map(lambda x:x[0].split('|')).map(lambda x:Row(id=x[0],title=x[1],post_time=x[2],url=x[4]))
film_rdd.take(5)
#创建电影 dataframe
film_df=spark.createDataFrame(film_rdd)
#注册电影临时表
film_df.registerTempTable('film')
spark.sql('select * from film').show()

4、利用协同过滤算法进行电影推荐
#导入 Spark 机器学习包:协同过滤算法
from pyspark.mllib.recommendation import ALS
#ALS.trainImplicit中第一个参数RDD是固定格式(用户编号,电影编号,评分值)
rdd=rating_rdd.map(lambda x:(x[3],x[0],x[1]))
rdd.take(5)
#训练模型
model=ALS.train(rdd,10,10,0.01)
#使用模型进行推荐,参数为用户 id,推荐个数
user_film=model.recommendProducts(112,3)
print(user_film)
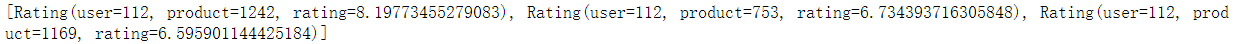
#显示推荐电影名称
for film in user_film:spark.sql("select id,title,post_time,url from film where id = "+str(film[1])).show()

#查看用户看过的电影
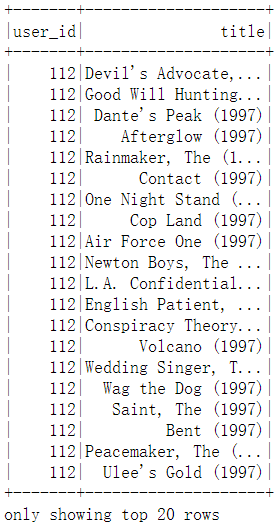
spark.sql("select a.user_id,b.title from rating a,film b where a.film_id=b.id and a.user_id=112").show()
#查看用户看过的电影
spark.sql("select a.user_id,b.title from rating a,film b where a.film_id=b.id and a.user_id=112").show()