事务隔离级别
我们知道 MySQL 是一个 C/S 架构的服务,对于同一个服务器来说,可以有多个客户端与之连接,每个客户端与服务器连接上之后,就是一个会话( Session )。每个客户端都可以在自己的会话中向服务器发出请求语句,一个请求语句可能是某个事务的一部分,也就是对于服务器来说可能同时处理多个事务。在事务简介的章节中我们说过事务有隔离性的特征,理论上在某个事务对某个数据进行访问时,其他事务应该进行排队,当该事务提交之后,其他事务才可以继续访问这个数据。但是这样子的话对性能影响太大,我们既想保持事务的隔离性 ,又想让服务器在处理访问同一数据的多个事务时性能尽量高些。在Mysql中,设计有多种不同的隔离级别,不同级别下对应的性能有所差异。
事务并发执行遇到的问题
我们先得看一下访问相同数据的事务在不保证串行执行(也就是执行完一个再执行另一个)的情况下可能会出现哪些问题:
- 脏写( Dirty Write )
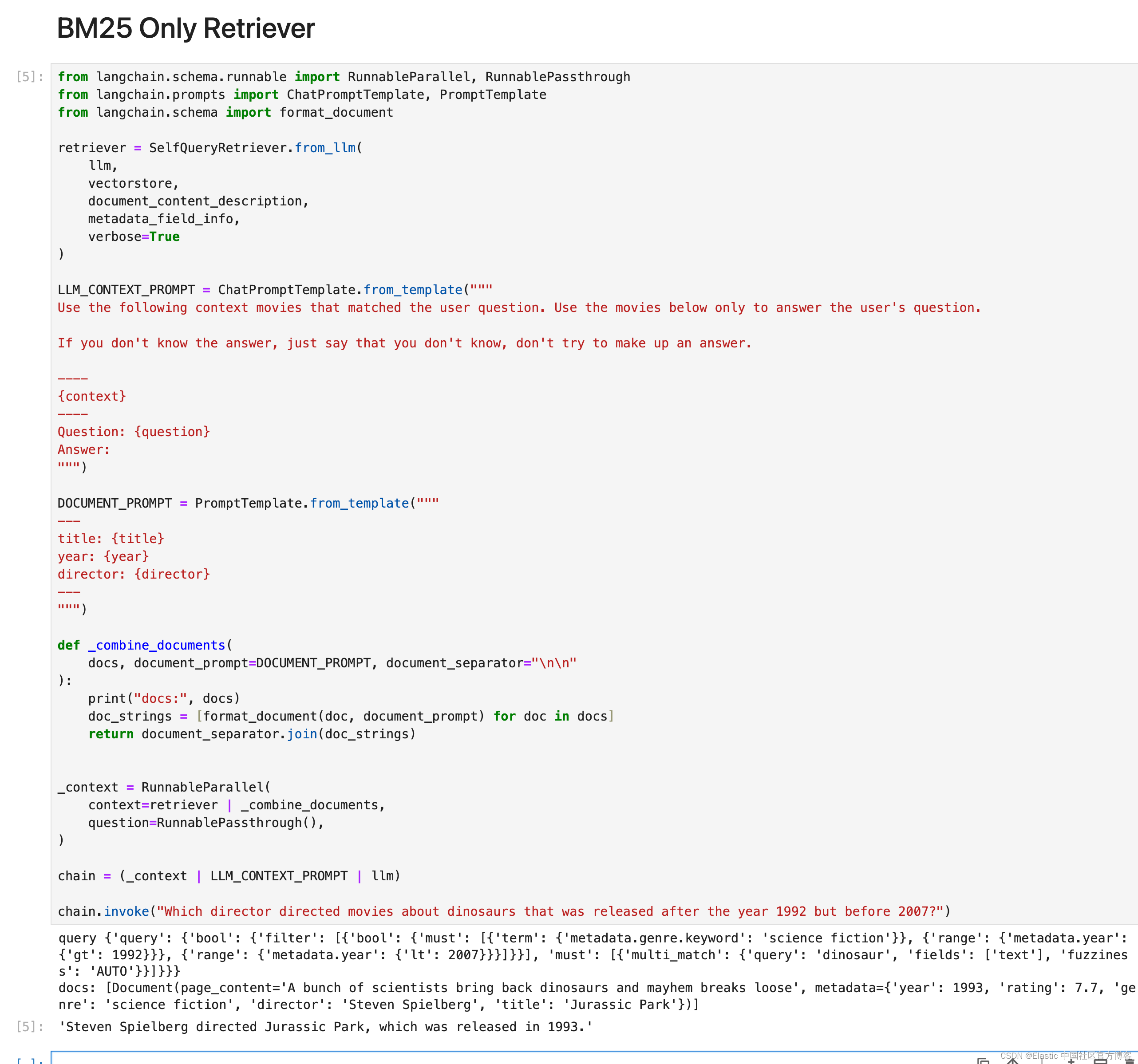
如果一个事务修改了另一个未提交事务修改过的数据,那就意味着发生了脏写 ,示意图如下:

如上图, Session A 和 Session B 各开启了一个事务, Session B 中的事务先将 number 列为 1 的记录的name 列更新为 ‘关羽’ ,然后 Session A 中的事务接着又把这条 number 列为 1 的记录的 name 列更新为张飞 。如果之后 Session B 中的事务进行了回滚,那么 Session A 中的更新也将不复存在,这种现象就称之为 脏写 。这时 Session A 中的事务就很纳闷,明明把数据更新了,最后也提交事务了,到最后怎么什么都没有变化呢? - 脏读( Dirty Read )
如果一个事务读到了另一个未提交事务修改过的数据,那就意味着发生了 脏读 ,示意图如下:

如上图, Session A 和 Session B 各开启了一个事务, Session B 中的事务先将 number 列为 1 的记录的name 列更新为 ‘关羽’ ,然后 Session A 中的事务再去查询这条 number 为 1 的记录,如果读取到列 name 的值为 ‘关羽’ ,而 Session B 中的事务稍后进行了回滚,那么 Session A 中的事务相当于读到了一个不存在的数据,这种现象就称之为 脏读 。 - 不可重复读(Non-Repeatable Read)
如果一个事务只能读到另一个已经提交的事务修改过的数据,并且其他事务每对该数据进行一次修改并提交后,该事务都能查询得到最新值,那就意味着发生了不可重复读 ,示意图如下:
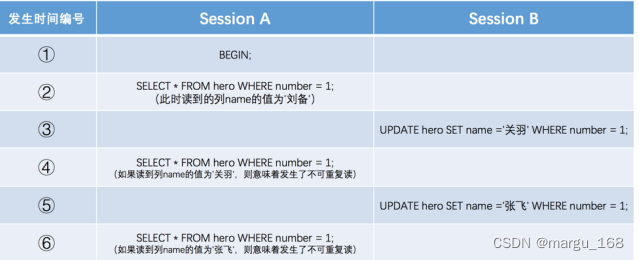
如上图,我们在 Session B 中提交了几个隐式事务(注意是隐式事务,意味着语句结束事务就提交了),这些事务都修改了 number 列为 1 的记录的列 name 的值,每次事务提交之后,如果 Session A 中的事务都可以查看到最新的值,这种现象也被称之为不可重复读 。 - 幻读(Phantom)
如果一个事务先根据某些条件查询出一些记录,之后另一个事务又向表中插入了符合这些条件的记录,原先的事务再次按照该条件查询时,能把另一个事务插入的记录也读出来,那就意味着发生了幻读 ,示意图如下:

如上图, Session A 中的事务先根据条件 number > 0 这个条件查询表 hero ,得到了 name 列值为 ‘刘备’ 的记录;之后 Session B 中提交了一个隐式事务,该事务向表 hero 中插入了一条新记录;之后Session A 中的事务再根据相同的条件 number > 0 查询表 hero ,得到的结果集中包含 Session B 中的事务新插入的那条记录,这种现象也被称之为 幻读 。
其次,如果 Session B 中是删除了一些符合 number > 0 的记录而不是插入新记录,那Session A 中之后再根据 number > 0 的条件读取的记录变少了,这种现象算不算 幻读 呢?明确说一下,这种现象不属于幻读 , 幻读 强调的是一个事务按照某个相同条件多次读取记录时,后读取时读到了之前没有读到的记录。
注意:那对于先前已经读到的记录,之后又读取不到这种情况,这种其实这相当于对每一条记录都发生了不可重复读的现象。幻读只是重点强调了读取到了之前读取没有获取到的记录。
SQL标准中的四种隔离级别
我们上边介绍了几种并发事务执行过程中可能遇到的一些问题,这些问题也有轻重缓急之分,我们给这些问题按照严重性来排一下序:
脏写 > 脏读 > 不可重复读 > 幻读
我们可以通过设置不同的级别来避免一些问题,规律如下:隔离级别越低,越严重的问题就越可能发生。在数据库行业有一个所谓的 SQL标准 ,在标准中设立了4个隔离级别 :
- READ UNCOMMITTED :未提交读。
- READ COMMITTED :已提交读。
- REPEATABLE READ :可重复读。
- SERIALIZABLE :可串行化。
SQL标准中规定,针对不同的隔离级别,并发事务可以发生不同严重程度的问题,具体情况如下:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ UNCOMMITTED | Possible | Possible | Possible |
| READ COMMITTED | Not Possible | Possible | Possible |
| REPEATABLE READ | Not Possible | Not Possible | Possible |
| SERIALIZABLE | Not Possible | Not Possible | Not Possible |
说明:
- READ UNCOMMITTED 隔离级别下,可能发生脏读 、 不可重复读和幻读问题。
- READ COMMITTED 隔离级别下,可能发生不可重复读和幻读 问题,但是不会发生脏读问题。
- REPEATABLE READ 隔离级别下,可能发生幻读问题,但是不会发生脏读和不可重复读的问题。
- SERIALIZABLE 隔离级别下,各种问题都不会发生。
最后脏写这个问题很严重,不论是哪种隔离级别,都不允许脏写的情况发生。
MySQL中支持的四种隔离级别
不同的数据库厂商对 SQL标准中规定的四种隔离级别支持不一样,比方说 Oracle 就只支持 READ COMMITTED 和SERIALIZABLE 隔离级别。本书中所讨论的 MySQL 虽然支持4种隔离级别,但与 SQL标准中所规定的各级隔离级别允许发生的问题却有些出入,MySQL在REPEATABLE READ隔离级别下,是可以禁止幻读问题的发生的(关于方法我们后续说明)。
MySQL 的默认隔离级别为 REPEATABLE READ ,我们可以手动修改一下事务的隔离级别。
如何设置事务的隔离级别
我们可以通过下边的语句修改事务的隔离级别:
SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL level;
其中的 level 可选值有4个:
level: {
REPEATABLE READ
| READ COMMITTED
| READ UNCOMMITTED
| SERIALIZABLE
}
设置事务的隔离级别的语句中, SET 关键字后可以是 GLOBAL 、 SESSION 或者空,这样会对不同范围的事务产生不同的影响,具体如下:
- 使用 GLOBAL (在全局范围影响):
比如:
SET GLOBAL TRANSACTIONISOLATION LEVEL SERIALIZABLE;
则:- 只对执行完该语句之后产生的会话起作用。
- 当前已经存在的会话无效。
- 使用 SESSION 关键字(在会话范围影响):
比如:
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
则:- 对当前会话的所有后续的事务有效
- 该语句可以在已经开启的事务中间执行,但不会影响当前正在执行的事务。
- 如果在事务之间执行,则对后续的事务有效。
- 上述两个关键字都不用(只对执行语句后的下一个事务产生影响):
比如:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
则:- 只对当前会话中下一个即将开启的事务有效。
- 下一个事务执行完后,后续事务将恢复到之前的隔离级别。
- 该语句不能在已经开启的事务中间执行,会报错的。
如果我们在服务器启动时想改变事务的默认隔离级别,可以修改启动参数 transaction-isolation 的值,比方说我们在启动服务器时指定了 --transaction-isolation=SERIALIZABLE ,那么事务的默认隔离级别就从原来的REPEATABLE READ 变成了 SERIALIZABLE 。想要查看当前会话默认的隔离级别可以通过查看系统变量 transaction_isolation 的值来确定:
mysql> show variables like "%transaction_isolation%";
+-----------------------+-----------------+
| Variable_name | Value |
+-----------------------+-----------------+
| transaction_isolation | REPEATABLE-READ |
+-----------------------+-----------------+
1 row in set (0.01 sec)
##或者使用更简便的写法:
mysql> select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| REPEATABLE-READ |
+-------------------------+
1 row in set (0.00 sec)
注意:我们也可以使用设置系统变量transaction_isolation的方式来设置事务的隔离级别,不过我们前边介绍过,一般系统变量只有GLOBAL和SESSION两个作用范围,而这个transaction_isolation却有3个。另外,transaction_isolation是在MySQL 5.7.20的版本中引入来替换tx_isolation的,如果使用的是之前版本的MySQL,关于隔离级别的系统变量为tx_isolation。
MVCC原理
版本链
我们前边说过,对于使用 InnoDB 存储引擎的表来说,它的聚簇索引记录中都包含两个必要的隐藏列( row_id 并不是必要的,我们创建的表中有主键或者非NULL的UNIQUE键时都不会包含 row_id 列):
- trx_id :每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的事务id 赋值给 trx_id隐藏列。
- roll_pointer :每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到 undo日志 中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
比如现创建一个表 hero,并向表插入一条数据如下:
mysql> CREATE TABLE hero (-> number INT,-> name VARCHAR(100),-> country varchar(100),-> PRIMARY KEY (number)-> ) Engine=InnoDB CHARSET=utf8;
Query OK, 0 rows affected (0.10 sec)mysql> INSERT INTO hero VALUES(1, '刘备', '蜀');
Query OK, 1 row affected (0.06 sec)
假设插入该记录的事务id为 80 ,那么此刻该条记录的示意图如下所示,不需要row_id,因为有number这个主键列:

实际上insert undo只在事务回滚时起作用,当事务提交后,该类型的undo日志就没用了,它占用的Undo Log Segment也会被系统回收(也就是该undo日志占用的Undo页面链表要么被重用,要么被释放)。虽然真正的insert undo日志占用的存储空间被释放了,但是roll_pointer的值并不会被清除,roll_pointer属性占用7个字节,第一个比特位就标记着它指向的undo日志的类型,如果该比特位的值为1时,就代表着它指向的undo日志类型为insert undo,在后面画图的时候都会把insert undo省略掉。
假设之后两个 事务id分别为 100 、 200 的事务对这条记录进行 UPDATE 操作,操作流程如下:
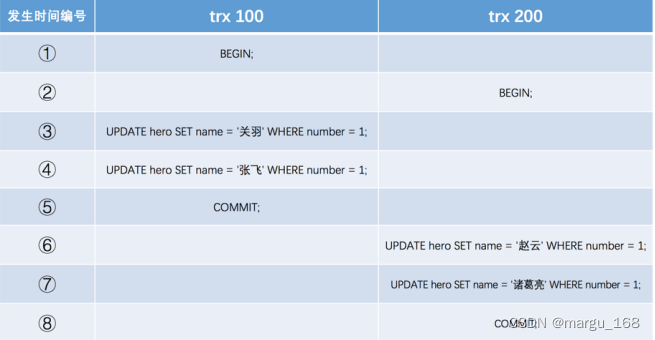
可以在两个事务中交叉更新同一条记录,但是InnoDB会使用锁来保证不会有脏写情况的发生,也就是在第一个事务更新了某条记录后,就会给这条记录加锁,另一个事务再次更新时就需要等待第一个事务提交了,把锁释放之后才可以继续更新。
每次对记录进行改动,都会记录一条 undo日志 ,每条 undo日志也都有一个 roll_pointer 属性( INSERT 操作对应的 undo日志没有该属性,因为该记录并没有更早的版本),可以将这些 undo日志 都连起来,串成一个链表,所以现在的情况就像下图一样:
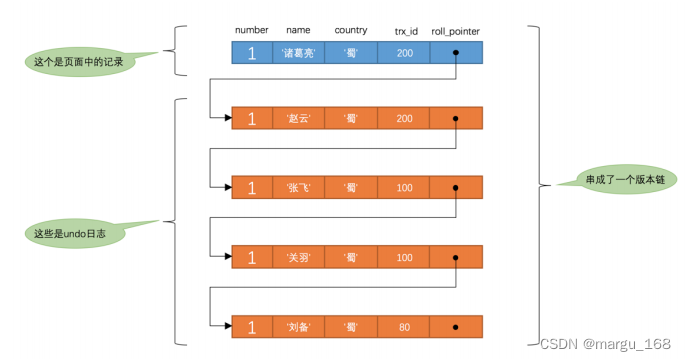
对该记录每次更新后,都会将旧值放到一条 undo日志中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被 roll_pointer 属性连接成一个链表,我们把这个链表称之为版本链 ,版本链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的事务id ,这个信息对判断数据是否能读取到很重要,我们稍后就会用到。
ReadView
对于使用 READ UNCOMMITTED 隔离级别的事务来说,由于可以读到未提交事务修改过的记录,所以直接读取记录的最新版本就好了;对于使用 SERIALIZABLE 隔离级别的事务来说,在InnoDB 中规定使用加锁的方式来访问记录;而对于使用 READ COMMITTED 和 REPEATABLE READ 隔离级别的事务来说,都必须保证读到已经提交了的事务修改过的记录,也就是说假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的,那么关键点就是:需要判断一下版本链中的哪个版本是当前事务可见的。为此,在 InnoDB 中提出了一个 ReadView 的概念(简单点说,ReadView就是读的时候生成的一个版本)。这个 ReadView 中主要包含4个比较重要的内容:
- m_ids :表示在生成 ReadView时当前系统中活跃的读写事务的 事务id 列表。
- min_trx_id :表示在生成 ReadView 时当前系统中活跃的读写事务中最小的 事务id ,也就是 m_ids 中的最小值。
- max_trx_id :表示生成 ReadView 时系统中应该分配给下一个事务的 id 值。注意max_trx_id并不是m_ids中的最大值,事务id是递增分配的。比方说现在有id为1,2,3这三个事务,之后id为3的事务提交了。那么一个新的读事务在生成ReadView时,m_ids就包括1和2,min_trx_id的值就是1,而max_trx_id的值是4。
- creator_trx_id :表示生成该 ReadView 的事务的事务id 。
说明:我们前边说过,只有在对表中的记录做改动时(执行INSERT、DELETE、UPDATE这些语句时)才会为事务分配事务id,否则在一个只读事务中的事务id值都默认为0。
有了这个 ReadView ,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
- 如果被访问版本的 trx_id 属性值与 ReadView 中的 creator_trx_id 值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。
- 如果被访问版本的 trx_id 属性值小于 ReadView 中的 min_trx_id 值,表明生成该版本的事务在当前事务生成 ReadView 前已经提交,所以该版本可以被当前事务访问。
- 如果被访问版本的 trx_id 属性值大于 ReadView 中的 max_trx_id 值,表明生成该版本的事务在当前事务生成 ReadView 后才开启,所以该版本不可以被当前事务访问。
- 如果被访问版本的 trx_id 属性值在 ReadView 的 min_trx_id 和 max_trx_id 之间,那就需要判断一下trx_id 属性值是不是在 m_ids 列表中,如果在,说明创建 ReadView 时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本。如果最后一个版本也不可见的话,那么就意味着该条记录对该事务完全不可见,查询结
果就不包含该记录。
在 MySQL 中, READ COMMITTED 和 REPEATABLE READ 隔离级别的的一个非常大的区别就是它们生成ReadView的时机不同。我们还是以表 hero 为例来,假设现在表 hero 中只有一条由 事务id 为80的事务插入的一条记录:
mysql> select * from hero;
+--------+--------+---------+
| number | name | country |
+--------+--------+---------+
| 1 | 刘备 | 蜀 |
+--------+--------+---------+
1 row in set (0.01 sec)
接下来看看 READ COMMITTED 和 REPEATABLE READ 所谓的生成ReadView的时机不同到底不同在哪里。
READ COMMITTED —— 每次读取数据前都生成一个ReadView
比方说现在系统里有两个事务id 分别为 100 、 200 的事务在执行:
# Transaction 100
BEGIN;
UPDATE hero SET name = ‘关羽’ WHERE number = 1;
UPDATE hero SET name = ‘张飞’ WHERE number = 1;
# Transaction 200
BEGIN;
# 更新了一些别的表的记录
…
注意:在事务执行过程中,只有在第一次真正修改记录时(比如使用INSERT、DELETE、UPDATE语句),才会被分配一个单独的事务id,这个事务id是递增的。所以我们才在Transaction 200中更新一些别的表的记录,目的是让它分配事务id。
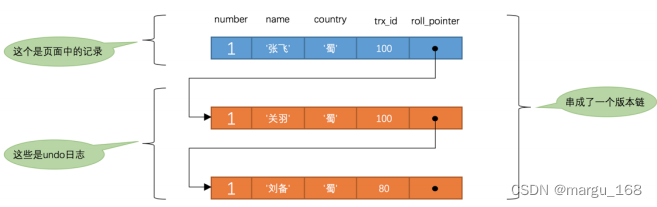
此刻,表 hero 中 number 为 1 的记录得到的版本链表如下所示:
假设现在有一个使用 READ COMMITTED 隔离级别的事务开始执行:
# 使用READ COMMITTED隔离级别的事务
BEGIN;
# SELECT1:Transaction 100、200未提交
SELECT * FROM hero WHERE number = 1; # 按理说应该得到的列name的值为’刘备’
这个 SELECT1 的执行过程如下:
- 在执行 SELECT 语句时会先生成一个 ReadView , ReadView 的 m_ids 列表的内容就是 [100, 200] ,min_trx_id 为 100 , max_trx_id 为 201 , creator_trx_id 为 0 。
- 然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列 name 的内容是 ‘张飞’ ,该版本的trx_id 值为 100 ,在 m_ids 列表内,说明该版本的事务还是活跃的,不符合可见性要求,根据 roll_pointer 跳到下一个版本。
- 下一个版本的列 name 的内容是 ‘关羽’ ,该版本的 trx_id 值也为 100 ,也在 m_ids 列表内,说明该版本的事务还是活跃的,不符合可见性要求,继续跳到下一个版本。
- 下一个版本的列 name 的内容是 ‘刘备’ ,该版本的 trx_id 值为 80 ,小于 ReadView 中的 min_trx_id 值100 ,所以这个版本是符合要求的,最后返回给用户的版本就是这条列 name 为 ‘刘备’ 的记录。
之后,我们把 事务id 为 100 的事务提交一下,如下:
# Transaction 100
BEGIN;
UPDATE hero SET name = ‘关羽’ WHERE number = 1;
UPDATE hero SET name = ‘张飞’ WHERE number = 1;
COMMIT;
然后再到 事务id 为 200 的事务中更新一下表 hero 中 number 为 1 的记录:
# Transaction 200
BEGIN;
# 更新了一些别的表的记录
…
UPDATE hero SET name = ‘赵云’ WHERE number = 1;
UPDATE hero SET name = ‘诸葛亮’ WHERE number = 1;
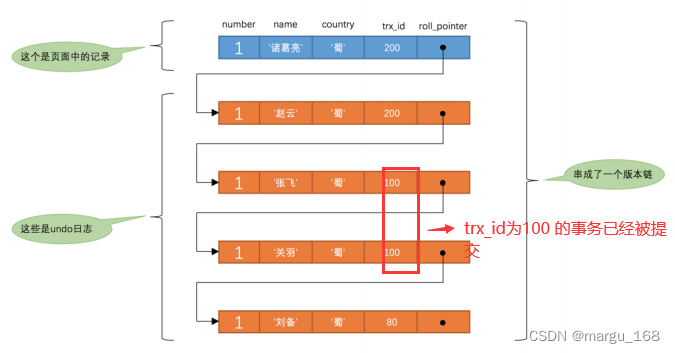
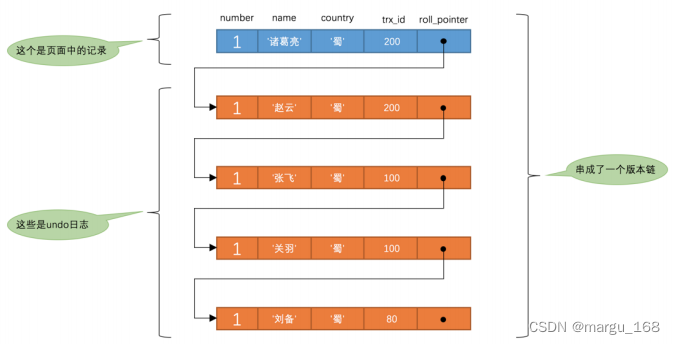
此刻,表 hero 中 number 为 1 的记录的版本链如下:
然后再到刚才使用 READ COMMITTED 隔离级别的事务中继续查找这个 number 为 1 的记录,如下:
# 使用READ COMMITTED隔离级别的事务
BEGIN;
# SELECT1:Transaction 100、200均未提交
SELECT * FROM hero WHERE number = 1; # 得到的列name的值应该为’刘备’
# SELECT2:Transaction 100提交,Transaction 200未提交
SELECT * FROM hero WHERE number = 1; # 得到的列name的值应该为’张飞’
这个 SELECT2 的执行过程如下:
- 在执行 SELECT 语句时会又会单独生成一个 ReadView ,该 ReadView 的 m_ids 列表的内容就是 [200] ( 事务id 为 100 的那个事务已经提交了,所以再次生成快照时就没有它了), min_trx_id 为 200 ,max_trx_id 为 201 , creator_trx_id 为 0 。
- 然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列 name 的内容是 ‘诸葛亮’ ,该版本的trx_id 值为 200 ,在 m_ids 列表内,所以不符合可见性要求,根据 roll_pointer 跳到下一个版本。
- 下一个版本的列 name 的内容是 ‘赵云’ ,该版本的 trx_id 值为 200 ,也在 m_ids 列表内,所以也不符合要求,继续跳到下一个版本。
- 下一个版本的列 name 的内容是 ‘张飞’ ,该版本的 trx_id 值为 100 ,小于 ReadView 中的 min_trx_id 值200 ,所以这个版本是符合要求的,最后返回给用户的版本就是这条列 name 为 ‘张飞’ 的记录。
以此类推,如果之后 事务id 为 200 的记录也提交了,再此在使用 READ COMMITTED 隔离级别的事务中查询表hero 中 number 值为 1 的记录时,得到的结果就应该是 ‘诸葛亮’ 了。总结重点:使用READ COMMITTED隔离级别的事务在每次查询开始时都会生成一个独立的ReadView(针对同一个事务中)。
REPEATABLEREAD —— 在第一次读取数据时生成一个ReadView
对于使用 REPEATABLEREAD 隔离级别的事务来说,只会在第一次执行查询语句时生成一个 ReadView ,之后的查询就不会重复生成了。过程如下。
比如说现在系统里有两个 事务id 分别为 100 、 200 的事务在执行:
# Transaction 100
BEGIN;
UPDATE hero SET name = ‘关羽’ WHERE number = 1;
UPDATE hero SET name = ‘张飞’ WHERE number = 1;
# Transaction 200
BEGIN;
# 更新了一些别的表的记录
…
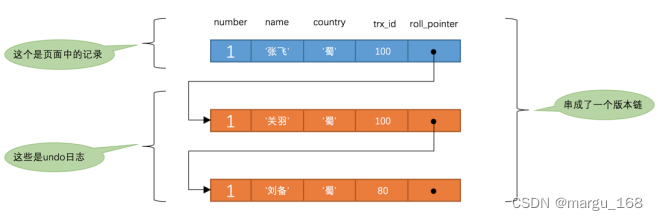
此刻,表 hero 中 number 为 1 的记录得到的版本链表如下所示:
假设现在有一个使用 REPEATABLE READ 隔离级别的事务开始执行:
# 使用REPEATABLE READ隔离级别的事务
BEGIN;
# SELECT1:Transaction 100、200未提交
SELECT * FROM hero WHERE number = 1; # 得到的列name的值应该为’刘备’
这个 SELECT1 的执行过程如下:
- 在执行 SELECT 语句时会先生成一个 ReadView , ReadView 的 m_ids 列表的内容就是 [100, 200] ,min_trx_id 为 100 , max_trx_id 为 201 , creator_trx_id 为 0 。
- 然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列 name 的内容是 ‘张飞’ ,该版本的trx_id 值为 100 ,在 m_ids 列表内,所以不符合可见性要求,根据 roll_pointer 跳到下一个版本。
- 下一个版本的列 name 的内容是 ‘关羽’ ,该版本的 trx_id 值也为 100 ,也在 m_ids 列表内,所以也不符合要求,继续跳到下一个版本。
- 下一个版本的列 name 的内容是 ‘刘备’ ,该版本的 trx_id 值为 80 ,小于 ReadView 中的 min_trx_id 值100 ,所以这个版本是符合要求的,最后返回给用户的版本就是这条列 name 为 ‘刘备’ 的记录。
之后,我们把事务id 为100 的事务提交一下,如下:
# Transaction 100
BEGIN;
UPDATE hero SET name = ‘关羽’ WHERE number = 1;
UPDATE hero SET name = ‘张飞’ WHERE number = 1;
COMMIT;
然后再到 事务id 为 200 的事务中更新一下表 hero 中 number 为 1 的记录:
# Transaction 200
BEGIN;
# 更新了一些别的表的记录
…
UPDATE hero SET name = ‘赵云’ WHERE number = 1;
UPDATE hero SET name = ‘诸葛亮’ WHERE number = 1;
此刻,表 hero 中 number 为 1 的记录的版本链如下:
然后再到刚才使用 REPEATABLE READ 隔离级别的事务中继续查找这个 number 为 1 的记录,如下:
\ # 使用REPEATABLE READ隔离级别的事务
BEGIN;
# SELECT1:Transaction 100、200均未提交
SELECT * FROM hero WHERE number = 1; # 得到的列name的值应该为’刘备’
\ # SELECT2:Transaction 100提交,Transaction 200未提交
SELECT * FROM hero WHERE number = 1; # 得到的列name的值还是应该为’刘备’
这个 SELECT2 的执行过程如下:
- 因为当前事务的隔离级别为 REPEATABLE READ ,而之前在执行 SELECT1 时已经生成过 ReadView 了,所以此时直接复用之前的 ReadView ,之前的 ReadView 的 m_ids 列表的内容就是 [100, 200] , min_trx_id 为100 , max_trx_id 为 201 , creator_trx_id 为 0 。
- 然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列 name 的内容是 ‘诸葛亮’ ,该版本的trx_id 值为 200 ,在 m_ids 列表内,所以不符合可见性要求,根据 roll_pointer 跳到下一个版本。
- 下一个版本的列 name 的内容是 ‘赵云’ ,该版本的 trx_id 值为 200 ,也在 m_ids 列表内,所以也不符合要求,继续跳到下一个版本。
- 下一个版本的列 name 的内容是 ‘张飞’ ,该版本的 trx_id 值为 100 ,而 m_ids 列表中是包含值为 100 的事务id 的,所以该版本也不符合要求,同理下一个列 name 的内容是 ‘关羽’ 的版本也不符合要求。继续跳到下一个版本。
- 下一个版本的列 name 的内容是 ‘刘备’ ,该版本的 trx_id 值为 80 ,小于 ReadView 中的 min_trx_id 值100 ,所以这个版本是符合要求的,最后返回给用户的版本就是这条列 c 为 ‘刘备’ 的记录。
也就是说两次 SELECT 查询得到的结果是重复(一样)的,记录的列 c 值都是 ‘刘备’ ,这就是可重复读的意思。如果我们之后再把 事务id 为 200 的记录提交了,然后再到刚才使用 REPEATABLE READ 隔离级别的事务中继续查找这个 number 为 1 的记录,得到的结果还是 ‘刘备’ ,具体执行过程大家可以自己分析一下。只有提交等100和200事务提交后,重新开始的新事务查询结果才不是’刘备’。
MVCC小结
从上面可以看出,所谓的 MVCC (Multi-Version Concurrency Control ,多版本并发控制)指的就是在使用 READ COMMITTD 、 REPEATABLE READ 这两种隔离级别的事务在执行普通的 SEELCT 操作时访问记录的版本链的过程,这样子可以使不同事务的读-写 、 写-读操作并发执行,从而提升系统性能。 而READ COMMITTD 、REPEATABLE READ 这两个隔离级别的一个最大区别就是:生成ReadView的时机不同,READ COMMITTD在每一次进行普通SELECT操作前都会生成一个ReadView,而REPEA T ABLE READ只在第一次进行普通SELECT操作前生成一个ReadView,之后的查询操作都重复使用这个ReadView。
注意:我们之前说执行DELETE语句或者更新主键的UPDATE语句并不会立即把对应的记录完全从页面中删除,而是执行一个所谓的delete mark操作,相当于只是对记录打上了一个删除标志位,这主要就是为MVCC服务的。
另外,MVCC只是在我们进行普通的SEELCT查询时才生效,目前我们所见的所有SELECT语句都算是普通的查询,后续会说明哪些不算是普通查询。
关于purge
我们说 insert undo 在事务提交之后就可以被释放掉了(因为它就相当于是第一个版本),而 update undo 由于还需要支持 MVCC ,不能立即删除掉。
为了支持 MVCC ,对于 delete mark 操作来说,仅仅是在记录上打一个删除标记,并没有真正将它删除掉。随着系统的运行,在确定系统中包含最早产生的那个 ReadView 的事务不会再访问某些 update undo日志以及被打了删除标记的记录后,有一个后台运行的 purge线程才会把它们真正的删除掉。
更多关于mysql的知识分享,请前往博客主页。编写过程中,难免出现差错,敬请指出