目录
基本步骤
关键领域
• 硬件接口:
任务级并行度:
存储器架构:
微观级别的最优化:
基本步骤
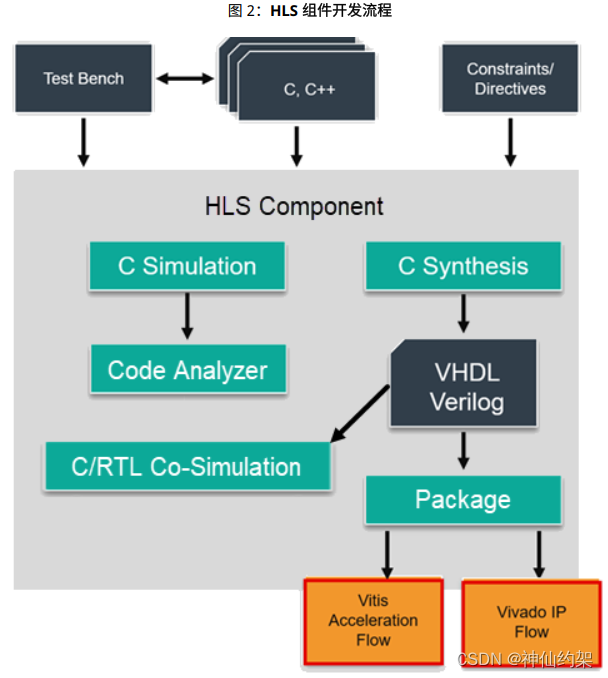
1. 基于 设计原则 建立算法架构。
2. (C 语言仿真) 利用 C/C++ 语言测试激励文件验证 C/C++ 代码的逻辑。
3. (代码分析器) 分析 C/C++ 代码的性能、并行度与合规性。
4. (C 语言综合) 使用 v++ 编译器生成 RTL。
5. (C/RTL 协同仿真) 验证使用 C/C++ 测试激励文件生成的 RTL 代码。
6. (封装) 复查 HLS 综合报告和实现时序报告。
7. 重新运行前述步骤直至满足性能目标为止。
Vitis HLS 基于目标流程、默认工具配置、设计约束和您指定的任意最优化编译指示或指令来生成 Vivado IP 或 Vitis 内核。您可使用最优化指令来修改和控制内部逻辑和 I/O 端口的实现, 以覆盖工具的默认行为。
关键领域
以下提供了有关在 HLS 设计中进行 C++ 函数编码与综合的部分关键领域信息, 在后续章节内将涵盖更多详细信息:
• 硬件接口:
Vitis HLS 设计的顶层函数的实参均综合到接口和端口内, 这些接口和端口通过将多个信号加以组合来定义 HLS 设计与设计外部的组件之间的通信协议。 Vitis HLS 会自动定义接口, 并使用业界标准来指定要使用的协议。根据 HLS 设计目标是 Vivado IP 生成还是 Vitis 内核, 默认接口协议不尽相同。接口的默认分配可通过使用INTERFACE 编译指示或指令来覆盖。
• 控制 HLS 设计的执行: HLS 设计的执行模式是由块级控制协议来指定的。 HLS 设计可包含控制信号, 用于启动/停止执行, 也可设置为仅当数据可用时才驱动 HLS 设计。作为设计人员, 您需要注意自己的 HLS 设计的执行方式,如 HLS 设计的执行模式 中所述。
任务级并行度:
• 为了在生成的硬件上实现高性能, HLS 工具必须基于顺序代码推断并行度, 并利用它来实现更高的性能。 设计原则 章节介绍了三个主要范例, 要为 FPGA 平台编写优秀软件, 就需要了解这三个范例。 Vitis HLS 工具通过指定 DATAFLOW 编译指示或者使用 hls::task 对象, 提供了多种类型的任务级并行度 (TLP), 如 HLS 抽象并行编程模型 中所述。
存储器架构:
• 存储器架构在 CPU 中已固定, 但开发者可以创建自己的架构来最优化存储器访问, 以便在 FPGA 上运行应用
• 在 C++ 程序中, 阵列是基础数据结构, 用于保存或移动数据。在硬件中完成综合后, 这些阵列是作为存储器或寄存器来实现的。存储器可作为本地存储器或全局存储器(通常是 DDR 或 HBM 存储体) 来实现。访问全局存储器会产生更高的时延成本, 可耗时大量周期, 而访问本地存储器通常十分快速, 只需一个或多个周期即可。
• 通常在 C++ 程序中, 对存储器进行动态分配/解除分配, 但这在硬件中无法进行综合。因此, 设计师需知晓算法所需存储器的精确数量。
• 存储器访问应加以最优化, 以减少全局存储器访问的开销。冗余访问表示最大程度利用连续访问, 以便能够推断突发。突发访问会隐藏存储器访问时延, 并改善存储器带宽。
微观级别的最优化:
• 在 C++ 程序中, 经常需要实现重复算法来处理数据块, 例如, 信号处理或图像处理。通常, C/C++ 源代码倾向于包含多个循环或多个嵌套循环。 Vitis HLS 可通过在源代码的相应级别插入编译指示来对循环或嵌套循环进行展开或流水打拍。如需了解更多信息, 请参阅 循环入门。
• 基于设计原则完成算法架构并推断并行度后, 您仍需要正确组合微观级别的 HLS 编译指示, 如, PIPELINE、UNROLL、 ARRAY_PARTITION 等。这些编译指示可能不会直观展示给用户。 Vitis HLS 提供了PERFORMANCE 编译指示用于为循环或嵌套循环的给定主体指定顶级性能目标。该工具将自动推断必要的低层次编译指示以满足该目标。借助 PERFORMANCE 编译指示可以减少实现理想 QoR 所需的编译指示, 这也是驱动该工具的一种直观方法