大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型24-SKAttention注意力机制模型的搭建与应用场景,本文将介绍关于SKAttention注意力机制模型的搭建,SKAttention机制具有灵活性和通用性,可应用于计算机视觉、视频分析、自然语言处理、医学影像分析和机器人视觉等领域。其主要优势在于能够根据任务和输入数据动态调整卷积核,从而提高模型的泛化能力和性能。在实际应用中,SKAttention机制可针对具体问题和数据集进行优化,以达到最佳效果。
一、SKAttention注意力机制的概述
SKAttention是一种用于深度学习中的注意力机制,特别是在卷积神经网络(CNN)中。它通过动态选择不同大小的卷积核来提高网络对多尺度特征的捕捉能力。SKAttention的设计灵感来源于视觉皮层神经元,这些神经元能够根据刺激自适应地调整其感受野大小。在CNN中实现这种机制可以帮助网络更好地捕捉复杂图像空间的多尺度特征,同时减少计算资源的浪费。
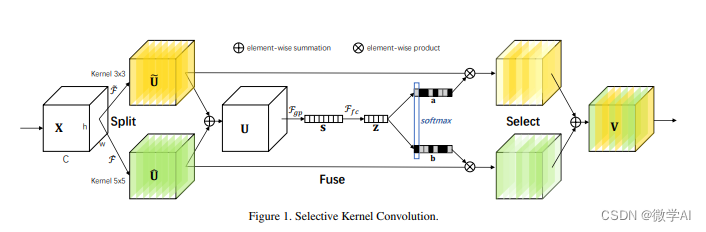
SKAttention的核心是“选择性核(Selective Kernel)”单元,它允许多个具有不同内核大小的分支在信息指导下使用SoftMax进行融合。这些分支中的每个卷积核都会对输入图像进行处理,产生不同尺寸的特征图。然后,通过融合操作将这些不同尺寸的特征图结合起来,生成用于选择权重的全局和综合表示。最后,根据这些权重对不同大小内核的特征图进行聚合,从而得到最终的输出特征。
SKAttention的主要优势在于它可以更有效地捕捉图像空间的多尺度特征,提高模型在处理不同尺度目标时的性能。此外,SKAttention还可以聚合深度特征,使模型更容易理解,同时也允许更好的可解释性。
SKAttention模块可以灵活地集成到各种深度学习模型中,特别是在目标检测领域,如YOLOv5和YOLOv7等模型,已经成功地集成了SKAttention来提升检测效果。在集成时,SKAttention可以作为即插即用的注意力模块添加到网络的任何合适位置。
SKAttention的实现涉及到多个卷积层、全连接层和softmax激活函数。在模型训练过程中,通过反向传播和梯度下降方法不断更新网络参数,优化模型性能。
二、SKAttention注意力机制的数学原理
SKAttention这个机制可以表示为两个主要步骤:特征融合(Feature Fusion)和注意力权重生成(Attention Weight Generation)。
- 特征融合:
假设我们有三种不同大小的卷积核(如3x3, 5x5, 7x7),分别应用于输入特征图 X X X 上,得到三个不同的特征图 F 1 , F 2 , F 3 F_1, F_2, F_3 F1,F2,F3。这些特征图通过一个融合层(例如,使用1x1卷积)来减少通道数并融合信息,得到融合后的特征图 F = [ f 1 , f 2 , f 3 ] F = [f_1, f_2, f_3] F=[f1,f2,f3],其中 f 1 , f 2 , f 3 f_1, f_2, f_3 f1,f2,f3 分别是 F 1 , F 2 , F 3 F_1, F_2, F_3 F1,F2,F3 经过融合层后的结果。 - 注意力权重生成:
在融合特征 F F F 上应用两个全连接层(或一个简单的神经网络)来生成注意力权重 α \alpha α。第一个全连接层将特征维度减少到 C r \frac{C}{r} rC,其中 C C C 是通道数, r r r 是减少比例。第二个全连接层将维度恢复到原始的通道数 C C C,并通过softmax函数生成归一化的注意力权重。
数学上,这个过程可以表示为:
F = Conv 1 x 1 ( F 1 , F 2 , F 3 ) F = \text{Conv}_{1x1}(F_1, F_2, F_3) F=Conv1x1(F1,F2,F3)
α = softmax ( FC C r ( FC C ( F ) ) ) \alpha = \text{softmax}(\text{FC}_{\frac{C}{r}}(\text{FC}_{C}(F))) α=softmax(FCrC(FCC(F)))
其中, Conv 1 x 1 \text{Conv}_{1x1} Conv1x1 表示1x1卷积, FC C r \text{FC}_{\frac{C}{r}} FCrC 和 FC C \text{FC}_{C} FCC 分别表示减少维度和恢复维度的全连接层, softmax \text{softmax} softmax 是softmax激活函数。
最终,通过注意力权重 α \alpha α 和原始特征 F 1 , F 2 , F 3 F_1, F_2, F_3 F1,F2,F3 的加权和来得到最终的输出特征图 O O O:
O = ∑ i = 1 3 α i ⋅ F i O = \sum_{i=1}^{3} \alpha_i \cdot F_i O=i=1∑3αi⋅Fi
这里, α i \alpha_i αi 是对应于 F i F_i Fi 的注意力权重。
三、SKAttention注意力机制应用场景
SKAttention(Selective Kernel Attention)机制是一种在深度学习领域中用于提高卷积神经网络性能的技术。它通过在网络中自动选择最合适的卷积核大小来增强模型对不同尺度特征的提取能力。SKAttention机制通常被应用于以下几个方面:
1.计算机视觉:SKAttention机制最初是为了改善图像分类任务而设计的。它可以被集成到各种卷积神经网络架构中,如ResNet、MobileNet等,以提高模型对图像特征的识别能力。在图像识别、目标检测和图像分割等任务中,SKAttention机制都有显著的效果。
2. 视频分析:在视频内容分析中,SKAttention机制可以帮助模型更好地理解视频中的时空特征,用于行为识别、运动检测等任务。
3. 自然语言处理:虽然SKAttention机制最初是为计算机视觉设计的,但其核心思想也可以被借鉴到自然语言处理领域,用于改进序列模型,比如在文本分类、机器翻译等任务中提取关键信息。
4. 医学影像分析:在医学影像领域,SKAttention机制可以帮助模型更加精确地识别和分析影像中的病变区域,用于疾病诊断、组织分割等。
5. 机器人视觉:在机器人视觉系统中,SKAttention机制可以提高机器人对周围环境的感知能力,用于路径规划、目标追踪等任务。
SKAttention机制的核心优势在于其灵活性,它能够根据不同的任务和输入数据动态地调整卷积核,从而提高模型的泛化能力和性能。在实际应用中,SKAttention机制可以根据具体问题和数据集的特点进行相应的调整和优化,以达到最佳的效果。
四、pytorch搭建SKAttention注意力机制
import numpy as np
import torch
from torch import nn
from torch.nn import init
from collections import OrderedDictclass SKAttention(nn.Module):def __init__(self, channel=512,kernels=[1,3,5,7],reduction=16,group=1,L=32):super().__init__()self.d=max(L,channel//reduction)self.convs=nn.ModuleList([])for k in kernels:self.convs.append(nn.Sequential(OrderedDict([('conv',nn.Conv2d(channel,channel,kernel_size=k,padding=k//2,groups=group)),('bn',nn.BatchNorm2d(channel)),('relu',nn.ReLU())])))self.fc=nn.Linear(channel,self.d)self.fcs=nn.ModuleList([])for i in range(len(kernels)):self.fcs.append(nn.Linear(self.d,channel))self.softmax=nn.Softmax(dim=0)def forward(self, x):bs, c, _, _ = x.size()conv_outs=[]### splitfor conv in self.convs:conv_outs.append(conv(x))feats=torch.stack(conv_outs,0)#k,bs,channel,h,w### fuseU=sum(conv_outs) #bs,c,h,w### reduction channelS=U.mean(-1).mean(-1) #bs,cZ=self.fc(S) #bs,d### calculate attention weightweights=[]for fc in self.fcs:weight=fc(Z)weights.append(weight.view(bs,c,1,1)) #bs,channelattention_weughts=torch.stack(weights,0)#k,bs,channel,1,1attention_weughts=self.softmax(attention_weughts)#k,bs,channel,1,1### fuseV=(attention_weughts*feats).sum(0)return Vif __name__ == '__main__':input=torch.randn(50,512,7,7)se = SKAttention(channel=512,reduction=8)output=se(input)print(output.shape)五、总结
SKAttention是一种深度学习中的注意力机制,用于自动选择最合适的卷积核大小,以提升卷积神经网络对多尺度特征的提取能力。该机制通过动态调整卷积核,增强模型对不同尺度特征的识别,从而提高模型的泛化能力和性能。SKAttention机制具有灵活性和通用性,适用于计算机视觉、视频分析、自然语言处理、医学影像分析和机器人视觉等多个领域。想了解更多SKAttention注意力机制的应用,请持续关注微学AI。




![[Python] scikit-learn中数据集模块介绍和使用案例](https://img-blog.csdnimg.cn/direct/61fb9a63a6fa4395b6eeed3e166d2de8.png)

![[office] 在Excel中怎么给单元格文本创建超链接- #职场发展#笔记](https://img-blog.csdnimg.cn/img_convert/5586a3705651fc7461fff27fd30c8fe9.jpeg)