文章目录
- 端口号
- UDP协议
在网络通信中,协议非常重要
协议进行了分层
应用层就是对应着应用程序,是程序员打交道最多的这一层,调用系统提供的网络api写出来的代码都是属于应用层的
应用层有很多现成的协议,但是更多的还是程序员需要根据实际场景自定义协议
自定义协议,约定好两方面内容
1.服务器和客户端之间要交互哪些信息
2.数据的具体格式
客户端按照上述约定发送请求,服务器按照上述约定解析请求
服务器按照上述约定构造响应,客户端也按照上述约定解析相应
为了让程序员更方便的去约定这里的协议格式,业界也给出了几个比较好用的方案,
1.xml(可扩展标记语言)
使用标签来定义语言,标签成对出现,标签的名字 / 标签的值 / 标签的嵌套关系都是程序员自定义的
2.json
举例:
请求
{userld: 1000,position:[经纬度]
}
相应
{id: 1001,name:"麻辣烫"
}
键值对结构
键和值之间使用:分割
键值对之间使用,分割
把若干个键值对使用{ }括起来,此时就形成一个json对象
还可以把多个json对象放在一起,使用,分割开,并且使用[ ]整体括起来就形成了一个json数组
相比于xml来说,json占用空间小,更节省了带宽
3.protobuffer
更节省带宽的方式,效率最高的方式
端口号
端⼝号(Port)标识了⼀个主机上进⾏通信的不同的应⽤程序;
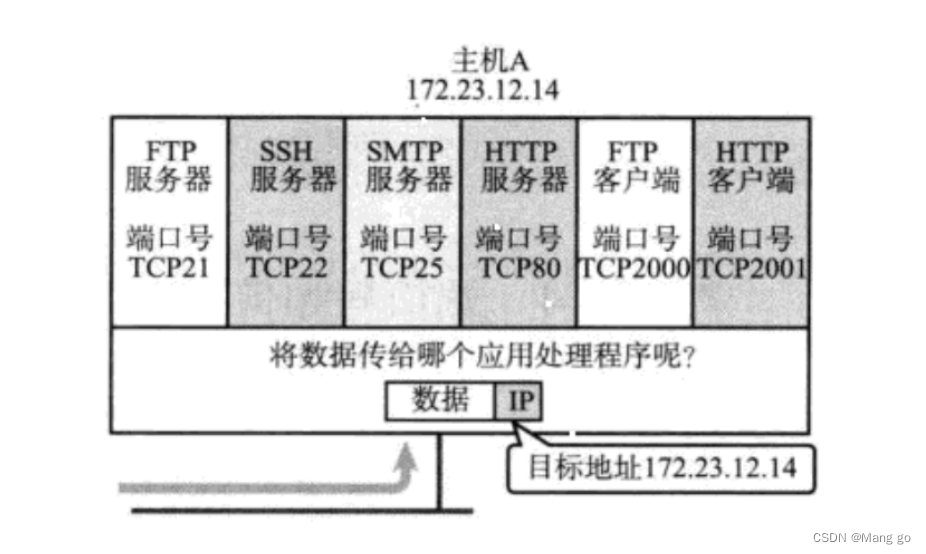
端口号范围划分
• 0-1023:知名端⼝号,HTTP,FTP,SSH等这些⼴为使⽤的应⽤层协议,他们的端⼝号都是固定的
.• 1024-65535:操作系统动态分配的端⼝号.客⼾端程序的端⼝号,就是由操作系统从这个范围分配
的.
认识知名端口号(Well-Know Port Number)
有些服务器是⾮常常⽤的,为了使⽤⽅便,⼈们约定⼀些常⽤的服务器,都是⽤以下这些固定的端⼝号:
• ssh服务器,使⽤22端⼝
• ftp服务器,使⽤21端⼝
• telnet服务器,使⽤23端⼝
• http服务器,使⽤80端⼝
• https服务器,使⽤443
我们⾃⼰写⼀个程序使⽤端⼝号时,要避开这些知名端⼝号
UDP协议
特点:
无连接,不可靠传输,面向数据报,全双工
研究一个协议,主要研究报文格式,基于报文格式,来了解这个协议的其他各个特性
UDP数据报 = 报头(重点) + 载荷(应用层数据包)
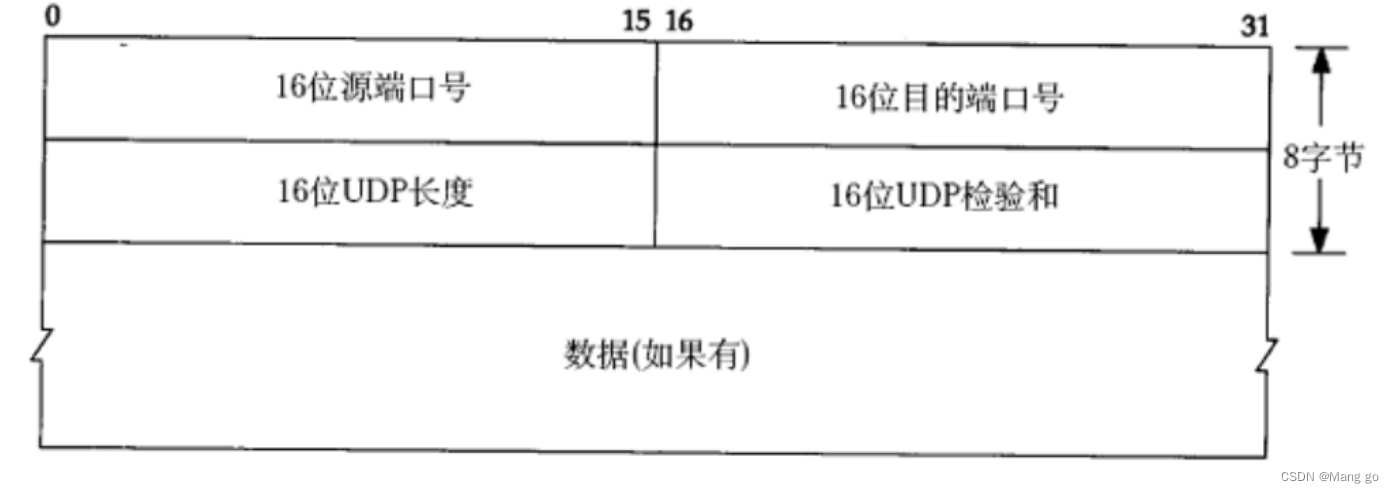
上述图其实不准确,教材为了排版方便

16位UDP⻓度,表⽰整个数据报(UDP⾸部+UDP数据)的最⼤⻓度;
• 如果校验和出错,就会直接丢弃;
UDP报头一共有四个字段,每个字段两个字节(一共八个字节)
协议报头中使用2个字节表示端口号,端口号的取值范围就是0–65535
因此一个UDP数据报最大长度就是64KB,无法更长了
校验和
验证数据传输过程中是否正确
前提:数据在网络传输过程中,可能坏掉
校验和的作用就是用来识别当前数据是否出现了比特翻转
UDP中,校验和使用比较简单的方式,CRC(循环冗余校验)算法完成校验
校验和使用过程:UDP数据报发送方,在发送之前,先计算一遍CRC,把计算好的CRC值放到UDP数据报中(设这个CRC值为value1),接下来这个数据报通过网络传输到达接收端,接收端收到这个数据之后,也按照同样的算法再算一遍CRC的值,得到的结果是value2,比较自己计算的value2和收到的value1是否一致,如果一致的,就说明数据是正确的,如果不一致,传输过程中发生了比特翻转了
上述的CRC算法中,如果只有一个bit位发生翻转,此时100%能够发现问题,如果有两个/多个bit位发生翻转,有可能恰好校验和和之前一样
除了CRC之外,还有一些更高精度的校验和算法
常用的有md5算法和sha1算法
md5背后有一系列的数学公式,md5的特点:
1.定长:无论原始数据多长,算出来的md5的最终值都是固定长度,常用的md5有16位版本(2字节),32位版本(4字节),64位版本(8字节)
2.分散:计算md5的过程中,原始数据只要有一点变化,算出来的md5值就会差别很大
3.不可逆:一个源字符串,计算md5值过程非常简单,但是一个算好的md5值,还原回原始的字符串,理论上是不可完成的




![[计算机提升] 备份系统:系统映像](https://img-blog.csdnimg.cn/direct/3ef96edfd59441f699bd77920db1b5bd.png)