【机器学习与自然语言处理】预训练 Pre-Training 各种经典方法的概念汇总
- 前言请看此
- 正文
- 预训练 Pre-Training
- 无监督学习 unsupervised learning
- 概念:标签
- PCA 主成分分析(Principal Component Analysis)降维算法
- LSA 潜在语义分析(Latent Semantic Analysis)降维算法
- LDA 隐含狄利克雷分布(Latent Dirichlet Allocation)降维算法
- 概念:词袋模型(Bag of Words Model / BOW)
- 概念:n-gram 模型
- K均值(K-Means) 聚类算法
- 概念:词嵌入(Word Embedding)
- Word2Vec 预测模型,词嵌入算法
- GloVe (Global Vectors for Word Representation) 词嵌入算法
- ELMo(Embeddings from Language Models) 词嵌入模型
- BERT (Bidirectional Encoder Representations from Transformers)语言模型,词嵌入模型
- AE 自动编码器(AutoEncoder)人工神经网络
- 概念:NLP中的编码器(Encoder)和解码器(Decoder)
- 概念:分词器(Tokenizer),词嵌入(Word Embedding)和编码器(Encoder)的区别
- 概念:Transformer架构
- 概念:Encoder 模型,Decoder 模型,Seq2Seq 模型
- 概念:预训练任务
- MLM 遮蔽语言模型(Masked Language Model)预训练任务
- NSP 下句预测(Next Sentence Prediction)预训练任务
- 其他一些经典的预训练任务
- 概念:NLU,NLG,NLI
- 自监督学习 Self-Supervised Learning
前言请看此
(1)一些概念源自LLM(Chatgpt)和网络(百度/知乎等),笔者进行了初步检查。
(2)由于其中的各种知识比较琐碎,为了形成较为结构化的知识体系,且使用最简单的、几乎无公式的介绍,故作此博客。
(3)着重为机器学习ML与自然语言处理领域NLP的,CV领域的不是很详细讲述了
正文
- 在深度学习中,一般流程包括预训练和微调两个主要阶段:
- 预训练阶段: 这个阶段包括在大规模无标签数据上进行训练,以学习模型的初始参数,用以学习通用的语言表示。无监督学习和自监督学习是常用的预训练方法,通过让模型在无标签数据上学习语言的结构和特征。
- 微调阶段: 预训练完成后,微调阶段会改变部分参数或全部参数,并在有标签数据上进行微调,以适应特定的任务。微调的目标是调整模型的参数,使其在特定任务上表现良好。
- 下面,按照预训练和微调为两个大类,其中有不同小类进行介绍。(微调貌似只能放到下一篇了捏)
预训练 Pre-Training
无监督学习 unsupervised learning
- 现实生活中常常会有这样的问题:缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。很自然地,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。
【机器学习】几种常见的无监督学习算法
概念:标签
- 在机器学习中,训练样本的标签指的是与每个输入样本相关联的输出或目标值。训练样本通常包括两个部分:输入特征(特征向量)和相应的标签。
- 输入特征: 描述样本的属性或特征,是模型用来进行学习和预测的信息。
- 标签: 对于监督学习任务,标签是与每个输入样本关联的真实输出值或类别。在监督学习中,模型的目标是学习从输入到标签的映射,以便在未见过的数据上进行准确的预测。
- 标签的形式可以是多样化的,具体取决于任务的性质和问题的定义。
- 分类任务:
单一类别标签: 通常用于分类任务,标签表示样本属于哪个类别。例如,图像分类任务中,标签可以是“猫”、“狗”等。
多类别标签: 如果一个样本可以属于多个类别,标签可以是一个包含多个类别的集合。
回归任务: - 数值标签: 在回归任务中,标签是一个实数或浮点数值,表示目标变量的具体数值。例如,房价预测任务中,标签可以是房价的具体价格。
- 序列标注任务:
句子或文本标签: 用于自然语言处理中的一些任务,标签可以是一个句子或文本序列。例如,命名实体识别任务中,标签是标注每个词语的实体类型。 - 图像生成任务:
图像标签: 在图像生成任务中,标签可以是一张图像,表示模型生成的目标图像。 - 向量标签:
多维向量: 在一些任务中,标签可以是一个多维的向量,表示样本的多个属性或特征。例如,人脸识别任务中,标签可以是包含人脸特征的向量。
- 那么问题来了,大量的数据,没有标签,我们怎么拿它们进行作为训练语料进行训练呢?
答案是使用一些算法进行标注呗。
PCA 主成分分析(Principal Component Analysis)降维算法
- 降维是指在保留数据特征的前提下,以少量的变量表示有许多变量的数据,这有助于降低多变量数据分析的复杂度。减少数据变量的方法有两种:一种是只选择重要的变量,不使用其余变量;另一种是基于原来的变量构造新的变量。
- 通过降维算法后变成低维向量,作为标签。
- PCA 采用以下步骤来寻找主成分:
(1)计算协方差矩阵。
(2)对协方差矩阵求解特征值问题,求出特征向量和特征值。
(3)以数据表示各主成分方向。
LSA 潜在语义分析(Latent Semantic Analysis)降维算法
- LSA 是一种用于处理和分析文本数据的无监督学习方法,主要用于文本挖掘和信息检索任务。其目标是通过降维技术,将文本数据从高维的词语空间映射到低维的语义空间,以捕捉文本数据的潜在语义结构。
潜在语义分析(LSA)解析 | 统计学习方法 | 数据分析,机器学习,学习历程全记录 - LSA 的主要步骤:
(1)构建文档-词矩阵
(2)奇异值分解
(3)选择主题数量
(4)降维
(5)文档相速度和检索 - LSA的优点包括对大规模文本数据的有效处理、对词语之间的语义关系进行建模以及对噪声和冗余信息的抵抗力。然而,它也有一些限制,如对词语的词序和上下文的敏感性较低。且分解变换后的矩阵难以解释,计算代价高。
LDA 隐含狄利克雷分布(Latent Dirichlet Allocation)降维算法
- LDA 是一种用于主题建模的概率图模型,主要用于分析大规模文本语料库中的主题结构。LDA 假设每个文档是由多个主题的混合生成的,而每个主题则是由一组词语的分布所定义的。该模型的目标是通过观察文档中的词语分布,推断文档和主题之间的潜在关系。
- LDA 通过以下步骤计算主题分布和单词分布。
(1)为各文本的单词随机分配主题。
(2)基于为单词分配的主题,计算每个文本的主题概率。
(3)基于为单词分配的主题,计算每个主题的单词概率。
(4)计算步骤 2 和步骤 3 中的概率的乘积,基于得到的概率,再次为各文本的单词分配主题。
(5)重复步骤 2 到步骤 4 的计算,直到收敛。
概念:词袋模型(Bag of Words Model / BOW)
- 所谓词袋模型,是将一篇文档,我们仅考虑一个词汇是否出现(或者出现频率),而不考虑其出现的顺序。在词袋模型中,"我喜欢你"和"你喜欢我"是等价的。
- 在词袋模型中,文本被表示为一个向量,其中每个维度对应一个词语,而向量的值表示相应词语在文本中的出现次数或其他权重。
- 我们发现,在上述LSA,LDA中通常使用的是BOW模型。但上述降维方法不单单局限于BOW。
概念:n-gram 模型
- 与BOW相反的是 n-gram模型
- N-gram 是自然语言处理中一种基于词序列的模型表示方法,它捕捉了文本中相邻词语之间的关系。N-gram 模型将文本分割成连续的 n 个词语组成的片段,并基于这些片段来建模文本的结构。
- 以一个简单的例子说明,对于句子 “I love natural language processing.”,各个 N-gram 如下:
Unigram: {“I”, “love”, “natural”, “language”, “processing”}
Bigram: {“I love”, “love natural”, “natural language”, “language processing”}
Trigram: {“I love natural”, “love natural language”, “natural language processing”}
Four-gram: {“I love natural language”, “love natural language processing”} - N-gram 模型的基本假设是当前词的出现只与前面的 n-1 个词相关,而与其他词无关。这种模型可以用于语言建模、文本生成、机器翻译等任务。一般来说,N 越大,模型捕捉的上下文信息越丰富,但也需要更多的数据来估计模型参数。
- N-gram 模型的局限性在于它无法捕捉长距离的依赖关系,因为它仅考虑相邻的 n 个词。更复杂的模型,如神经网络的语言模型,通常被用来处理更大范围的语境依赖。
K均值(K-Means) 聚类算法
- 当然,聚类算法也可以作为无监督学习的一种学习算法。
- K-Means 算法是一种聚类算法。其典型计算步骤如下:
(1)从数据点中随机选择数量与簇的数量相同的数据点,作为这些簇的重心。
(2)计算数据点与各重心之间的距离,并将最近的重心所在的簇作为该数据点所属的簇。
(3)计算每个簇的数据点的平均值,并将其作为新的重心。
(4)重复步骤 2 和步骤 3,直到所有数据点不改变所属的簇,或者达到最大计算步数。
概念:词嵌入(Word Embedding)
- 词嵌入是一种将词语映射到实数向量空间的技术,通过这种表示,词语之间的语义关系可以在向量空间中更好地体现。
- 【学习词嵌入一般都是无监督学习的。但词嵌入可以作为一个底层工具,为后续的比如其他预训练和微调学习提供帮助。】
- 独热编码 One-Hot Encoding
一个单词对应一个n维向量,n为词汇表大小,向量只在某个位置为1,比如 Love 可能对应 (0,0,1,0, ……,0,0) - 词向量 Word Vector
一般来说,一个单词对应一个n维向量,n一般为固定超参数,每个位置的值都是实数,比如 Love 可能对应 (0.0384, 0.1235, ……, 0.8997)
NLP(一)Word Embeding词嵌入 - 引申:句子嵌入(Sentence Embedding)
要为一个句子生成句子嵌入,最基本的方法是对该句子中出现的所有单词进行平均词嵌入。
Word2Vec 预测模型,词嵌入算法
- Word2Vec,主要包含连续词袋模型(CBOW)和SG(SkipGram)模型。
(1)CBOW模型通过上下文中的周围词语来预测目标词语。模型的目标是最大化给定上下文条件下目标词语的条件概率。
(2)SG模型与CBOW相反,它通过目标词语来预测上下文中的周围词语。Skip-Gram旨在最大化给定目标词语条件下周围词语的条件概率。 - 注意,BOW词袋模型和CBOW连续词袋模型不是同一个概念,一个是文本的向量表示作用,一个是词嵌入的方法

- 但是可能有人问,这个不是预测模型嘛,但它同时也是强大而经典的词嵌入工具
- 更详细的词嵌入学习过程,可以查看如下知乎2.2和2.3节
Graph Embedding之从word2vec到node2vec
GloVe (Global Vectors for Word Representation) 词嵌入算法
- GloVe 是一种基于全局词-词共现统计的方法,即共同利用了全局信息和局部信息。它通过对整个语料库中词语的共现信息进行建模,使用奇异值分解(SVD)来学习词向量。GloVe生成的词向量在语义上捕捉了词语之间的关系。Glove的计算效率很高、效果也很好。
- 总体来看,Glove可以被看作是更换了目标函数和权重函数的全局Word2Vec。
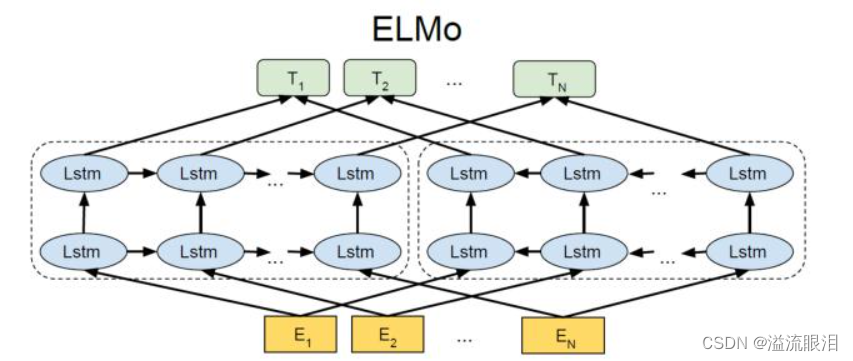
ELMo(Embeddings from Language Models) 词嵌入模型
- ELMo 使用双向LSTM(Long Short-Term Memory)模型,通过学习上下文中的信息来生成词向量。ELMo的独特之处在于,它将词语表示为多个不同层次的语境敏感表示,使其能够更好地捕捉词语的语义变化
- 虽然经典,但貌似现在用的流行方向都转变为GPT系列,BERT系列去了
BERT (Bidirectional Encoder Representations from Transformers)语言模型,词嵌入模型
- 使用 BERT 词嵌入的优点:
(1)上下文敏感性: BERT 通过预训练阶段,使用大规模的无标签语料库,学习了深层次的上下文表示。这使得生成的词嵌入能够更好地捕捉词语在不同上下文中的语义变化和依赖关系。
(2)双向性: 与传统的单向语言模型不同,BERT 是一个双向模型,它考虑了输入序列中每个位置的上下文信息。这有助于更好地理解文本中的语境和关系,使得生成的词嵌入更加全面。
(3)适应不同任务: BERT 的预训练模型可以被微调用于各种下游任务,如文本分类、命名实体识别、问答等。这种通用性使得 BERT 在多个自然语言处理任务中都能够表现出色。
(4)Transformer 架构: BERT 基于 Transformer 模型架构,这种架构在处理长距离依赖和捕捉上下文信息方面表现出色。Transformer 的自注意力机制允许 BERT 考虑输入序列中的所有位置,而不受限于固定的窗口大小。
(5)大规模预训练: BERT 的预训练模型使用了庞大的语料库进行训练,这使得模型能够学到更丰富的语言知识和表示。预训练阶段中的掩码语言模型任务和下一句预测任务帮助模型学到了深层次的语言理解。
(6)开源和预训练模型: BERT 的预训练模型已经在开源平台上发布,研究者和从业者可以直接使用这些预训练模型,从而避免了从头开始训练庞大的语言模型的复杂性。 - BERT 词嵌入的方法:神经网络算法 - 一文搞懂BERT(基于Transformer的双向编码器)
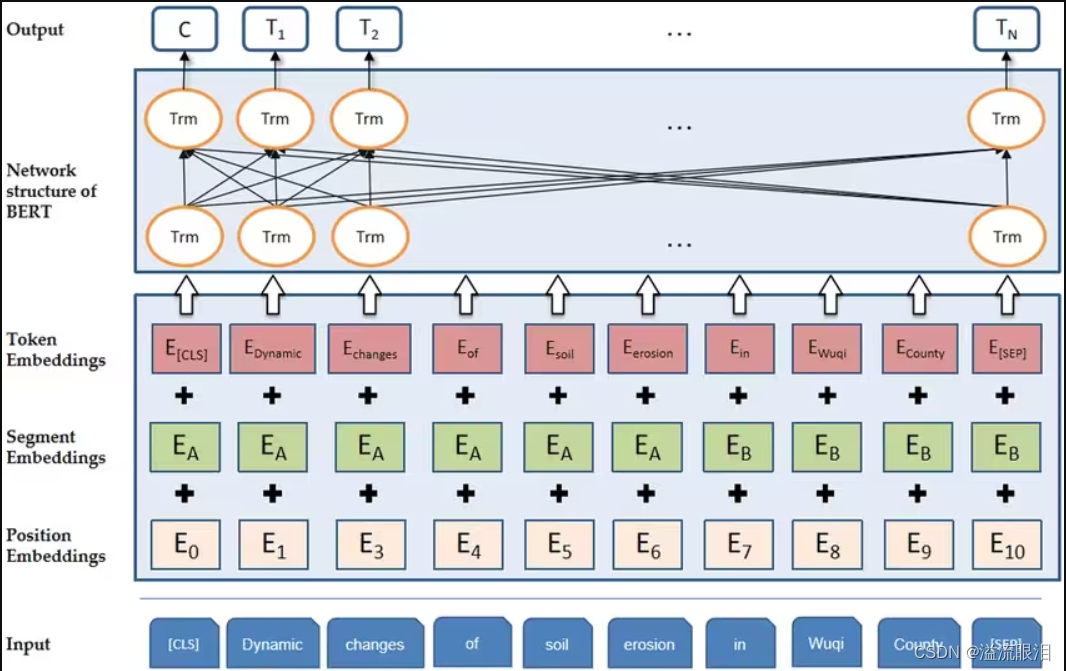
(1)Tokenization: 输入文本首先通过分词器(Tokenizer)被分割成Token。这一步通常包括将文本转换为小写、去除标点符号、分词等。BERT使用WordPiece分词方法,将单词进一步拆分成子词(subwords),以优化词汇表的大小和模型的泛化能力。
(2)Token Embeddings: 分词后的Token被映射到一个高维空间,形成Token Embeddings。这是通过查找一个预训练的嵌入矩阵来实现的,该矩阵为每个Token提供一个固定大小的向量表示。
(3)Segment Embeddings: 由于BERT能够处理两个句子作为输入(例如,在句子对分类任务中),因此需要一种方法来区分两个句子。Segment Embeddings用于此目的,为每个Token添加一个额外的嵌入,以指示它属于哪个句子(通常是“A”或“B”)。
(4)Position Embeddings: 由于Transformer模型本身不具有处理序列中Token位置信息的能力,因此需要位置嵌入来提供这一信息。每个位置都有一个独特的嵌入向量,这些向量在训练过程中学习得到。
(5)Token Embeddings、Segment Embeddings和Position Embeddings三者相加,得到每个Token的最终输入嵌入。
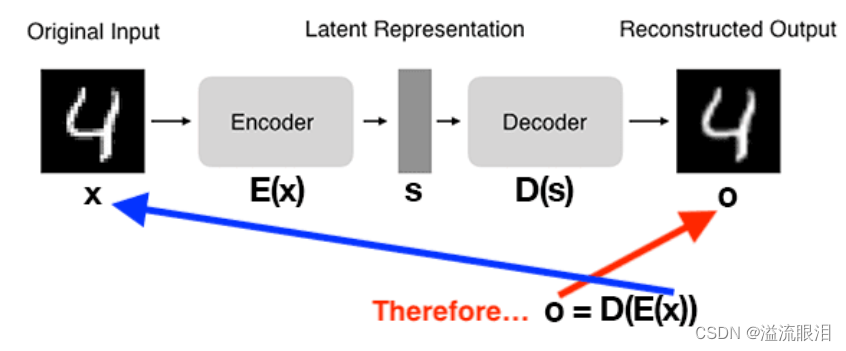
AE 自动编码器(AutoEncoder)人工神经网络
- Autoencoder 是一种无监督学习的神经网络模型,其目标是学习数据的紧凑表示(编码)以及用于重建原始数据的解码器。
- 在NLP中,AE可以做如下任务:
词嵌入,降维和特征选取,去噪,文本生成和重建,异常检测等 - AE 的步骤:
(1)接受一组输入数据(即输入);
(2)在内部将输入数据压缩为潜在空间表示(即压缩和量化输入的单个向量);
(3)从这个潜在表示(即输出)重建输入数据。
自动编码器(AutoEncoder)简介 - 比较火的有CAE卷积自编码,DAE降噪自编码,VAE变分自编码
但是大多在CV比较火
概念:NLP中的编码器(Encoder)和解码器(Decoder)
- 在自然语言处理(NLP)中,Encoder 和 Decoder 是神经网络中常用的两个组件,尤其在序列到序列(seq2seq)模型中广泛应用。这种结构通常用于机器翻译、文本生成等任务。
- Encoder(编码器)
作用: 编码器负责将输入序列(例如源语言句子)映射为一个中间的表示(通常是固定维度的向量),该表示捕捉了输入序列的语义信息。
结构: 编码器通常由循环神经网络(RNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)或更现代的 Transformer 架构组成。这些模型能够逐步处理输入序列并捕捉其上下文信息。 - Decoder(解码器)
作用: 解码器接受编码器生成的中间表示,并将其转换为目标序列(例如目标语言翻译的句子)。
结构: 解码器也可以使用 RNN、LSTM、GRU 或 Transformer 架构。解码器的设计允许它逐步生成目标序列,考虑到上下文信息和之前生成的部分。
概念:分词器(Tokenizer),词嵌入(Word Embedding)和编码器(Encoder)的区别
从词到数:Tokenizer与Embedding串讲
- 【Tokenizer 】用于文本预处理,将文本转化为离散表示的词语序列,也就是tokens序列。
huggingface的一些模型使用中,在使用模型前,都需要过一遍tokenizer
输入为一个句子(str)
输出为一个id数组(List[int])
事实上,tokenizer总体上做三件事情:
(1)分词。tokenizer将字符串分为一些sub-word token string,再将token string映射到id,并保留来回映射的mapping。从string映射到id为tokenizer encode过程,从id映射回token为tokenizer decode过程。映射方法有多种,例如BERT用的是WordPiece,GPT-2和RoBERTa用的是BPE等等,后面会详细介绍。
(2)扩展词汇表。部分tokenizer会用一种统一的方法将训练语料出现的且词汇表中本来没有的token加入词汇表。对于不支持的tokenizer,用户也可以手动添加。
(3)识别并处理特殊token。特殊token包括[MASK], <|im_start|>, <sos>, <s>等
注:一般,BERT族用的为WORD-PIECE,GPT族用的是BPE,更详细介绍请看后文知乎链接。

- 【Word Embedding】 用于将词语映射为实数向量,捕捉词语的语义信息。
通过分词器之后得到的tokens序列作为输入,经过词嵌入转换成密度更高的词向量,也叫embedding编码。 - 现在Huggingface(后文简称HF)的很多模型会一起把词嵌入矩阵(Embedding Matrix)也训练好。
这样,根据我们输入的tokens序列,直接按照表格就可以查找好我们要的词嵌入向量。
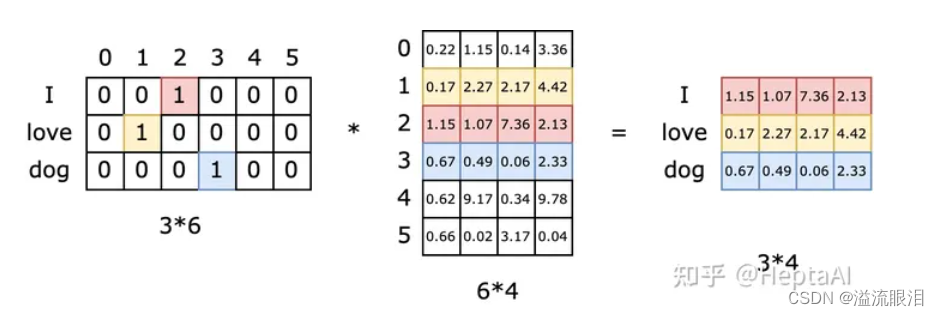
- 但这样我们发现,这样只有词的语义信息,并没有上下文信息。所以这只是词嵌入的一种比较基础的方法,或者需要经过后续加工。上文也提到了其他的一些方法。下文也会介绍更先进的方法,包含上下文语义的信息。
- 【Encoder 】接收经过 Tokenizer 处理和经过 Word Embedding 映射的输入序列,生成一个表示,传递给模型的下一层。
Encoder 或者 Decoder,是人工神经网络中的一层结构。提到这俩,就不得不提到 Transformer 架构了
概念:Transformer架构
- The Illustrated Transformer
这篇以比较简单易懂的方式阐述了 Transformer 架构的一些内容
如何最简单、通俗地理解Transformer?
也参考了一些知乎回答 - Transformer是一种架构,它使用注意力来显著提高深度学习 NLP 翻译模型的性能,其首次在论文《Attention is all you need》中出现,并很快被确立为大多数文本数据应用的领先架构。
- 比如一个二层堆叠的编码器和解码器的 Transformer 架构就如下图所示
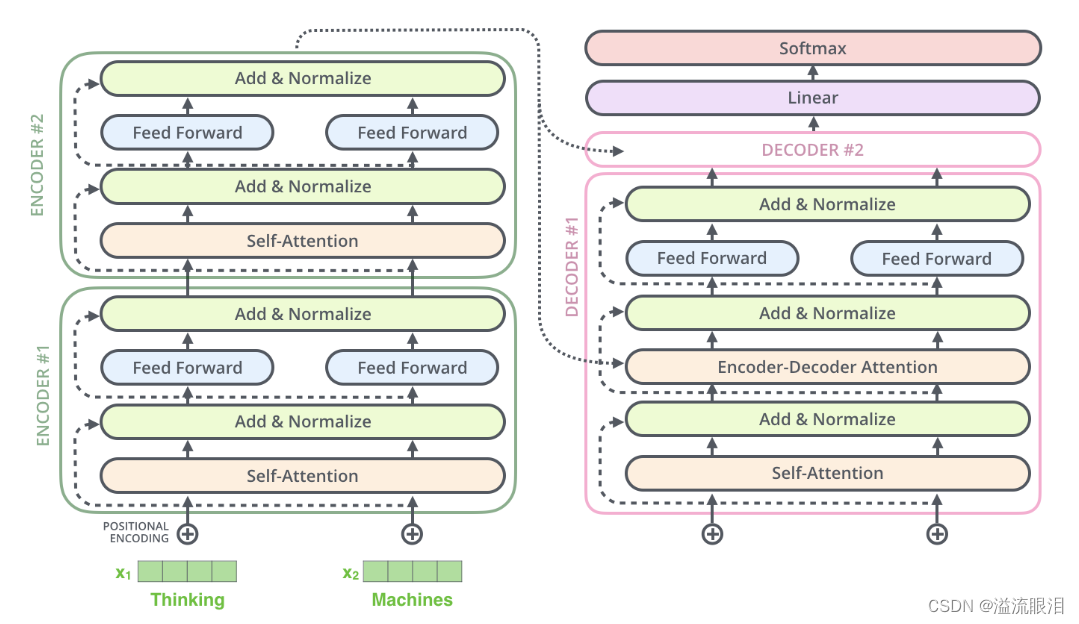
- 在编码器堆栈和解码器堆栈之前,都有对应的嵌入层。而在解码器堆栈后,有一个输出层来生成最终的输出。
- 编码器一般有两个子层:包含自注意力层 self-attention,用于计算序列中不同词之间的关系;同时包含一个前馈层 feed-forward。
- 解码器一般有三个子层:包含自注意力层self-attention,前馈层 feed-forward,编码器-解码器注意力层 Decoder-Encoder self attention。
- 每个编码器和解码器都有独属于本层的一组权重。
- 需要注意的是,编码器的自注意力层及前馈层均有残差连接以及正则化层。(就是图中的 残差链接Add & 正则化Normalize)
- Transformer 的突破性表现关键在于其对注意力的使用。
可以详细去看一下里面的自注意力机制,多头注意力机制。
概念:Encoder 模型,Decoder 模型,Seq2Seq 模型
机器学习中的encoder,decoder和embedding都有什么区别?
- 按照是否使用 Transformer 架构中的 Encoder 和 Decoder,我们把模型分成如下三类
- Encoder 模型仅使用 Transformer 中的 encoder。在每个阶段,注意力层都可以访问原始句子中的每个单词。这种模型通常拥有“双向注意力”的特点,常被称作自编码模型(auto-encoding models),简称AE。
- Decoder 模型仅使用 Transformre 中的 decoder。在每个阶段,注意力层仅能访问给定单词在句子中之前位置的单词。这种模型常被称作自回归模型(auto-regressive models),简称AR。
- Encoder-decoder 模型(也称 Seq2seq (sequence-to-sequence) 模型)同时使用 Transformer 的两个部分。在每个阶段,encoder 的注意力层都可以访问原始句子中的每个单词,而 decoder 的注意力层只能注意力层仅能访问给定单词在输入句子中之前位置的单词。

概念:预训练任务
- 预训练任务是指在大规模无标签数据上训练语言模型时使用的任务。通过这些任务,语言模型能够学到文本中的深层次表示,捕捉语言的语法、语义和上下文关系。
MLM 遮蔽语言模型(Masked Language Model)预训练任务
- BERT预训练的任务MLM和NSP
详细可以看这篇介绍MLM和NSP - MLM是很多LLM最经典的预训练任务了
在一个句子中,随机选中一定百分比(实际是15%)的token,将这些token用"[MASK]“替换。然后用分类模型预测”[MASK]"实际上是什么词
NSP 下句预测(Next Sentence Prediction)预训练任务
- 对于很多重要的下游任务比如问答(Question Answering,QA)和自然语言推理(Natural Language Inference,NLI),都需要理解两个句子之间的关系。为了训练一个理解句子关系的模型,作者提出了Next Sentence Prediction(NSP)任务。即每个样本都是由A和B两句话构成,分为两种情况:①、句子B确实是句子A的下一句话,样本标签为IsNext;②、句子B不是句子A的下一句,句子B为语料中的其他随机句子,样本标签为NotNext。在样本集合中,两种情况的样本占比均为50%。
- 在刚开始发现NSP对模型的提升性能不是很大。但是也有论文指出有一些作用。
其他一些经典的预训练任务
- BERT的预训练任务为MLM和NSP,但是GPT它是自回归模型,注意力只关注目前位置及其左边的单词,所以预训练任务不能使用MLM,而选择 Autoregressive Language Modeling 预训练,即训练模型来预测给定上下文中的下一个词
- 因果语言建模(Causal Language Modeling),与 Autoregressive Language Modeling 呼应,也是只关注上文的tokens,预测下一个词。
(笔者感觉这俩个差不多是一个东西?有待存疑) - 对比学习(Contrastive Learning), 学习将正例(相似的样本)与负例(不相似的样本)区分开。在CV使用比较多。
概念:NLU,NLG,NLI
- NLG 自然语言生成(Natural Language Generating), NLI 自然语言推理(Natural Language Inference)和 NLU 自然语言理解(Natural Language Understanding)是自然语言处理中不同但相关的任务。
- NLG:在大规模无标签语料库上预测下一个词语或一段文本。关注的是如何将计算机生成的信息转化为可读的、自然的文本。NLG的任务包括文本摘要、对话系统的回复生成、文本创作等。
- NLI:预测一个文本是否蕴含在另一个文本中,即判断两个文本之间的关系(蕴含、矛盾、中立)
- NLU:关注的是理解和解释人类语言的能力。它涉及从文本中提取有关语言结构和语义的信息,使计算机能够理解文本的含义。NLU的任务包括实体识别、关系抽取、情感分析等。
- 所以可以发现,NSP是NLI的任务,而MLM/CLM 则关注 NLU+NLG
自监督学习 Self-Supervised Learning
-
自监督学习是一种机器学习的范式,其中模型从输入数据中自动生成标签或目标,而不需要人工标注的真实标签。在自监督学习中,模型通过设计一些任务来自己生成训练目标,然后通过最小化预测和生成目标之间的差异来学习有用的表示。
-
然后我们发现,在预训练阶段,我们给定的是无标注的文本,但是在训练过程中或多或少都需要该数据的标签呀!只不过我们是使用比如算法,或者模型,或者人工神经网络之类的进行自动计算了。
-
即在很多情况下,无监督学习作为预训练的方式就是自监督学习的一种形式。
-
下一篇就讲讲微调和监督学习吧。




![[MFC] MFC消息机制的补充](https://img-blog.csdnimg.cn/direct/d83f3c72202e45009a49441f0c4ca183.png)