HI,朋友们好,「爬虫职海录」第二期更新啦!
本栏目的内容方向会以爬虫相关的“岗位分析”和“职场访谈”为主,方便大家了解一下当下的市场行情。
本栏目持续更新,暂定收集国内主要城市的爬虫岗位相关招聘信息,有求职和跳槽打算的小伙伴们,可以多多关注。
本期为广州篇!
这不马上就要过年了,每年这时候都有很多小伙伴按捺不住,想要跳槽或者观望观望。
这两年行情不好,大家转行or跳槽,都需要多做功课,慎重做决定。
本次我依然从招聘网站找来了300+份当前广州的爬虫岗位JD,数据不一定很全面,但保证很热乎~
若是能帮到大家,K哥荣幸之至,要是没啥用,那就权当看看图一乐!

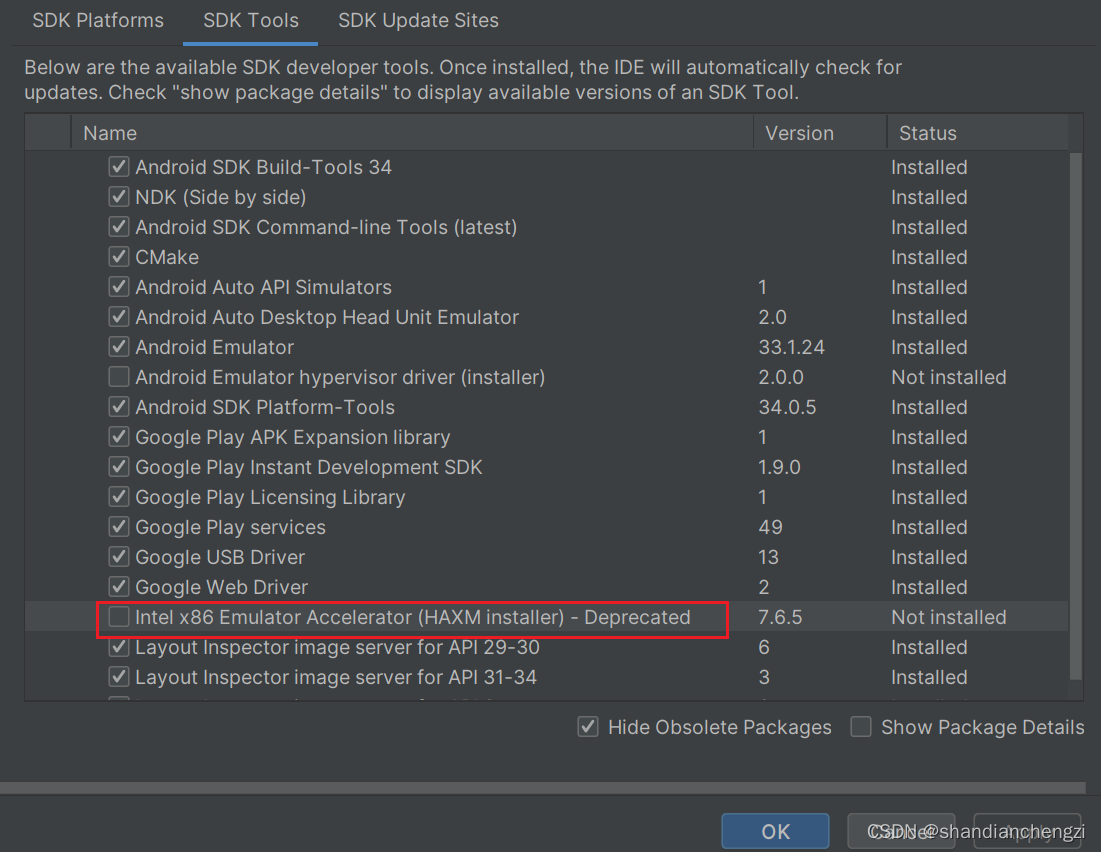
(各大城市当前爬虫工程师岗位收入)
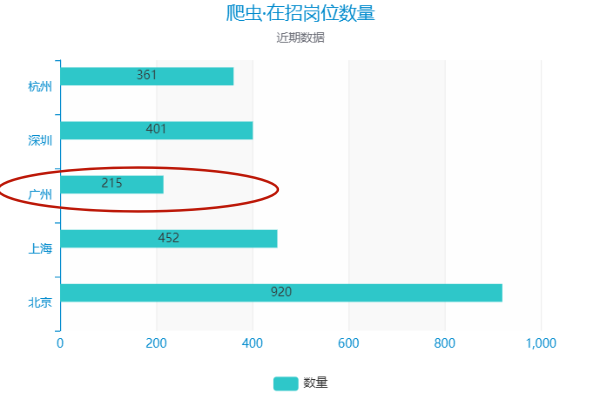
(各大城市当前爬虫工程师岗位需求)
要了解一个城市对于某一岗位的友好程度,是需要同比其他城市的,所以我一共找来了北上广深杭5个城市的相关数据做参照。
可以看到,目前广州的爬虫工程师们,平均收入为12269元,收入中位数是11500元,
同时根据已公布数据可知,广州市2023-2024年度的平均工资为11300元,大家可以自行对比对比。
数据很直观,相较其他一线城市,广州的岗位数量和工资水平确实没有优势。
下边我们再看看当下的实际招聘情况。

(广州当前爬虫岗位招聘薪资)
招聘信息上挂出的薪酬,月薪大多在10~15K这个大区间内,还满足你的要求吗?
另外K哥在收集招聘信息时,顺便为大家整理了一些关键词,包括公司行业、公司规模、岗位title、技能标签、学历要求、福利待遇等方面,兄弟们可以瞅瞅。

(广州爬虫岗位招聘信息词云图)
可以看到,“本科”、“20—99人”、“1—3年”、“年终奖”、“互联网”、“大专”、“五险一金”、“Sql”、“Java”、“python” 这些词在招聘jd里高频出现,反映了大部分公司当前的招聘情况。
K哥锐评—城市&岗位
guang zhou
岗位情况:★★★(3)
目前在一线城市中,广州的爬虫工程师相关岗位是最少的,岗位竞争压力相对较大。
但另一方面,工作经验在3年内就符合条件的岗位占比达到47.7%,相较于北京大量稀缺3-5年经验的爬虫工程师,广州对初级或者刚毕业的爬虫工程师会更加友好。
薪酬水平:★★★(3)
广州的爬虫岗工资确实不算高,但这只是相对其他几个一线城市而言,从另一方面来讲,已经跑赢了广州市的平均月薪啦。
城市潜力:★★★★(4)
尽管岗位数量和薪资水平都不占优,但大家还要看到,广州在吃住方面的生活成本同样是相对较低的,毕竟每个月工资再高,只有“可支配收入”才是真的。
况且“食在广州”、“气候宜人”也为广州的城市魅力加分不少~
综合得分:★★★★★★★★★★(10)
我认为,工资水平是选择城市&岗位的重要标准,但不会是唯一标准。
若你饮食清淡,不喜寒冷,那么广州应该是个还不错的选择!
广州丨爬虫岗位
(以下岗位为随机列举,信息来源——BOOS直聘)
探迹
-1000-9999人
-互联网 SaaS
地址|广州海珠区智通广场C塔16层
爬虫开发
20-35K·14薪
- 职位详情:
- 1、发挥创造性思维,用专业技术攻坚数据采集与应用难题;
- 2、用技术赋能数据采集,帮助数据产品经理稳靠把握数据情况,确保数据更新快、准、全;
- 3、设计搭建大规模分布式爬虫系统、大规模APP采集系统,以及其他相关服务系统;
- 4、分析开发效率瓶颈,利用devops手段,实现爬虫采集工具化、自动化、平台化,提高爬虫团队生产效率;
- 5、使用容器化技术,解决系统自动化部署及爬虫资源分配问题。
- 任职要求:
- 1、本科以上学历,计算机相关专业,熟悉操作系统(多线程、多进程)、计算机网络编程、数据结构与算法等基础知识;
- 2、3年以上Linux环境下常用语言
- (C/C++/JAVA/Python)开发经验,熟练使用常用Linux命令;
- 3、1年以上大规模网页爬虫开发经验,熟悉浏览器原理、前端JS、AJAX;
- 4、深入了解前端JS反爬,能解决前端动态JS混淆问题;
- 5、深入了解非逆向、非侵入式手机APP采集方法;
- 6、熟悉了解容器化编排技(swarm/k8s/mesos);
- 7、熟练使用一门以上脚本语言
- (Python/Javascript);
- 8、熟练使用一种以上的数据库
- (Mongodb/HBase/MySQL);
- 9、有前后端或大数据项目开发经验优先;
- 10、有分布式系统设计开发落地经验优先。
- 其他:
- 上午09:00 - 下午06:00 双休
————————————————
网易游戏
-10000人以上
-游戏
地址|广州侨鑫国际
高级爬虫工程师
20-30K
- 职位详情:
- 1.负责多平台信息爬取和页面内容的提取分析;
- 2.研究各种网站、网页、链接的形态,发现它们的特点和规律;
- 3.解决技术疑难问题,包括反反爬、压力控制等;
- 4.设计各种策略和算法,提升抓取效果;充分利用带宽资源,避免限制,
- 5.参与搭建通用爬虫系统。
- 任职要求:
- 1.计算机及相关专业,本科以上学历,3年以上工作经验;
- 2.精通计算机网络,熟练掌握Python,Java,多线程,HTML,JS/CSS等技术,熟悉Scrapy框架或其他的Web scraping framework;
- 3.精通网页抓取原理及技术,精通正则表达式,能从结构化的和非结构化的数据中获取信息;
- 4.有丰富的Linux系统使用经验,熟悉MySQL、Redis等,熟悉Internet基本协议(如TCP/IP,HTTP等);
- 5.能够解决封账号、封IP采集、验证码识别、图像识别等问题,解决网页抓取、信息抽取等问题,构建完善的网络信息收集平台;
- 6.有分布式爬虫架构经验者优先;
- 7.具有文本分析、数据挖掘、自然语言处理、信息检索、机器学习背景者优先;
- 其他:
- 上午9:30 - 下午6:00 双休
————————————————
臻悦票务服务
-20-99人
-旅游.景区
地址|广州海珠区粤民大厦1616
高级逆向工程师
20-25K
- 职位详情:
- 1、负责网络爬虫系统的设计与开发;
- 2、负责和业务沟通抓取需求,满足业务的发展需要;
- 3、负责大数据产品所需网站的信息抓取、解析、清洗等研发与优化工作;
- 任职要求:
- 1、熟练掌握js,js逆向经验
- 2、能够解决常见的验证码,包括不限于字符、滑块、等等
- 3、熟悉做过 阿卡迈 或者了解 阿卡迈 和reese84
- 4、具备数据处理和清洗能力,从原始数据中提取有用的信息负责多平台信息爬取和页面内容的提取分析
————————————————
钱大妈
-1000-9999人已上市
-生活服务(O2O)
地址|广州海珠区钱大妈(总店)海珠区钱大妈总部
爬虫工程师
15-25K·13薪
- 职位详情:
- 1、负责设计和开发通用爬虫系统,进行多平台信息的抓取、清洗和消重等工作;
- 2、负责实时监控爬虫的进度和警报反馈;
- 3、研究各种网站、链接的形态,发现它们的特点和规律;
- 4、解决技术疑难问题,包括反反爬、压力控制等,提升网页抓取的效率和质量。
- 任职要求:
- 1、熟悉Linux系统,精通python,熟练使用多线程,熟悉Scrapy等常用爬虫框架;
- 2、熟悉爬虫原理,掌握网页抓取原理及技术,熟悉基于正则表达式、XPath、CSS等网页信息抽取技术;
- 3、熟悉常见的反爬虫技术,能够解决封账号、封IP、验证码识别、图像识别等问题;
- 4、有大规模数据提取、数据处理、分布式爬虫架构经验等经验者优先。
- 5、有前端动态 JS 逆向工程经验优先;
- 6、有非逆向、非侵入式手机APP采集经验优先;
- 其他:
- 上午09:00 - 下午06:00 双休
- 工作午餐
————————————————
用实
-20-99人
-计算机软件
地址|广州海珠区琶洲新村-2栋B座3907室
Python高级爬虫工程师
12-24K
- 职位详情:
- 1.负责国内主流电商平台数据爬虫的研发工作
- 2.评审爬虫团队的技术解决方案,指导技术攻坚
- 3.负责搭建Python任务的调度监控后台
- 任职要求:
- 1.6年以上工作经验,4年以上Python爬虫经验,本科及以上学历
- 2.精通爬虫和反爬虫技术,需有丰富的爬虫项目研发经验
- 3.有掌握开源项目或前后端开发经验
- 4.熟悉Linux,能配置、部署和运维应用服务
- 5.至少熟悉Mysql、SQL server、PostgresQL一种数据库的使用
- 6.主动负责,热爱编程,乐于挑战,有良好的团队协作精神
- 加分项:
- 1.有天猫、京东、抖音等国内主流平台的项目经验
- 2.有App端数据采集经验
- 3.有部署Airflow或DolphinScheduler或xxl-job等开源调度平台经验
- 4.有浏览器插件采集数据经验
- for 面试官:
- 5.需精通爬虫反爬虫,爬虫经验丰富,工作7年8年较佳
- 6.学历本科
————————————————
卓进创新跨境
-20-99人
-电子商务
地址|广州番禺区万达广场(广州番禺店)307
高级Python 爬虫工程师
75-120元/时(兼职)
- 职位详情:
- 1、负责爬取HTML页面所需数据,并对数据进行清洗、解析、归档、输出等;
- 2、负责设计和开发分布式的网络爬虫,数据的采集与爬取、调度、监控、自动化运行等;
- 3、负责实时监控爬虫的进度和警报反馈,提升爬虫系统稳定性、可扩展性。
- 4、负责js渲染抓取,反爬虫策略研究,验证码识别等采集支撑服务建设;
- 5、参与公司业务平台的数据的挖掘和分析,协助进行产品改进。
- 任职资格:
- 1. 本科以上,计算机或相关专业毕业,扎实的Python基础,熟悉多线程编程环境,熟悉常见开源框架;
- 2、熟悉基于正则表达式、XPath、CssSelector、beautifulsoup等网页信息解析技术;
- 3、熟悉Scrapy、feapder等主流爬虫框架框架,能够解决封账号、封IP、验证码、网页限制爬取等问题,且有实际经验;
- 4、熟悉常见的反爬机制,并对反爬具有一定的应对措施策略且有一定研究,如协议破解、模拟点击等;
- 5、熟悉代理IP池、Headers认证和Cookie等
____________________________
ps:
1,文中出现的岗位JD,包括薪酬,工作时间、福利等情况,均为招聘单位公示,我只是做了收集,实际情况大家可以主动联系招聘方进行咨询。
2,文中出现的岗位基本为随机选取,只作为参考,并不代表K哥推荐,我并未收取任何单位以及个人的广告费,也不提供简历投递渠道。
3,文中出现的招聘信息截至发文,仍为在招状态,后期K哥不对相关信息的有效性负责。
4,关于爬虫&职场方面的内容,大家还希望看到哪些呢,欢迎多多向我提建议,也欢迎小伙伴们在评论区积极“吐槽”自己的公司。