https://www.bilibili.com/video/BV1Kz4y1x7AK/?spm_id_from=333.337.search-card.all.click
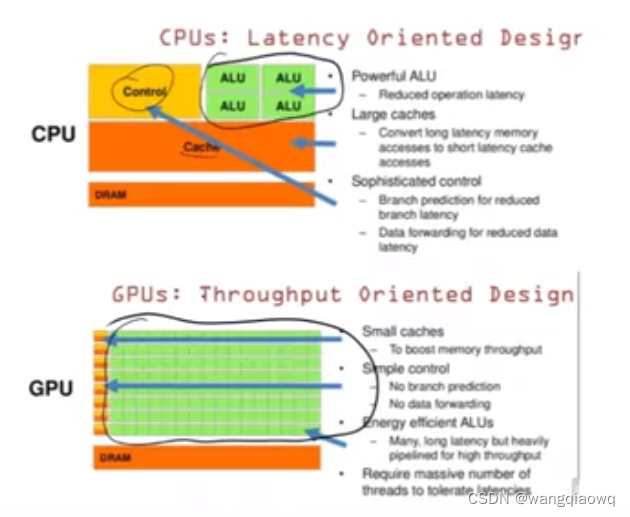
GPU 计算单元多 并行计算能力强

指数更重要

A100 80G

V100

A100
海外 100元/时 单卡
多卡并行:

单机多卡
模型并行
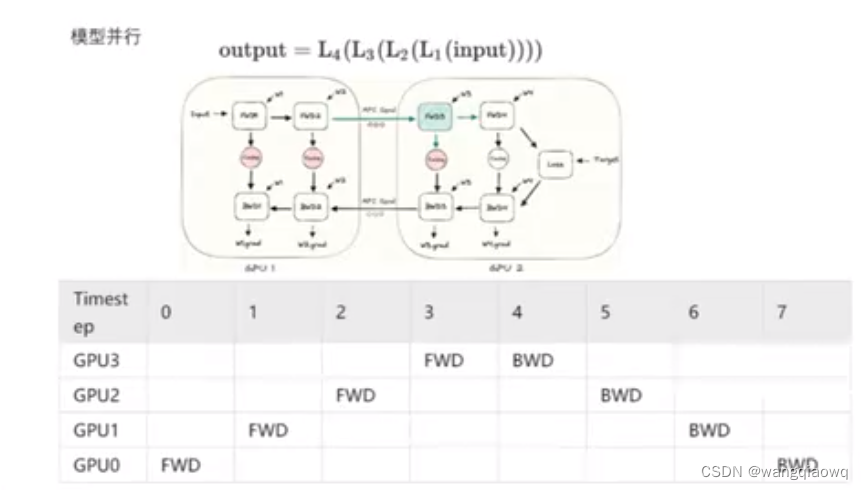
有资源的浪费
反向传播
反向传播(Backpropagation,简称BP)是一种用于训练人工神经网络的关键算法,特别是在多层前馈神经网络中。该算法的核心作用是计算整个网络中每个参数对损失函数的梯度,这个过程通过应用链式法则(在微积分中用于求复合函数的导数)自后向前逐层进行。
在训练神经网络时,其过程可以分为以下几个主要步骤:
-
前向传播:
- 输入数据通过网络各层从输入层到输出层进行传递。
- 每个神经元根据其权重和偏置计算输出值,并通过激活函数生成非线性转换后的结果。
-
计算损失:
- 网络的最终输出与真实标签相比较,计算出一个表示预测误差的损失函数值。
-
反向传播阶段:
- 从输出层开始,根据损失函数的梯度信息,按相反方向(即从输出层到输入层)逐层回传误差。
- 在每一层,算法计算每个权重和偏置对损失函数的影响(梯度),这是通过将当前层的梯度与上一层的梯度结合来实现的。
- 这个过程实质上是利用链式法则将输出层的误差逐步分解到每一层的参数上。
-
参数更新:
- 使用计算得到的梯度,通过优化算法(如梯度下降法、随机梯度下降、Adam等)更新网络中的权重和偏置。
- 参数更新的目标是减少损失函数的值,从而使得神经网络在下一次迭代时能够更好地拟合训练数据。
通过反复执行这些步骤,神经网络逐渐调整其内部参数以最小化损失函数,从而达到学习的目的,提高模型在未知数据上的泛化能力。
正向传播(Forward Propagation)是神经网络在训练和预测过程中,信息从输入层经过隐藏层到输出层的处理过程。具体步骤如下:
-
初始化:
- 对于给定的输入数据样本,将其作为输入层的激活值。
-
前向传播计算:
- 从输入层开始,每个神经元将接收到来自上一层(对于输入层来说则是输入数据)的所有输入信号,并根据其连接权重进行加权求和。
- 加权求和的结果加上该神经元的偏置项后,通过激活函数(如Sigmoid、ReLU等)进行非线性转换得到新的输出值。
- 这个过程在每一层重复进行,直到到达输出层。
-
计算损失:
- 输出层的最终结果与真实标签(在训练阶段提供)比较,计算模型的预测误差,通常使用交叉熵损失、均方误差等损失函数衡量。
-
评估预测结果:
- 在预测阶段,我们直接利用正向传播得到的输出层结果作为对输入样本的预测值。
简而言之,在神经网络中,正向传播是用来模拟从输入到输出的信息流动过程,用于实际预测以及为后续的反向传播计算损失函数关于各层权重的梯度做准备。在训练期间,正向传播的结果被用来确定模型预测的好坏,并启动反向传播算法以更新网络权重,从而优化模型性能。

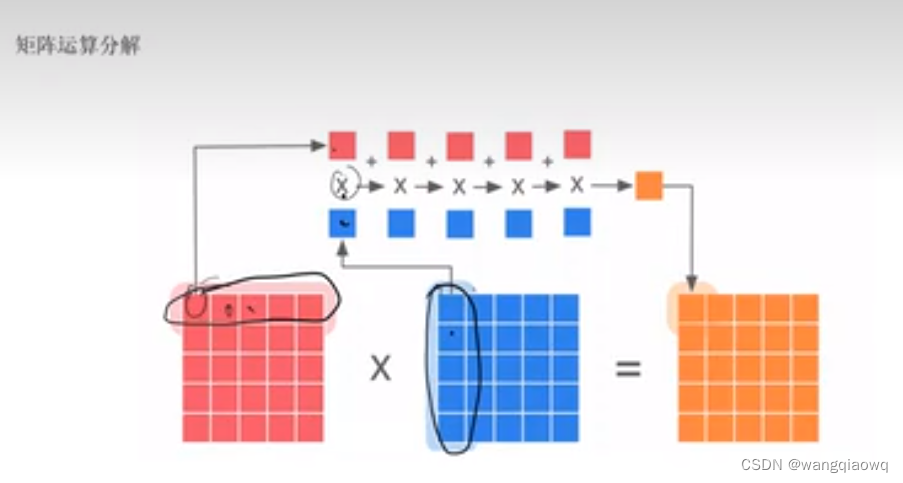
列并行
列并行(Column Parallelism)是指在计算或存储过程中,将数据集的列分割到多个处理单元上进行并行处理的技术。这种技术在大规模数据分析、机器学习和高性能计算等领域中广泛应用。
特别是在训练深度神经网络时,列并行通常用于优化权重矩阵的更新过程:
-
权重矩阵分解:
- 当模型的权重矩阵过大时,可以将其按列拆分,每个部分分配给不同的计算资源(如GPU核心、CPU核或分布式系统中的不同节点)。
-
梯度更新:
- 在反向传播阶段,每个计算单元独立地计算它所负责的那一部分权重对应的梯度。
- 各个单元同时完成梯度计算后,需要进行梯度的聚合操作以得到完整的权重梯度。
-
同步与通信:
- 为了保持整个模型的一致性,在每次参数更新之前,各个计算单元需要通过某种形式的通信机制(例如点对点通信、AllReduce操作等)来合并各自计算出的梯度。
- 合并后的全局梯度用于更新所有计算单元上的相应权重部分。
列并行的主要优势在于它可以有效地利用多核处理器或多节点集群的计算能力,从而加快大型模型的训练速度。然而,它也面临一些挑战,比如如何高效地管理和调度通信开销,以及确保算法在并行化后仍能保持良好的收敛性能。
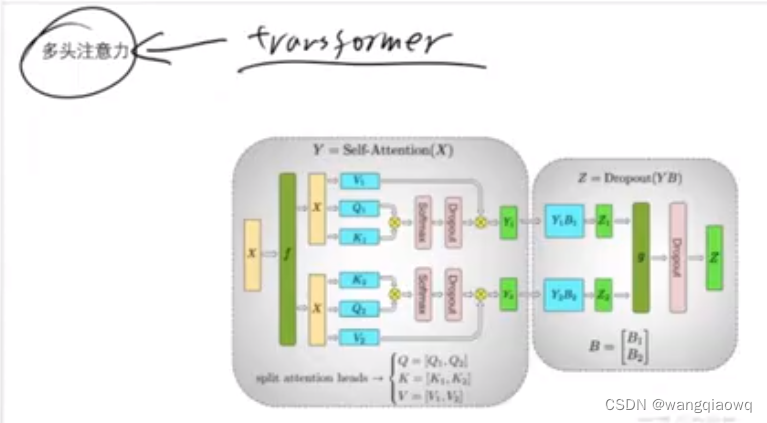
transformer
2.大模型系列-Agent到底是什么?_哔哩哔哩_bilibili








不同模型有对应的prompt
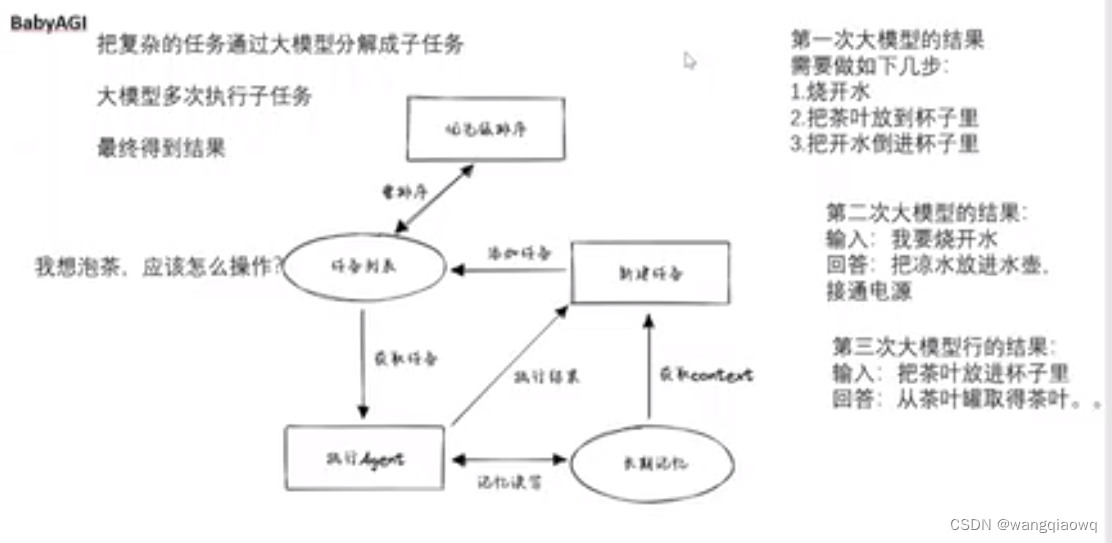
babyapi




COT



3.大模型系列-GPU原理详解(上)_哔哩哔哩_bilibili