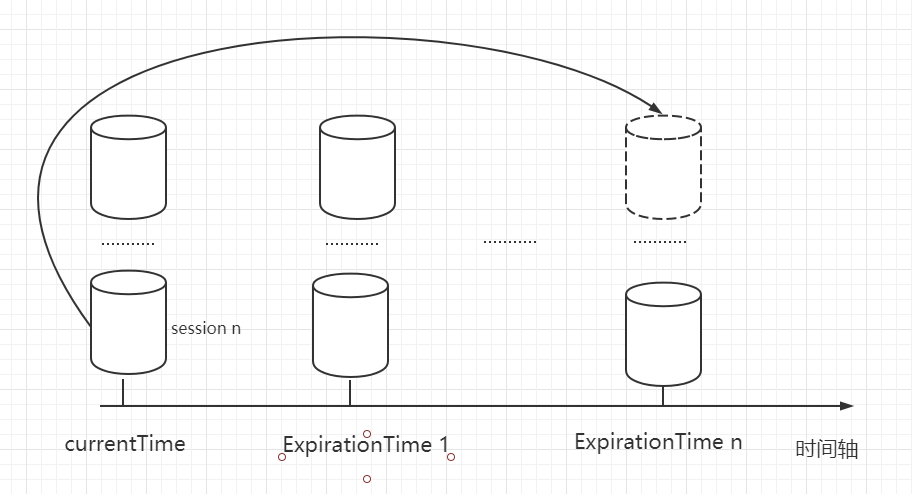
深度学习 2:第 2 部分第 8 课
原文:
medium.com/@hiromi_suenaga/deep-learning-2-part-2-lesson-8-5ae195c49493译者:飞龙
协议:CC BY-NC-SA 4.0
来自 fast.ai 课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和Rachel 给了我这个学习的机会。
目标检测
论坛 / 视频 / 笔记本 / 幻灯片
我们在第一部分中涵盖的内容 [02:00]

可微分层 [02:11]

Yann LeCun 一直在推广这样一个观点,即我们不称之为“深度学习”,而是“可微分编程”。我们在第一部分所做的一切实际上都是关于建立一个可微分函数和一个描述参数好坏的损失函数,然后按下开始按钮,它就开始工作了。如果你能配置一个评分函数来评估某个任务的表现,并且有一个相当灵活的神经网络架构,那么你就完成了。
是的,可微分编程只不过是现代深度学习技术的一个重新包装,就像深度学习是神经网络的现代化版本,具有超过两层的层次一样。
重要的一点是,人们现在通过组装参数化的功能块网络,并通过使用某种形式的基于梯度的优化从示例中训练它们来构建一种新型软件……这实际上非常类似于常规程序,只是它是参数化的,自动区分的,可训练/可优化的。
- Yann LeCun,FAIR 主任
2. 迁移学习 [03:23]

迁移学习是有效使用深度学习的最重要的单一事项。你几乎永远不会想要或需要从随机权重开始,除非没有人曾经在一个大致相似的数据集上训练过一个与你正在解决的问题有一定联系的模型 — 这几乎不会发生。Fastai 库专注于迁移学习,这使它与其他库不同。迁移学习的基本思想是:
-
给定一个执行 A 任务的网络,移除最后一层。
-
在最后随机添加几个层
-
微调这些层以执行 B 任务,同时利用原始网络学到的特征
-
然后选择性地对整个模型进行微调,现在你有了一个可能使用数量级更少的数据,更准确,训练速度更快的东西。
3. 架构设计 [05:17]

通常有一小范围的架构通常在很多时候都表现得相当不错。我们一直专注于使用 CNN 处理通常大小固定的有序数据,RNN 处理具有某种状态的序列。我们还稍微调整了一下激活函数 — 如果有单一分类结果,则使用 softmax,如果有多个结果,则使用 sigmoid。我们将在第 2 部分研究的一些架构设计更有趣。特别是关于目标检测的这个第一个会话。但总的来说,我们可能花更少的时间讨论架构设计,因为这通常不是难点。
4. 处理过拟合 [06:26]

Jeremy 喜欢构建模型的方式:
- 创建一些明显过度参数化的东西,肯定会过度拟合,训练它并确保它确实过拟合。在那一点上,你已经有了一个能够反映训练集的模型。然后只需做这些事情来减少过拟合。
如果你不从一个过拟合的地方开始,你就会迷失。所以你从一个过拟合的地方开始,为了让它过拟合得更少,你可以:
-
添加更多数据
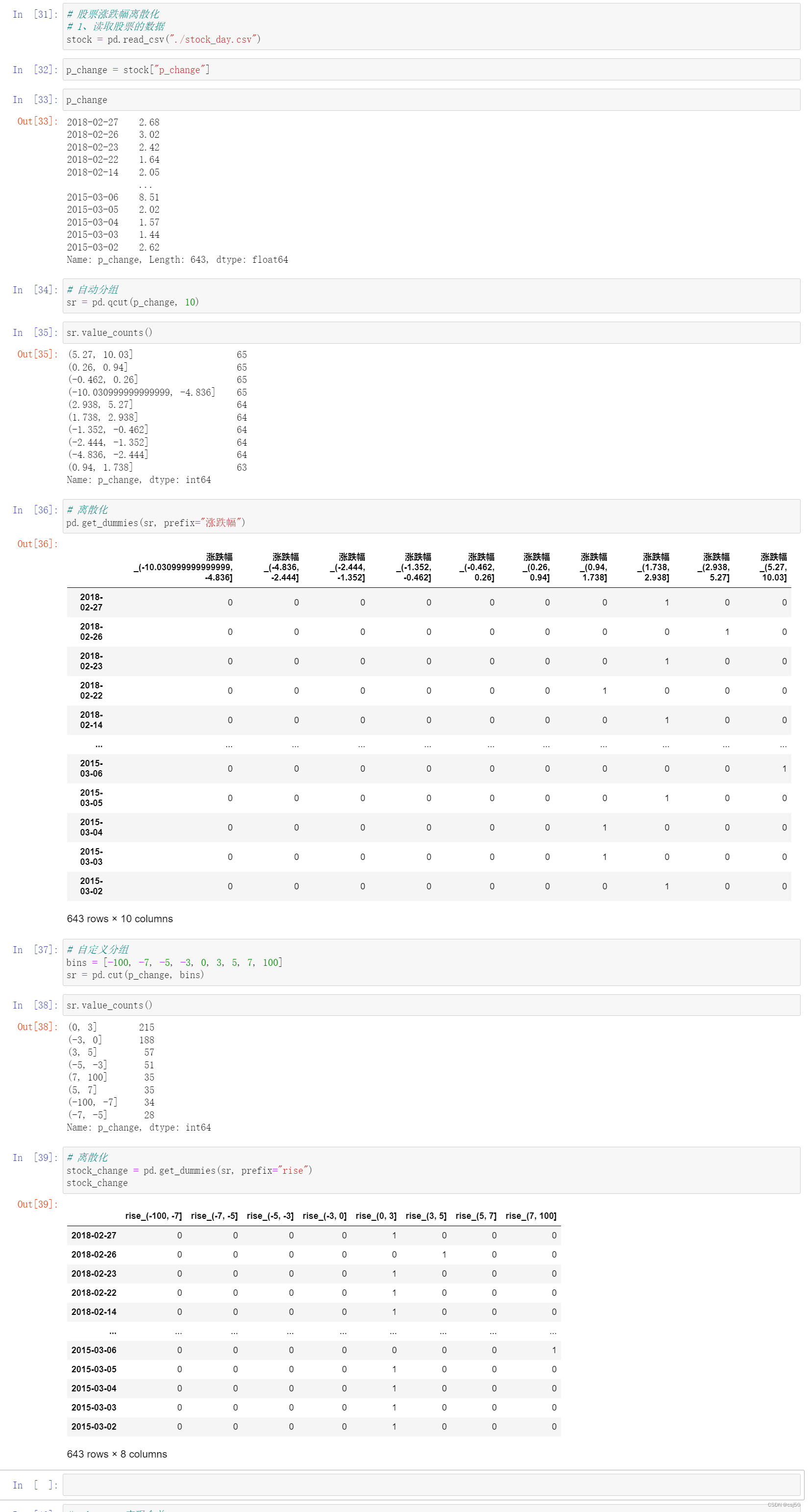
-
添加更多数据增强
-
做一些像更多的批量归一化层、稠密网络,或者各种可以处理更少数据的东西。
-
添加正则化,如权重衰减和丢失
-
最后(这通常是人们首先做的事情,但这应该是你最后做的事情)减少你的架构复杂性。减少层数或激活数量。
- 嵌入[07:46]

我们已经谈了很多关于嵌入 - 无论是用于自然语言处理还是任何种类的分类数据,现在你可以用神经网络来建模。就在今年初,几乎没有关于在深度学习中使用表格数据的例子,但现在越来越多的人开始使用神经网络来进行时间序列和表格数据分析。
第一部分到第二部分[08:54]

第一部分真的是关于引入深度学习的最佳实践。我们看到的技术已经足够成熟,可以相对可靠地应用于实际的现实世界问题。Jeremy 经过相当长一段时间的研究和调整,提出了一系列步骤、架构等,并将它们快速、轻松地放入 fastai 库中。
第二部分是面向程序员的前沿深度学习,这意味着 Jeremy 通常不知道确切的最佳参数、架构细节等来解决特定问题。我们不一定知道它是否能够解决问题到足够实用的程度。它几乎肯定不会被很好地整合到 fastai 或任何其他库中,你不能只按几个按钮就开始工作。Jeremy 不会教授它,除非他非常有信心,要么现在就是,要么很快就会成为非常实用的技术。但通常需要大量的调整和实验才能使其在你的特定问题上工作,因为我们不知道足够的细节来知道如何使其适用于每个数据集或每个示例。
这意味着与 Fastai 和 PyTorch 成为你只知道这些配方的晦涩黑匣子不同,你将学会足够了解它们的细节,以便可以按照自己的意愿定制它们,可以调试它们,可以阅读它们的源代码以了解发生了什么。如果你对面向对象的 Python 不自信,那么这是你在本课程中要专注学习的内容,因为我们不会在课堂上涵盖它。但 Jeremy 会介绍一些他认为特别有帮助的工具,比如 Python 调试器,如何使用你的编辑器跳转到代码中。总的来说,将会有更多详细和具体的代码演示,编码技术讨论,以及更详细的论文演示。
注意示例代码[13:20]!学术界提供的代码与论文配套或其他人在 github 上编写的示例代码,Jeremy 几乎总是发现有一些重大的关键缺陷,所以小心从在线资源中获取代码,并准备做一些调试。
如何使用笔记本[14:17]


构建你自己的盒子[16:50]

阅读论文[21:37]
每周,我们将实现一两篇论文。左边是一篇实现 adam 的论文摘录(你也在电子表格上看到过 adam 作为一个单独的 excel 公式)。在学术论文中,人们喜欢使用希腊字母。他们也不喜欢重构,所以你经常会看到一页长的公式,仔细看时你会意识到相同的子方程出现了 8 次。学术论文有点奇怪,但最终,这是研究界传达他们发现的方式,所以我们需要学会阅读它们。一个很好的做法是拿一篇论文,努力理解它,然后写一篇博客,在博客中用代码和普通英语解释它。许多这样做的人最终会得到相当多的关注,得到一些非常好的工作机会等,因为能够展示你能理解这些论文、在代码中实现它们并用英语解释它们是一种非常有用的技能。很难阅读或理解你无法口头表达的东西。所以学习希腊字母吧!

更多机会

第二部分的主题
生成模型
在第一部分,我们的神经网络的输出通常是一个数字或一个类别,而在第二部分中,很多东西的输出将是很多东西,比如:
-
图像中每个对象的左上角和右下角位置以及该对象是什么
-
一幅完整的图片,显示该图片中每个像素的类别
-
输入图像的增强超分辨率版本
-
整个原始输入段落翻译成法语
我们将要查看的绝大多数数据要么是文本数据,要么是图像数据。
我们将查看一些更大的数据集,无论是数据集中的对象数量还是每个对象的大小。对于那些使用有限计算资源的人,请不要因此而退缩。随时可以用更小更简单的东西替代。Jeremy 实际上在没有互联网的情况下(在 Point Leo)用 15 英寸的 surface book 写了大部分课程。几乎所有这门课程在 Windows 笔记本电脑上都能很好地运行。你可以始终使用更小的批量大小、精简版本的数据集。但如果你有资源,当可用时,使用更大的数据集会获得更好的结果。
目标检测

与我们习惯的两个主要区别:
1.我们正在对多个事物进行分类。
这并不罕见——我们在第一部分的星球卫星数据中做过这个。
2.我们正在对我们分类的事物周围加上边界框。
边界框有一个非常具体的定义,即它是一个矩形,矩形内的对象完全适合其中,但它不会比必须的更大。
我们的工作将是采用这种方式标记的数据,并在未标记的数据上生成对象的类别和每个对象的边界框。需要注意的一点是,标记这种数据通常更昂贵。对于目标检测数据集,标注者会得到一个对象类别列表,并被要求在图片中找到每一个类型的对象以及它们的位置。在这种情况下,为什么没有一个树或跳跃被标记呢?因为对于这个特定的数据集,标注者没有被要求找到它们,因此不是这个特定问题的一部分。
阶段:
-
对每个图像中最大的对象进行分类。
-
找到每个图像中最大对象的位置。
-
最后,我们将尝试同时做两件事(即标记它是什么以及在图片中的位置)。

帕斯卡笔记本
%matplotlib inline
%reload_ext autoreload
%autoreload 2
from fastai.conv_learner import *
from fastai.dataset import *
from pathlib import Path
import json
from PIL import ImageDraw, ImageFont
from matplotlib import patches, patheffects
# torch.cuda.set_device(1)
您可能会发现一行torch.cuda.set_device(1)被遗留下来,如果您只有一个 GPU,这会导致错误。这是在您有多个 GPU 时选择 GPU 的方法,所以只需将其设置为零或完全删除该行。
就像 ImageNet 是一个标准的对象分类数据集一样,还有许多标准的目标检测数据集[41:12]。经典的 ImageNet 等价物是 Pascal VOC。
Pascal VOC
我们将查看Pascal VOC数据集。这个数据集相当慢,所以您可能更喜欢从这个镜像下载。有两个不同的竞赛/研究数据集,分别来自 2007 年和 2012 年。我们将使用 2007 年的版本。您可以使用更大的 2012 年版本获得更好的结果,甚至可以将它们结合起来[42:25](但如果这样做,请注意避免验证集之间的数据泄漏)。
与以前的课程不同,我们在路径和文件访问中使用了 Python 3 标准库pathlib。请注意,它返回一个特定于操作系统的类(在 Linux 上是PosixPath),因此您的输出可能会有些不同[44:50]。大多数以路径作为输入的库可以接受pathlib对象 - 尽管有些(如cv2)不能,这种情况下可以使用str()将其转换为字符串。
Pathlib Cheat Sheet
PATH = Path('data/pascal')
list(PATH.iterdir())
'''
[PosixPath('data/pascal/PASCAL_VOC.zip'),PosixPath('data/pascal/VOCdevkit'),PosixPath('data/pascal/VOCtrainval_06-Nov-2007.tar'),PosixPath('data/pascal/pascal_train2012.json'),PosixPath('data/pascal/pascal_val2012.json'),PosixPath('data/pascal/pascal_val2007.json'),PosixPath('data/pascal/pascal_train2007.json'),PosixPath('data/pascal/pascal_test2007.json')]
'''
关于生成器的一点说明[43:23]:
生成器是 Python 3 中的一种可以迭代的东西。
-
for i in PATH.iterdir(): print(i) -
[i for i in PATH.iterdir()](列表推导) -
list(PATH.iterdir())(将生成器转换为列表)
通常返回生成器的原因是,如果目录中有 1000 万个项目,您不一定希望有 1000 万个长列表。生成器让您可以“懒惰”地执行操作。
加载注释
除了图像外,还有注释 - 显示每个对象位置的边界框。这些是手工标记的。原始版本是 XML 格式[47:59],这在现在有点难以处理,所以我们使用了更近期的 JSON 版本,您可以从此链接下载。
您可以在这里看到pathlib包含打开文件的能力(以及许多其他功能)。
trn_j = json.load((PATH/'pascal_train2007.json').open())
trn_j.keys()
'''
dict_keys(['images', 'type', 'annotations', 'categories'])
'''
这里的/不是除法符号,而是路径斜杠[45:55]。PATH/可以让您获取该路径中的子项。PATH/’pascal_train2007.json’返回一个pathlib对象,该对象具有一个open方法。这个 JSON 文件不包含图像,而是包含对象的边界框和类别。
IMAGES,ANNOTATIONS,CATEGORIES = ['images', 'annotations', 'categories'
]
trn_j[IMAGES][:5]
'''
[{'file_name': '000012.jpg', 'height': 333, 'id': 12, 'width': 500}, {'file_name': '000017.jpg', 'height': 364, 'id': 17, 'width': 480}, {'file_name': '000023.jpg', 'height': 500, 'id': 23, 'width': 334}, {'file_name': '000026.jpg', 'height': 333, 'id': 26, 'width': 500}, {'file_name': '000032.jpg', 'height': 281, 'id': 32, 'width': 500}]
'''
注释 [49:16]
-
bbox:列,行(左上角),高度,宽度 -
image_id:您需要将其与trn_j[IMAGES](上面)连接起来,以查找file_name等。 -
category_id:查看trn_j[CATEGORIES](下面) -
segmentation:多边形分割(我们将使用它们) -
ignore:我们将忽略忽略标志 -
iscrowd:指定这是该对象的一群,而不仅仅是其中一个
trn_j[ANNOTATIONS][:2]
'''
[{'area': 34104,'bbox': [155, 96, 196, 174],'category_id': 7,'id': 1,'ignore': 0,'image_id': 12,'iscrowd': 0,'segmentation': [[155, 96, 155, 270, 351, 270, 351, 96]]},{'area': 13110,'bbox': [184, 61, 95, 138],'category_id': 15,'id': 2,'ignore': 0,'image_id': 17,'iscrowd': 0,'segmentation': [[184, 61, 184, 199, 279, 199, 279, 61]]}]
'''
类别 [50:15]
trn_j[CATEGORIES][:4]
'''
[{'id': 1, 'name': 'aeroplane', 'supercategory': 'none'},{'id': 2, 'name': 'bicycle', 'supercategory': 'none'},{'id': 3, 'name': 'bird', 'supercategory': 'none'},{'id': 4, 'name': 'boat', 'supercategory': 'none'}]
'''
使用常量而不是字符串很有帮助,因为我们可以获得制表符补全,不会输错。
FILE_NAME,ID,IMG_ID,CAT_ID,BBOX = 'file_name','id','image_id','category_id','bbox'
cats = dict((o[ID], o['name']) for o in trn_j[CATEGORIES])
trn_fns = dict((o[ID], o[FILE_NAME]) for o in trn_j[IMAGES])
trn_ids = [o[ID] for o in trn_j[IMAGES]]
侧记:当人们实时看到 Jeremy 在工作时,看到他的课程后最常评论的是[51:21]:
“哇,你实际上不知道自己在做什么,是吧”。他做的 99%的事情都不起作用,而那些确实起作用的事情只占很小的比例。他提到这一点是因为机器学习,特别是深度学习,非常令人沮丧。理论上,您只需定义正确的损失函数和足够灵活的架构,然后按下训练按钮,就完成了。但如果那确实是所有需要的,那么什么都不会花费任何时间。问题在于一直到它起作用的所有步骤,它都不起作用。就像它直接进入无限大,崩溃并显示不正确的张量大小等。他将努力向您展示一些调试技术,但这是最难教授的事情之一。它需要的主要是坚韧不拔。那些非常有效的人和那些似乎走得不远的人之间的区别从来不是智力问题。它总是关于坚持下去 - 基本上是永不放弃。这在这种深度学习中尤为重要,因为您不会得到持续的奖励循环。它是一种持续的不起作用,不起作用,不起作用,直到最终起作用的过程,所以有点烦人。
让我们看看这些图像。
list((PATH/'VOCdevkit'/'VOC2007').iterdir())
'''
[PosixPath('data/pascal/VOCdevkit/VOC2007/JPEGImages'),PosixPath('data/pascal/VOCdevkit/VOC2007/SegmentationObject'),PosixPath('data/pascal/VOCdevkit/VOC2007/ImageSets'),PosixPath('data/pascal/VOCdevkit/VOC2007/SegmentationClass'),PosixPath('data/pascal/VOCdevkit/VOC2007/Annotations')]*JPEGS = 'VOCdevkit/VOC2007/JPEGImages'IMG_PATH = PATH/JPEGS
list(IMG_PATH.iterdir())[:5]*[PosixPath('data/pascal/VOCdevkit/VOC2007/JPEGImages/007594.jpg'),PosixPath('data/pascal/VOCdevkit/VOC2007/JPEGImages/005682.jpg'),PosixPath('data/pascal/VOCdevkit/VOC2007/JPEGImages/005016.jpg'),PosixPath('data/pascal/VOCdevkit/VOC2007/JPEGImages/001930.jpg'),PosixPath('data/pascal/VOCdevkit/VOC2007/JPEGImages/007666.jpg')]
'''
创建字典(键:图像 ID,值:注释)
每个图像都有一个唯一的 ID。
im0_d = trn_j[IMAGES][0]
im0_d[FILE_NAME],im0_dID
defaultdict在任何时候都很有用,当您想要为新键设置默认字典条目时。如果尝试访问不存在的键,则它会自动使其存在,并将其设置为您指定的函数的返回值(在本例中为lambda:[])。
在这里,我们创建了一个从图像 ID 到注释列表(边界框和类别 ID 的元组)的字典。
我们将 VOC 的高度/宽度转换为左上角/右下角,并切换 x/y 坐标以与 numpy 保持一致。如果给定的数据集格式不佳,请花一点时间使事情保持一致,并使它们成为您想要的方式。
trn_anno = collections.defaultdict(lambda:[])
for o in trn_j[ANNOTATIONS]:if not o['ignore']:bb = o[BBOX]bb = np.array([bb[1], bb[0], bb[3]+bb[1]-1, bb[2]+bb[0]-1])trn_anno[o[IMG_ID]].append((bb,o[CAT_ID]))len(trn_anno)
'''
2501
'''
变量命名,编码风格哲学等
示例 1
-
[ 96, 155, 269, 350]:一个边界框。正如您在上面看到的,当我们创建边界框时,我们做了几件事。首先是我们交换了 x 和 y 坐标。这样做的原因是,在计算机视觉世界中,当您说“我的屏幕是 640 乘以 480”时,宽度是高度。或者,在数学世界中,当您说“我的数组是 640 乘以 480”时,是行乘以列。因此,pillow 图像库倾向于按宽度和高度或列和行进行操作,而 numpy 则相反。其次,我们将通过描述左上角 xy 坐标和右下角 xy 坐标来进行操作,而不是 x、y、高度、宽度。 -
7:类标签/类别
im0_a = im_a[0]; im0_a
'''
[(array([96, 155, 269, 350]), 7)]
'''
im0_a = im_a[0]; im0_a
'''
(array([ 96, 155, 269, 350]), 7)
'''
cats[7]
'''
'car'
'''
示例 2
trn_anno[17]
'''
[(array([61, 184, 198, 278]), 15), (array([77, 89, 335, 402]), 13)]
'''
cats[15],cats[13]
'''
('person', 'horse')
'''
有些库采用 VOC 格式的边界框,因此当需要时,我们可以将其转换回来:
def bb_hw(a): return np.array([a[1],a[0],a[3]-a[1],a[2]-a[0]])
我们将使用 fast.ai 的open_image来显示它:
im = open_image(IMG_PATH/im0_d[FILE_NAME])
集成开发环境(IDE)简介
您可以使用Visual Studio Code(vscode - 附带最新版本的 Anaconda 的开源编辑器,或者可以单独安装),或者大多数编辑器和 IDE,了解有关open_image函数的所有信息。vscode 需要知道的事项:
-
命令面板(
Ctrl-shift-p) -
选择解释器(用于 fastai 环境)
-
选择终端 shell
-
转到符号(
Ctrl-t) -
查找引用(
Shift-F12) -
转到定义(
F12) -
返回(
alt-left) -
查看文档
-
隐藏侧边栏(
Ctrl-b) -
禅模式(
Ctrl-k,z)
如果您像我一样在 Mac 上使用 PyCharm 专业版:
-
命令面板(
Shift-command-a) -
选择解释器(用于 fastai 环境)(
Shift-command-a然后搜索“解释器”) -
选择终端外壳(
Option-F12) -
转到符号(
Option-command-shift-n并输入类名、函数名等。如果是驼峰式或下划线分隔的,您可以输入每个部分的前几个字母) -
查找引用(
Option-F7),下一个出现(Option-command-⬇︎),上一个出现(Option-command-⬆︎) -
转到定义(
Command-b) -
返回(
Option-command-⬅︎) -
查看文档
-
禅模式(
Control--4-2`或搜索“无干扰模式”)
让我们谈谈 open_image [1:10:52]
Fastai 使用 OpenCV。TorchVision 使用 PyTorch 张量进行数据增强等。很多人使用 Pillow PIL。Jeremy 对所有这些进行了大量测试,他发现 OpenCV 比 TorchVision 快 5 到 10 倍。对于星球卫星图像竞赛 [1:11:55],TorchVision 非常慢,因为他们进行了大量的数据增强,只能利用 25%的 GPU 利用率。分析器显示这一切都在 TorchVision 中。
Pillow 速度相当快,但不及 OpenCV 快,也远不及线程安全[1:12:19]。Python 有一个叫做全局解释器锁(GIL)的东西,这意味着两个线程不能同时执行 Pythonic 的事情 —— 这使得 Python 成为现代编程的糟糕语言,但我们却被困在其中。OpenCV 释放了 GIL。fast.ai 库之所以如此快,是因为它不像其他库那样为数据增强使用多个处理器 —— 它实际上使用多个线程。它能够使用多个线程的原因是因为它使用了 OpenCV。不幸的是,OpenCV 有一个晦涩的 API,文档有些晦涩。这就是为什么 Jeremy 试图让使用 fast.ai 的人不需要知道它正在使用 OpenCV。您不需要知道要传递哪些标志来打开一个图像。您不需要知道如果读取失败,它不会显示异常 —— 它会静默地返回None。

不要开始使用 PyTorch 进行数据增强或引入 Pillow —— 您会发现事情突然变得非常缓慢,或者多线程将不再起作用。您应该坚持使用 OpenCV 进行处理[1:14:10]
更好地使用 Matplotlib [1:14:45]
Matplotlib 之所以被命名为 Matplotlib,是因为它最初是 Matlab 绘图库的一个克隆。不幸的是,Matlab 的绘图库并不好,但那时候,这是每个人都知道的。在某个时候,Matplotlib 的开发人员意识到了这一点,并添加了第二个 API,即面向对象的 API。不幸的是,因为最初学习 Matplotlib 的人没有学习过 OO API,他们随后教导下一代人使用旧的 Matlab 风格 API。现在几乎没有例子或教程使用更好、更容易理解和更简单的 OO API。由于绘图在深度学习中非常重要,我们在这门课程中要学习的一件事就是如何使用这个 API。
技巧 1:plt.subplots [1:16:00]
Matplotlib 的plt.subplots是一个非常有用的包装器,用于创建图表,无论您是否有多个子图。请注意,Matplotlib 有一个可选的面向对象的 API,我认为这个 API 更容易理解和使用(尽管在线上很少有例子使用它!)
def show_img(im, figsize=None, ax=None):if not ax: fig,ax = plt.subplots(figsize=figsize)ax.imshow(im)ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)return ax
它返回两个东西 —— 你可能不会关心第一个(图形对象),第二个是 Axes 对象(或其数组)。基本上,你以前在哪里说 plt. 什么,现在你说 ax. 什么,它将绘制到特定的子图。当你想绘制多个图以便进行比较时,这很有帮助。
技巧 2:无论背景颜色如何都可见的文本 [1:17:59]
使文本在任何背景下都可见的一个简单但很少使用的技巧是使用白色文本和黑色轮廓,或者反之。这是如何在 matplotlib 中做到的。
def draw_outline(o, lw):o.set_path_effects([patheffects.Stroke(linewidth=lw, foreground='black'), patheffects.Normal()])
请注意参数列表中的 * 是 splat 操作符。在这种情况下,与写出 b[-2],b[-1] 相比,这是一个小快捷方式。
def draw_rect(ax, b):patch = ax.add_patch(patches.Rectangle(b[:2], *b[-2:], fill=False, edgecolor='white', lw=2))draw_outline(patch, 4)
def draw_text(ax, xy, txt, sz=14):text = ax.text(*xy, txt, verticalalignment='top', color='white',fontsize=sz, weight='bold')draw_outline(text, 1)ax = show_img(im)
b = bb_hw(im0_a[0])
draw_rect(ax, b)
draw_text(ax, b[:2], cats[im0_a[1]])

将所有内容打包起来 [1:21:20]
def draw_im(im, ann):ax = show_img(im, figsize=(16,8))for b,c in ann:b = bb_hw(b)draw_rect(ax, b)draw_text(ax, b[:2], cats[c], sz=16)
def draw_idx(i):im_a = trn_anno[i]im = open_image(IMG_PATH/trn_fns[i])print(im.shape)draw_im(im, im_a)draw_idx(17)

当你使用新数据集时,快速探索它的能力是值得的。
最大项目分类器 [1:22:57]
与其一次性解决所有问题,不如持续取得进展。我们知道如何找到每个图像中最大的对象并对其进行分类,所以让我们从那里开始。Jeremy 在 Kaggle 竞赛中的方法是每天半小时 [1:24:00]。在那半小时结束时,提交一些东西,并尝试比昨天稍微好一点。
我们需要做的第一件事是遍历图像中的每个边界框并获取最大的边界框。lambda 函数 只是一种内联定义匿名函数的方式。在这里,我们用它来描述如何对每个图像的注释进行排序 —— 按边界框大小(降序)。
我们从左上角减去右下角并乘以(np.product)值以获得一个面积 lambda x: np.product(x[0][-2:]-x[0][:2])。
def get_lrg(b):if not b: raise Exception()b = sorted(b, key=lambda x: np.product(x[0][-2:]-x[0][:2]), reverse=True)return b[0]
字典推导式 [1:27:04]
trn_lrg_anno = {a: get_lrg(b) for a,b in trn_anno.items()}
现在我们有一个从图像 ID 到单个边界框的字典 —— 该图像的最大边界框。
b,c = trn_lrg_anno[23]
b = bb_hw(b)
ax = show_img(open_image(IMG_PATH/trn_fns[23]), figsize=(5,10))
draw_rect(ax, b)
draw_text(ax, b[:2], cats[c], sz=16)

当你有任何类型的处理管道时,你需要查看每个阶段 [1:28:01]。假设你做的每件事第一次都会出错。
(PATH/'tmp').mkdir(exist_ok=True)
CSV = PATH/'tmp/lrg.csv'
通常,最简单的方法是简单地创建要建模的数据的 CSV,而不是尝试创建自定义数据集 [1:29:06]。在这里,我们使用 Pandas 帮助我们创建一个图像文件名和类别的 CSV。columns=[‘fn’,’cat’] 是因为字典没有顺序,列的顺序很重要。
df = pd.DataFrame({'fn': [trn_fns[o] for o in trn_ids],'cat': [cats[trn_lrg_anno[o][1]] for o in trn_ids]
}, columns=['fn','cat'])
df.to_csv(CSV, index=False)
f_model = resnet34
sz=224
bs=64
从这里开始就像狗与猫!
tfms = tfms_from_model(f_model, sz, aug_tfms=transforms_side_on, crop_type=CropType.NO
)
md = ImageClassifierData.from_csv(PATH, JPEGS, CSV, tfms=tfms)
让我们来看看这个 [1:30:48]
一个不同的地方是 crop_type。在 fast.ai 中创建 224x224 图像的默认策略是首先调整大小,使最小边为 224。然后在训练期间随机取一个正方形裁剪。在验证期间,我们取中心裁剪,除非我们使用数据增强。
对于边界框,我们不想这样做,因为与图像网不同,我们关心的东西基本上在中间且相当大,而在目标检测中,很多东西相当小且靠近边缘。通过将 crop_type 设置为 CropType.NO,它将不会裁剪,因此,为了使其成为正方形,它会压缩它 [1:32:09]。一般来说,许多计算机视觉模型在裁剪而不是压缩时效果稍好一些,但如果你压缩,它们仍然效果很好。在这种情况下,我们绝对不想裁剪,所以这是完全可以的。
x,y=next(iter(md.val_dl))
show_img(md.val_ds.denorm(to_np(x))[0]);

数据加载器 [1:33:04]
您已经知道,在模型数据对象内部,我们有一堆东西,包括训练数据加载器和训练数据集。关于数据加载器的主要知识点是,它是一个迭代器,每次从中获取下一个迭代的内容时,您会得到一个小批量。您获得的小批量是您请求的任何大小,默认情况下批量大小为 64。在 Python 中,从迭代器中获取下一个内容的方法是使用next(md.trn_dl),但您不能直接这样做。您不能这样说的原因是您需要说“现在开始一个新的时期”。通常情况下,不仅仅是在 PyTorch 中,对于任何 Python 迭代器,您需要说“请从序列的开头开始”。您这样做的方式是使用iter(md.trn_dl),它将从md.trn_dl中获取一个迭代器 —— 具体来说,正如我们稍后将学到的那样,这意味着这个类必须定义一个__iter__方法,该方法返回一些不同的对象,然后该对象具有一个__next__方法。
如果您只想获取一个批次,这是您的操作方法(x:自变量,y:因变量):
x,y=next(iter(md.val_dl))
我们不能直接将其发送到show_image[1:35:30]。例如,x不是一个 numpy 数组,不在 CPU 上,并且形状完全错误(3x224x224)。此外,它们不是介于 0 和 1 之间的数字,因为所有标准 ImageNet 预训练模型都期望我们的数据已经被标准化为具有零均值和 1 标准差。
正如您所看到的,对输入进行了大量处理,以便准备传递给预训练模型。因此我们有一个名为denorm的函数用于反标准化,还可以修复维度顺序等。由于反标准化取决于转换[1:37:52],并且数据集知道用于创建它的转换,这就是为什么您需要执行md.val_ds.denorm并将小批量转换为 numpy 数组后传递:
show_img(md.val_ds.denorm(to_np(x))[0]);
使用 ResNet34 进行训练[1:38:36]
learn = ConvLearner.pretrained(f_model, md, metrics=[accuracy])
learn.opt_fn = optim.Adamlrf=learn.lr_find(1e-5,100)
learn.sched.plot()

我们故意删除了前几个点和最后几个点[1:38:54],因为通常最后几个点会向无穷大飙升,以至于您无法看到任何东西,所以这通常是个好主意。但是当您只有很少的小批量时,这并不是一个好主意。当您的 LR 查找器图像看起来像上面时,您可以要求在每一端获取更多点(您还可以将批量大小设置得非常小):
learn.sched.plot(n_skip=5, n_skip_end=1)

lr = 2e-2
learn.fit(lr, 1, cycle_len=1)
'''
epoch trn_loss val_loss accuracy 0 1.280753 0.604127 0.806941
'''
解冻几层:
lrs = np.array([lr/1000,lr/100,lr])
learn.freeze_to(-2)
learn.fit(lrs/5, 1, cycle_len=1)
'''
epoch trn_loss val_loss accuracy 0 0.780925 0.575539 0.821064
'''
解冻整个模型:
learn.unfreeze()
learn.fit(lrs/5, 1, cycle_len=2)
'''
epoch trn_loss val_loss accuracy 0 0.676254 0.546998 0.834285 1 0.460609 0.533741 0.833233
'''
准确率没有太大改善 —— 由于许多图像具有多个不同的对象,要达到那么高的准确率几乎是不可能的。
让我们看看结果[1:40:48]
fig, axes = plt.subplots(3, 4, figsize=(12, 8))
for i,ax in enumerate(axes.flat):ima=md.val_ds.denorm(x)[i]b = md.classes[preds[i]]ax = show_img(ima, ax=ax)draw_text(ax, (0,0), b)
plt.tight_layout()

如何理解陌生的代码:
- 逐行运行代码,打印输入和输出。
方法 1[1:42:28]:您可以获取循环的内容,复制它,创建一个在其上方的单元格,粘贴它,取消缩进,设置i=0并将它们放在单独的单元格中。

方法 2[1:43:04]:使用 Python 调试器
您可以使用 Python 调试器pdb逐步执行代码。
-
pdb.set_trace()设置断点 -
%debug魔术以跟踪错误(在异常发生后)
您需要了解的命令:
-
h(帮助) -
s(步入) -
n(下一行/跳过 —— 您也可以按回车键) -
c(继续到下一个断点) -
u(向上调用堆栈) -
d(向下调用堆栈) -
p(打印) —— 当有一个单字母变量也是一个命令时,强制打印。 -
l(列出) —— 显示上面和下面的行 -
q(退出) —— 非常重要
注释 [1:49:10]:[IPython.core.debugger](http://ipython.readthedocs.io/en/stable/api/generated/IPython.core.debugger.html)(右侧)使其看起来很漂亮:


创建边界框[1:52:51]
围绕最大对象创建边界框可能看起来像是您以前没有做过的事情,但实际上它完全是您以前做过的事情。我们可以创建一个回归而不是分类神经网络。分类神经网络是具有 sigmoid 或 softmax 输出的神经网络,我们使用交叉熵、二元交叉熵或负对数似然损失函数。这基本上是使其成为分类器的原因。如果我们在最后没有 softmax 或 sigmoid,并且我们使用均方误差作为损失函数,那么现在它是一个预测连续数字而不是类别的回归模型。我们还知道我们可以有多个输出,就像在 planet 竞赛中一样(多分类)。如果我们将这两个想法结合起来并进行多列回归呢?
这是您考虑它像可微编程的地方。不是“我如何创建一个边界框模型?”而是更像:
-
我们需要四个数字,因此需要一个具有 4 个激活的神经网络
-
对于损失函数,什么样的函数在较低时意味着这四个数字更好?均方损失函数!
就是这样。让我们试试看。
Bbox only [1:55:27]
现在我们将尝试找到最大对象的边界框。这只是一个具有 4 个输出的回归。因此,我们可以使用具有多个“标签”的 CSV。如果您还记得第 1 部分如何进行多标签分类,您的多个标签必须以空格分隔,并且文件名以逗号分隔。
BB_CSV = PATH/'tmp/bb.csv'
bb = np.array([trn_lrg_anno[o][0] for o in trn_ids])
bbs = [' '.join(str(p) for p in o) for o in bb]
df = pd.DataFrame({'fn': [trn_fns[o] for o in trn_ids], 'bbox': bbs
}, columns=['fn','bbox'])
df.to_csv(BB_CSV, index=False)
BB_CSV.open().readlines()[:5]
'''
['fn,bbox\n','000012.jpg,96 155 269 350\n','000017.jpg,77 89 335 402\n','000023.jpg,1 2 461 242\n','000026.jpg,124 89 211 336\n']
'''
Training [1:56:11]
f_model=resnet34
sz=224
bs=64
将continuous=True设置为告诉 fastai 这是一个回归问题,这意味着它不会对标签进行独热编码,并且将使用 MSE 作为默认的 crit。
请注意,我们必须告诉 transforms 构造函数我们的标签是坐标,以便它可以正确处理 transforms。
此外,我们使用 CropType.NO,因为我们希望将矩形图像“压缩”成正方形,而不是中心裁剪,以免意外裁剪掉一些对象。(在像 imagenet 这样的情况下,这不是太大的问题,因为有一个要分类的单个对象,通常很大且位于中心位置)。
tfms = tfms_from_model(f_model, sz, crop_type=CropType.NO, tfm_y=TfmType.COORD
)
md = ImageClassifierData.from_csv(PATH, JPEGS, BB_CSV, tfms=tfms, continuous=True
)
下周我们将看一下TfmType.COORD,但现在,只需意识到当我们进行缩放和数据增强时,需要对边界框进行操作,而不仅仅是图像。
x,y=next(iter(md.val_dl))ima=md.val_ds.denorm(to_np(x))[0]
b = bb_hw(to_np(y[0])); b
'''
array([ 49., 0., 131., 205.], dtype=float32)
'''
ax = show_img(ima)
draw_rect(ax, b)
draw_text(ax, b[:2], 'label')

让我们基于 ResNet34 创建一个卷积网络[1:56:57]:
fastai 允许您使用custom_head在卷积网络的顶部添加自己的模块,而不是默认添加的自适应池化和全连接网络。在这种情况下,我们不想进行任何池化,因为我们需要知道每个网格单元的激活。
最终层有 4 个激活,每个激活对应一个边界框坐标。我们的目标是连续的,而不是分类的,因此使用的 MSE 损失函数不会对模块输出进行任何 sigmoid 或 softmax 处理。
head_reg4 = nn.Sequential(Flatten(), nn.Linear(25088,4))
learn = ConvLearner.pretrained(f_model, md, custom_head=head_reg4)
learn.opt_fn = optim.Adam
learn.crit = nn.L1Loss()
-
Flatten():通常在 ResNet34 中,前一层具有7x7x512,因此将其展平为长度为 2508 的单个向量。 -
L1Loss[1:58:22]:不是将平方误差相加,而是将误差的绝对值相加。这通常是您想要的,因为将平方误差相加会过度惩罚错误。因此,L1Loss 通常更好地处理。
learn.lr_find(1e-5,100)
learn.sched.plot(5)78%|███████▊ | 25/32 [00:04<00:01, 6.16it/s, loss=395]

lr = 2e-3
learn.fit(lr, 2, cycle_len=1, cycle_mult=2)
'''
epoch trn_loss val_loss 0 49.523444 34.764141 1 36.864003 28.007317 2 30.925234 27.230705
'''
lrs = np.array([lr/100,lr/10,lr])
learn.freeze_to(-2)
lrf=learn.lr_find(lrs/1000)
learn.sched.plot(1)

learn.fit(lrs, 2, cycle_len=1, cycle_mult=2)
'''
epoch trn_loss val_loss 0 25.616161 22.83597 1 21.812624 21.387115 2 17.867176 20.335539
'''
learn.freeze_to(-3)
learn.fit(lrs, 1, cycle_len=2)
'''
epoch trn_loss val_loss 0 16.571885 20.948696 1 15.072718 19.925312
'''
验证损失是绝对值的平均值,像素偏离了。
learn.save('reg4')
看一下结果[1:59:18]
x,y = next(iter(md.val_dl))
learn.model.eval()
preds = to_np(learn.model(VV(x)))
fig, axes = plt.subplots(3, 4, figsize=(12, 8))
for i,ax in enumerate(axes.flat):ima=md.val_ds.denorm(to_np(x))[i]b = bb_hw(preds[i])ax = show_img(ima, ax=ax)draw_rect(ax, b)
plt.tight_layout()

我们将在下周进一步修改这个。在这堂课之前,如果有人问你“你知道如何创建一个边界框模型吗?”,你可能会说“不,没有人教过我”。但实际上问题是:
-
您可以创建一个具有 4 个连续输出的模型吗?可以。
-
您能否创建一个损失函数,如果这 4 个输出接近另外 4 个数字,则较低?可以
然后你就完成了。
当你继续往下看时,它开始看起来有点糟糕 - 每当我们有多个对象时。这并不奇怪。总的来说,它做得相当不错。
深度学习 2:第 2 部分第 9 课
原文:
medium.com/@hiromi_suenaga/deep-learning-2-part-2-lesson-9-5f0cf9e4bb5b译者:飞龙
协议:CC BY-NC-SA 4.0
来自 fast.ai 课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢 Jeremy 和Rachel 给了我这个学习的机会。
链接
论坛 / 视频
回顾
上周的内容:
-
Pathlib;JSON
-
字典推导
-
Defaultdict
-
如何在 fastai 源代码中跳转
-
matplotlib OO API
-
Lambda 函数
-
边界框坐标
-
自定义头部;边界框回归


来自第 1 部分:
-
如何查看 DataLoader 中的模型输入
-
如何查看模型输出

数据增强和边界框[2:58]
笔记本
fastai 的尴尬问题:
分类器是任何具有分类或二元因变量的东西。与回归相对,回归是任何具有连续因变量的东西。命名有点混乱,但将在未来得到解决。在这里,continuous是True,因为我们的因变量是边界框的坐标 — 因此这实际上是一个回归器数据。
tfms = tfms_from_model(f_model, sz, crop_type=CropType.NO, aug_tfms=augs)
md = ImageClassifierData.from_csv(PATH, JPEGS, BB_CSV, tfms=tfms,**continuous=True**, bs=4)
让我们创建一些数据增强[4:40]
augs = [RandomFlip(), RandomRotate(30),RandomLighting(0.1,0.1)]
通常,我们使用 Jeremy 为我们创建的这些快捷方式,但它们只是随机增强的列表。但您可以轻松创建自己的(大多数,如果不是全部,都以“Random”开头)。
tfms = tfms_from_model(f_model, sz, crop_type=CropType.NO,aug_tfms=augs
)
md = ImageClassifierData.from_csv(PATH, JPEGS, BB_CSV, tfms=tfms,continuous=True, bs=4
)
idx=3
fig,axes = plt.subplots(3,3, figsize=(9,9))
for i,ax in enumerate(axes.flat):x,y=next(iter(md.aug_dl))ima=md.val_ds.denorm(to_np(x))[idx]b = bb_hw(to_np(y[idx]))print(b)show_img(ima, ax=ax)draw_rect(ax, b)
'''
[115\. 63\. 240\. 311.]
[ 115\. 63\. 240\. 311.]
[ 115\. 63\. 240\. 311.]
[ 115\. 63\. 240\. 311.]
[ 115\. 63\. 240\. 311.]
[ 115\. 63\. 240\. 311.]
[ 115\. 63\. 240\. 311.]
[ 115\. 63\. 240\. 311.]
[ 115\. 63\. 240\. 311.]*

如您所见,图像会旋转并且光照会变化,但边界框不会移动,而且位置不正确[6:17]。这是数据增强的问题,当您的因变量是像素值或以某种方式与自变量相关联时,它们需要一起增强。如您在边界框坐标[ 115. 63. 240. 311.]中所看到的,我们的图像是 224 乘以 224 — 因此它既没有缩放也没有裁剪。因变量需要经历所有几何变换,就像自变量一样。
要执行此操作[7:10],每个转换都有一个可选的tfm_y参数:
augs = [RandomFlip(tfm_y=TfmType.COORD),RandomRotate(30, tfm_y=TfmType.COORD),RandomLighting(0.1,0.1, tfm_y=TfmType.COORD)
]
tfms = tfms_from_model(f_model, sz, crop_type=CropType.NO,tfm_y=TfmType.COORD, aug_tfms=augs
)
md = ImageClassifierData.from_csv(PATH, JPEGS, BB_CSV, tfms=tfms, continuous=True, bs=4
)
TrmType.COORD表示y值表示坐标。这需要添加到所有增强以及tfms_from_model中,后者负责裁剪、缩放、调整大小、填充等。
idx=3
fig,axes = plt.subplots(3,3, figsize=(9,9))
for i,ax in enumerate(axes.flat):x,y=next(iter(md.aug_dl))ima=md.val_ds.denorm(to_np(x))[idx]b = bb_hw(to_np(y[idx]))print(b)show_img(ima, ax=ax)draw_rect(ax, b)
'''
[ 48\. 34\. 112\. 188.]
[ 65\. 36\. 107\. 185.]
[ 49\. 27\. 131\. 195.]
[ 24\. 18\. 147\. 204.]
[ 61\. 34\. 113\. 188.]
[ 55\. 31\. 121\. 191.]
[ 52\. 19\. 144\. 203.]
[ 7\. 0\. 193\. 222.]
[ 52\. 38\. 105\. 182.]*

现在,边界框随图像移动并位于正确位置。您可能会注意到有时看起来像底部行中间的那个奇怪。这是我们拥有的信息的限制。如果对象占据原始边界框的角落,那么在图像旋转后,您的新边界框需要更大。因此,您必须小心不要对边界框进行过高的旋转,因为没有足够的信息使它们保持准确。如果我们正在进行多边形或分割,我们将不会遇到这个问题。

这就是为什么框变大了
tfm_y = TfmType.COORD
augs = [RandomFlip(tfm_y=tfm_y),RandomRotate(3, **p=0.5**, tfm_y=tfm_y),RandomLighting(0.05,0.05, tfm_y=tfm_y)
]
tfms = tfms_from_model(f_model, sz, crop_type=CropType.NO, tfm_y=tfm_y, aug_tfms=augs
)
md = ImageClassifierData.from_csv(PATH, JPEGS, BB_CSV, tfms=tfms, continuous=True
)
因此,在这里,我们最多进行 3 度旋转,以避免这个问题[9:14]。它也只有一半的时间旋转(p=0.5)。
custom_head[9:34]
learn.summary()将通过模型运行一小批数据,并打印出每一层张量的大小。正如您所看到的,在Flatten层之前,张量的形状为 512 乘以 7 乘以 7。因此,如果它是一个秩为 1 的张量(即一个单一向量),其长度将为 25088(512 * 7 * 7),这就是为什么我们自定义标题的输入大小为 25088。输出大小为 4,因为它是边界框坐标。
head_reg4 = nn.Sequential(Flatten(), nn.Linear(25088,4))
learn = ConvLearner.pretrained(f_model, md, custom_head=head_reg4)
learn.opt_fn = optim.Adam
learn.crit = nn.L1Loss()

单个对象检测[10:35]
让我们将这两者结合起来,创建一个可以对每个图像中最大的对象进行分类和定位的东西。
训练神经网络有 3 件事情我们需要做:
-
数据
-
架构
-
损失函数
1. 提供数据
我们需要一个ModelData对象,其独立变量是图像,依赖变量是一个包含边界框坐标和类别标签的元组。有几种方法可以做到这一点,但这里是 Jeremy 想出的一个特别懒惰和方便的方法,即创建两个代表我们想要的两个不同依赖变量的ModelData对象(一个带有边界框坐标,一个带有类别)。
f_model=resnet34
sz=224
bs=64
val_idxs = get_cv_idxs(len(trn_fns))
tfms = tfms_from_model(f_model, sz, crop_type=CropType.NO, tfm_y=TfmType.COORD, aug_tfms=augs
)
md = ImageClassifierData.from_csv(PATH, JPEGS, BB_CSV, tfms=tfms, continuous=True, val_idxs=val_idxs
)
md2 = ImageClassifierData.from_csv(PATH, JPEGS, CSV,tfms=tfms_from_model(f_model, sz)
)
数据集可以是任何具有__len__和__getitem__的东西。这里有一个数据集,它向现有数据集添加了第二个标签:
class ConcatLblDataset(Dataset):def __init__(self, ds, y2): self.ds,self.y2 = ds,y2def __len__(self): return len(self.ds)def __getitem__(self, i):x,y = self.ds[i]return (x, (y,self.y2[i]))
-
ds:包含独立和依赖变量 -
y2:包含额外的依赖变量 -
(x, (y,self.y2[i])):__getitem___返回一个独立变量和两个依赖变量的组合。
我们将用它来将类别添加到边界框标签中。
trn_ds2 = ConcatLblDataset(md.trn_ds, md2.trn_y)
val_ds2 = ConcatLblDataset(md.val_ds, md2.val_y)
这是一个例子的依赖变量:
val_ds2[0][1]*(array([ 0., 49., 205., 180.], dtype=float32), 14)*
我们可以用这些新的数据集替换数据加载器的数据集。
md.trn_dl.dataset = trn_ds2
md.val_dl.dataset = val_ds2
我们必须在绘图之前从数据加载器中对图像进行denormalize。
x,y = next(iter(md.val_dl))
idx = 3
ima = md.val_ds.ds.denorm(to_np(x))[idx]
b = bb_hw(to_np(y[0][idx])); b
'''
array([ 52., 38., 106., 184.], dtype=float32)
'''
ax = show_img(ima)
draw_rect(ax, b)
draw_text(ax, b[:2], md2.classes[y[1][idx]])

2. 选择架构[13:54]
架构将与我们用于分类器和边界框回归的相同,但我们将它们结合起来。换句话说,如果我们有c个类别,那么最终层中所需的激活数量是 4 加上c。4 用于边界框坐标和c个概率(每个类别一个)。
这次我们将使用额外的线性层,再加上一些 dropout,来帮助我们训练一个更灵活的模型。一般来说,如果预训练的主干适合,我们希望我们的自定义头部能够独立解决问题。因此,在这种情况下,我们尝试做了很多事情——分类器和边界框回归,所以单个线性层似乎不够。如果你想知道为什么第一个ReLU后面没有BatchNorm1d,那是因为 ResNet 主干已经有BatchNorm1d作为最后一层。
head_reg4 = nn.Sequential(Flatten(),nn.ReLU(),nn.Dropout(0.5),nn.Linear(25088,256),nn.ReLU(),nn.BatchNorm1d(256),nn.Dropout(0.5),nn.Linear(256, 4+len(cats)),
)
models = ConvnetBuilder(f_model, 0, 0, 0, custom_head=head_reg4)learn = ConvLearner(md, models)
learn.opt_fn = optim.Adam
3. 损失函数[15:46]
损失函数需要查看这些4 + len(cats)激活,并决定它们是否良好——这些数字是否准确反映了图像中最大对象的位置和类别。我们知道如何做到这一点。对于前 4 个激活,我们将像以前一样使用 L1Loss(L1Loss 类似于均方误差——它使用绝对值的和,而不是平方误差的和)。对于其余的激活,我们可以使用交叉熵损失。
def detn_loss(input, target):bb_t,c_t = targetbb_i,c_i = input[:, :4], input[:, 4:]bb_i = F.sigmoid(bb_i)*224# I looked at these quantities separately first then picked a # multiplier to make them approximately equalreturn F.l1_loss(bb_i, bb_t) + F.cross_entropy(c_i, c_t)*20
def detn_l1(input, target):bb_t,_ = targetbb_i = input[:, :4]bb_i = F.sigmoid(bb_i)*224return F.l1_loss(V(bb_i),V(bb_t)).data
def detn_acc(input, target):_,c_t = targetc_i = input[:, 4:]return accuracy(c_i, c_t)
learn.crit = detn_loss
learn.metrics = [detn_acc, detn_l1]
-
input:激活 -
target:真实值 -
bb_t,c_t = target:我们的自定义数据集返回一个包含边界框坐标和类别的元组。这个赋值将对它们进行解构。 -
bb_i,c_i = input[:, :4], input[:, 4:]:第一个:是用于批处理维度。 -
b_i = F.sigmoid(bb_i)*224:我们知道我们的图像是 224x224。Sigmoid将强制它在 0 和 1 之间,并将其乘以 224,以帮助我们的神经网络处于必须的范围内。
**问题:**一般规则是,在 ReLU 之前还是之后放置 BatchNorm 更好[18:02]?Jeremy 建议在 ReLU 之后放置 BatchNorm,因为 BatchNorm 旨在朝着零均值一标准差移动。因此,如果你在它之后放置 ReLU,你就在零处截断它,所以没有办法创建负数。但如果你先放 ReLU 再放 BatchNorm,它确实有这个能力,并且会给出稍微更好的结果。话虽如此,无论哪种方式都不是太大的问题。你会在这门课程的这部分看到,大多数时候 Jeremy 会先 ReLU 再 BatchNorm,但有时会相反,当他想要与论文保持一致时。
问题:在 BatchNorm 之后使用 dropout 的直觉是什么?BatchNorm 不是已经很好地进行了正则化吗[19:12]?BatchNorm 做正则化的效果还可以,但是如果回想第 1 部分,我们讨论过避免过拟合的一系列方法,添加 BatchNorm 是其中之一,数据增强也是其中之一。但是仍然有可能过拟合。关于 dropout 的一个好处是它有一个参数来指定要丢弃多少。参数非常好,特别是决定要进行多少正则化,因为它让你可以构建一个很大的超参数化模型,然后决定要进行多少正则化。Jeremy 倾向于总是从p=0开始添加 dropout,然后随着添加正则化,他可以只需更改 dropout 参数,而不必担心是否保存了一个模型,他希望能够重新加载它,但如果一个中有 dropout 层而另一个中没有,它将无法加载。这样,保持一致性。
现在我们有了输入和目标,我们可以计算 L1 损失并添加交叉熵[20:39]:
F.l1_loss(bb_i, bb_t) + F.cross_entropy(c_i, c_t)*20
这是我们的损失函数。交叉熵和 L1 损失可能处于非常不同的尺度——在这种情况下,较大的那个将占主导地位。在这种情况下,Jeremy 打印出值并发现如果我们将交叉熵乘以 20,它们就会大致处于相同的尺度。
lr=1e-2
learn.fit(lr, 1, cycle_len=3, use_clr=(32,5))
'''
epoch trn_loss val_loss detn_acc detn_l1 0 72.036466 45.186367 0.802133 32.647586 1 51.037587 36.34964 0.828425 25.389733 2 41.4235 35.292709 0.835637 24.343577
[35.292709, 0.83563701808452606, 24.343576669692993]
'''
在训练时打印信息是很好的,所以我们抓取了 L1 损失并将其添加为指标。
learn.save('reg1_0')
learn.freeze_to(-2)
lrs = np.array([lr/100, lr/10, lr])
learn.fit(lrs/5, 1, cycle_len=5, use_clr=(32,10))
'''
epoch trn_loss val_loss detn_acc detn_l1 0 34.448113 35.972973 0.801683 22.918499 1 28.889909 33.010857 0.830379 21.689888 2 24.237017 30.977512 0.81881 20.817996 3 21.132993 30.60677 0.83143 20.138552 4 18.622983 30.54178 0.825571 19.832196
[30.54178, 0.82557091116905212, 19.832195997238159]
'''
learn.unfreeze()
learn.fit(lrs/10, 1, cycle_len=10, use_clr=(32,10))
'''
epoch trn_loss val_loss detn_acc detn_l1 0 15.957164 31.111507 0.811448 19.970753 1 15.955259 32.597153 0.81235 20.111022 2 15.648723 32.231941 0.804087 19.522853 3 14.876172 30.93821 0.815805 19.226574 4 14.113872 31.03952 0.808594 19.155093 5 13.293885 29.736671 0.826022 18.761728 6 12.562566 30.000023 0.827524 18.82006 7 11.885125 30.28841 0.82512 18.904158 8 11.498326 30.070133 0.819712 18.635296 9 11.015841 30.213772 0.815805 18.551489
[30.213772, 0.81580528616905212, 18.551488876342773]
'''
检测准确率在 80%左右,与之前相同。这并不令人惊讶,因为 ResNet 是设计用于分类的,所以我们不会指望能够以这种简单的方式改进事情。它确实不是设计用于边界框回归的。实际上,它是明确设计成不关心几何形状的——它取最后的 7x7 激活网格并将它们全部平均在一起,丢弃了所有关于每个位置的信息。
有趣的是,当我们同时进行准确性(分类)和边界框时,L1 似乎比我们只进行边界框回归时要好一点[22:46]。如果这对你来说是违反直觉的,那么这将是本课后需要考虑的主要问题之一,因为这是一个非常重要的想法。这个想法是——找出图像中的主要对象是比较困难的部分。然后确定边界框的确切位置和类别是一种简单的方式。因此,当你有一个同时指出对象是什么和对象在哪里的单个网络时,它将共享所有关于找到对象的计算。所有这些共享的计算非常高效。当我们反向传播类别和位置的错误时,所有这些信息都将帮助计算找到最大对象的周围。因此,每当你有多个任务共享某些概念,这些任务需要完成它们的工作,它们很可能应该至少共享网络的一些层。今天晚些时候,我们将看一个模型,其中大部分层都是共享的,除了最后一层。
以下是结果[24:34]。与以前一样,在图像中有单个主要对象时表现良好。

多标签分类[25:29]
笔记本
我们希望继续构建比上一个模型稍微复杂的模型,这样如果某些东西停止工作,我们就知道出了什么问题。以下是上一个笔记本中的函数:
%matplotlib inline
%reload_ext autoreload
%autoreload 2
from fastai.conv_learner import *
from fastai.dataset import *import json, pdb
from PIL import ImageDraw, ImageFont
from matplotlib import patches, patheffects
torch.backends.cudnn.benchmark=True
设置
PATH = Path('data/pascal')
trn_j = json.load((PATH / 'pascal_train2007.json').open())
IMAGES,ANNOTATIONS,CATEGORIES = ['images', 'annotations', 'categories'
]
FILE_NAME,ID,IMG_ID,CAT_ID,BBOX = \'file_name','id','image_id', 'category_id','bbox'cats = dict((o[ID], o['name']) for o in trn_j[CATEGORIES])
trn_fns = dict((o[ID], o[FILE_NAME]) for o in trn_j[IMAGES])
trn_ids = [o[ID] for o in trn_j[IMAGES]]JPEGS = 'VOCdevkit/VOC2007/JPEGImages'
IMG_PATH = PATH/JPEGSdef get_trn_anno():trn_anno = collections.defaultdict(lambda:[])for o in trn_j[ANNOTATIONS]:if not o['ignore']:bb = o[BBOX]bb = np.array([bb[1], bb[0], bb[3]+bb[1]-1, bb[2]+bb[0]-1])trn_anno[o[IMG_ID]].append((bb,o[CAT_ID]))return trn_annotrn_anno = get_trn_anno()
def show_img(im, figsize=None, ax=None):if not ax: fig,ax = plt.subplots(figsize=figsize)ax.imshow(im)ax.set_xticks(np.linspace(0, 224, 8))ax.set_yticks(np.linspace(0, 224, 8))ax.grid()ax.set_yticklabels([])ax.set_xticklabels([])return axdef draw_outline(o, lw):o.set_path_effects([patheffects.Stroke(linewidth=lw, foreground='black'), patheffects.Normal()])def draw_rect(ax, b, color='white'):patch = ax.add_patch(patches.Rectangle(b[:2], *b[-2:], fill=False, edgecolor=color, lw=2))draw_outline(patch, 4)def draw_text(ax, xy, txt, sz=14, color='white'):text = ax.text(*xy, txt,verticalalignment='top', color=color, fontsize=sz, weight='bold')draw_outline(text, 1)
def bb_hw(a): return np.array([a[1],a[0],a[3]-a[1],a[2]-a[0]])def draw_im(im, ann):ax = show_img(im, figsize=(16,8))for b,c in ann:b = bb_hw(b)draw_rect(ax, b)draw_text(ax, b[:2], cats[c], sz=16)def draw_idx(i):im_a = trn_anno[i]im = open_image(IMG_PATH/trn_fns[i])draw_im(im, im_a)
多类别[26:12]
MC_CSV = PATH/'tmp/mc.csv'
trn_anno[12]
'''
[(array([ 96, 155, 269, 350]), 7)]
'''
mc = [set([cats[p[1]] for p in trn_anno[o]]) for o in trn_ids]
mcs = [' '.join(str(p) for p in o) for o in mc]
df = pd.DataFrame({'fn': [trn_fns[o] for o in trn_ids], 'clas': mcs
}, columns=['fn','clas'])
df.to_csv(MC_CSV, index=False)
有一个学生指出,通过使用 Pandas,我们可以比使用collections.defaultdict更简单地完成一些事情,并分享了这个gist。您越了解 Pandas,就越会意识到它是解决许多不同问题的好方法。
问题:当您在较小的模型基础上逐步构建时,您是否重复使用它们作为预训练权重?还是将其丢弃然后从头开始重新训练?当 Jeremy 像这样逐步弄清楚事情时,他通常倾向于丢弃,因为重用预训练权重会引入不必要的复杂性。但是,如果他试图达到一个可以在非常大的图像上训练的点,他通常会从更小的模型开始,并经常重用这些权重。
f_model=resnet34
sz=224
bs=64
tfms = tfms_from_model(f_model, sz, crop_type=CropType.NO)
md = ImageClassifierData.from_csv(PATH, JPEGS, MC_CSV, tfms=tfms)
learn = ConvLearner.pretrained(f_model, md)
learn.opt_fn = optim.Adamlr = 2e-2
learn.fit(lr, 1, cycle_len=3, use_clr=(32,5))
'''
epoch trn_loss val_loss <lambda> 0 0.104836 0.085015 0.972356 1 0.088193 0.079739 0.972461 2 0.072346 0.077259 0.974114
[0.077258907, 0.9741135761141777]
'''
lrs = np.array([lr/100, lr/10, lr])
learn.freeze_to(-2)learn.fit(lrs/10, 1, cycle_len=5, use_clr=(32,5))
'''
epoch trn_loss val_loss <lambda> 0 0.063236 0.088847 0.970681 1 0.049675 0.079885 0.973723 2 0.03693 0.076906 0.975601 3 0.026645 0.075304 0.976187 4 0.018805 0.074934 0.975165
[0.074934497, 0.97516526281833649]
'''
learn.save('mclas')
learn.load('mclas')
y = learn.predict()
x,_ = next(iter(md.val_dl))
x = to_np(x)
fig, axes = plt.subplots(3, 4, figsize=(12, 8))
for i,ax in enumerate(axes.flat):ima=md.val_ds.denorm(x)[i]ya = np.nonzero(y[i]>0.4)[0]b = '\n'.join(md.classes[o] for o in ya)ax = show_img(ima, ax=ax)draw_text(ax, (0,0), b)
plt.tight_layout()

多类别分类非常直接。在这一行中使用set的一个小调整,以便每种对象类型只出现一次。
mc = [set([cats[p[1]] for p in trn_anno[o]]) for o in trn_ids]
SSD 和 YOLO
我们有一个输入图像通过卷积网络,输出大小为4+c的向量,其中c=len(cats)。这为我们提供了一个用于单个最大对象的对象检测器。现在让我们创建一个可以找到 16 个对象的检测器。显而易见的方法是取最后一个线性层,而不是有4+c个输出,我们可以有16x(4+c)个输出。这为我们提供了 16 组类别概率和 16 组边界框坐标。然后我们只需要一个损失函数,检查这 16 组边界框是否正确表示了图像中的最多 16 个对象(我们将在后面讨论损失函数)。

第二种方法是,与其使用nn.linear,不如从我们的 ResNet 卷积主干中取出并添加一个带有步幅 2 的nn.Conv2d?这将给我们一个4x4x[# of filters]张量 - 这里让我们将其设为4x4x(4+c),以便得到一个元素数量与我们想要的元素数量完全相等的张量。现在,如果我们创建一个损失函数,接受一个4x4x(4+c)张量,并将其映射到图像中的 16 个对象,并检查每个对象是否由这些4+c激活正确表示,这也可以起作用。事实证明,这两种方法实际上都被使用。从一个完全连接的线性层输出一个很长的向量的方法被一类模型使用,这类模型被称为YOLO(You Only Look Once),而卷积激活的方法被一些从SSD(Single Shot Detector)开始的模型使用。由于这些东西在 2015 年末几乎同时出现,事情在很大程度上朝着 SSD 发展。所以今天早上,YOLO 版本 3发布了,现在正在使用 SSD,这就是我们要做的。我们还将了解为什么这样做更有意义。
锚框

假设我们有另一个Conv2d(stride=2),那么我们将有一个2x2x(4+c)张量。基本上,它创建了一个看起来像这样的网格:

这是第二个额外的卷积步幅 2 层激活的几何形状。请记住,步幅 2 卷积对激活的几何形状做的事情与步幅 1 卷积后跟着最大池化假设填充正常的激活几何形状是一样的。
让我们谈谈我们可能在这里做什么。我们希望每个网格单元负责查找图像该部分中最大的对象。
感受野
为什么我们关心每个卷积网格单元负责找到图像相应部分中的事物的想法?原因是因为有一个叫做卷积网格单元的感受野。基本思想是,在您的卷积层中,这些张量的每一部分都有一个感受野,这意味着负责计算该单元的输入图像的哪个部分。就像生活中的所有事物一样,最容易通过 Excel 来看到这一点[38:01]。

取一个激活(在这种情况下是在最大池层)并看看它来自哪里[38:45]。在 Excel 中,您可以执行公式 → 跟踪前导。一直追溯到输入层,您可以看到它来自图像的这个 6 x 6 部分(以及滤波器)。更重要的是,中间部分有很多权重从外部的细胞中出来,而外部的细胞只有一个权重出来。所以我们称这 6 x 6 个单元格为我们选择的一个激活的感受野。

3x3 卷积,不透明度为 15% —— 明显地,盒子的中心有更多的依赖关系
请注意,感受野不仅仅是说这是一个盒子,而且盒子的中心有更多的依赖关系[40:27],当涉及到理解架构以及理解为什么卷积网络工作方式时,这是一个至关重要的概念。
架构 [41:18]
架构是,我们将有一个 ResNet 主干,后面跟着一个或多个 2D 卷积(现在只有一个),这将给我们一个4x4的网格。
class StdConv(nn.Module):def __init__(self, nin, nout, stride=2, drop=0.1):super().__init__()self.conv = nn.Conv2d(nin, nout, 3, stride=stride, padding=1)self.bn = nn.BatchNorm2d(nout)self.drop = nn.Dropout(drop)def forward(self, x): return self.drop(self.bn(F.relu(self.conv(x))))def flatten_conv(x,k):bs,nf,gx,gy = x.size()x = x.permute(0,2,3,1).contiguous()return x.view(bs,-1,nf//k)
class OutConv(nn.Module):def __init__(self, k, nin, bias):super().__init__()self.k = kself.oconv1 = nn.Conv2d(nin, (len(id2cat)+1)*k, 3, padding=1)self.oconv2 = nn.Conv2d(nin, 4*k, 3, padding=1)self.oconv1.bias.data.zero_().add_(bias)def forward(self, x):return [flatten_conv(self.oconv1(x), self.k),flatten_conv(self.oconv2(x), self.k)]
class SSD_Head(nn.Module):def __init__(self, k, bias):super().__init__()self.drop = nn.Dropout(0.25)self.sconv0 = StdConv(512,256, stride=1)self.sconv2 = StdConv(256,256)self.out = OutConv(k, 256, bias)def forward(self, x):x = self.drop(F.relu(x))x = self.sconv0(x)x = self.sconv2(x)return self.out(x)head_reg4 = SSD_Head(k, -3.)
models = ConvnetBuilder(f_model, 0, 0, 0, custom_head=head_reg4)
learn = ConvLearner(md, models)
learn.opt_fn = optim.Adam
SSD_Head
-
我们从 ReLU 和 dropout 开始
-
然后是步幅为 1 的卷积。我们从步幅为 1 的卷积开始的原因是因为这不会改变几何形状 —— 它只让我们增加一层额外的计算。它让我们不仅可以创建一个线性层,而且现在我们的自定义头部中有一个小型神经网络。
StdConv在上面定义了 —— 它执行卷积、ReLU、BatchNorm 和 dropout。您看到的大多数研究代码不会像这样定义一个类,而是一遍又一遍地写整个代码。不要这样做。重复的代码会导致错误和理解不足。 -
步幅为 2 的卷积 [44:56]
-
最后,步骤 3 的输出是
4x4,传递给OutConv。OutConv有两个单独的卷积层,每个都是步幅为 1,因此不会改变输入的几何形状。其中一个的长度是类别数(现在忽略k和+1是为了“背景” —— 即没有检测到对象),另一个的长度是 4。与其有一个输出4+c的单个卷积层,不如有两个卷积层并将它们的输出返回到列表中。这使得这些层可以稍微专门化。我们谈到了这样一个想法,当您有多个任务时,它们可以共享层,但它们不必共享所有层。在这种情况下,我们的两个任务是创建一个分类器和创建和创建边界框回归,除了最后一个层外,它们共享每一个层。 -
最后,我们展平卷积,因为 Jeremy 编写的损失函数期望展平的张量,但我们完全可以重写它以不这样做。
Fastai 编码风格 [42:58]
第一版本本周发布。它非常重视阐述性编程的概念,即编程代码应该是您可以用来解释一个想法的东西,理想情况下,可以像数学符号一样容易地向理解您编码方法的人解释。这个想法已经存在很长时间了,但最好的描述是杰里米最崇拜的计算机科学英雄肯·艾弗森在 1979 年的图灵奖演讲中描述的。他在 1964 年之前就一直在研究这个问题,但 1964 年是他发布这种编程方法的第一个例子,称为 APL,25 年后,他获得了图灵奖。然后他把接力棒传给了他的儿子埃里克·艾弗森。Fastai 风格指南是对这些想法的一种尝试。
损失函数[47:44]
损失函数需要查看这 16 组激活中的每一组,每组都有四个边界框坐标和c+1类概率,并决定这些激活是否接近或远离图像中与该网格单元最接近的对象。如果没有任何东西,那么它是否正确地预测了背景。这是非常难做到的。
匹配问题[48:43]

损失函数需要将图像中的每个对象与这些卷积网格单元中的一个进行匹配,以便说“这个网格单元负责这个特定对象”,然后它可以继续说“好的,这 4 个坐标有多接近,类概率有多接近”。
这是我们的目标[49:56]:

我们的因变量看起来像左边的那个,我们最终的卷积层将是4x4x(c+1),在这种情况下c=20。然后我们将其展平为一个向量。我们的目标是设计一个函数,该函数接受一个因变量和模型输出的一些特定激活,并在这些激活不是地面真实边界框的良好反映时返回更高的数字;或者如果是一个好的反映,则返回更低的数字。
测试[51:58]
x,y = next(iter(md.val_dl))
x,y = V(x),V(y)
learn.model.eval()
batch = learn.model(x)
b_clas,b_bb = batch
b_clas.size(),b_bb.size()
'''
(torch.Size([64, 16, 21]), torch.Size([64, 16, 4]))
'''
确保这些形状是合理的。现在让我们看看地面真实y[53:24]:
idx=7
b_clasi = b_clas[idx]
b_bboxi = b_bb[idx]
ima=md.val_ds.ds.denorm(to_np(x))[idx]
bbox,clas = get_y(y[0][idx], y[1][idx])
bbox,clas
'''
(Variable containing:0.6786 0.4866 0.9911 0.62500.7098 0.0848 0.9911 0.54910.5134 0.8304 0.6696 0.9063[torch.cuda.FloatTensor of size 3x4 (GPU 0)], Variable containing:81017[torch.cuda.LongTensor of size 3 (GPU 0)])
'''
请注意,边界框坐标已缩放到 0 和 1 之间 - 基本上我们将图像视为 1x1,因此它们是相对于图像大小的。
我们已经有了show_ground_truth函数。这个torch_gt(gt:地面真相)函数简单地将张量转换为 numpy 数组。
def torch_gt(ax, ima, bbox, clas, prs=None, thresh=0.4):return show_ground_truth(ax, ima, to_np((bbox*224).long()),to_np(clas), to_np(prs) if prs is not None else None, thresh)
fig, ax = plt.subplots(figsize=(7,7))
torch_gt(ax, ima, bbox, clas)

以上是一个地面真相。这是我们最终卷积层的4x4网格单元[54:44]:
fig, ax = plt.subplots(figsize=(7,7))
torch_gt(ax, ima, anchor_cnr, b_clasi.max(1)[1])

每个正方形框,不同的论文称其为不同的东西。您将听到的三个术语是:锚框、先验框或默认框。我们将坚持使用术语锚框。
对于这个损失函数,我们将通过一个匹配问题,看看这 16 个框中的每一个与给定正方形中的这三个地面真实对象哪一个有最高的重叠量。为了做到这一点,我们必须有一种衡量重叠量的方法,这种标准函数称为 Jaccard 指数(IoU)。

我们将逐个查看这三个对象与每个 16 个锚框的 Jaccard 重叠[57:11]。这将给我们一个3x16矩阵。
这是我们所有锚框(中心、高度、宽度)的坐标:
anchors
'''
Variable containing:0.1250 0.1250 0.2500 0.25000.1250 0.3750 0.2500 0.25000.1250 0.6250 0.2500 0.25000.1250 0.8750 0.2500 0.25000.3750 0.1250 0.2500 0.25000.3750 0.3750 0.2500 0.25000.3750 0.6250 0.2500 0.25000.3750 0.8750 0.2500 0.25000.6250 0.1250 0.2500 0.25000.6250 0.3750 0.2500 0.25000.6250 0.6250 0.2500 0.25000.6250 0.8750 0.2500 0.25000.8750 0.1250 0.2500 0.25000.8750 0.3750 0.2500 0.25000.8750 0.6250 0.2500 0.25000.8750 0.8750 0.2500 0.2500
[torch.cuda.FloatTensor of size 16x4 (GPU 0)]
'''
这是 3 个地面真实对象和 16 个锚框之间的重叠量:
overlaps = jaccard(bbox.data, anchor_cnr.data)
overlaps
'''
Columns 0 to 7
0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 Columns 8 to 15
0.0000 0.0091 0.0922 0.0000 0.0000 0.0315 0.3985 0.0000 0.0356 0.0549 0.0103 0.0000 0.2598 0.4538 0.0653 0.0000 0.0000 0.0000 0.0000 0.1897 0.0000 0.0000 0.0000 0.0000 [torch.cuda.FloatTensor of size 3x16 (GPU 0)]
'''
现在我们可以取维度 1(按行)的最大值,这将告诉我们每个地面真实对象的最大重叠量以及索引:
overlaps.max(1)
'''
(0.39850.45380.1897[torch.cuda.FloatTensor of size 3 (GPU 0)], 141311[torch.cuda.LongTensor of size 3 (GPU 0)])
'''
我们还将查看维度 0(按列)的最大值,这将告诉我们每个网格单元与所有地面真实对象之间的最大重叠量是多少:
overlaps.max(0)
'''
(0.00000.00000.00000.00000.00000.00000.00000.00000.03560.05490.09220.18970.25980.45380.39850.0000[torch.cuda.FloatTensor of size 16 (GPU 0)], 0000000011021100[torch.cuda.LongTensor of size 16 (GPU 0)])
'''
这里特别有趣的是,它告诉我们每个网格单元与之重叠最多的地面真实对象的索引是什么。零在这里有点过载 - 零可能意味着重叠量为零,也可能意味着它与对象索引零的重叠最大。这将被证明并不重要,但只是供参考。
有一个名为map_to_ground_truth的函数,我们现在不用担心。这是非常简单的代码,但稍微难以理解。基本上它的作用是以 SSD 论文中描述的方式将这两组重叠组合起来,将每个锚框分配给一个地面真实对象。它的分配方式是每个三个(按行最大)都被分配为是。对于其余的锚框,它们被分配给它们与至少 0.5 重叠的任何东西(按列)。如果两者都不适用,则被视为包含背景的单元格。
gt_overlap,gt_idx = map_to_ground_truth(overlaps)
gt_overlap,gt_idx
'''
(0.00000.00000.00000.00000.00000.00000.00000.00000.03560.05490.09221.99000.25981.99001.99000.0000[torch.cuda.FloatTensor of size 16 (GPU 0)], 0000000011021100[torch.cuda.LongTensor of size 16 (GPU 0)])
'''
现在您可以看到所有分配的列表。任何gt_overlap < 0.5的地方都被分配为背景。三行最大锚框具有较高的数字以强制分配。现在我们可以将这些值组合到类别中:
gt_clas = clas[gt_idx]; gt_clas
'''
Variable containing:888888881010817101088
[torch.cuda.LongTensor of size 16 (GPU 0)]
'''
然后添加一个阈值,最后得出正在预测的三个类:
thresh = 0.5
pos = gt_overlap > thresh
pos_idx = torch.nonzero(pos)[:,0]
neg_idx = torch.nonzero(1-pos)[:,0]
pos_idx
'''111314
[torch.cuda.LongTensor of size 3 (GPU 0)]
'''
这里是每个锚框预测的含义:
gt_clas[1-pos] = len(id2cat)
[id2cat[o] if o<len(id2cat) else 'bg' for o in gt_clas.data]
'''
['bg','bg','bg','bg','bg','bg','bg','bg','bg','bg','bg','sofa','bg','diningtable','chair','bg']
'''
那就是匹配阶段。对于 L1 损失,我们可以:
-
取匹配的激活(
pos_idx = [11, 13, 14]) -
从中减去地面真实边界框
-
取差的绝对值
-
取平均值。
对于分类,我们可以做一个交叉熵
gt_bbox = bbox[gt_idx]
loc_loss = ((a_ic[pos_idx] - gt_bbox[pos_idx]).abs()).mean()
clas_loss = F.cross_entropy(b_clasi, gt_clas)
loc_loss,clas_loss
'''
(Variable containing:1.00000e-02 6.5887[torch.cuda.FloatTensor of size 1 (GPU 0)], Variable containing:1.0331[torch.cuda.FloatTensor of size 1 (GPU 0)])
'''
最终我们将得到 16 个预测的边界框,其中大多数将是背景。如果您想知道它在背景边界框方面的预测是什么,答案是它完全忽略了它。
fig, axes = plt.subplots(3, 4, figsize=(16, 12))
for idx,ax in enumerate(axes.flat):ima=md.val_ds.ds.denorm(to_np(x))[idx]bbox,clas = get_y(y[0][idx], y[1][idx])ima=md.val_ds.ds.denorm(to_np(x))[idx]bbox,clas = get_y(bbox,clas); bbox,clasa_ic = actn_to_bb(b_bb[idx], anchors)torch_gt(ax, ima, a_ic, b_clas[idx].max(1)[1], b_clas[idx].max(1)[0].sigmoid(), 0.01)
plt.tight_layout()

微调 1.我们如何解释激活?
我们解释激活的方式在这里定义:
def actn_to_bb(actn, anchors):actn_bbs = torch.tanh(actn)actn_centers = (actn_bbs[:,:2]/2 * grid_sizes) + anchors[:,:2]actn_hw = (actn_bbs[:,2:]/2+1) * anchors[:,2:]return hw2corners(actn_centers, actn_hw)
我们抓取激活,将它们通过tanh(记住tanh与 sigmoid 形状相同,只是缩放到-1 和 1 之间)强制使其在该范围内。然后我们抓取锚框的实际位置,并根据激活值除以二(actn_bbs[:,:2]/2)将它们移动。换句话说,每个预测的边界框可以从其默认位置最多移动一个网格大小的 50%。高度和宽度也是如此 - 它可以是默认大小的两倍大或一半小。
微调 2.我们实际上使用二元交叉熵损失而不是交叉熵
class BCE_Loss(nn.Module):def __init__(self, num_classes):super().__init__()self.num_classes = num_classesdef forward(self, pred, targ):t = one_hot_embedding(targ, self.num_classes+1)t = V(t[:,:-1].contiguous())*#.cpu()*x = pred[:,:-1]w = self.get_weight(x,t)return F.binary_cross_entropy_with_logits(x, t, w, size_average=False) / self.num_classesdef get_weight(self,x,t): return None
二元交叉熵是我们通常用于多标签分类的。就像在行星卫星竞赛中,每个卫星图像可能有多个物体。如果它有多个物体,你不能使用 softmax,因为 softmax 真的鼓励只有一个物体有高的数字。在我们的情况下,每个锚框只能与一个物体相关联,所以我们避免使用 softmax 并不是因为这个原因。还有其他原因——即一个锚框可能没有任何与之相关联的物体。处理这种“背景”的想法有两种方法;一种是说背景只是一个类,所以让我们使用 softmax,将背景视为 softmax 可以预测的类之一。很多人都是这样做的。但这是一个非常困难的事情要求神经网络做[1:06:52] — 基本上是在问这个网格单元是否没有我感兴趣的 20 个物体中的任何一个,Jaccard 重叠大于 0.5。这是一个非常难以放入单个计算中的事情。另一方面,如果我们只问每个类;“这是摩托车吗?”“这是公共汽车吗?”“这是一个人吗?”等等,如果所有的答案都是否定的,那就认为是背景。这就是我们在这里做的方式。并不是我们可以有多个真实标签,而是我们可以有零个。
在forward中:
-
首先我们获取目标的 one hot 编码(在这个阶段,我们已经有了背景的概念)
-
然后我们移除背景列(最后一列),结果是一个全为零或全为一的向量。
-
使用二元交叉熵预测。
这是一个小的调整,但这是 Jeremy 希望你考虑和理解的小调整,因为它对你的训练有很大的影响,当有一些对以前论文的增量时,会是这样的[1:08:25]。重要的是要理解这是在做什么,更重要的是为什么。
现在我们有[1:09:39]:
-
一个自定义损失函数
-
计算 Jaccard 指数的方法
-
将激活转换为边界框的方法
-
将锚框映射到地面真实的方法
现在剩下的就是 SSD 损失函数。
SSD 损失函数[1:09:55]
def ssd_1_loss(b_c,b_bb,bbox,clas,print_it=False):bbox,clas = get_y(bbox,clas)a_ic = actn_to_bb(b_bb, anchors)overlaps = jaccard(bbox.data, anchor_cnr.data)gt_overlap,gt_idx = map_to_ground_truth(overlaps,print_it)gt_clas = clas[gt_idx]pos = gt_overlap > 0.4pos_idx = torch.nonzero(pos)[:,0]gt_clas[1-pos] = len(id2cat)gt_bbox = bbox[gt_idx]loc_loss = ((a_ic[pos_idx] - gt_bbox[pos_idx]).abs()).mean()clas_loss = loss_f(b_c, gt_clas)return loc_loss, clas_lossdef ssd_loss(pred,targ,print_it=False):lcs,lls = 0.,0.for b_c,b_bb,bbox,clas in zip(*pred,*targ):loc_loss,clas_loss = ssd_1_loss(b_c,b_bb,bbox,clas,print_it)lls += loc_losslcs += clas_lossif print_it: print(f'loc: {lls.data[0]}, clas: {lcs.data[0]}')return lls+lcs
ssd_loss函数是我们设置的标准,它循环遍历每个小批量中的图像,并调用ssd_1_loss函数(即一个图像的 SSD 损失)。
ssd_1_loss是所有操作发生的地方。它从bbox和clas开始解构。让我们更仔细地看一下get_y[1:10:38]:
def get_y(bbox,clas):bbox = bbox.view(-1,4)/szbb_keep = ((bbox[:,2]-bbox[:,0])>0).nonzero()[:,0]return bbox[bb_keep],clas[bb_keep]
你在互联网上找到的很多代码都不能用于小批量。它一次只能做一件事,而我们不想要这样。在这种情况下,所有这些函数(get_y、actn_to_bb、map_to_ground_truth)都是在一次处理,不完全是一个小批量,而是一次处理一堆地面真实对象。数据加载器每次被馈送一个小批量以执行卷积层。因为我们可以在每个图像中有不同数量的地面真实对象,但张量必须是严格的矩形形状,fastai 会自动用零填充它(任何较短的目标值)[1:11:08]。这是最近添加的一个功能,非常方便,但这意味着你必须确保去掉这些零。因此,get_y会去掉任何只是填充的边界框。
-
去掉填充
-
将激活转换为边界框
-
计算 Jaccard 指数
-
进行地面真实的映射
-
检查是否有大约 0.4~0.5 的重叠(不同的论文使用不同的值)
-
找到匹配的索引
-
为那些不匹配的分配背景类
-
然后最终得到定位的 L1 损失,分类的二元交叉熵损失,并将它们返回,加入
ssd_loss
训练
learn.crit = ssd_loss
lr = 3e-3
lrs = np.array([lr/100,lr/10,lr])
learn.lr_find(lrs/1000,1.)
learn.sched.plot(1)
'''
epoch trn_loss val_loss 0 44.232681 21476.816406
'''

learn.lr_find(lrs/1000,1.)
learn.sched.plot(1)
'''
epoch trn_loss val_loss 0 86.852668 32587.789062
'''

learn.fit(lr, 1, cycle_len=5, use_clr=(20,10))
'''
epoch trn_loss val_loss 0 45.570843 37.099854 1 37.165911 32.165031 2 33.27844 30.990122 3 31.12054 29.804482 4 29.305789 28.943184
[28.943184]
'''
learn.fit(lr, 1, cycle_len=5, use_clr=(20,10))
'''
epoch trn_loss val_loss 0 43.726979 33.803085 1 34.771754 29.012939 2 30.591864 27.132868 3 27.896905 26.151638 4 25.907382 25.739273
[25.739273]
'''
learn.save('0')
learn.load('0')
结果

在实践中,我们希望去除背景,并为概率添加一些阈值,但这是正确的方向。盆栽植物图像,结果并不令人惊讶,因为我们所有的锚盒都很小(4x4 网格)。要从这里走向更准确的东西,我们要做的就是创建更多的锚盒。
问题:对于多标签分类,为什么我们不像以前那样将分类损失乘以一个常数?很好的问题。因为后来会发现我们不需要这样做。
更多的锚点!
有 3 种方法可以做到这一点:
- 创建不同尺寸的锚盒(缩放):



从左边(1x1、2x2、4x4 的锚盒网格)。注意一些锚盒比原始图像大。
- 创建不同长宽比的锚盒:



- 使用更多卷积层作为锚盒的来源(盒子被随机抖动,以便我们可以看到重叠的盒子):

结合这些方法,你可以创建很多锚盒(Jeremy 说他不会打印出来,但这里有):

anc_grids = [4, 2, 1]
anc_zooms = [0.75, 1., 1.3]
anc_ratios = [(1., 1.), (1., 0.5), (0.5, 1.)]anchor_scales = [(anz*i,anz*j) for anz in anc_zooms for (i,j) in anc_ratios
]
k = len(anchor_scales)
anc_offsets = [1/(o*2) for o in anc_grids]
anc_x = np.concatenate([np.repeat(np.linspace(ao, 1-ao, ag), ag)for ao,ag in zip(anc_offsets,anc_grids)
])
anc_y = np.concatenate([np.tile(np.linspace(ao, 1-ao, ag), ag)for ao,ag in zip(anc_offsets,anc_grids)
])
anc_ctrs = np.repeat(np.stack([anc_x,anc_y], axis=1), k, axis=0)
anc_sizes = np.concatenate([np.array([[o/ag,p/ag] for i in range(ag*ag) for o,p in anchor_scales])for ag in anc_grids
])
grid_sizes = V(np.concatenate([np.array([ 1/ag for i in range(ag*ag) for o,p in anchor_scales])for ag in anc_grids
]), requires_grad=False).unsqueeze(1)
anchors = V(np.concatenate([anc_ctrs, anc_sizes], axis=1), requires_grad=False
).float()
anchor_cnr = hw2corners(anchors[:,:2], anchors[:,2:])
锚点:中间和高度,宽度
anchor_cnr:左上角和右下角
关键概念回顾

-
我们有一个地面真相的向量(一组 4 个边界框坐标和一个类)
-
我们有一个神经网络,它接受一些输入并输出一些输出激活
-
比较激活和地面真相,计算损失,找到该导数的导数,并根据导数乘以学习率调整权重。
-
我们需要一个损失函数,可以接受地面真相和激活,并输出一个数字,表示这些激活有多好。为了做到这一点,我们需要考虑每一个
m个地面真相对象,并决定哪组(4+c)激活负责该对象 — 我们应该比较哪一个来决定类是否正确,边界框是否接近(匹配问题)。 -
由于我们使用 SSD 方法,所以我们匹配的对象并不是任意的。我们希望匹配的是接收域密度最大的激活集,从真实对象所在的地方。
-
损失函数需要是一些一致的任务。如果在第一幅图像中,左上角的对象对应于前 4+c 个激活,并且在第二幅图像中,我们把事物扔来扔去,突然它现在与最后的 4+c 个激活一起,神经网络就不知道要学习什么。
-
一旦匹配问题解决了,其余的就和单个对象检测一样。
架构:
-
YOLO — 最后一层是全连接的(没有几何概念)
-
SSD — 最后一层是卷积
k(缩放 x 比率)
对于每个可能具有不同大小的网格单元,我们可以有不同的方向和缩放,代表不同的锚框,这些锚框就像是每个锚框都与我们模型中的一个4+c激活集相关联的概念性想法。因此,无论我们有多少个锚框,我们都需要有那么多次(4+c)激活。这并不意味着每个卷积层都需要那么多激活。因为 4x4 卷积层已经有 16 组激活,2x2 层有 4 组激活,最后 1x1 层有一组激活。所以我们基本上可以免费获得 1 + 4 + 16。因此,我们只需要知道k,其中k是缩放数乘以宽高比数。而网格,我们将通过我们的架构免费获得。
模型架构
drop=0.4class SSD_MultiHead(nn.Module):def __init__(self, k, bias):super().__init__()self.drop = nn.Dropout(drop)self.sconv0 = StdConv(512,256, stride=1, drop=drop)self.sconv1 = StdConv(256,256, drop=drop)self.sconv2 = StdConv(256,256, drop=drop)self.sconv3 = StdConv(256,256, drop=drop)self.out1 = OutConv(k, 256, bias)self.out2 = OutConv(k, 256, bias)self.out3 = OutConv(k, 256, bias)def forward(self, x):x = self.drop(F.relu(x))x = self.sconv0(x)x = self.sconv1(x)o1c,o1l = self.out1(x)x = self.sconv2(x)o2c,o2l = self.out2(x)x = self.sconv3(x)o3c,o3l = self.out3(x)return [torch.cat([o1c,o2c,o3c], dim=1),torch.cat([o1l,o2l,o3l], dim=1)]head_reg4 = SSD_MultiHead(k, -4.)
models = ConvnetBuilder(f_model, 0, 0, 0, custom_head=head_reg4)
learn = ConvLearner(md, models)
learn.opt_fn = optim.Adam
模型几乎与之前的模型相同。但我们有许多步长为 2 的卷积,这将带我们到 4x4、2x2 和 1x1(每个步长为 2 的卷积都会将我们的网格大小在两个方向上减半)。
-
在我们进行第一次卷积以达到 4x4 后,我们将从中获取一组输出,因为我们想要保存 4x4 的锚点。
-
一旦我们到达 2x2,我们再抓取一组 2x2 的锚点
-
最后我们到达 1x1
-
然后我们将它们全部连接在一起,这给我们正确数量的激活(每个锚框一个激活)。
训练
learn.crit = ssd_loss
lr = 1e-2
lrs = np.array([lr/100,lr/10,lr])
learn.lr_find(lrs/1000,1.)
learn.sched.plot(n_skip_end=2)

learn.fit(lrs, 1, cycle_len=4, use_clr=(20,8))
'''
epoch trn_loss val_loss 0 15.124349 15.015433 1 13.091956 10.39855 2 11.643629 9.4289 3 10.532467 8.822998
[8.822998]
'''
learn.save('tmp')
learn.freeze_to(-2)
learn.fit(lrs/2, 1, cycle_len=4, use_clr=(20,8))
'''
epoch trn_loss val_loss 0 9.821056 10.335152 1 9.419633 11.834093 2 8.78818 7.907762 3 8.219976 7.456364
[7.4563637]
'''
x,y = next(iter(md.val_dl))
y = V(y)
batch = learn.model(V(x))
b_clas,b_bb = batch
x = to_np(x)fig, axes = plt.subplots(3, 4, figsize=(16, 12))
for idx,ax in enumerate(axes.flat):ima=md.val_ds.ds.denorm(x)[idx]bbox,clas = get_y(y[0][idx], y[1][idx])a_ic = actn_to_bb(b_bb[idx], anchors)torch_gt(ax, ima, a_ic, b_clas[idx].max(1)[1], b_clas[idx].max(1)[0].sigmoid(), 0.2)
plt.tight_layout()
在这里,我们打印出那些至少概率为0.2的检测结果。有些看起来很有希望,但有些则不太好。

目标检测的历史

使用深度神经网络的可扩展目标检测
-
当人们提到多框法时,他们指的是这篇论文。
-
这篇论文提出了一个损失函数的想法,该函数具有匹配过程,然后可以用来进行目标检测。因此,自那时以来,一切都在尝试找出如何使其更好。
实时目标检测与区域提议网络
-
同时,Ross Girshick 正在走一条完全不同的方向。他有这两个阶段的过程,第一阶段使用经典的计算机视觉方法来找到边缘和梯度变化,猜测图像的哪些部分可能代表不同的对象。然后将每个对象放入一个卷积神经网络中,这个网络基本上是设计用来确定我们感兴趣的对象的类型。
-
R-CNN 和 Fast R-CNN 是传统计算机视觉和深度学习的混合体。
-
Ross 和他的团队接着做的是,他们采用了多框法的思想,用卷积网络替换了他们两阶段过程中传统的非深度学习计算机视觉部分。现在他们有两个卷积网络:一个用于区域提议(可能是对象的所有东西),第二部分与他之前的工作相同。
统一、实时目标检测
单次多框检测器(SSD)
-
在同一时间,这些论文出现了。这两篇论文做了一些非常酷的事情,就是他们实现了与 Faster R-CNN 相似的性能,但只用了 1 个阶段。
-
他们采用了多框法,并试图找出如何处理混乱的输出。基本思想是使用,例如,硬负样本挖掘,他们会遍历所有看起来不太好的匹配项并将其丢弃,使用非常棘手和复杂的数据增强方法,以及各种技巧。但他们让它们运行得相当不错。
密集目标检测的焦点损失(RetinaNet)
-
然后去年年底发生了一件非常酷的事情,那就是焦点损失。
-
他们实际上意识到为什么这个混乱的东西不起作用。当我们查看图像时,有 3 种不同的卷积网格粒度(4x4、2x2、1x1)。1x1 很可能与某个对象有合理的重叠,因为大多数照片都有某种主题。另一方面,在 4x4 网格单元中,大多数 16 个锚框不会与任何东西有太多重叠。因此,如果有人对你说“20 美元赌注,你认为这个小片段是什么?”而你不确定,你会说“背景”,因为大多数时候,它是背景。
问题:我理解为什么我们在图像中有一个 4x4 网格的感受野,每个都有一个锚框来粗略定位对象。但我觉得我不明白的是为什么我们需要不同尺寸的多个感受野。第一个版本已经包括了 16 个感受野,每个都有一个关联的单个锚框。通过添加,现在有更多的锚框要考虑。这是因为您限制了感受野可以从其原始大小移动或缩放的程度吗?还是有其他原因?这有点反向。Jeremy 做约束的原因是因为他知道他以后会添加更多的框。但实际上,原因是 4x4 网格单元之一与占据图像大部分的单个对象的图像之间的 Jaccard 重叠永远不会达到 0.5。交集远小于并集,因为对象太大。因此,为了使这个一般想法起作用,我们说你负责的东西与之有 50%以上的重叠,我们需要锚框,这些锚框将定期具有 50%或更高的重叠,这意味着我们需要具有各种大小、形状和比例的锚框。所有这些都发生在损失函数中。所有目标检测中大部分有趣的东西都在损失函数中。
焦点损失

关键是这张第一张图片。蓝线是二元交叉熵损失。如果答案不是摩托车,我说“我认为这不是摩托车,我有 60%的把握”用蓝线,损失仍然约为 0.5,这相当糟糕。所以,如果我们想降低损失,那么对于所有这些实际上是背景的东西,我们必须说“我确定那是背景”,“我确定这不是摩托车,公共汽车或人” — 因为如果我不说我们确定它不是这些东西中的任何一个,那么我们仍然会有损失。
这就是为什么摩托车的例子不起作用。因为即使它到达右下角并想说“我认为这是一辆摩托车”,也没有回报。如果错了,就会被淘汰。而且大多数时候,它是背景。即使不是背景,仅仅说“这不是背景”是不够的 — 你必须说它是 20 件事物中的哪一个。
所以诀窍是尝试找到一个更像紫线的不同损失函数。焦点损失实际上只是一个缩放的交叉熵损失。现在如果我们说“我有 60%的把握这不是摩托车”,那么损失函数会说“干得好!没问题”。
这篇论文的实际贡献是在方程的开头添加(1 − pt)^γ,听起来像无关紧要的事情,但实际上人们多年来一直在努力解决这个问题。当你遇到这样一个改变游戏规则的论文时,不要假设你将不得不编写成千上万行的代码。很多时候只是一行代码,或者改变一个常数,或者在一个地方添加对数。
关于这篇论文的一些了不起的事情[1:46:08]:
-
方程式以简单的方式编写
-
他们“重构”
实现焦点损失[1:49:27]:

记住,-log(pt)是交叉熵损失,焦点损失只是一个缩放版本。当我们定义二项式交叉熵损失时,您可能已经注意到默认情况下没有权重:
class BCE_Loss(nn.Module):def __init__(self, num_classes):super().__init__()self.num_classes = num_classesdef forward(self, pred, targ):t = one_hot_embedding(targ, self.num_classes+1)t = V(t[:,:-1].contiguous()) #.cpu()x = pred[:,:-1]w = self.get_weight(x,t)return F.binary_cross_entropy_with_logits(x, t, w, size_average=False) / self.num_classesdef get_weight(self,x,t): return None
当您调用F.binary_cross_entropy_with_logits时,可以传入权重。由于我们只想将交叉熵乘以某个值,我们可以定义get_weight。这是焦点损失的全部内容[1:50:23]:
class FocalLoss(BCE_Loss):def get_weight(self,x,t):alpha,gamma = 0.25,2.p = x.sigmoid()pt = p*t + (1-p)*(1-t)w = alpha*t + (1-alpha)*(1-t)return w * (1-pt).pow(gamma)
如果您想知道为什么 alpha 和 gamma 是 0.25 和 2,这篇论文的另一个优点是,因为他们尝试了许多不同的值,并发现这些值效果很好:

训练[1:51:25]
learn.lr_find(lrs/1000,1.)
learn.sched.plot(n_skip_end=2)

learn.fit(lrs, 1, cycle_len=10, use_clr=(20,10))
'''
epoch trn_loss val_loss 0 24.263046 28.975235 1 20.459562 16.362392 2 17.880827 14.884829 3 15.956896 13.676485 4 14.521345 13.134197 5 13.460941 12.594139 6 12.651842 12.069849 7 11.944972 11.956457 8 11.385798 11.561226 9 10.988802 11.362164
[11.362164]
'''
learn.save('fl0')
learn.load('fl0')
learn.freeze_to(-2)
learn.fit(lrs/4, 1, cycle_len=10, use_clr=(20,10))
'''
epoch trn_loss val_loss 0 10.871668 11.615532 1 10.908461 11.604334 2 10.549796 11.486127 3 10.130961 11.088478 4 9.70691 10.72144 5 9.319202 10.600481 6 8.916653 10.358334 7 8.579452 10.624706 8 8.274838 10.163422 9 7.994316 10.108068
[10.108068]
'''
learn.save('drop4')
learn.load('drop4')
plot_results(0.75)

这次情况看起来好多了。因此,我们现在的最后一步是基本上弄清楚如何只提取感兴趣的部分。
非极大值抑制[1:52:15]
我们要做的就是遍历每对这些边界框,如果它们重叠超过一定数量,比如 0.5,使用 Jaccard 并且它们都预测相同的类别,我们将假设它们是相同的东西,并且我们将选择具有更高p值的那个。
这是非常无聊的代码,Jeremy 自己没有写,而是复制了别人的。没有特别的原因要去研究它。
def nms(boxes, scores, overlap=0.5, top_k=100):keep = scores.new(scores.size(0)).zero_().long()if boxes.numel() == 0: return keepx1 = boxes[:, 0]y1 = boxes[:, 1]x2 = boxes[:, 2]y2 = boxes[:, 3]area = torch.mul(x2 - x1, y2 - y1)v, idx = scores.sort(0) # sort in ascending orderidx = idx[-top_k:] # indices of the top-k largest valsxx1 = boxes.new()yy1 = boxes.new()xx2 = boxes.new()yy2 = boxes.new()w = boxes.new()h = boxes.new()count = 0while idx.numel() > 0:i = idx[-1] # index of current largest valkeep[count] = icount += 1if idx.size(0) == 1: breakidx = idx[:-1] # remove kept element from view# load bboxes of next highest valstorch.index_select(x1, 0, idx, out=xx1)torch.index_select(y1, 0, idx, out=yy1)torch.index_select(x2, 0, idx, out=xx2)torch.index_select(y2, 0, idx, out=yy2)# store element-wise max with next highest scorexx1 = torch.clamp(xx1, min=x1[i])yy1 = torch.clamp(yy1, min=y1[i])xx2 = torch.clamp(xx2, max=x2[i])yy2 = torch.clamp(yy2, max=y2[i])w.resize_as_(xx2)h.resize_as_(yy2)w = xx2 - xx1h = yy2 - yy1# check sizes of xx1 and xx2.. after each iterationw = torch.clamp(w, min=0.0)h = torch.clamp(h, min=0.0)inter = w*h# IoU = i / (area(a) + area(b) - i)rem_areas = torch.index_select(area, 0, idx) # load remaining areas)union = (rem_areas - inter) + area[i]IoU = inter/union # store result in iou# keep only elements with an IoU <= overlapidx = idx[IoU.le(overlap)]return keep, count
def show_nmf(idx):ima=md.val_ds.ds.denorm(x)[idx]bbox,clas = get_y(y[0][idx], y[1][idx])a_ic = actn_to_bb(b_bb[idx], anchors)clas_pr, clas_ids = b_clas[idx].max(1)clas_pr = clas_pr.sigmoid()conf_scores = b_clas[idx].sigmoid().t().dataout1,out2,cc = [],[],[]for cl in range(0, len(conf_scores)-1):c_mask = conf_scores[cl] > 0.25if c_mask.sum() == 0: continuescores = conf_scores[cl][c_mask]l_mask = c_mask.unsqueeze(1).expand_as(a_ic)boxes = a_ic[l_mask].view(-1, 4)ids, count = nms(boxes.data, scores, 0.4, 50)ids = ids[:count]out1.append(scores[ids])out2.append(boxes.data[ids])cc.append([cl]*count)cc = T(np.concatenate(cc))out1 = torch.cat(out1)out2 = torch.cat(out2)fig, ax = plt.subplots(figsize=(8,8))torch_gt(ax, ima, out2, cc, out1, 0.1)for i in range(12): show_nmf(i)












这里还有一些需要修复的地方[1:53:43]。技巧将是使用称为特征金字塔的东西。这就是我们将在第 14 课中做的事情。
更多关于 SSD 论文的讨论[1:54:03]
当这篇论文出来时,Jeremy 很兴奋,因为这和 YOLO 是第一种单次通过的高质量目标检测方法。在深度学习世界中存在这种连续的历史重复,即涉及多次通过多个不同部分的事物,特别是当它们涉及一些非深度学习部分(如 R-CNN)时,随着时间的推移,它们总是被转化为单一的端到端深度学习模型。因此,我倾向于忽略它们,直到发生这种情况,因为那是人们已经找到如何将其展示为深度学习模型的时候,一旦他们这样做,它们通常会变得更快更准确。因此,SSD 和 YOLO 非常重要。
这个模型有 4 段。论文非常简洁,这意味着您需要非常仔细地阅读它们。但部分原因是,您需要知道哪些部分需要仔细阅读。当他们说“在这里我们将证明该模型的误差界限”时,您可以忽略,因为您不关心证明误差界限。但是当他们说这就是模型时,您需要仔细阅读。
Jeremy 阅读了一个部分2.1 模型[1:56:37]
如果您直接阅读这样的论文,这 4 段可能毫无意义。但是现在我们已经阅读过了,您阅读这些内容时,希望会想到“哦,这就是 Jeremy 说的,只是他们比 Jeremy 说得更好,用词更少[2:00:37]。如果您开始阅读一篇论文并说“到底是什么”,那么技巧就是开始回顾引文。
Jeremy 阅读匹配策略和训练目标(也称为损失函数)[2:01:44]
一些论文提示[2:02:34]
使用深度神经网络的可扩展目标检测
-
“训练目标”是损失函数
-
双条和两个 2,像这样表示均方误差

-
log©和 log(1-c),以及 x 和(1-x)它们都是二元交叉熵的组成部分。

这周,浏览代码和论文,看看发生了什么。记住 Jeremy 为了让你更容易理解,他将损失函数复制到一个单元格中,并将其拆分,使每个部分都在单独的单元格中。然后在每次出售后,他打印或绘制该值。希望这是一个好的起点。