目录
- 一、前言
- 二、分词器原理
- 1、常用分词器
- 2、ik分词器模式
- 3、指定索引的某个字段进行分词测试
- 3.1、采用ts_match_analyzer进行分词
- 3.2、采用standard_analyzer进行分词
- 三、如何调整分词器
- 1、已存在的索引调整分词器
- 2、特别的词语不能被拆开
一、前言
最近项目需求,针对客户提出搜索引擎业务要做到自定义个性化,如输入简体或繁体能能够互相查询、有的关键词不能被分词搜索等等。为更好解决这些问题,“分词器”的原理和使用至关重要。
二、分词器原理
当 ES 自带的分词器不能满足需求的情况下,可以通过组合不同的 Character Filters,Tokenizer,Token Filter 来实现。
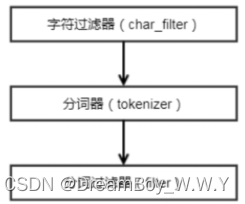
首先字符串经过字符过滤器(character filter),他们的工作是在分词前处理字符串。字符过滤器能够去除 HTML 标记,或者转化为“&”为“and”。
然后,分词器(tokenizer)被分词为独立的词【按照一定的规则,对字符串进行划分单词】。一个简单的分词器(tokenizer)可以根据空格或逗号将词语分开。
最后,每个词都通过分词过滤器(Token filter)【将切分的单词进行加工、大小写转换、删除stopwords、增加同义词等】,它可以修改词(例如将“Quick”转为小写),去掉词(例如停用词像“a”、“and”、“the”等等),或者增加词(例如同义词像“a”、“and”、“the”等等)或者增加词(例如同义词像“jump”
![[C#]winform制作圆形进度条好用的圆环圆形进度条控件和使用方法](https://img-blog.csdnimg.cn/direct/8cf01adbc3ed4d918a5dcef2b5364201.gif)