Python爬虫提取数据无非下面四点
1. 要获得怎么样的数据
2. 找到数据来源
3. 模拟浏览器发送请求获得数据
4. 处理数据,保存数据
第一步:要获得怎么样的数据
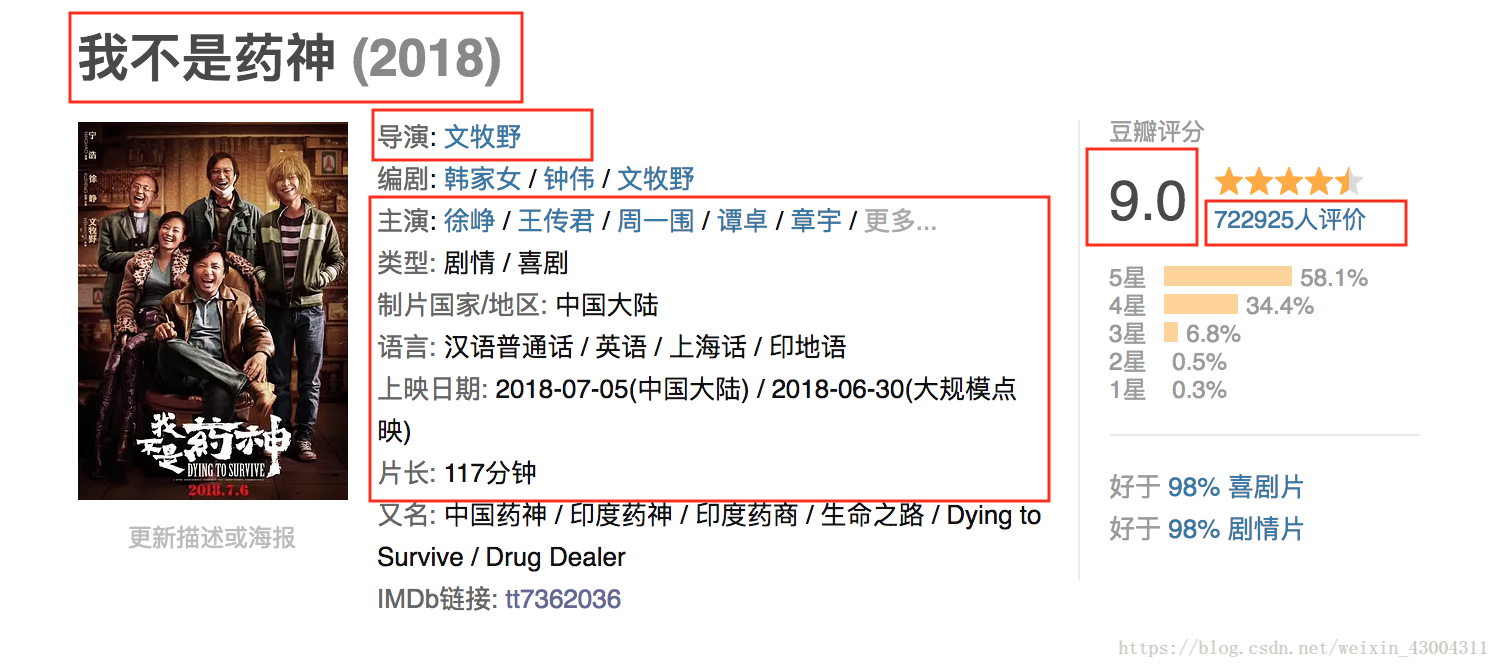
首先明白要提取什么数据,这里我们提取数据的url地址为:https://m.douban.com/music/newchinese

我们要提取里面的标题,歌手,评分,类型,精彩评论
第二步:找出数据来源
在这里PC版和手机版信息已经对比过,手机版的信息更易提取
我们打开手机版的页面

勾上箭头保证刷新页面后,不会刷新请求包
从而发现信息在该请求中

故我们请求只需请求网址:https://m.douban.com/rexxar/api/v2/subject_collection/music_chinese/items?os=ios&for_mobile=1&callback=jsonp1&start=0&count=18&loc_id=0&_=0 即可
我们猜测请求中start属性表示从第几个数据开始,count表示请求几个数据
那么我们只需一直改边start={}的值即可。直到请求失败或者返回空数据到请求数据结束。
第三步:模拟浏览器发送请求获得数据
我们查看该请求为get请求。
故我们只需制备请求头,Url即可发送get请求
数据是json类型。故可以用json模块解析数据

我们发现:Url的callback属性 callback=jsonp1 就会在请求后的数据后放在 ;jsonp1(); 括号中
故我们把callback属性删除之后还想也能请求相应的数据,且请求后的数据不含有任何其他的杂项(比如;jsonp1(); )
在此把url中的callback删除
我们制备请求头和Url如下
def __init__(self):self.TempUrl="https://m.douban.com/rexxar/api/v2/subject_collection/music_chinese/items?&for_mobile=1&start={}&count=50&_=0"self.headers={"User-Agent":"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1"
,"Referer": "https://m.douban.com/music/newchinese"}
最后一步: 处理数据,保存数据
'''
0.根据url不断请求json字符串的函数
1.根据json字符串提取出数据的函数
2.保存数据的函数
这里信息只有18条,故其实run函数的while循环只运行了一次
'''
#获取豆瓣 华语热搜榜 .其实数据就18条
import requests
import json
from pprint import pprint
#title singer rating info recommend_comment
class DoubanPC:def __init__(self):#构造函数self.TempUrl="https://m.douban.com/rexxar/api/v2/subject_collection/music_chinese/items?&for_mobile=1&start={}&count=50&_=0"self.headers={"User-Agent":"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1"
,"Referer": "https://m.douban.com/music/newchinese"}def GetJsonDate(self,url):#根据urrl得到请求的数据print("url:",url)ret=requests.get(url,headers=self.headers)return ret.content.decode()def GetWantDate(self,JsonStr):#得到想要的数据WantKeyList=["title", "singer", "rating" ,"info", "recommend_comment"]#想要提取的信息的key值Res=[]JsonStr=json.loads(JsonStr)# pprint(JsonStr)for i in JsonStr['subject_collection_items']:TempDict={}for j in WantKeyList:TempDict[j]=i[j]Res.append(TempDict)return Resdef Save(self,Str):#保存一条信息with open("douban.json","a",encoding="utf-8") as fp:fp.write(Str)fp.write("\n")def run(self):#实现主要逻辑numbers=0while True:url=self.TempUrl.format(numbers*50)JsonStr=self.GetJsonDate(url)DateList=self.GetWantDate(JsonStr)print("List legth:",len(DateList))if len(DateList)==0:breakself.Save(json.dumps(DateList,ensure_ascii=False))numbers+=1
if __name__ == '__main__':Douban=DoubanPC()Douban.run()