什么是嵌入?
OpenAI 的文本嵌入衡量文本字符串的相关性。嵌入通常用于:
- Search 搜索(结果按与查询字符串的相关性排序)
- Clustering 聚类(文本字符串按相似性分组)
- Recommendations 推荐(推荐具有相关文本字符串的条目)
- Anomaly detection 异常检测(识别出相关性很小的异常值)
- Diversity measurement 多样性测量(分析相似性分布)
- Classification 分类(其中文本字符串按其最相似的标签分类)
嵌入是浮点数的向量(列表)。两个向量之间的距离衡量它们的相关性。小距离表示高相关性,大距离表示低相关性。
访问我们的定价页面以了解嵌入定价。请求根据发送的输入中的令牌(Token) 数量计费。
如何获得嵌入
要获得嵌入,请将您的文本字符串连同选择的嵌入模型 ID(例如,text-embedding-ada-002)一起发送到嵌入 API 端点。响应将包含一个嵌入,您可以提取、保存和使用它。
示例请求:
curl https://api.openai.com/v1/embeddings \-H "Content-Type: application/json" \-H "Authorization: Bearer $OPENAI_API_KEY" \-d '{"input": "Your text string goes here","model": "text-embedding-ada-002"
}'
示例响应:
{
"data": [{"embedding": [-0.006929283495992422,-0.005336422007530928,...-4.547132266452536e-05,-0.024047505110502243],"index": 0,"object": "embedding"}],"model": "text-embedding-ada-002","object": "list","usage": {"prompt_tokens": 5,"total_tokens": 5}
}
在 OpenAI Cookbook 中查看更多 Python 代码示例。
使用 OpenAI 嵌入时,请牢记它们的 局限性和风险。
嵌入模型
OpenAI 提供了一个第二代嵌入模型(在模型 ID 中用 -002 表示)和 16 个第一代模型(在模型 ID 中用 -001 表示)。
我们建议对几乎所有用例使用 text-embedding-ada-002。它更好、更便宜、更易于使用。
| 模型生成 | 分词器 | 最大输入 token | 数据来源截止至 |
|---|---|---|---|
| V2 | cl100k_base | 8191 | Sep 2021 |
| V1 | GPT-2/GPT-3 | 2046 | Aug 2020 |
使用量按输入令牌(Token) 定价,每 1000 个令牌(Token) 0.0004 美元,或每美元约 3,000 页(假设每页约 800 个令牌(Token) ):
| 模型 | 每美元粗略页数 | BEIR 搜索评估的示例性能 |
|---|---|---|
| text-embedding-ada-002 | 3000 | 53.9 |
| -davinci--001 | 6 | 52.8 |
| -curie--001 | 60 | 50.9 |
| -babbage--001 | 240 | 50.4 |
| -ada--001 | 300 | 49.0 |
第二代模型
| 模型名称 | 分词器 | 最大输入 token | 输出 |
|---|---|---|---|
| text-embedding-ada-002 | cl100k_base | 8191 | 1536 |
第一代模型(不推荐)
所有第一代模型(以 -001 结尾的模型)都使用 GPT-3 分词器,最大输入为 2046 个分词。
用例
在这里,我们展示了一些有代表性的用例。我们将在以下示例中使用亚马逊美食评论数据集。
获取嵌入
该数据集包含截至 2012 年 10 月亚马逊用户留下的总共 568,454 条食品评论。我们将使用 1,000 条最新评论的子集用于说明目的。评论是英文的,往往是正面的或负面的。每条评论都有一个 ProductId、UserId、Score、评论标题(Summary)和评论正文(Text)。例如:
| PRODUCT ID | USER ID | SCORE | SUMMARY | TEXT |
|---|---|---|---|---|
| B001E4KFG0 | A3SGXH7AUHU8GW | 5 | Good Quality Dog Food | I have bought several of the Vitality canned… |
| B00813GRG4 | A1D87F6ZCVE5NK | 1 | Not as Advertised | Product arrived labeled as Jumbo Salted Peanut… |
我们会将评论摘要和评论文本合并为一个组合文本。该模型将对该组合文本进行编码并输出单个向量嵌入。
Obtain_dataset.ipynb
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']df['ada_embedding'] = df.combined.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))
df.to_csv('output/embedded_1k_reviews.csv', index=False)
要从保存的文件中加载数据,您可以运行以下命令:
import pandas as pddf = pd.read_csv('output/embedded_1k_reviews.csv')
df['ada_embedding'] = df.ada_embedding.apply(eval).apply(np.array)
二维数据可视化
Visualizing_embeddings_in_2D.ipynb
嵌入的大小随底层模型的复杂性而变化。为了可视化这种高维数据,我们使用 t-SNE 算法将数据转换为二维。
我们根据评论者给出的星级评分为各个评论着色:
- 1-star: red (红色)
- 2-star: dark orange (深橙色)
- 3-star: gold (金色)
- 4-star: turquoise (薄荷绿)
- 5-star: dark green (深绿色)
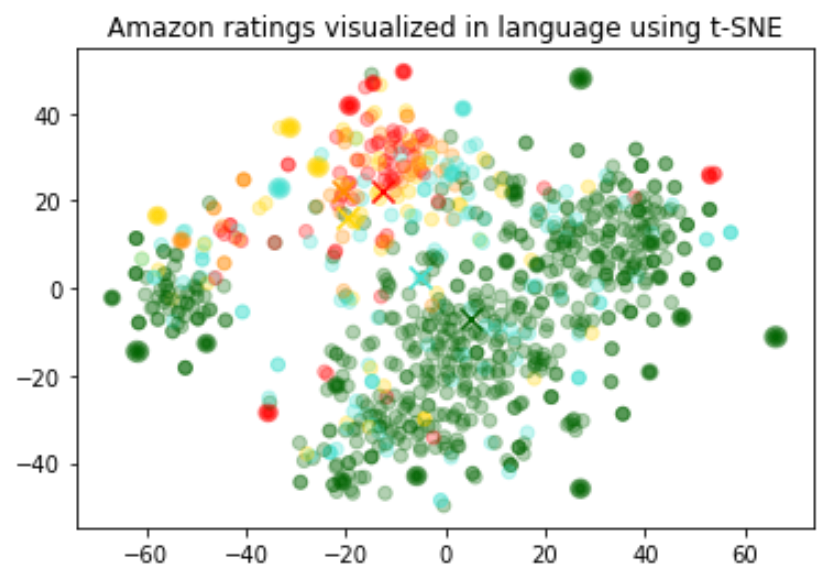
可视化似乎产生了大约 3 个集群,其中一个集群的评论大多是负面的。
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import matplotlibdf = pd.read_csv('output/embedded_1k_reviews.csv')
matrix = df.ada_embedding.apply(eval).to_list()# Create a t-SNE model and transform the datatsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
vis_dims = tsne.fit_transform(matrix)colors = ["red", "darkorange", "gold", "turquiose", "darkgreen"]
x = [x for x,y in vis_dims]
y = [y for x,y in vis_dims]
color_indices = df.Score.values - 1colormap = matplotlib.colors.ListedColormap(colors)
plt.scatter(x, y, c=color_indices, cmap=colormap, alpha=0.3)
plt.title("Amazon ratings visualized in language using t-SNE")
嵌入作为 ML 算法的文本特征编码器
Regression_using_embeddings.ipynb
嵌入可以用作机器学习模型中的通用自由文本特征编码器。如果一些相关输入是自由文本,则合并嵌入将提高任何机器学习模型的性能。嵌入也可以用作 ML 模型中的分类特征编码器。如果分类变量的名称有意义且数量众多,例如职位名称,那么这会增加最大的价值。对于此任务,相似性嵌入通常比搜索嵌入表现更好。
我们观察到,通常嵌入表示非常丰富且信息密集。例如,使用 SVD 或 PCA 降低输入的维度,即使降低 10%,通常也会导致特定任务的下游性能变差。
此代码将数据拆分为训练集和测试集,将由以下两个用例使用,即回归和分类。
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(list(df.ada_embedding.values),df.Score,test_size = 0.2,random_state=42
)
使用嵌入特征进行回归
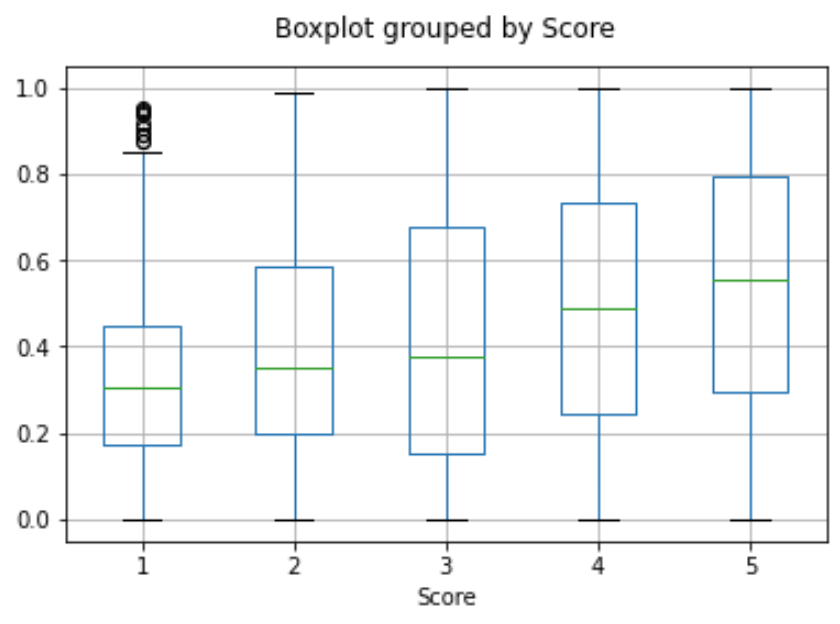
嵌入提供了一种预测数值的优雅方法。在这个例子中,我们根据评论的文本预测评论者的星级。因为嵌入中包含的语义信息很高,所以即使评论很少,预测也不错。
我们假设分数是 1 到 5 之间的连续变量,并允许算法预测任何浮点值。 ML 算法最小化预测值与真实分数的距离,并实现 0.39 的平均绝对误差,这意味着平均预测偏差不到半星。
from sklearn.ensemble import RandomForestRegressorrfr = RandomForestRegressor(n_estimators=100)
rfr.fit(X_train, y_train)
preds = rfr.predict(X_test)
使用嵌入特征进行分类
Classification_using_embeddings.ipynb
这一次,我们不再让算法预测 1 到 5 之间的任何值,而是尝试将评论的确切星数分类为 5 个桶,范围从 1 到 5 星。
训练后,该模型学习预测 1 星和 5 星评论比更细微的评论(2-4 星)更好,这可能是由于更极端的情绪表达。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_scoreclf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
零样本分类
Zero-shot_classification_with_embeddings.ipynb
我们可以在没有任何标记训练数据的情况下使用嵌入进行零样本分类。对于每个类,我们嵌入类名或类的简短描述。为了以零样本方式对一些新文本进行分类,我们将其嵌入与所有类嵌入进行比较,并预测具有最高相似度的类。
from openai.embeddings_utils import cosine_similarity, get_embeddingdf= df[df.Score!=3]
df['sentiment'] = df.Score.replace({1:'negative', 2:'negative', 4:'positive', 5:'positive'})labels = ['negative', 'positive']
label_embeddings = [get_embedding(label, model=model) for label in labels]def label_score(review_embedding, label_embeddings):
return cosine_similarity(review_embedding, label_embeddings[1]) - cosine_similarity(review_embedding, label_embeddings[0])prediction = 'positive' if label_score('Sample Review', label_embeddings) > 0 else 'negative'
获取用于冷启动推荐的用户和产品嵌入
User_and_product_embeddings.ipynb
我们可以通过对他们的所有评论进行平均来获得用户嵌入。同样,我们可以通过对有关该产品的所有评论进行平均来获得产品嵌入。为了展示这种方法的实用性,我们使用 50k 评论的子集来覆盖每个用户和每个产品的更多评论。
我们在单独的测试集上评估这些嵌入的有用性,我们将用户和产品嵌入的相似性绘制为评分的函数。有趣的是,基于这种方法,甚至在用户收到产品之前,我们就可以比随机预测更好地预测他们是否喜欢该产品。
user_embeddings = df.groupby('UserId').ada_embedding.apply(np.mean)
prod_embeddings = df.groupby('ProductId').ada_embedding.apply(np.mean)
聚类
Clustering.ipynb
聚类是理解大量文本数据的一种方式。嵌入对于这项任务很有用,因为它们提供了每个文本的语义上有意义的向量表示。因此,以一种无监督的方式,聚类将揭示我们数据集中隐藏的分组。
在这个例子中,我们发现了四个不同的集群:一个专注于狗食,一个专注于负面评论,两个专注于正面评论。
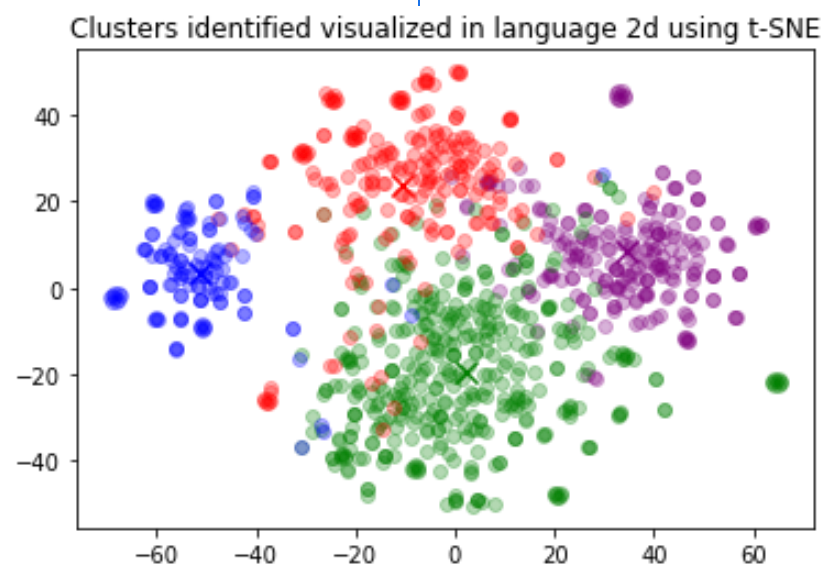
import numpy as np
from sklearn.cluster import KMeansmatrix = np.vstack(df.ada_embedding.values)
n_clusters = 4kmeans = KMeans(n*clusters = n_clusters, init='k-means++', random_state=42)
kmeans.fit(matrix)
df['Cluster'] = kmeans.labels*
使用嵌入的文本搜索
Semantic_text_search_using_embeddings.ipynb
为了检索最相关的文档,我们使用查询的嵌入向量与每个文档之间的余弦相似度,并返回得分最高的文档。
from openai.embeddings_utils import get_embedding, cosine_similaritydef search_reviews(df, product_description, n=3, pprint=True):embedding = get_embedding(product_description, model='text-embedding-ada-002')df['similarities'] = df.ada_embedding.apply(lambda x: cosine_similarity(x, embedding))res = df.sort_values('similarities', ascending=False).head(n)return resres = search_reviews(df, 'delicious beans', n=3)
使用嵌入的代码搜索
Code_search.ipynb
代码搜索的工作方式类似于基于嵌入的文本搜索。我们提供了一种从给定存储库中的所有 Python 文件中提取 Python 函数的方法。然后每个函数都由 text-embedding-ada-002 模型索引。
为了执行代码搜索,我们使用相同的模型将查询嵌入到自然语言中。然后我们计算结果查询嵌入和每个函数嵌入之间的余弦相似度。最高的余弦相似度结果是最相关的。
from openai.embeddings_utils import get_embedding, cosine_similaritydf['code_embedding'] = df['code'].apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))def search_functions(df, code_query, n=3, pprint=True, n_lines=7):embedding = get_embedding(code_query, model='text-embedding-ada-002')df['similarities'] = df.code_embedding.apply(lambda x: cosine_similarity(x, embedding))res = df.sort_values('similarities', ascending=False).head(n)return res
res = search_functions(df, 'Completions API tests', n=3)
使用嵌入的推荐
Recommendation_using_embeddings.ipynb
因为嵌入向量之间的距离越短表示相似度越高,嵌入可用于推荐。
下面,我们说明了一个基本的推荐系统。它接受一个字符串列表和一个“源”字符串,计算它们的嵌入,然后返回字符串的排名,从最相似到最不相似。作为一个具体示例,下面链接的笔记本将此函数的一个版本应用于 AG 新闻数据集(采样到 2,000 篇新闻文章描述)以返回与任何给定源文章最相似的前 5 篇文章。
def recommendations_from_strings(strings: List[str],index_of_source_string: int,model="text-embedding-ada-002",
) -> List[int]:"""Return nearest neighbors of a given string."""# get embeddings for all stringsembeddings = [embedding_from_string(string, model=model) for string in strings]# get the embedding of the source stringquery_embedding = embeddings[index_of_source_string]# get distances between the source embedding and other embeddings (function from embeddings_utils.py)distances = distances_from_embeddings(query_embedding, embeddings, distance_metric="cosine")# get indices of nearest neighbors (function from embeddings_utils.py)indices_of_nearest_neighbors = indices_of_nearest_neighbors_from_distances(distances)return indices_of_nearest_neighbors
局限性和风险
我们的嵌入模型可能不可靠或在某些情况下会带来社会风险,并且在没有缓解措施的情况下可能会造成伤害。
社会偏见
局限性:模型对社会偏见进行编码,例如通过对某些群体的刻板印象或负面情绪。
我们通过运行 SEAT(May 等人,2019 年)和 Winogender(Rudinger 等人,2018 年)基准测试发现了模型中存在偏差的证据。这些基准一起包含 7 个测试,用于衡量模型在应用于性别名称、区域名称和某些刻板印象时是否包含隐性偏见。
例如,我们发现,与非裔美国人的名字相比,我们的模型更强烈地将 (a) 欧裔美国人的名字与积极情绪联系起来,以及 (b) 对黑人女性的负面刻板印象。
这些基准在几个方面存在局限性:(a) 它们可能无法推广到您的特定用例,以及 (b) 它们仅测试极小部分可能的社会偏见。
这些测试是初步的,我们建议针对您的特定用例运行测试。这些结果应被视为该现象存在的证据,而不是对您的用例的明确描述。请参阅我们的使用政策以获取更多详细信息和指导。
如果您有任何问题,请通过聊天联系我们的支持团队;我们很乐意就此提供建议。
对最近发生的事件视而不见
局限性:模型缺乏对 2020 年 8 月之后发生的事件的了解。
我们的模型在包含 8/2020 之前真实世界事件的一些信息的数据集上进行训练。如果你依赖于代表最近事件的模型,那么它们可能表现不佳。
常见问题
在嵌入字符串之前,如何知道它有多少个 Token?
在 Python 中,您可以使用 OpenAI 的分词器 tiktoken 将字符串拆分为分词。
示例代码:
import tiktokendef num_tokens_from_string(string: str, encoding_name: str) -> int:"""Returns the number of tokens in a text string."""encoding = tiktoken.get_encoding(encoding_name)num_tokens = len(encoding.encode(string))return num_tokensnum_tokens_from_string("tiktoken is great!", "cl100k_base")
对于像 text-embedding-ada-002 这样的第二代嵌入模型,使用 cl100k_base 编码。
更多详细信息和示例代码在 OpenAI Cookbook 指南中如何使用 tiktoken 计算令牌(Token) 。
如何快速检索 K 个最近的嵌入向量?
为了快速搜索多个向量,我们建议使用向量数据库。您可以在 GitHub 上的 Cookbook 中找到使用向量数据库和 OpenAI API 的示例。
向量数据库选项包括:
- Pinecone, 完全托管的向量数据库
- Weaviate, 开源向量搜索引擎
- Redis 用作向量数据库
- Qdrant, 向量搜索引擎
- Milvus, 为可扩展的相似性搜索而构建的向量数据库
- Chroma,一个开源嵌入数据库
- Typesense,快速开源矢量搜索
- Zilliz,数据基础设施,由 Milvus 提供支持
我应该使用哪个 distance 函数?
我们推荐余弦相似度。distance 函数的选择通常无关紧要。
OpenAI 嵌入被归一化为长度 1,这意味着:
- 仅使用点积可以稍微更快地计算余弦相似度
- 余弦相似度和欧几里德距离将导致相同的排名







![[机器学习]K-means——聚类算法](https://img-blog.csdnimg.cn/direct/cfe264aecec147118f4418f5794bff14.png)
![IAR报错:Error[Pa045]: function “halUartInit“ has no prototype](https://img-blog.csdnimg.cn/direct/dd80ac0e3da6430ca49ba1b50c6e1219.png)