Reduce 算子优化
- 注: 本文主要是对文章 【BBuf的CUDA笔记】三,reduce优化入门学习笔记 - 知乎 的学习整理
Reduce 又称之为归约, 即根据数组中的每个元素得到一个输出值, 常见的包括求和(sum)、取最大值(max)、取最小值(min)等.
前言
本文同样按照英伟达官方 PPT 文档 Optimizing Parallel Reduction in CUDA 的优化思路给出一步步优化的 kernel 实现.
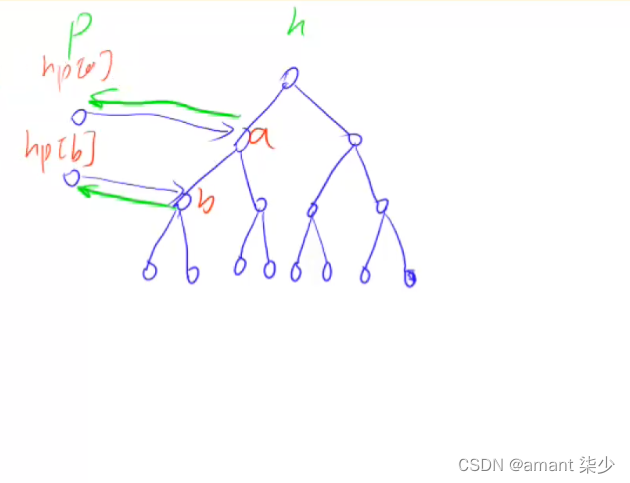
本文中的 reduce 算子实现, 都采用树形归约的方式, 这种方式更适合 GPU 这种可以大规模并行的情况. 整体 reduce 划分为两个阶段: 首先是对全部数据划分为线程块归分别约成 1 个结果, 然后再对每个线程块归约后的结果地进行同样地归约, 如此递归, 最后可以得到最终的 1 个结果. 如下图所示:
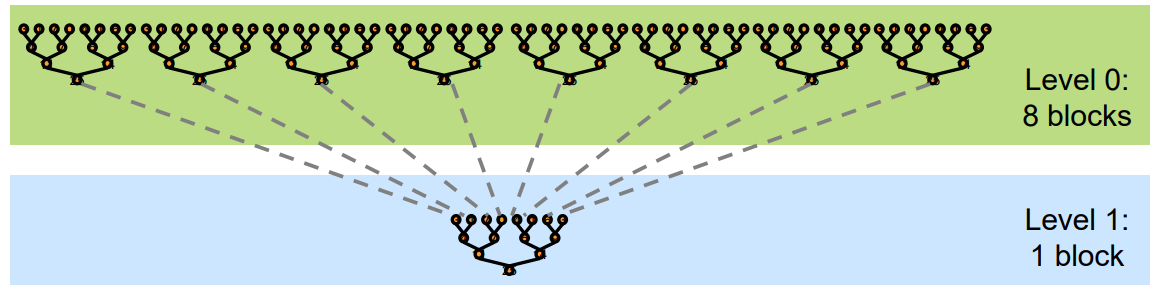
因此, 本文的线程块 Reduce 算子的函数可以定义为 void reduce(T* input, T* output, size_t n), 实现对 n 个数据 input 按照线程块大小 block_size 归约, 得到 (n+block_size-1)/block_size 个输出数据 output.
以下 kernel 笔者均是在 NVIDIA V100 (7.0 算力) 上进行测试的(线程块大小固定选择 256), 代码参照 BBuf 仓库的 reduce 目录. 注: 可能由于 GPU 和实际代码的不同测试结果和相关博文存在差异.
Kernel 0: Baseline
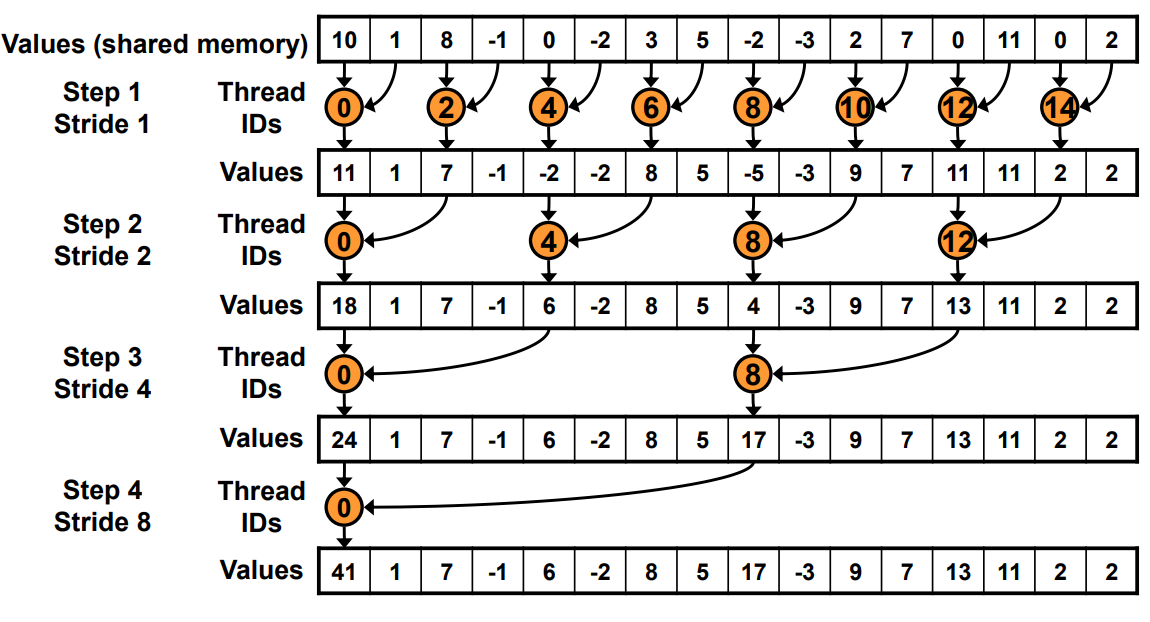
__global__ void reduce_v0(float *g_idata,float *g_odata){__shared__ float sdata[BLOCK_SIZE];// each thread loads one element from global to shared memunsigned int tid = threadIdx.x;unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;sdata[tid] = g_idata[i];__syncthreads();// do reduction in shared memfor(unsigned int s=1; s < blockDim.x; s *= 2) {if (tid % (2*s) == 0) {sdata[tid] += sdata[tid + s];}__syncthreads();}// write result for this block to global memif (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
Baseline 实现很直接, 整体分为 3 个步骤: 第 1 步每个线程加载一个数据到共享内存; 第 2 步为核心的归约代码, 对共享内存中的数据按照指数级跨度进行归约; 第 3 步将线程块归约的结果写回全局内存.
可视化如下图所示. 在归约的时候, 每个线程仍然对应 1 个元素, 但只有满足 tid % (2*s) == 0 线程为有效线程, 进行归约操作.
| kernel | 用时(us) | 内存带宽(GB/s) | 带宽利用率(%) | 加速比 |
|---|---|---|---|---|
| v0 | 788.29 | 170.90 | 40.97 |
在官方 PPT 指出这个 baseline 的两个问题, 都在 if (tid % (2*s) == 0) 这个条件判断语句, 一是会造成 warp divergence; 二是取余操作性能很差. 后者无需多言, 前者 warp divergenc 也很好理解, 因为每个 warp 中, 每隔 2*s 个才有一个是满足条件的线程进行归约计算, 而其余的线程什么都不做但是要等待, 这样使得直至 s>=16 的每次迭代 warp 中都要有两个分支.
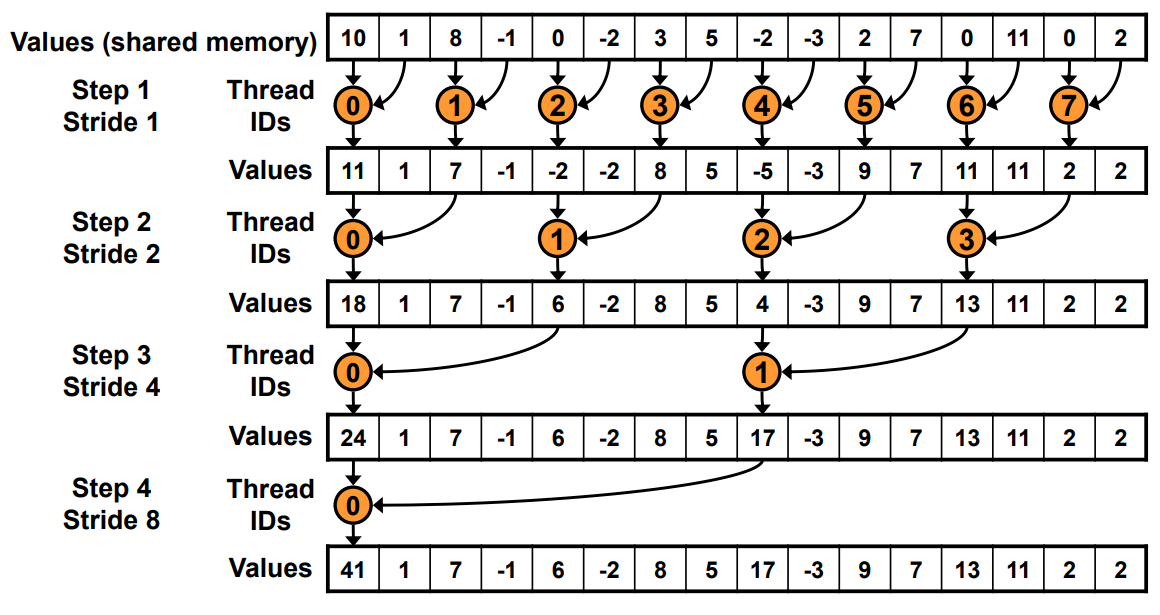
Kernel 1: 间隔寻址
__global__ void reduce_v1(float *g_idata,float *g_odata){__shared__ float sdata[BLOCK_SIZE];// each thread loads one element from global to shared memunsigned int tid = threadIdx.x;unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;sdata[tid] = g_idata[i];__syncthreads();// do reduction in shared memfor(unsigned int s=1; s < blockDim.x; s *= 2) {// if (tid % (2*s) == 0) {// sdata[tid] += sdata[tid + s];// }int index = 2 * s * tid;if (index < blockDim.x) {sdata[index] += sdata[index + s];}__syncthreads();}// write result for this block to global memif (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
Kernel 1 针对 Kernel 0 的两个问题进行了解决, 将条件语句由 tid % (2*s) == 0 替换为了 2 * s * tid < blockDim.x.
很直观的是原本的取余操作不见了. 而这种实现的核心是, 将原本每次迭代每个线程始终负责 1 个数据, 变为每次迭代每个线程对应 1 个归约操作的 s 个数据. 如下图所示, 原本的 kernel 0 可以理解为每个线程对应上面的 10, 1, 8 -1, ... 这些数据; 而现在变成了每个线程对应下面有橙色的归约过程.
这样在满足条件的线程个数小于 32 之前, 都不会有 warp divergence. 在这之后虽然有 warp divergence, 但实际工作的 warp 只有 1 个, 相比于 kernel 0 从一开始就有的情况会好很多.
| kernel | 用时(us) | 内存带宽(GB/s) | 带宽利用率(%) | 加速比 |
|---|---|---|---|---|
| v0 | 788.29 | 170.90 | 40.97 | |
| v1 | 502.43 | 268.13 | 90.72 | 1.56 |
kernel 1 的问题也相对比较明显: 在满足 if 语句的线程中, 每个线程会读取 sdata[index] 和 sdata[index + s] 两个共享内存上的数据, 在同一 warp 内相邻两个线程读取的这两个数据分别间隔 2*s, 这样 threadIdx 相差 32/(2*s) (s<=16) 的线程读取的数据就相隔 32 个(s>=16 是, 读取的数据相隔为 32 的倍数), 从而会产生 bank conflict. bank conflict 会增加线程读写共享内存的延迟, 从而降低性能.
Kernel 1.5: 取余替换
在 深入浅出GPU优化系列:reduce优化 - 知乎 文章的评论区, 用户"见南山"提出了将 kernel 0 中取余操作等价替换的方法. 关键代码如下:
// do reduction in shared memfor(unsigned int s=1; s < blockDim.x; s *= 2) {// if (tid % (2*s) == 0) {// sdata[tid] += sdata[tid + s];// }if ((tid & (2*s-1)) == 0) {sdata[tid] += sdata[tid + s];}__syncthreads();}
这里是考虑到 s 是从 1 按 2 的指数增大, 正好对应 1 个比特位, 因此 2*s-1 就可以作为一个取余的掩码.
该 kernel 的性能相当高, 甚至与后面 kernel 2 的性能相当.
这反应出取余操作在 GPU 上的开销是很大的, 这才是 kernel 0 性能差的首要原因; 而 warp divergence 可能是因为这里的条件分支只有 if 语句没有 else 语句, warp 中不满足条件的线程只是什么也不做, 因此并不会有分支造成的额外开销; 而同时, 由于 kernel 1.5 仍然是一个线程对应一个数据, 也没有前文提到的 kernel 1 严重的 bank conflict 问题, 因此性能比 kernel 1 还要高.
| kernel | 用时(us) | 内存带宽(GB/s) | 带宽利用率(%) | 加速比 |
|---|---|---|---|---|
| v0 | 788.29 | 170.90 | 40.97 | |
| v1 | 502.43 | 268.13 | 90.72 | 1.56 |
| v1.5 | 394.88 | 341.16 | 82.54 | 2.00 |
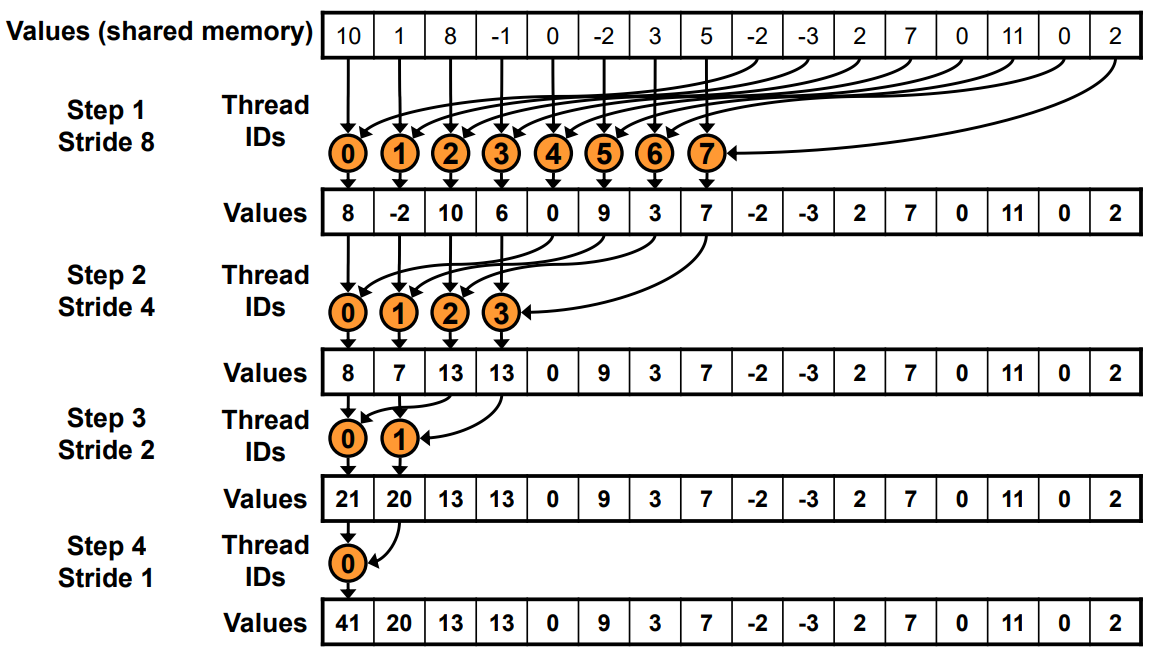
Kernel 2: 顺序寻址
__global__ void reduce_v2(float *g_idata,float *g_odata){__shared__ float sdata[BLOCK_SIZE];// each thread loads one element from global to shared memunsigned int tid = threadIdx.x;unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;sdata[tid] = g_idata[i];__syncthreads();// do reduction in shared memfor(unsigned int s=blockDim.x/2; s>0; s >>= 1) {if (tid < s){sdata[tid] += sdata[tid + s];}__syncthreads();}// write result for this block to global memif (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
kernel 2 同样是对共享内存归约的 for 循环进行了改动, 之所以称之为"顺序寻址", 就是因为相比与 kernel 1, 每个线程读取的两个数据仍然相差 s, 但相邻线程之间读取的数据则变成连续的了, 即间隔 1. 如下图所示. 这样 warp 内的 32 个线程读取的数据就映射到了不同的 32 个 bank, 从而避免了 bank conflict 的问题, 进而提高了性能.
(注: 额外一提的是, 每个线程会读取间隔差 s 的两个数据, 当 s>=32 时两个数据同样会位于同一 bank 上, 但并不会有 bank conflict, 因为这两个数据是由同一线程读取的, 地址不连续的情况下必然要通过前后两个 load 指令读取, 因此不会有 bank conflict; bank conflict 需要是不同线程同时读取同一 bank 才会发生.)
| kernel | 用时(us) | 内存带宽(GB/s) | 带宽利用率(%) | 加速比 |
|---|---|---|---|---|
| v0 | 788.29 | 170.90 | 40.97 | |
| v1 | 502.43 | 268.13 | 90.72 | 1.56 |
| v1.5 | 394.88 | 341.16 | 82.54 | 2.00 |
| v2 | 375.90 | 358.38 | 85.79 | 2.10 |
可以看到 kernel 2 的性能相比 kernel 1 有了明显提升.
Kernel 3: 解决空闲线程
前面所有的 kernel 其实都存在一个问题, 即在数据加载到共享内存之后的归约阶段(也就是 for 循环部分), 由于是两两归约, 每次迭代实际工作的线程数均减半, 因此每个线程块在第一次迭代就有一半的线程在闲置, 且一直闲置到最后. 这对 GPU 资源而言是很大的浪费.
在官方 PPT 文档中给出了这样的解决方法, 即让每个线程在从全局内存加载数据到共享内存时, 额外做一次归约操作(即加法).
__global__ void reduce_v3(float *g_idata,float *g_odata){__shared__ float sdata[BLOCK_SIZE];// perform first level of reduction,// reading from global memory, writing to shared memoryunsigned int tid = threadIdx.x;unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;sdata[tid] = g_idata[i] + g_idata[i + blockDim.x];__syncthreads();// do reduction in shared memfor(unsigned int s=blockDim.x/2; s>0; s >>= 1) {if (tid < s){sdata[tid] += sdata[tid + s];}__syncthreads();}// write result for this block to global memif (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
从代码来看, 修改的是 for 循环前面的数据加载部分. 先前的 kernel 都是每个线程读取 1 个数据, 现在每个线程变成了读取 2 个数据, 并进行一次归约操作. 这样, 相当于刚刚所说的线程块中一直空闲的半数线程也会做一次计算, 从而提高内核的计算强度.
值得一提的是, 现在一个线程读取两个数据, 因此在计算索引 i 的时候要 blockDim.x*2; 同样需要注意的是, 在数据量固定的情况下, 启动 kernel 所设置的线程块数 grid_size 也需要减半.
| kernel | 用时(us) | 内存带宽(GB/s) | 带宽利用率(%) | 加速比 |
|---|---|---|---|---|
| v0 | 788.29 | 170.90 | 40.97 | |
| v1 | 502.43 | 268.13 | 90.72 | 1.56 |
| v1.5 | 394.88 | 341.16 | 82.54 | 2.00 |
| v2 | 375.90 | 358.38 | 85.79 | 2.10 |
| v3 | 205.89 | 653.10 | 81.72 | 3.83 |
可以看到, kernel 3 的性能相比 kernel 2 有了进一步的提升, 且内存带宽也有了大幅提高. 笔者分析, 应该是 kernel 3 每个线程读取了 2 个数据从而提高了内存带宽; 虽然将两个全局内存的数据直接进行归约性能不如后续在共享内存中归约, 但整体上减少了先前 kernel 半数线程块的启动, 因此也带来了较大的性能提升.
Kernel 4: 展开最后一个 warp (CC<7.0)
在官方 PPT 文档的第 20 页介绍了 reduce 算子的一些特点:
- 到目前为止, reduce 的带宽与 GPU 的带宽上限还相差很远(这里笔者其实并不是很理解, 可能与官方文档使用的 GPU 有关, 在笔者使用的 V100 上可以看到带宽利用率已经达到 80%, 已经比较高了). 很关键的一点原因是 reduce 是一个低算术强度的算子, 即计算量本身就不大.
- 指令开销可能成为性能瓶颈. 这里说的指令不是加载、存储或者算术指令; 而是指地址算术指令和循环的开销.
__device__ void warpReduce(volatile float* cache, unsigned int tid){cache[tid]+=cache[tid+32];cache[tid]+=cache[tid+16];cache[tid]+=cache[tid+8];cache[tid]+=cache[tid+4];cache[tid]+=cache[tid+2];cache[tid]+=cache[tid+1];
}__global__ void reduce_v4(float *g_idata,float *g_odata){__shared__ float sdata[BLOCK_SIZE];// perform first level of reduction,// reading from global memory, writing to shared memoryunsigned int tid = threadIdx.x;unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;sdata[tid] = g_idata[i] + g_idata[i + blockDim.x];__syncthreads();// do reduction in shared memfor(unsigned int s=blockDim.x/2; s>32; s >>= 1) {if (tid < s) {sdata[tid] += sdata[tid + s];}__syncthreads();}// write result for this block to global memif (tid < 32) warpReduce(sdata, tid);if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
官方 PPT 文档给出的减少指令开销的方法即"展开最后一个 warp".
因为 warp 是 GPU 最基本的调度单元, 当归约过程(即 for 循环)中满足条件的线程数小于等于 32 后, 实际上只有一个 warp 在工作, 此时由于在 warp 内的指令满足 SIMT 同步(注: 这个要求算力 7.0 以下的 GPU, 后文会具体说明), 因此无需 __syncthreads(), 而且也不再需要 if (tid < s) 的条件判断(因为 warp 内线程都会执行这些指令, 这也是 warp divergence 的原因).
因此从代码看, 当 tid<32 时, 便调用 warpReduce() 函数, 该函数即将原本这部分的 for 循环手动进行了展开.
值得注意的是, 这里 warpReduce() 的参数 cache 即要处理的共享内存数据, 需要加上 volatile 修饰符, 表示该变量是"易变的", 其作用是保证每次对 cache 访问是都重新从共享内存中加载数据. 原因是编译器可能会对代码进行一些优化, 将需要访问的共享内存数据预先保存在寄存器中, 特别是一些架构的 GPU 共享内存之间的数据拷贝必须要经过寄存器; 此时去掉 volatile 可能导致线程保存在寄存器中的值并不是刚刚由其他线程计算好的最新的结果值, 而导致计算结果错误. 比如线程 0 在计算 cache[0]+=cache[0+4] 时, 需要读取最新的 cache[4], 这有之前线程 4 的 cache[4]+=cache[4+8] 计算得到; 而没有 volatile 时编译器在线程 0 预先加载了 cache[4] 的结果到寄存器, 那么就不能拿到线程 4 更新的结果. 相关内容可参见 Stack Overflow 上的回答.
| kernel | 用时(us) | 内存带宽(GB/s) | 带宽利用率(%) | 加速比 |
|---|---|---|---|---|
| v0 | 788.29 | 170.90 | 40.97 | |
| v1 | 502.43 | 268.13 | 90.72 | 1.56 |
| v1.5 | 394.88 | 341.16 | 82.54 | 2.00 |
| v2 | 375.90 | 358.38 | 85.79 | 2.10 |
| v3 | 205.89 | 653.10 | 81.72 | 3.83 |
| v4 | 176.86 | 760.28 | 43.47 | 4.46 |
可以看到, 测试性能和带宽又有了一定提升, 不过这里带宽利用率却降低到了 43%, 这里笔者也并不清楚原因, 在参考的博客中也提到了该问题.
Kernel 4.1: 展开最后一个 warp (CC>=7.0)
上文提到, kernel 4 中可以展开最后一个 warp 的很重要的原因是"warp 内的指令满足 SIMT 同步", 但需要注意的是, 在 NVIDIA 7.0 及以上算力的 GPU 上不再一定满足, 7.0 算力开始 NVIDIA 提出了 “independent thread scheduling” 即"独立的线程调度"的架构, 这使得 warp 内 32 个线程共用一个 PC 指针和栈变成了线程各自拥有自己的 PC 指针和栈; 重要的是, 这使得 warp 内的 32 个线程并不一定同步执行指令, 即 32 个线程在实际运行时可能也有快有慢. 关于"独立的线程调度", 可以参考 Using CUDA Warp-Level Primitives | NVIDIA Technical Blog, 关于GPU一些笔记(SIMT方面)_simt core-CSDN博客, CUDA微架构与指令集(5)-Independent Thread Scheduling - 知乎 等相关文章, 在此不多赘述.
虽然笔者在 V100 (算力 7.0) 上运行 kernel 4 也能得到正确结果, 但严谨来看, 对于算力 7.0 开始的 GPU 而言, 上述实现是存在问题的. 在 Using CUDA Warp-Level Primitives | NVIDIA Technical Blog 这篇 NVIDIA 官方博客中, 提到了一个正确的解决方法, 结合 kernel 4 代码, warpReduce() 函数修改后如下:
__device__ void warpReduce(volatile float* cache, unsigned int tid){int v = cache[tid];v += cache[tid+32]; __syncwarp();cache[tid] = v; __syncwarp();v += cache[tid+16]; __syncwarp();cache[tid] = v; __syncwarp();v += cache[tid+8]; __syncwarp();cache[tid] = v; __syncwarp();v += cache[tid+4]; __syncwarp();cache[tid] = v; __syncwarp();v += cache[tid+2]; __syncwarp();cache[tid] = v; __syncwarp();v += cache[tid+1]; __syncwarp();cache[tid] = v;
}
可以看到, 代码发生的变化主要有两点:
- 在原本共享内存的数据赋值之间使用了寄存器变量
v来传递. - 在每次共享内存的读或写操作之后都加上了
__syncwarp()函数进行同步.
__syncwarp() 函数的作用是让 warp 内的 32 个线程进行同步(类似于线程块同步的 __syncthreads()), 通过该函数, warp 内线程每执行一步操作后都会同步, 从而避免了线程步调不一致造成的读写竞态, 达到了算力 7.0 以下 GPU 执行 kernel 4 的效果.
这里的 volatile 修饰符笔者在保留和去掉两种情况下都能得到正确结果. 但笔者个人感觉保留还是比较稳妥, 因为虽然此时使用了寄存器变量 v, 但实际上是 v = v + cache[] 的加法运算操作, 理论上共享内存的数据还是需要先加载到一个寄存器上的, 所以为了避免编译器使用寄存器优化, volatile 还是有必要的.
额外说明的是, 根据上述的 NVIDIA 官方博客, cache[tid] += cache[tid+16]; __syncwarp(); 这样修改 warpReduce() 的代码是不正确的. 该代码相当于每完成一次对共享内存的读写操作后再进行 warp 的线程同步. 这样仍然是会存在不同线程间读写共享内存的竞态问题, 因为这只能保证调用 __syncwarp() 时的线程同步, 而这之间有读和写共享内存的两个操作, 无法保证每个线程这两个操作步调都是一致的. 仍然是上面的例子, 线程 0 在执行 cache[0]+=cache[0+4] 时需读取 cache[4], 此时线程 4 执行 cache[4]+=cache[4+4], 但如果线程 0 在读取之前线程 4 已经完成了对 cache[4] 的写入, 那么结果就会产生错误. 而上述 kernel 4.1 的代码则可以避免此问题.
| kernel | 用时(us) | 内存带宽(GB/s) | 带宽利用率(%) | 加速比 |
|---|---|---|---|---|
| v0 | 788.29 | 170.90 | 40.97 | |
| v1 | 502.43 | 268.13 | 90.72 | 1.56 |
| v1.5 | 394.88 | 341.16 | 82.54 | 2.00 |
| v2 | 375.90 | 358.38 | 85.79 | 2.10 |
| v3 | 205.89 | 653.10 | 81.72 | 3.83 |
| v4 | 176.86 | 760.28 | 43.47 | 4.46 |
| v4.1 | 183.23 | 733.86 | 70.28 | 4.30 |
在性能上, 因为引入了额外的操作, 性能比 kernel 4 稍差, 但仍比 kernel 3 要好.
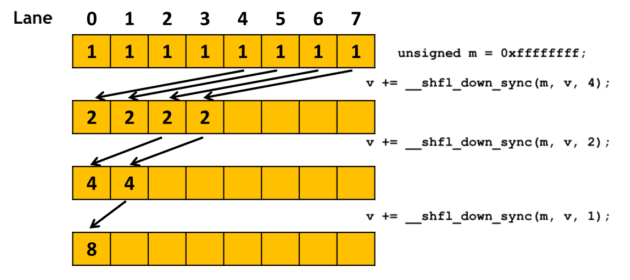
Kernel 4.2: 展开最后一个 warp (warp 原语)
仍然是在 Using CUDA Warp-Level Primitives | NVIDIA Technical Blog 这篇官方文章中, 提到了使用 warp 层次原语实现的归约算法. 结合 kernel 4 代码, warpReduce() 函数修改后如下:
#define FULL_MASK 0xffffffff
__device__ void warpReduce(float* cache, unsigned int tid){int v = cache[tid] + cache[tid + 32];v += __shfl_down_sync(FULL_MASK, v, 16);v += __shfl_down_sync(FULL_MASK, v, 8);v += __shfl_down_sync(FULL_MASK, v, 4);v += __shfl_down_sync(FULL_MASK, v, 2);v += __shfl_down_sync(FULL_MASK, v, 1);cache[tid] = v;
}
代码的关键在于使用了 __shfl_down_sync() 函数, 它正是一个 warp 层次的原语, 用于获取 warp 内其他线程变量的函数, 它的优势在于可以直接在寄存器间进行变量交换而无需通过共享内存, 因此更加高效. 而且正如函数名的 sync, 每次函数调用都会进行 warp 内线程的同步, 保证 warp 内线程的步调一致. 值得一提的是, 由于是 warp 内的数据交换, __shfl_down_sync() 的第三个参数, 即偏移值 offset 不能超过 31, 因此 warpReduce() 函数第一次跨度为 32 的归约操作不能通过上述函数实现, 需要从共享内存中读取并归约, 而后续便可以使用 __shfl_down_sync() 逐次调整偏移值即可达到 warp 内归约的效果. 如下图所示.
| kernel | 用时(us) | 内存带宽(GB/s) | 带宽利用率(%) | 加速比 |
|---|---|---|---|---|
| v0 | 788.29 | 170.90 | 40.97 | |
| v1 | 502.43 | 268.13 | 90.72 | 1.56 |
| v1.5 | 394.88 | 341.16 | 82.54 | 2.00 |
| v2 | 375.90 | 358.38 | 85.79 | 2.10 |
| v3 | 205.89 | 653.10 | 81.72 | 3.83 |
| v4 | 176.86 | 760.28 | 43.47 | 4.46 |
| v4.1 | 183.23 | 733.86 | 70.28 | 4.30 |
| v4.2 | 176.13 | 763.46 | 40.09 | 4.48 |
在性能上, kernel 4.2 的性能与 kernel 4 相差无几, 但相对而言, 这应该是算力 7.0 及以上 GPU 进行 warp 归约的更好的实现选择, 符合这之后的 CUDA 编程模型.
- 注: 后续由于仍按照英伟达官方 PPT 文档的思路, 因此后面几个 kernel 仍然使用的是 kernel 4 的
warpReduce()的实现, 但在实际中更推荐 kernel 4.2 的实现方式.
Kernel 5: 完全展开
template <unsigned int blockSize>
__device__ void warpReduce(volatile float* cache,int tid){if(blockSize >= 64) cache[tid] += cache[tid+32];if(blockSize >= 32) cache[tid] += cache[tid+16];if(blockSize >= 16) cache[tid] += cache[tid+8];if(blockSize >= 8) cache[tid] += cache[tid+4];if(blockSize >= 4) cache[tid] += cache[tid+2];if(blockSize >= 2) cache[tid] += cache[tid+1];
}template <unsigned blockSize>
__global__ void reduce_v5(float *g_idata,float *g_odata){__shared__ float sdata[BLOCK_SIZE];// perform first level of reduction,// reading from global memory, writing to shared memoryunsigned int tid = threadIdx.x;unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;sdata[tid] = g_idata[i] + g_idata[i + blockDim.x];__syncthreads();// do reduction in shared memif (blockSize == 1024) {if (tid < 512) sdata[tid] += sdata[tid+512];__syncthreads();}if (blockSize >= 512) {if (tid < 256) sdata[tid] += sdata[tid+256];__syncthreads();}if (blockSize >= 256) {if(tid < 128) sdata[tid] += sdata[tid+128];__syncthreads();}if (blockSize >= 128) {if (tid < 64) sdata[tid] += sdata[tid+64];__syncthreads();}// write result for this block to global memif (tid < 32) warpReduce<blockSize>(sdata, tid);if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
在 kernel 4 基础上再进行优化就比较困难了, kernel 5 采取了"完全展开"的策略, 即将原本的 for 循环完全展开, 并设置了模板参数 blockSize 和相应的条件判断语句. 这是因为对于很多程序而言, blockSize 是一个编译器常量, 因此可以作为模板参数, 这样配合完全展开, 编译器可以根据实际的 blockSize 大小进行转换跳过不符合的 blockSize 的条件体语句 (可以理解为 if constexpr), 进而得到更精简的指令, 提高执行速度.
顺便一提, 相比与官方 PPT 给出的 kernel, 这里我增加了 blockSize == 1024 的判断, 这是根据 NVIDIA GPU 算力及规格参数 线程块大小 blockSize 最大为 1024, 在此时就会多出一次展开. (在实际调用时, blockSize 我们往往选择 256.)
| kernel | 用时(us) | 内存带宽(GB/s) | 带宽利用率(%) | 加速比 |
|---|---|---|---|---|
| v0 | 788.29 | 170.90 | 40.97 | |
| v1 | 502.43 | 268.13 | 90.72 | 1.56 |
| v1.5 | 394.88 | 341.16 | 82.54 | 2.00 |
| v2 | 375.90 | 358.38 | 85.79 | 2.10 |
| v3 | 205.89 | 653.10 | 81.72 | 3.83 |
| v4 | 176.86 | 760.28 | 43.47 | 4.46 |
| v4.1 | 183.23 | 733.86 | 70.28 | 4.30 |
| v4.2 | 176.13 | 763.46 | 40.09 | 4.48 |
| v5 | 175.52 | 766.10 | 44.06 | 4.49 |
可以看到 kernel 5 相比与 kernel 4 而言性能提升并不明显, 由此也可以看出 CUDA 编译器已经将优化做的很好了.
Kernel 6: 每个线程更多的计算和合理设置线程块数
在官方 PPT 文档的第 31 页给出了最后的优化技巧. 其中很重要的一点是: 每个线程更多的工作可以提供更好的延迟隐藏. 这有点类似于 kernel 3 的做法, kernel 3 只是让空闲的线程多做了 1 次归约计算, 而实际上我们可以做更多次, 而这样就会导致需要的线程块数 grid_size 成倍减少. 因此, 这两者实际上是一回事.
template <unsigned int blockSize>
__device__ void warpReduce(volatile float* cache,int tid){if(blockSize >= 64) cache[tid] += cache[tid+32];if(blockSize >= 32) cache[tid] += cache[tid+16];if(blockSize >= 16) cache[tid] += cache[tid+8];if(blockSize >= 8) cache[tid] += cache[tid+4];if(blockSize >= 4) cache[tid] += cache[tid+2];if(blockSize >= 2) cache[tid] += cache[tid+1];
}template <unsigned blockSize, unsigned NUM_PER_THREAD>
__global__ void reduce_v6(float *g_idata,float *g_odata){__shared__ float sdata[BLOCK_SIZE];// each thread loads one element from global to shared memunsigned int tid = threadIdx.x;unsigned int i = blockIdx.x * (blockDim.x * NUM_PER_THREAD) + threadIdx.x;sdata[tid] = 0;#pragma unrollfor(int iter = 0; iter < NUM_PER_THREAD; ++iter){sdata[tid] += g_idata[i + iter * blockSize];}__syncthreads();// do reduction in shared memif (blockSize == 1024) {if (tid < 512) sdata[tid] += sdata[tid+512];__syncthreads();}if (blockSize >= 512) {if (tid < 256) sdata[tid] += sdata[tid+256];__syncthreads();}if (blockSize >= 256) {if(tid < 128) sdata[tid] += sdata[tid+128];__syncthreads();}if (blockSize >= 128) {if (tid < 64) sdata[tid] += sdata[tid+64];__syncthreads();}// write result for this block to global memif (tid < 32) warpReduce<blockSize>(sdata, tid);if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}int main() {// ...const int BLOCK_NUM = 2048;const int NUM_PER_BLOCK = N / BLOCK_NUM;const int NUM_PER_THREAD = NUM_PER_BLOCK / BLOCK_SIZE;reduce_v6<BLOCK_SIZE, NUM_PER_THREAD><<<BLOCK_NUM, BLOCK_SIZE>>>(...);// ...
}
代码上来看, 核心的变化是从全局内存加载元素的地方变成了一个 for 循环: 从全局内存加载 NUM_PER_THREAD 个数据到共享内存并归约. 而这里的 NUM_PER_THREAD, 即每个线程从全局内存加载的数据个数, 是根据数据总数 N 和线程块数 BLOCK_NUM 算出来的.
额外一提的是, 在上述测试代码中, NUM_PER_THREAD 之所以能作为模板参数, 关键是这里 N 是常数, 在实际情况下归约的总数 n 往往是一个变量, 这时候 NUM_PER_THREAD 就只能在运行时计算得到, 从而退化为 reduce 函数的参数了.
| kernel | 用时(us) | 内存带宽(GB/s) | 带宽利用率(%) | 加速比 |
|---|---|---|---|---|
| v0 | 788.29 | 170.90 | 40.97 | |
| v1 | 502.43 | 268.13 | 90.72 | 1.56 |
| v1.5 | 394.88 | 341.16 | 82.54 | 2.00 |
| v2 | 375.90 | 358.38 | 85.79 | 2.10 |
| v3 | 205.89 | 653.10 | 81.72 | 3.83 |
| v4 | 176.86 | 760.28 | 43.47 | 4.46 |
| v4.1 | 183.23 | 733.86 | 70.28 | 4.30 |
| v4.2 | 176.13 | 763.46 | 40.09 | 4.48 |
| v5 | 175.52 | 766.10 | 44.06 | 4.49 |
| v6 | 163.84 | 819.26 | 33.83 | 4.81 |
笔者在 V100 上测试了 BLOCK_NUM 为 256, 512, 1024, 2048, 4096 的这几个情况, 在 BLOCK_NUM 为 2048 的时候得到了最优的结果, 相比于 kernel 5 又有了一定的性能提升.
英伟达官方 PPT 中给出的优化方法和实现到这里就结束了, 由于 PPT 时间较早, 优化也有一些过时, 不过仍然具有学习意义.
kernel 7: Pytorch BlockReduceSum()
Pytorch 提供了 reduce 求和函数 BlockReduceSum(), 其核心是通过两轮 warp 内的归约达到线程块内数据归约的效果.
相关文章和代码可以参考: Pytorch CUDA源码解析 - BlockReduceSum, pytorch_block_reduce.cu
// Sums `val` accross all threads in a warp.
//
// Assumptions:
// - The size of each block should be a multiple of `C10_WARP_SIZE`
template <typename T>
__inline__ __device__ T WarpReduceSum(T val) {
#pragma unrollfor (int offset = (C10_WARP_SIZE >> 1); offset > 0; offset >>= 1) {val += WARP_SHFL_DOWN(val, offset);}return val;
}struct Block1D {static __forceinline__ __device__ int Tid() { return threadIdx.x; }static __forceinline__ __device__ int Warps() {return blockDim.x / C10_WARP_SIZE;}
};struct Block2D {static __forceinline__ __device__ int Tid() {return threadIdx.x + threadIdx.y * blockDim.x;}static __forceinline__ __device__ int Warps() {return blockDim.x * blockDim.y / C10_WARP_SIZE;}
};// Sums `val` across all threads in a block.
//
// Warning: the return value is only valid for thread 0.
// Assumptions:
// - The size of each block should be a multiple of `C10_WARP_SIZE`
// - `shared` should be a pointer to shared memory with size of, at least,
// `sizeof(T) * number_of_warps`
template <typename T, typename B = Block1D>
__inline__ __device__ T BlockReduceSum(T val, T* shared) {const int tid = B::Tid();const int lid = tid % C10_WARP_SIZE;const int wid = tid / C10_WARP_SIZE;val = WarpReduceSum(val);__syncthreads(); // prevent races when BlockReduces are called in a row.if (lid == 0) {shared[wid] = val;}__syncthreads();val = (tid < B::Warps()) ? shared[lid] : T(0);if (wid == 0) {val = WarpReduceSum(val);}return val;
}
代码主要包括 BlockReduceSum() 和 WarpReduceSum() 两个函数, 分别执行线程块和 warp 内的归约求和操作.
其中, WarpReduceSum() 函数与前文 kernel 4.2 的 warpReduce() 函数是类似的, 采用了 warp 原语 __shfl_down_sync()(这里的宏 WARP_SHFL_DOWN) 来对 warp 内的数据归约, 并使用 for 循环配合 unroll 精简了代码. 最终 warp 内 lane_id 为 0 的线程得到归约的结果.
BlockReduceSum() 函数首先调用一次 WarpReduceSum(), 这样线程块中每个 warp 进行了归约; 然后 shared[wid] = val; lane_id 为 0 的线程将归约结果写入共享内存该 warp_id 对应的位置. 然后 0 号 warp 再进行一次 warp 内归约, 最后 threadIdx 为 0 的线程得到的即为该线程块内数据归约的结果.
代码中有以下几个地方值得说明:
- 两个
__syncthreads()线程块同步.
第二个__syncthreads()很好理解, 因为要确保前面每个 warp 对共享内存的写操作均完成, 后面 warp 0 才能继续归约.
关键是第一个__syncthreads(), 根据注释, 即"避免BlockReduceSum()函数连续调用时的竞态条件", 可以参考 Pytorch CUDA源码解析 - BlockReduceSum, pytorch_block_reduce.cu 文末用户"走歌人"的评论, 简单而言, 在连续两次调用BlockReduceSum()且使用相同的共享内存地址的情况下, 在没有第一个__syncthreads()时, 可能存在两个 warp, 一个 warp 已经运行到第 2 次调用BlockReduceSum()的shared[wid] = val;, 已经将第二次归约的结果写入共享内存了, 而第二个 warp 作为 0 号 warp 刚运行到第 1 次调用BlockReduceSum()的val = (tid < B::Warps()) ? shared[lid] : T(0);语句, 正准备从共享内存读取数据, 这时候很显然它拿到的是已经被覆盖掉的数据, 因此会造成错误. 解决这个方法便是第一个__syncthreads(). - 前文也提到过, 线程块的大小最大为 1024, 也就最多包含 32 个 warp, 因此每个 warp 归约后写入共享内存至多 32 个元素, 只需要在进行一次 warp 内归约即可得到最终结果. 而存在线程块大小小于 1024 的情况, 此时第一轮 warp 归约时不会写入共享内存, 因此在第二轮读取共享内存数据时要进行时要初始化
T(0). - 该函数是一个设备函数
__device__, 前提是归约的数据已经存到了线程的寄存器中, 因此如果与前面的 reduce kernel 保持一致, 可以进行如下封装:
template <unsigned blockSize, unsigned NUM_PER_THREAD>
__global__ void reduce_v7(float *g_idata,float *g_odata){__shared__ float sdata[WARP_SIZE];// each thread loads one element from global to shared memunsigned int tid = threadIdx.x;unsigned int i = blockIdx.x * (blockDim.x * NUM_PER_THREAD) + threadIdx.x;float sum = 0;#pragma unrollfor(int iter = 0; iter < NUM_PER_THREAD; ++iter){sum += g_idata[i + iter * blockSize];}__syncthreads();sum = BlockReduceSum(sum, sdata);if (tid == 0) g_odata[blockIdx.x] = sum;
}
如果想要直接调用, 可以展开如下(此时可以省略 BlockReduceSum() 的第一个 __syncthreads()):
template <unsigned int blockSize>
__device__ __forceinline__ float warpReduceSum(float sum) {if (blockSize >= 32)sum += __shfl_down_sync(0xffffffff, sum, 16); // 0-16, 1-17, 2-18, etc.if (blockSize >= 16)sum += __shfl_down_sync(0xffffffff, sum, 8); // 0-8, 1-9, 2-10, etc.if (blockSize >= 8)sum += __shfl_down_sync(0xffffffff, sum, 4); // 0-4, 1-5, 2-6, etc.if (blockSize >= 4)sum +=__shfl_down_sync(0xffffffff, sum, 2); // 0-2, 1-3, 4-6, 5-7, etc.if (blockSize >= 2)sum += __shfl_down_sync(0xffffffff, sum, 1); // 0-1, 2-3, 4-5, etc.return sum;
}template <unsigned int blockSize, int NUM_PER_THREAD>
__global__ void reduce7(float *g_idata, float *g_odata, unsigned int n) {// perform first level of reduction,// reading from global memory, writing to shared memoryunsigned int tid = threadIdx.x;unsigned int i = blockIdx.x * (blockSize * NUM_PER_THREAD) + threadIdx.x;float sum = 0;#pragma unrollfor (int iter = 0; iter < NUM_PER_THREAD; iter++) {sum += g_idata[i + iter * blockSize];}// Shared mem for partial sums (one per warp in the block)__shared__ float warpLevelSums[WARP_SIZE];const int laneId = threadIdx.x % WARP_SIZE;const int warpId = threadIdx.x / WARP_SIZE;const unsigned num_warps = blockSize / WARP_SIZE;sum = warpReduceSum<blockSize>(sum);if (laneId == 0) warpLevelSums[warpId] = sum;__syncthreads();// read from shared memory only if that warp existedsum = (tid < num_warps) ? warpLevelSums[laneId] : 0;// Final reduce using first warpif (warpId == 0) sum = warpReduceSum<num_warps>(sum);// write result for this block to global memif (tid == 0) g_odata[blockIdx.x] = sum;
}
该 kernel 的优点是很明显的: 线程块同步 __syncthreads() 可以减少到 1 个, 这样会节省很大一部分同步开销; 同时, warp 内归约通过使用 warp 原语实现了寄存器变量之间的归约, 无需共享内存, 而共享内存至多使用 32 个来记录第一轮 warp 内归约的结果, 使得共享内存的读写开销也大幅下降, 因此 kernel 7 应该具有很高的性能.
| kernel | 用时(us) | 内存带宽(GB/s) | 带宽利用率(%) | 加速比 |
|---|---|---|---|---|
| v0 | 788.29 | 170.90 | 40.97 | |
| v1 | 502.43 | 268.13 | 90.72 | 1.56 |
| v1.5 | 394.88 | 341.16 | 82.54 | 2.00 |
| v2 | 375.90 | 358.38 | 85.79 | 2.10 |
| v3 | 205.89 | 653.10 | 81.72 | 3.83 |
| v4 | 176.86 | 760.28 | 43.47 | 4.46 |
| v4.1 | 183.23 | 733.86 | 70.28 | 4.30 |
| v4.2 | 176.13 | 763.46 | 40.09 | 4.48 |
| v5 | 175.52 | 766.10 | 44.06 | 4.49 |
| v6 | 163.84 | 819.26 | 33.83 | 4.81 |
| v7 | 162.62 | 825.41 | 33.73 | 4.85 |
可以看到 kernel 7 相比与 kernel 6 有了一点性能提升, 但确实不明显了, 也侧面证明之前的优化已经很充分了.
Kernel 8: Pytorch BlockReduceSum() + 向量化访存 + grid_size 设置
在 【BBuf的CUDA笔记】三,reduce优化入门学习笔记 - 知乎 文章的最后, 作者给出了最后一个 reduce 的实现, 结合了 Oneflow 的向量化访问数据结构 Packed 以及设置 grid_size 的函数 GetNumBlocks().
笔者这里觉得比较重要的是这里的向量化访存. 之前的 kernel 至多考虑了尽可能的让每个线程多从全局内存读取几个数据并归约, 但粒度都是 1 个元素(即 32 字节), 容易想到要最大化利用全局内存的带宽, 便应该使用向量化访存, 这样一次性可以读取 4 个元素.
constexpr int kBlockSize = 256;
constexpr int kNumWaves = 1;int64_t GetNumBlocks(int64_t n) {int dev;{cudaError_t err = cudaGetDevice(&dev);if (err != cudaSuccess) {return err;}}int sm_count;{cudaError_t err = cudaDeviceGetAttribute(&sm_count, cudaDevAttrMultiProcessorCount, dev);if (err != cudaSuccess) { return err; }}int tpm;{cudaError_t err = cudaDeviceGetAttribute(&tpm, cudaDevAttrMaxThreadsPerMultiProcessor, dev);if (err != cudaSuccess) { return err; }}int64_t num_blocks = std::max<int64_t>(1, std::min<int64_t>((n + kBlockSize - 1) / kBlockSize,sm_count * tpm / kBlockSize * kNumWaves));return num_blocks;
}template <typename T, int pack_size>
struct alignas(sizeof(T) * pack_size) Packed {__device__ Packed(T val) {#pragma unrollfor (int i = 0; i < pack_size; i++) {elem[i] = val;}}__device__ Packed() {// do nothing}union {T elem[pack_size];};__device__ void operator+=(Packed<T, pack_size> packA) {#pragma unrollfor (int i = 0; i < pack_size; i++) {elem[i] += packA.elem[i];}}
};template <typename T, int pack_size>
__device__ T PackReduce(const Packed<T, pack_size>& pack) {T res = 0.0;#pragma unrollfor (int i = 0; i < pack_size; i++) {res += pack.elem[i];}return res;
}template <typename T>
__device__ T warpReduceSum(T val) {#pragma unrollfor (int lane_mask = 16; lane_mask > 0; lane_mask /= 2) {val += __shfl_down_sync(0xffffffff, val, lane_mask);}return val;
}__global__ void reduce_v8(float *g_idata, float *g_odata, unsigned int n) {// each thread loads one element from global to shared memunsigned int i = blockDim.x * blockIdx.x + threadIdx.x;Packed<float, PackSize> sum_pack(0.0);Packed<float, PackSize> load_pack(0.0);const auto *pack_ptr =reinterpret_cast<const Packed<float, PackSize> *>(g_idata);for (int32_t linear_index = i; linear_index < n / PackSize;linear_index += blockDim.x * gridDim.x) {load_pack = pack_ptr[linear_index];sum_pack += load_pack;}float sum = PackReduce<float, PackSize>(sum_pack);// Shared mem for partial sums (one per warp in the block)static __shared__ float warpLevelSums[kWarpSize];const int laneId = threadIdx.x % kWarpSize;const int warpId = threadIdx.x / kWarpSize;sum = warpReduceSum<float>(sum);__syncthreads();if (laneId == 0) warpLevelSums[warpId] = sum;__syncthreads();// read from shared memory only if that warp existedsum = (threadIdx.x < BLOCK_SIZE / kWarpSize) ? warpLevelSums[laneId] : 0;// Final reduce using first warpif (warpId == 0) sum = warpReduceSum<float>(sum);// write result for this block to global memif (threadIdx.x == 0) g_odata[blockIdx.x] = sum;
}
| kernel | 用时(us) | 内存带宽(GB/s) | 带宽利用率(%) | 加速比 |
|---|---|---|---|---|
| v0 | 788.29 | 170.90 | 40.97 | |
| v1 | 502.43 | 268.13 | 90.72 | 1.56 |
| v1.5 | 394.88 | 341.16 | 82.54 | 2.00 |
| v2 | 375.90 | 358.38 | 85.79 | 2.10 |
| v3 | 205.89 | 653.10 | 81.72 | 3.83 |
| v4 | 176.86 | 760.28 | 43.47 | 4.46 |
| v4.1 | 183.23 | 733.86 | 70.28 | 4.30 |
| v4.2 | 176.13 | 763.46 | 40.09 | 4.48 |
| v5 | 175.52 | 766.10 | 44.06 | 4.49 |
| v6 | 163.84 | 819.26 | 33.83 | 4.81 |
| v7 | 162.62 | 825.41 | 33.73 | 4.85 |
| v8 | 162.21 | 827.45 | 34.30 | 4.86 |
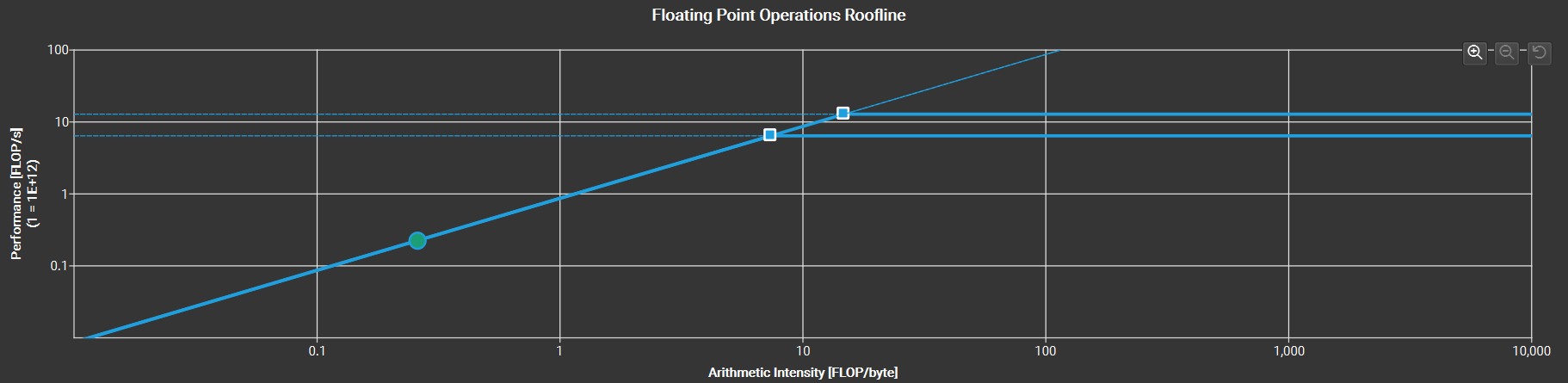
可以看到, 到此性能的提升就已经微乎其微了, 基本上和 kernel 6 和 7 的性能相近. 如下面 kernel 8 的 roofline 图所示, 由于 reduce 算子本身计算强度较低, 可以说此时已经优化到了该计算强度的性能上限了.
参考资料
- 【BBuf的CUDA笔记】三,reduce优化入门学习笔记 - 知乎
- 深入浅出GPU优化系列:reduce优化 - 知乎
- Optimizing Parallel Reduction in CUDA
- Using CUDA Warp-Level Primitives | NVIDIA Technical Blog