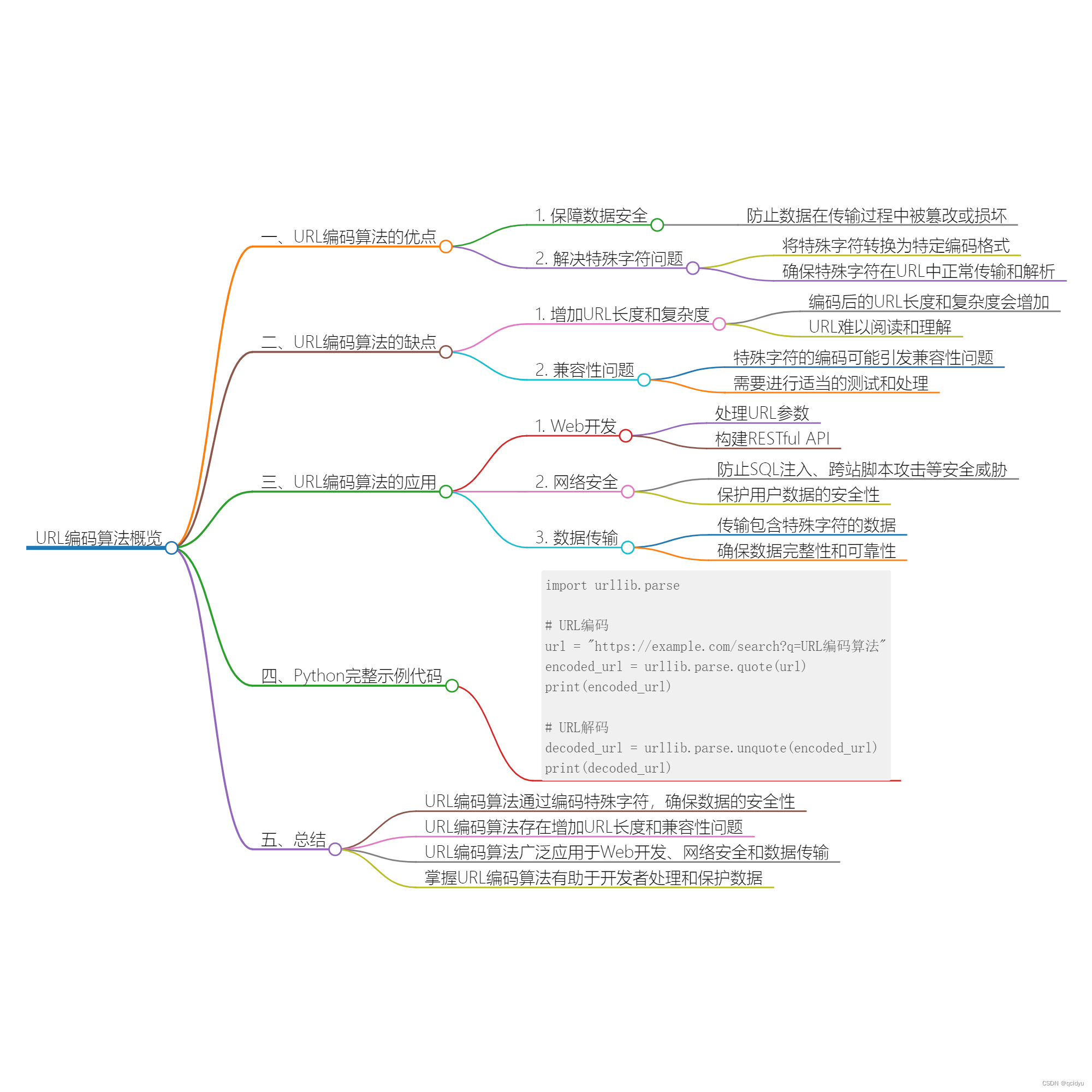
NLP入门
课程链接:https://www.bilibili.com/video/BV17K4y1W7yb/?p=1&vd_source=3f265bbf5a1f54aab2155d9cc1250219
参考文档链接1:NLP知识点:Tokenizer分词器 - 掘金 (juejin.cn)
一、分词
分词是什么?
每个字母都有对应的ASCII编码,可以用编码代替一个单词中的不同字母,即表示一个单词

但是对于一个句子,取用编码表示里面的每个单词,而不是对单词里面的字母进行编码
如I love my dog,用001、002、003、004表示,这时候新来一个句子I love my cat,cat就可以用005编码代表,再用编码看一下,分别是[1 2 3 4]和[1 2 3 5],可以看出这两个句子是有一定的相似性的,都是表示对某物的喜爱

Tokenizer了解
计算机无论如何都无法理解人类语言,它只会计算,通过计算它让你感觉它理解了人类语言
- 举个例子:单=1,双=2,计算机面临“单”和“双”的时候,它所理解的就是2倍关系
- 再举一个例子:赞美=1,诋毁=0, 当计算机遇到0.5的时候,它知道这是“毁誉参半”
- 再再举一个例子:女王={1,1},女人={1,0},国王={0,1},它能明白“女人”+“国王”=“女王”
面临文字的时候,都是要通过数字去理解的,如何把文本转成数字,就是NLP中最基础的一步,TensorFlow框架中,提供了一个很好用的类Tokenizer, 它就是为此而生的。
Tokenizer实例常用属性和方法了解
tokenizer.word_index给所有单词上了户口,每一个单词都指定了一个身份证编号tokenizer.document_count记录了它处理过几段文本okenizer.index_word和word_index相对,只是数字在前tokenizer.word_docs则统计的是每一个词出现的次数
代码示例
用代码实现上述过程的形式,就是叫做分词,实现用单词用数字来进行表示
假设我们有一批文本,我们想投到分词器中,让他变为数字,既可以按照如下流程实现
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
# 字符串数组表示这些句子
sentences = ["I love my dog","I love my cat","You love my dog!"
]# 创建一个Tokenizer实例,num_words表示要保留的最大单词数,即要保留语料库中出现最频繁的100个单词
tokenizer = Tokenizer(num_words=100)
# 分词器自动实现查看所有文本,并将文本与对应数字进行匹配
tokenizer.fit_on_texts(sentences)
# 通过分词器的word_index属性可以获得完整的单词列表
word_index = tokenizer.word_index
print(word_index)
print(tokenizer.document_count)
print(tokenizer.index_word)
print(tokenizer.word_docs)
输出如下
{'love': 1, 'my': 2, 'i': 3, 'dog': 4, 'cat': 5, 'you': 6}
3
{1: 'love', 2: 'my', 3: 'i', 4: 'dog', 5: 'cat', 6: 'you'}
defaultdict(<class 'int'>, {'love': 3, 'dog': 2, 'i': 2, 'my': 3, 'cat': 1, 'you': 1})
二、序列:将文本转换为数据
texts_to_sequences方法了解
为句子创建数字序列,然后用工具对其进行处理,为训练神经网络做准备
texts_to_sequences方法来将文本序列化为数字,它创建了代表每个句子的token序列

PS:处理是忽略英文字母大小写和英文标点符号的
文本为何能序列化?
文本之所以能被序列化,其基础就是每一个词汇都有一个编号
| 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| i | love | cat | dog | you | too |
未见过的单词如何处理?
当我们遇到没有见过的词汇时,比如 I do not love cat,这时候该怎么办?
举个例子,你做了一个电影情感分析,用20000条电影的好评和差评训练了一个神经网络模型。当你想试验效果的时候,这时候你随便输入一条评论文本,这条新评论文本里面的词汇很有可能之前没出现过,这时候也是要能序列化并给出预测结果的。
先来看会发生什么?
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizersentences = ["I love my dog","I love my cat","You love my dog!","Do you think my dog is amazing?"
]tokenizer = Tokenizer(num_words=100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_indextest_data=["i really love my dog","my dog loves my manatee"
]
test_seq = tokenizer.texts_to_sequences(test_data)print(word_index)
print(test_seq)
# {'my': 1, 'love': 2, 'dog': 3, 'i': 4, 'you': 5, 'cat': 6, 'do': 7, 'think': 8, 'is': 9, 'amazing': 10}
# [[4, 2, 1, 3], [1, 3, 1]]
从结果看,它给忽略了,只因为那几个单词没有备案,语料库中没有它们

如果我们并不想忽略它,只需要构建Tokenizer的时候传入一个参数oov_token='<OOV>'
OOV指的是在自然语言文本处理的时候,通常会有一个字词库,它来源于训练数据集,这个词库是有限的。当以后有新的数据集时,这个数据集中有一些词并不在你现有的vocabulary里,我们就说这些词汇是out-of-vocabulary,简称OOV。
只要是通过Tokenizer(oov_token='<OOV>')方式构建的,分词器会给预留一个编号,专门用于标记超纲的词汇
再来看看会发生什么?
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizersentences = ["I love my dog","I love my cat","You love my dog!","Do you think my dog is amazing?"
]tokenizer = Tokenizer(num_words=100, oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_indextest_data = ["i really love my dog","my dog loves my manatee"
]
test_seq = tokenizer.texts_to_sequences(test_data)print(word_index)
print(test_seq)
# {'<OOV>': 1, 'my': 2, 'love': 3, 'dog': 4, 'i': 5, 'you': 6, 'cat': 7, 'do': 8, 'think': 9, 'is': 10, 'amazing': 11}
# [[5, 1, 3, 2, 4], [2, 4, 1, 2, 1]]
从结果可见,给超纲词一个编号,它也会输出

序列填充 pad_sequences
训练神经网络时候,如何处理不同长度的句子呢?对于图像而言,通常尺寸是相同的,那么对于文本如何?
进阶的解决方案是借助不规则张量(Ragged Tensor),但是难度过大,另种解决方案较为简单,对于文本中也有像图像padding一样的东西
你看下面这张图,是两捆铅笔,你觉得不管是收纳还是运输,哪一个更方便处理呢?

从生活的常识来看,肯定是B序列更方便处理,因为它有统一的长度,可以不用考虑差异性,50个或者50000个,只是单纯的倍数关系。计算机也和人一样,[[1, 2, 3], [1, 2, 4], [1, 2, 5, 6]]这些数字也是有长有短的,它也希望你能统一成一个长度。
pad_sequences方法就是专门干这个事情,将序列数据传进去后,它会以序列中最长的那一条为标准长度,其他短的数据会在前面补0,这样就让序列长度统一了。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequencessentences = ["I love my dog","I love my cat","You love my dog!","Do you think my dog is amazing?"
]tokenizer = Tokenizer(num_words=100, oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_indexsequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences)print(word_index)
print(sequences)
print(padded)
输出
{'<OOV>': 1, 'my': 2, 'love': 3, 'dog': 4, 'i': 5, 'you': 6, 'cat': 7, 'do': 8, 'think': 9, 'is': 10, 'amazing': 11}
[[5, 3, 2, 4], [5, 3, 2, 7], [6, 3, 2, 4], [8, 6, 9, 2, 4, 10, 11]]
[[ 0 0 0 5 3 2 4][ 0 0 0 5 3 2 7][ 0 0 0 6 3 2 4][ 8 6 9 2 4 10 11]]
如果想在句子后而不是句子前补零,只需要将padding参数设置为post
padded = pad_sequences(sequences, padding="post")
如果不希望填充句子的长度根最大长度一致,也可以进行手动设置maxlen属性设置最大单词个数,超过则通过truncating设置为post或者pre,分别代表阶段结尾或开头处的单词
padded = pad_sequences(sequences, padding="post", truncating="post", maxlen=5)
三、打造识别文本情感的模型
数据集介绍
数据集中标题已经被分为[sarcastic]和[no sarcastic]两类,在此基础上训练一个文本分类器,进而判断一段新文本是否具有讽刺意味
地址:https://www.kaggle.com/datasets/rmisra/news-headlines-dataset-for-sarcasm-detection

1和0,分别代表着是或不是讽刺的;有对应文章标题headline和文本内容aeticle_link

数据格式以json格式进行存储

功能实现
数据集加载
import jsondatastore = []
with open("Sarcasm_Headlines_Dataset.json", 'r') as f:for line in f:item = json.loads(line)datastore.append(item)
sentences = []
labels = []
urls = []
for item in datastore:sentences.append(item["headline"])labels.append(item["is_sarcastic"])urls.append((item['article_link']))
# print(sentences)
# print(labels)
# print(urls)
可以看出一共26709个序列,每个序列有40个token
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequencestokenizer = Tokenizer(oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_indexsequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences, padding="post")print(padded[0])
print(padded.shape)
# [ 308 15115 679 3337 2298 48 382 2576 15116 6 2577 8434
# 0 0 0 0 0 0 0 0 0 0 0 0
# 0 0 0 0 0 0 0 0 0 0 0 0
# 0 0 0 0]
# (26709, 40)
数据集划分、填充、处理
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequencesvocab_size = 10000 # 词汇表的大小
embedding_dim = 16 # 每个单词在嵌入空间中的表示维度
max_length = 100 # 填充后的句子长度,表示模型接受的输入序列的最大长度
padding_type = "post" # 填充类型,表示在填充序列时在句子的哪一端进行填充
trunc_type = "post" # 截断类型,表示在截断序列时在句子的哪一端进行截断
oov_tok = "<OOV>"
training_size = 20000training_sentences = sentences[0:training_size]
test_sentences = sentences[training_size:]
training_labels = labels[0:training_size]
test_labels = labels[training_size:]# 分词
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
# 将训练集句子转换成数字序列,并进行填充
training_sequences = tokenizer.texts_to_sequences(training_sentences)
training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
# 将测试集句子转换成数字序列,并进行填充
test_sequences = tokenizer.texts_to_sequences(test_sentences)
test_padded = pad_sequences(test_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
# 转换
import numpy as np
training_padded = np.array(training_padded)
training_labels = np.array(training_labels)
test_padded = np.array(test_padded)
test_labels = np.array(test_labels)
模型网络定义和训练
model = tf.keras.Sequential([tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),tf.keras.layers.GlobalAveragePooling1D(),tf.keras.layers.Dense(24, activation='relu'),tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()
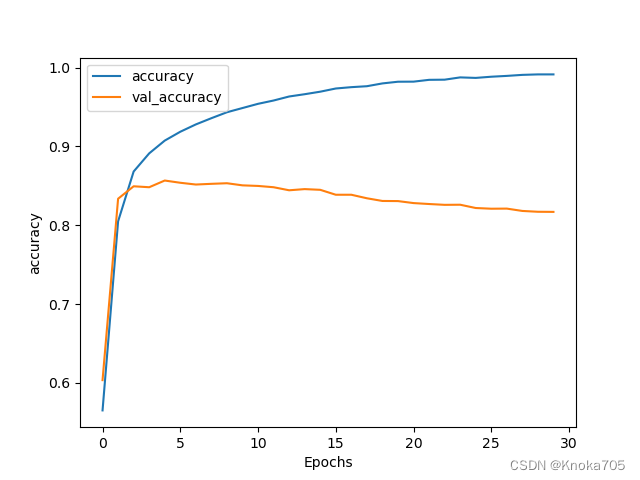
num_epochs = 30
history = model.fit(training_padded, training_labels, epochs=num_epochs, validation_data=(test_padded, test_labels), verbose=2)
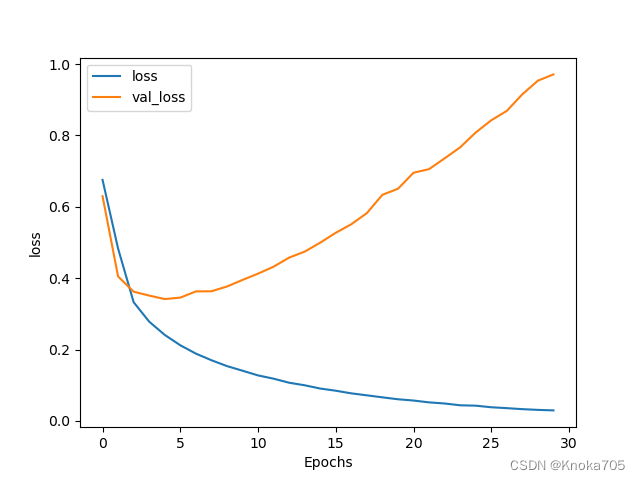
绘图评估
import matplotlib.pyplot as pltdef plot_graphs(history, string):plt.plot(history.history[string])plt.plot(history.history['val_' + string])plt.xlabel("Epochs")plt.ylabel(string)plt.legend([string, 'val_' + string])plt.show()plot_graphs(history, "accuracy")
plot_graphs(history, "loss")
测试
sentence = ["granny starting to fear spiders in the garden might be real","game of thrones season finale showing this sunday night"]
sequences = tokenizer.texts_to_sequences(sentence)
padded = pad_sequences(sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
print(model.predict(padded))
#[[9.4739074e-01] [5.3165233e-05]]
四、循环神经网络
此类型神经网络在学习时候,会将数据序列考虑在内,文本生成本质上就是要预测下一个单词
非序列数据是如何转换为序列数据?

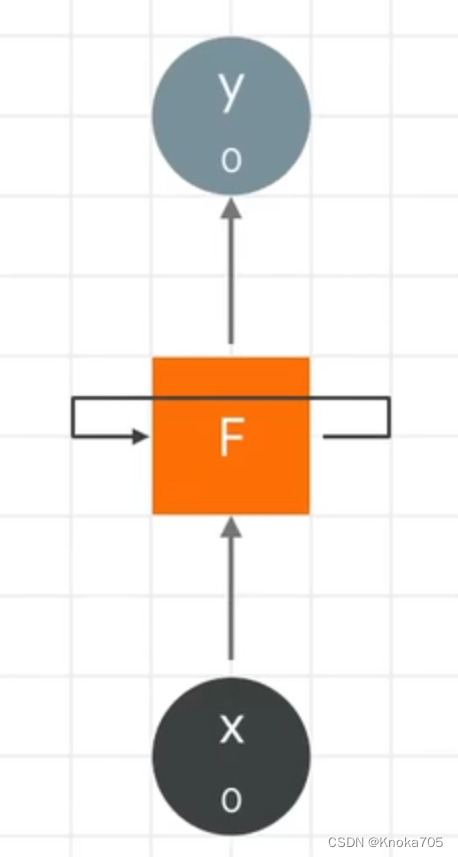
一个数值再整个数列的生命中反复出现,这就是循环神经网络的原理,通常一个循环神经网络神经元如下,神经元得到一个输入值,产生一个输出值,除输出外他还会参数一个前馈数值,并传递给下一个神经元

大量神经元加在一起就形成了这个网络,从左到右,将X0输入神经元,会计算出一个结果Y0,同时还会输出一个数值,传递给下一个神经元,然后得到X1以及前一个神经元的前馈数值并计算出Y1,他的输出和X2结合,得到Y2和一个前馈值,在传递给下一个神经元,以此类推,序列被编码到输出中
这种数据的递归,就被称为循环神经网络,随着计算的加深,最先的输入影像会逐渐减小,比如1号位置的数字对于100号位置的数字影响很小,影响虽然是存在的,但是微乎其微,这就是循环神经网络的局限性
关键描述词约接近预测文本,预测就越精确,如下面的词的预测就是,如果只根据最近的单词进行预测,就会漏掉这一线索,结果也就不精确,这部分实现的关键是超越循环神经网络的超短期记忆形成了长短期记忆,这种适用于循环神经网络的算法就叫长短期记忆,简称LSTM

五、长短期记忆网络(LSTM)
句子前文单词可以决定下文的含义和语义,要实现这个目标,就要用到LSTM
如果是下面这一句话,我们是很容易预测到下面的这个单词是sky,因为句子中有很多处符合这个单词的语境,尤其是单词blue

但如果是这样一句话,正确答案就是Gaelic而不是lrish,关键词在lreland,因为这种情况下国家决定语言,但是这个单词在句中的位置非常靠前,所以在使用循环神经网络时候可能很难实现正确的预测
因为循环神经网络如果传输距离很长的话,它上下文之间的联系可能会被大大稀释,这样一来就没办法弄清楚前文单词如何决定整体句意了

LSTM就可以解决这个问题,它引入了一种叫做Cell state的概念,可以跨越多个和时间段保持语境,从而将句子开头的句意带入下文
可以学习到当我们谈论语言的时候,Ireland说的是Gaelic,而且它可以是双向的,句子后面的词也可以为前面的词提供语境

代码说明:首先定义一个LSTM层,这里需要一个参数表示其中隐藏节点的数量,也表示LSTM输入门的维度,如果希望是双向的,则可以使用Bidirectional包裹这个层,实现同时向前和向后巡视句子文本,学习每个句子的最佳参数然后将其合并
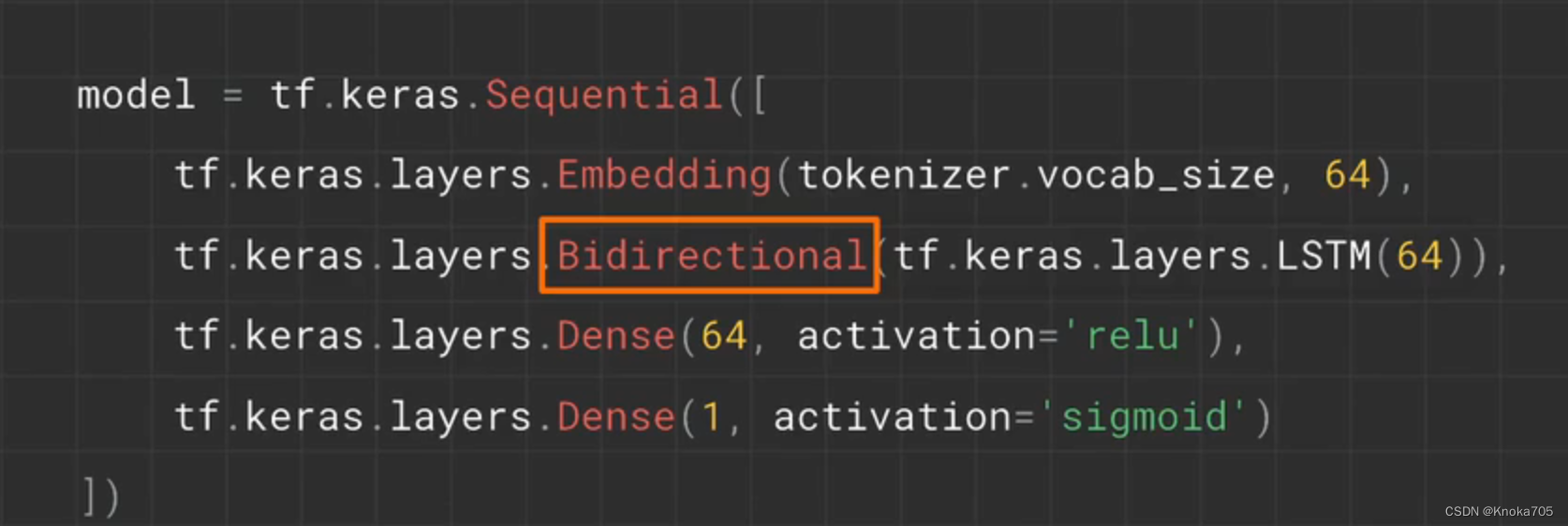
当然LSTM层也可以进行堆积,但是要确保所有逐层传递的图层都设置return_sequences=True

六、打造一个会写诗的AI
使用传统爱尔兰歌曲的单词进行训练,得到一个可以写诗的模型,爱尔兰歌曲生成器 Colab → https://goo.gle/3aSTLGx
相关库导入
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
import numpy as np
!wget --no-check-certificate \https://storage.googleapis.com/learning-datasets/irish-lyrics-eof.txt \-O /tmp/irish-lyrics-eof.txt
数据集生成
可以将一行文本形成多行文本列表,如知道A后面就是B,知道A、B后面就是C
tokenizer = Tokenizer()
data = open('/tmp/irish-lyrics-eof.txt').read()
corpus = data.lower().split("\n")
tokenizer.fit_on_texts(corpus)
total_words = len(tokenizer.word_index) + 1
print(tokenizer.word_index)
print(total_words)

进行填充等操作,并分割处数据和标签
input_sequences = []
for line in corpus:token_list = tokenizer.texts_to_sequences([line])[0]for i in range(1, len(token_list)):n_gram_sequence = token_list[:i+1]input_sequences.append(n_gram_sequence)# pad sequences
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))# create predictors and label
xs, labels = input_sequences[:,:-1],input_sequences[:,-1]ys = tf.keras.utils.to_categorical(labels, num_classes=total_words)


模型训练
这部分用的lstm,云端是正常能跑通的,但不知本地为何一直报错,可能是我的版本问题
model = Sequential()
model.add(Embedding(total_words, 100, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(150)))
model.add(Dense(total_words, activation='softmax'))
adam = Adam(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
#earlystop = EarlyStopping(monitor='val_loss', min_delta=0, patience=5, verbose=0, mode='auto')
history = model.fit(xs, ys, epochs=100, verbose=1)
#print model.summary()
print(model)
绘图评估
import matplotlib.pyplot as pltdef plot_graphs(history, string):plt.plot(history.history[string])plt.xlabel("Epochs")plt.ylabel(string)plt.show()
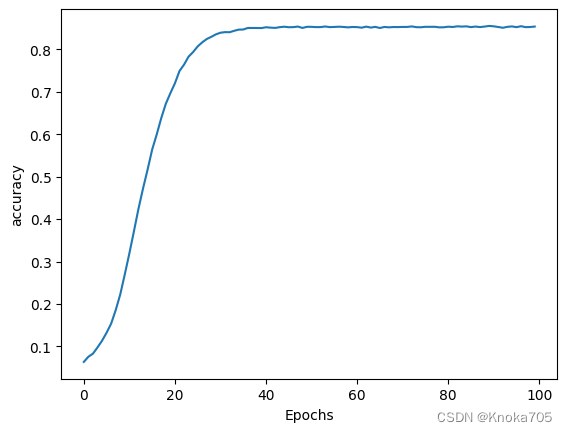
调用测试
seed_text = "I've got a bad feeling about this"
next_words = 100for _ in range(next_words):token_list = tokenizer.texts_to_sequences([seed_text])[0]token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')predicted = np.argmax(model.predict(token_list), axis=-1)output_word = ""for word, index in tokenizer.word_index.items():if index == predicted:output_word = wordbreakseed_text += " " + output_word
print(seed_text)
'''
I've got a bad feeling about this town my father say you is there i journey your eyes more did sends him fairer than only jenny to hat eight platform tiny name they wind diamond wind sod sod sod change struggle buy beating tie round wind and doesnt wind mythology bride and tree round the tiny dungannon politicians havent james lassies up sheilings dungannon rogue rogue they could not bound be a hobble in the blue town down down the rocky thorn to warm down they ground and bride as tis the wind shines wandered of a call spancil hill li li fairer friend they turning grey
'''