| 文献阅读笔记 | ||
| 简介 | 题目 | End-to-end people detection in crowded scenes |
| 作者 | Russell Stewart, Mykhaylo Andriluka | |
| 原文链接 | https://arxiv.org/pdf/1506.04878.pdf | |
| 关键词 | Null | |
| 研究问题 | 当前的人员检测器要么以滑动窗口的方式扫描图像,要么对一组离散的提议进行分类。 这项任务是具有挑战性的,因为它既需要将物体从背景中区分开来,又需要正确估计不同物体的数量和它们的位置。 要避免对同一对象的多次检测。 对象实例重叠时根据边界框的属性进行推理往往会得出错误的结果。 拥挤场景中,多个人常常近距离出现,使得区分附近的个体变得尤为困难。 | |
| 研究方法 | 提出了一种基于图像解码的人员检测模型。要求以一幅图像作为输入,从而能够直接输出一组不同的检测假设。由于是联合生成预测,因此不需要非极大值抑制等常见的后处理步骤。 本文贡献一个使用一个新的损失函数来端到端地训练模型,该损失函数对检测集进行操作。 另一个技术贡献是表明可以成功地利用LSTM单元链将图像内容解码为可变长度的相干实值输出。 图像解码:首先使用来自谷歌公司的表达性图像特征。然后使用该图像的中间表示使用lstm进行训练得到一组预测对象。 | |
| 研究结论 | 该方法在拥挤场景中检测人群这一具有挑战性的任务上非常有效。能够生成任意距离的预测。 | |
| 额外知识 | Bounding box regression:Region Proposal经过fine-tuning跟Ground Truth更加接近的方法 人脸检测中的bounding box regression详解-CSDN博客 | |
(论文阅读14/100)End-to-end people detection in crowded scenes
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/180192.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

python加上ffmpeg实现音频分割
前言: 这是一个系列的文章,主要是使用python加上ffmpeg来对音视频文件进行处理,包括音频播放、音频格式转换、音频文件分割、视频播放等。
系列文章链接: 链接1: python使用ffmpeg来制作音频格式转换工具(优化版) 链接2:<Python>PyQt5+ffmpeg,简单视频播放器的编写(…
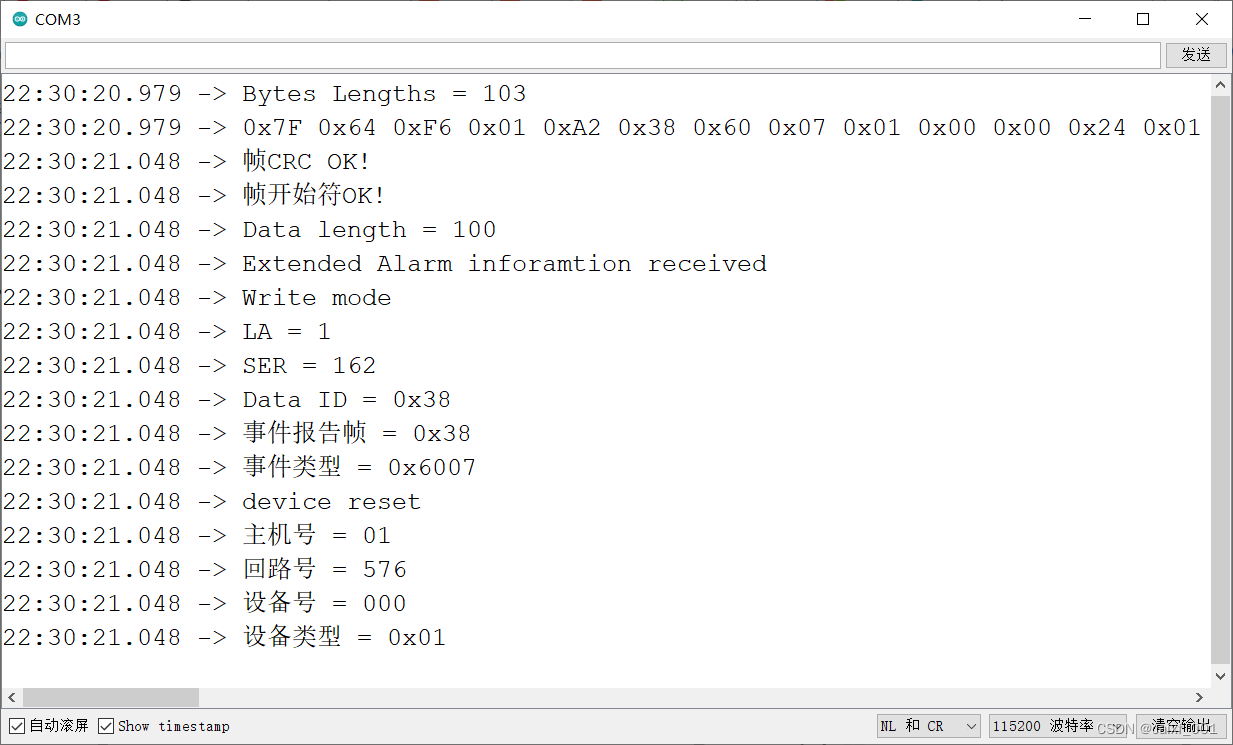
Arduino设置SoftwareSerial缓冲区大小
SoftwareSerial的缓冲区大小设置 概述修改缓冲区的大小实验 概述
新的Arduino的ESP8266软串口的缓冲区原来老的库中有宏定义可以用来修改接收和发送缓冲区的大小。在现在新的库中已经没有这个设置了,那怎么才能修改缓冲区的大小哪?
修改缓冲区的大小
…
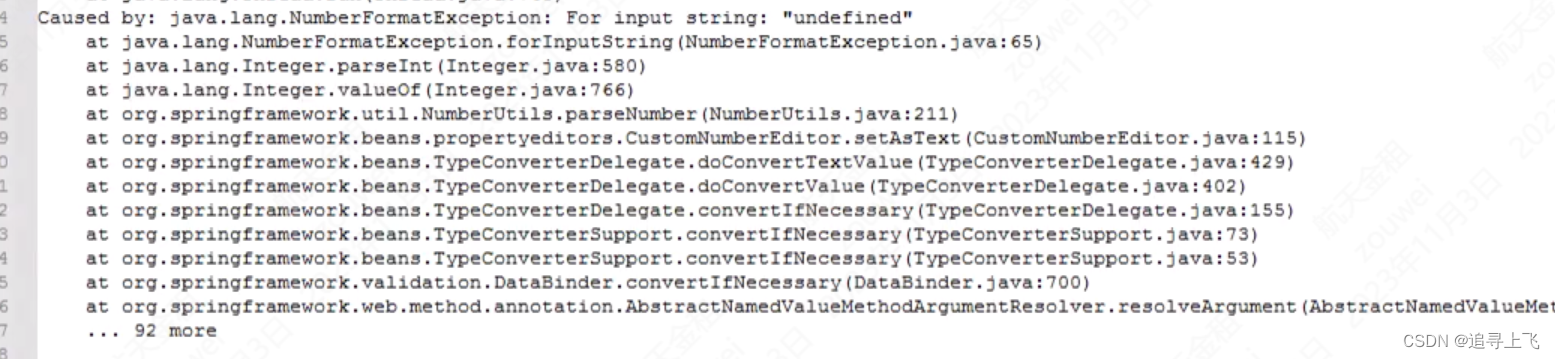
【借力打力】记一次由于堆栈信息不详细的错误排查方法,利用访问日志进行定位问题
【借力打力】记一次由于堆栈信息不详细的错误排查方法,利用访问日志进行定位问题 1,背景2,排查步骤2.1 调用方问题2.2 Nginx手段2.3 运维工具辅助2.4 嵌入tomcat日志记录 3,结果 1,背景
异常信息每隔50分钟显示一次&a…
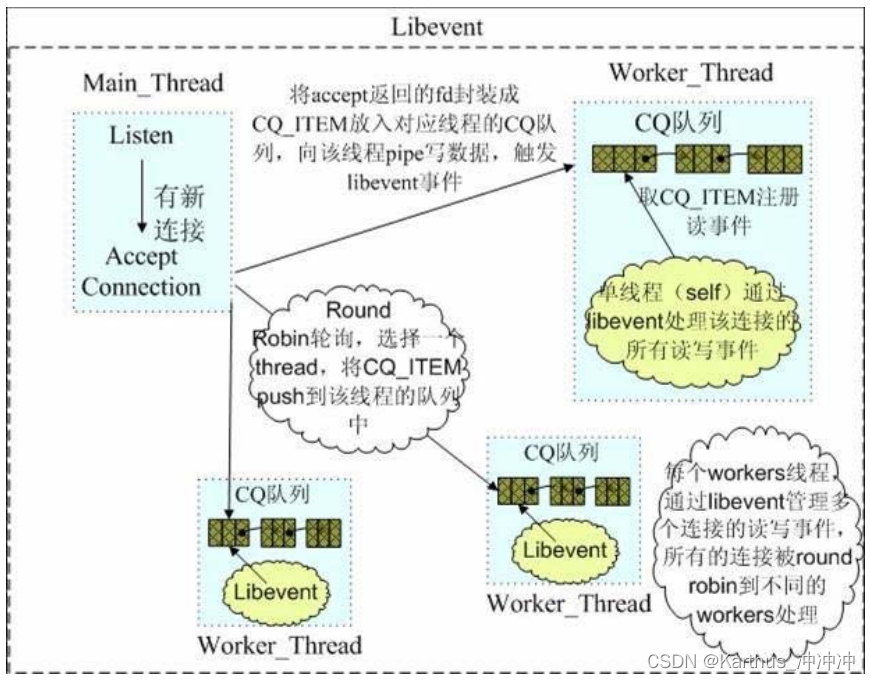
Libevent网络库原理及使用方法
目录 1. Libevent简介2. Libevent事件处理流程3. Libevent常用API接口3.1 地基——event_base3.2 事件——event3.3 循环等待事件3.4 自带 buffer 的事件——bufferevent3.5 链接监听器——evconnlistener3.6 基于event的服务器程序3.7 基于 bufferevent 的服务器和客户端实现 …
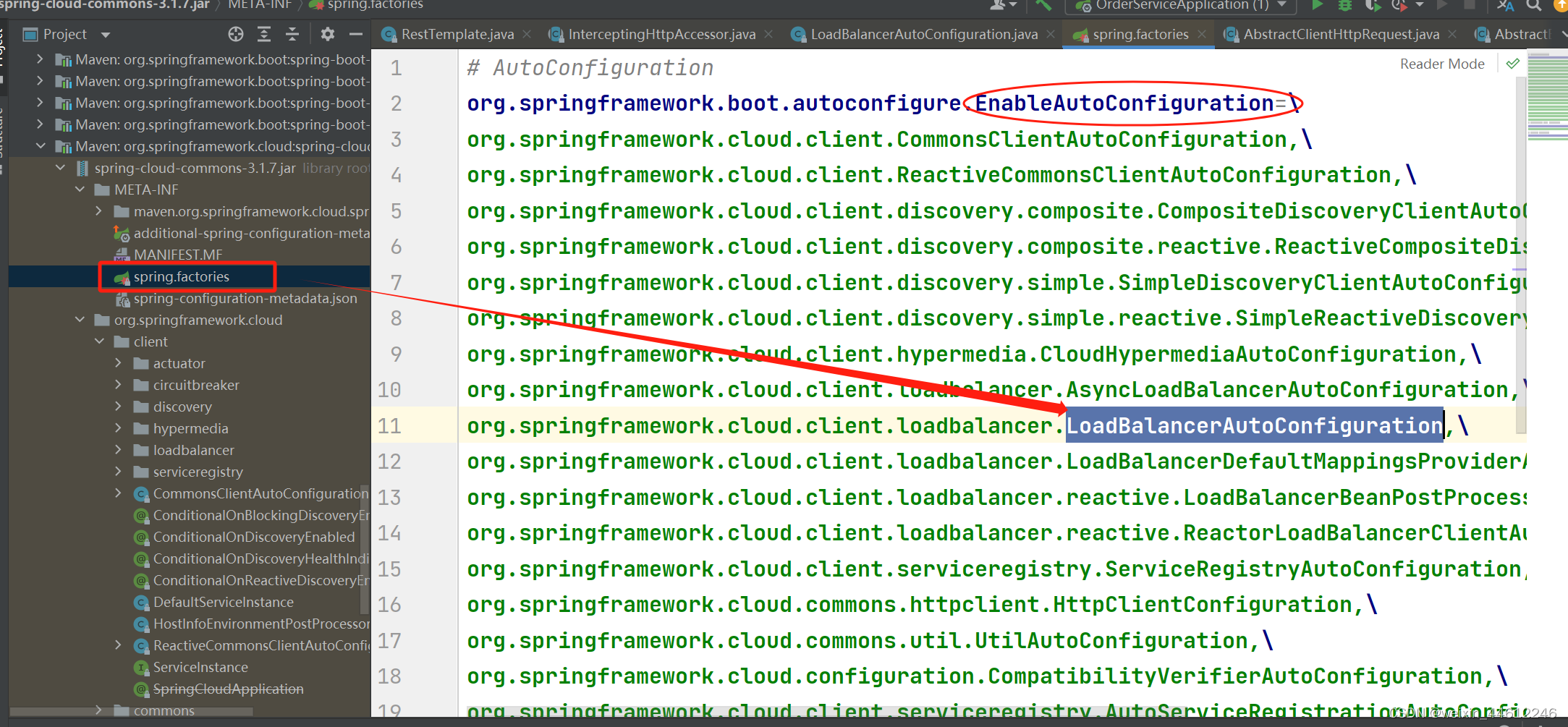
Spring cloud负载均衡 @LoadBalanced注解原理
接上一篇文章,案例代码也在上一篇文章的基础上。
在上一篇文章的案例中,我们创建了作为Eureka server的Eureka注册中心服务、作为Eureka client的userservice、orderservice。
orderservice引入RestTemplate,加入了LoadBalanced注解&#x…

大数据(十):数据可视化(二)
专栏介绍
结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来!
全部文章请访问专栏:《Python全栈教…

Leetcode实战
我们今天来利用这段时间的学习实操下我们的oj题。 int removeElement(int* nums, int numsSize, int val){int dst0;int src0;while(src<numsSize){if(nums[src]!val){nums[dst]nums[src];}elsesrc;}return dst;}我们这里用用两个下标,src来移动,如果…

linux的shell script判断用户输入的字符串,判断主机端口开通情况
判断输入的字符串是否是hello
图一运行报错
检查发下,elif 判断里面少个引号,哎,现在小白到了,一看就会,一写就错的时候了,好像现在案例比较简单,行数较少。 案例二
if 结合test 判断主机端…

小程序如何设置用户同意服务协议并上传头像和昵称
为了保护用户权益和提供更好的用户体验,设置一些必填项和必读协议是非常必要的。首先,用户必须阅读服务协议。服务协议是明确规定用户和商家之间权益和义务的文件。通过要求用户在下单前必须同意协议,可以确保用户在使用服务之前了解并同意相…
第11章_数据处理之增删改
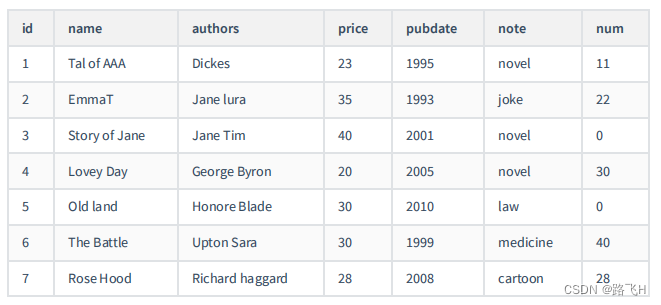
文章目录 1 插入数据1.1 实际问题1.2 方式 1:VALUES的方式添加1.3 方式2:将查询结果插入到表中演示代码 2 更新数据演示代码 3 删除数据演示代码 4 MySQL8新特性:计算列演示代码 5 综合案例课后练习 1 插入数据
1.1 实际问题 解决方式&#…

深度学习之基于Python+OpenCV+dlib的考生信息人脸识别系统(GUI界面)
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 深度学习在人脸识别领域的应用已经取得了显著的进展。Python是一种常用的编程语言,它提供了许多强大的库…

从零开始学习搭建量化平台笔记
从零开始学习搭建量化平台笔记
本笔记由纯新手小白开发学习记录,欢迎大佬请教指点留言,有空的话还可以认识一下,来上海请您喝咖啡~~ 2023/10/30:上份工作辞职并休息了几个月后,打算开始找个关于量化投资相关的工作。面…
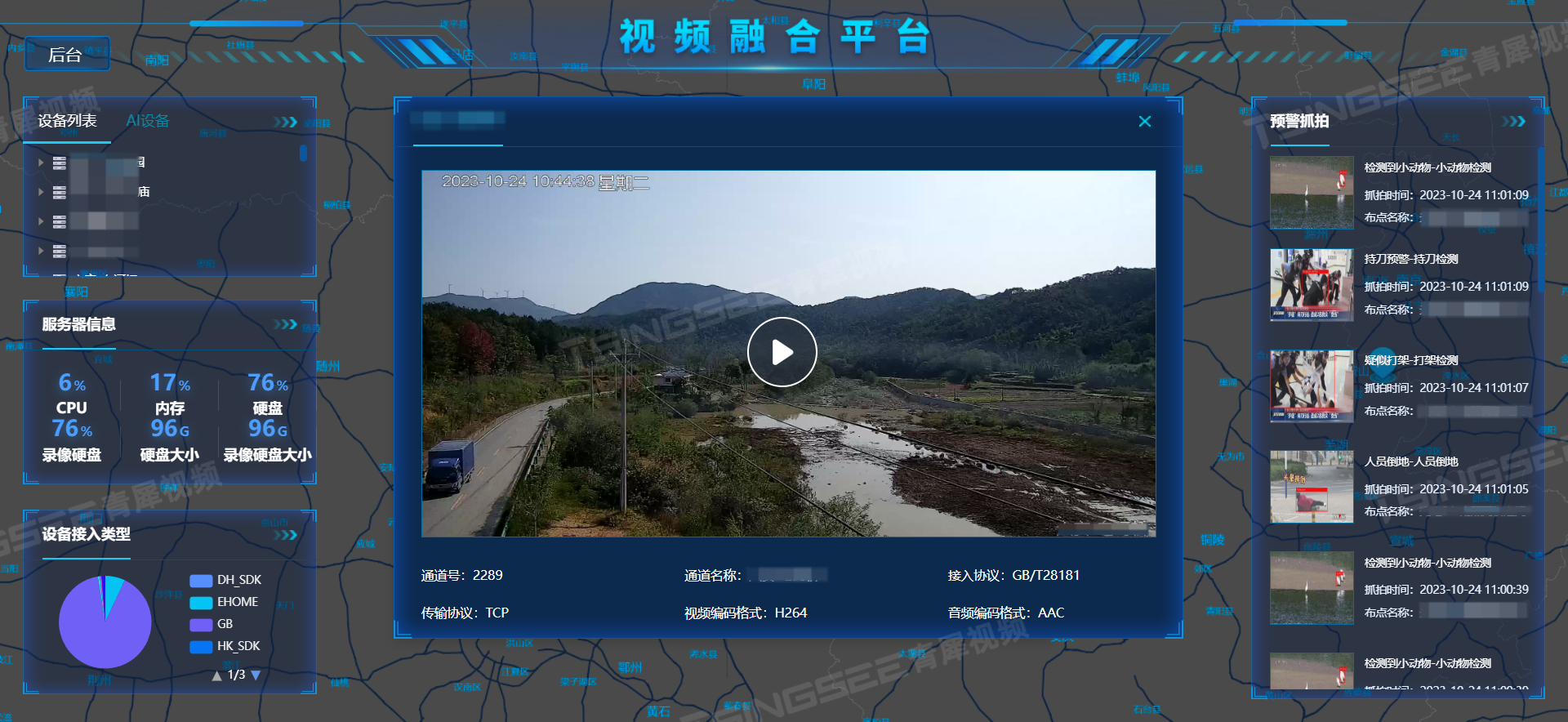
在公共安全场景下,智能监控如何做到保障安全的同时又最大化地提供便利?
智能监控系统应用的场景十分广泛,其中,公共安全场所的需求尤为重要,为保障公共区域的安全,提升人民群众的归属感,增强公共场所的安全性,智慧安防EasyCVR智能视频监控系统做出了极大努力。具体细节如下&…

基于生成对抗网络的照片上色动态算法设计与实现 - 深度学习 opencv python 计算机竞赛
文章目录 1 前言1 课题背景2 GAN(生成对抗网络)2.1 简介2.2 基本原理 3 DeOldify 框架4 First Order Motion Model5 最后 1 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 基于生成对抗网络的照片上色动态算法设计与实现
该项目较为新颖&am…

YOLOv5源码中的参数超详细解析(5)— 验证部分(val.py)参数解析
前言:Hello大家好,我是小哥谈。YOLOv5是一种先进的目标检测算法,它可以实现快速和准确的目标检测。在YOLOv5源码中,train.py和detect.py文件讲完了之后,接着就是讲val.py文件了。本节课就结合源码对val.py文件进行逐行解析~!🌈 前期回顾: YOLOv5源码中的参数超详细解…

喜报|英码科技荣登“广州首届百家新锐企业名单”、“2022年度中国好技术项目库名单”榜单
近日,英码科技喜报连连,在刚刚公布的2022年度“中国好技术”项目库入选名单和广州首届百家新锐企业名单中,英码科技凭借出色的技术创新能力和优秀的企业竞争力荣登榜单。 2022年度“中国好技术” 近期,2022年度“中国好技术”征集…

持续进化,快速转录,Faster-Whisper对视频进行双语字幕转录实践(Python3.10)
Faster-Whisper是Whisper开源后的第三方进化版本,它对原始的 Whisper 模型结构进行了改进和优化。这包括减少模型的层数、减少参数量、简化模型结构等,从而减少了计算量和内存消耗,提高了推理速度,与此同时,Faster-Whi…
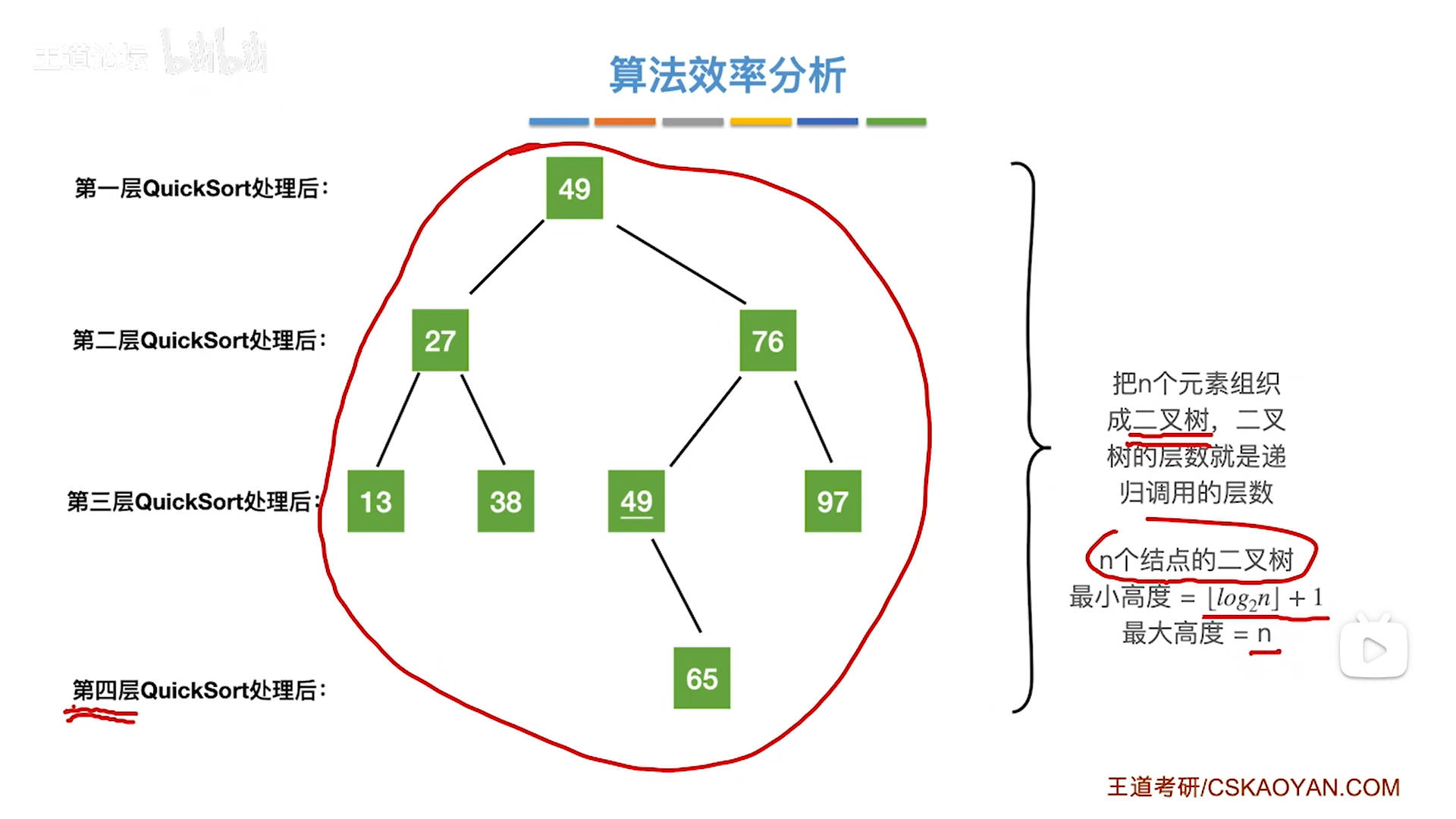
数据结构笔记——查找、排序(王道408)
文章目录 查找基本概念线性表查找顺序查找折半查找(二分)分块查找 树查找二叉排序树(BST)平衡二叉树(AVL)的插入平衡化复杂度分析 平衡二叉树的删除 红黑树红黑树的定义和性质红黑树定义红黑树性质 红黑树的…
MySQL进阶之性能优化与调优技巧
数据库开发-MySQL 1. 多表查询1.1 概述1.1.2 介绍1.1.3 分类 1.2 内连接1.3 外连接1.4 子查询1.4.1 介绍1.4.2 标量子查询1.4.3 列子查询1.4.4 行子查询1.4.5 表子查询 2. 事务2.1 介绍2.2 操作2.3 四大特性 3. 索引3.1 介绍3.2 结构3.3 语法 1. 多表查询
1.1 概述
1.1.2 介绍…
最新文章
- android开发工具手机版/深圳优化公司样高粱seo
- 房地产开发公司网站建设方案/成人计算机培训机构哪个最好
- 小视频制作模板免费/惠州seo代理商
- seo网站结构图/外链怎么发
- 进一步推进政府网站建设工作的通知/关键词热度分析工具
- 做网站的怎么跑业务/在线html5制作网站
- linux springboot项目启动端口被占用 Port 8901 was already in use.
- MFC/C++学习系列之简单记录13
- el-form组件中的常用属性
- C# cad启动自动加载启动插件、类库编译 多个dll合并为一个
- Linux系统安装node.js
- Android Studio AI助手---Gemini
推荐文章
- vue编译 Error: Could not load /src/core/config
- SQLiteC/C++接口详细介绍之sqlite3类(十一)
- ### 深入解析HarmonyOS Swiper组件的使用与优化
- #渗透测试#漏洞挖掘#红蓝攻防#SRC漏洞挖掘02之权限漏洞挖掘技巧
- #是啥,v-slot插槽的区别
- #硬件电路设计VL817-Q7(B0)芯片拓展USB3.0一转四调试心得
- (11)Python引领金融前沿:投资组合优化实战案例
- (35)远程识别(又称无人机识别)(二)
- (done) 关于 pytorch 代码里常出现的 batch_first 到底是啥?
- (leetcode学习)45. 跳跃游戏 II
- (不是Al创作助手、AiLink、开放猫、AiTab新标签、Official Index)分享好用的ChatGPT
- (二)ffmpeg 下载安装以及拉流推流示例