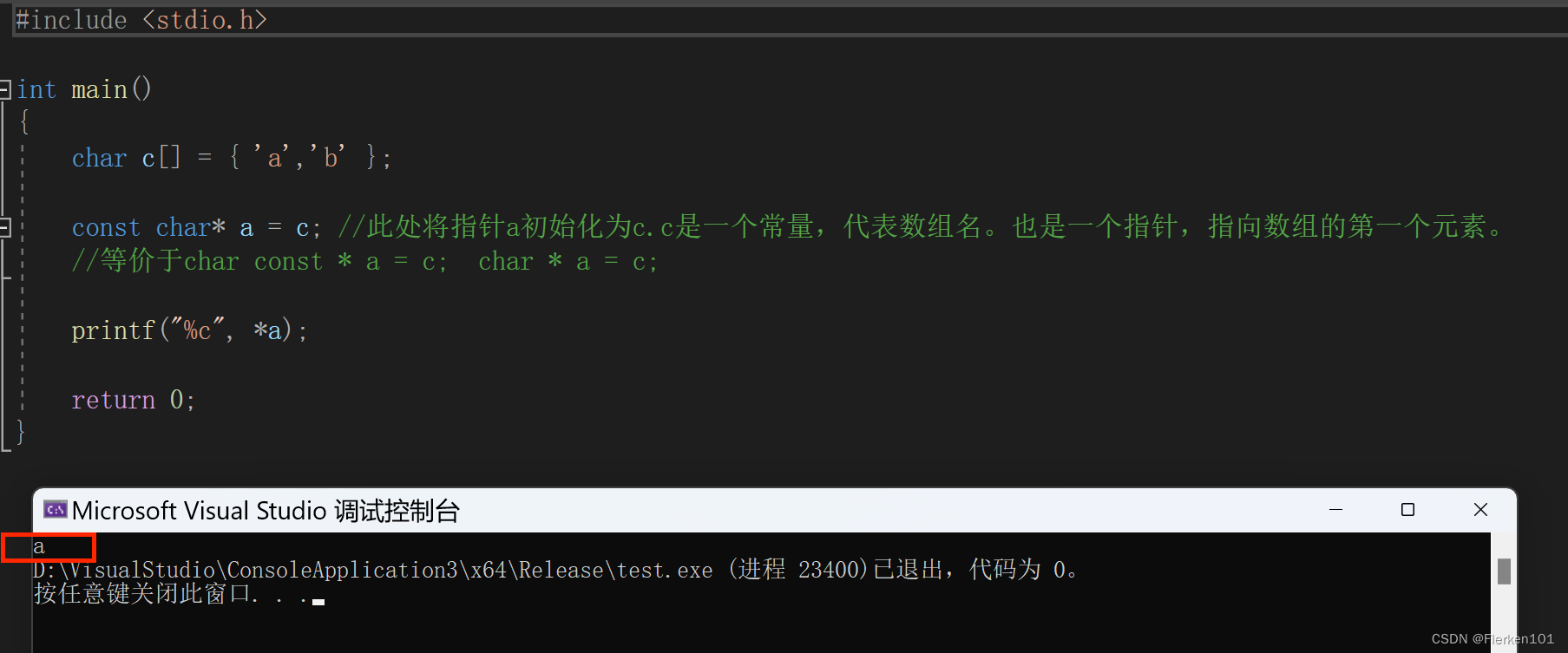
gorm day9
- 实体关联
- gorm会话
实体关联
自动创建、更新
在创建、更新数据时,GORM会通过Upsert自动保存关联及其引用记录。
user := User{Name: "jinzhu",BillingAddress: Address{Address1: "Billing Address - Address 1"},ShippingAddress: Address{Address1: "Shipping Address - Address 1"},Emails: []Email{{Email: "jinzhu@example.com"},{Email: "jinzhu-2@example.com"},},Languages: []Language{{Name: "ZH"},{Name: "EN"},},
}db.Create(&user)
// BEGIN TRANSACTION;
// INSERT INTO "addresses" (address1) VALUES ("Billing Address - Address 1"), ("Shipping Address - Address 1") ON DUPLICATE KEY DO NOTHING;
// INSERT INTO "users" (name,billing_address_id,shipping_address_id) VALUES ("jinzhu", 1, 2);
// INSERT INTO "emails" (user_id,email) VALUES (111, "jinzhu@example.com"), (111, "jinzhu-2@example.com") ON DUPLICATE KEY DO NOTHING;
// INSERT INTO "languages" ("name") VALUES ('ZH'), ('EN') ON DUPLICATE KEY DO NOTHING;
// INSERT INTO "user_languages" ("user_id","language_id") VALUES (111, 1), (111, 2) ON DUPLICATE KEY DO NOTHING;
// COMMIT;db.Save(&user)如果你想要更新关联的数据。你应该使用FullSaveAssociations模式:
db.Session(&gorm.Session{FullSaveAssociations: true}).Updates(&user)
// ...
// INSERT INTO "addresses" (address1) VALUES ("Billing Address - Address 1"), ("Shipping Address - Address 1") ON DUPLICATE KEY SET address1=VALUES(address1);
// INSERT INTO "users" (name,billing_address_id,shipping_address_id) VALUES ("jinzhu", 1, 2);
// INSERT INTO "emails" (user_id,email) VALUES (111, "jinzhu@example.com"), (111, "jinzhu-2@example.com") ON DUPLICATE KEY SET email=VALUES(email);
// ...解读:
这段内容展示了GORM如何处理与对象关系映射(ORM)相关的自动创建和更新操作,特别是涉及到关联记录的处理。GORM提供了一个强大的特性,即在执行插入(Create)或更新(Save、Updates)操作时,自动处理相关联模型的数据。
自动创建
在第一个示例中,创建了一个User实例,该实例包含了多种关联数据:一个计费地址(BillingAddress)、一个送货地址(ShippingAddress)、多个电子邮件(Emails)、以及多种语言(Languages)。当使用db.Create(&user)执行插入操作时,GORM会按照以下步骤处理这些数据:
1.开始事务:为了保证数据一致性,GORM首先开始一个数据库事务。
2.插入地址:计费地址和送货地址被插入到addresses表中。如果记录已存在(基于主键或唯一索引),则不执行任何操作(ON DUPLICATE KEY DO NOTHING)。
3.插入用户:随后,用户信息(包括关联的地址ID)被插入到users表中。
4.插入电子邮件:用户的电子邮件地址被插入到emails表中,关联到用户的ID。如果遇到重复记录,则不更新现有记录。
5.插入语言:语言数据被插入到languages表中,同样遵循ON DUPLICATE KEY DO NOTHING规则。
6.关联用户和语言:用户和语言之间的关系通过user_languages连接表建立。
7.提交事务:如果所有操作都成功,事务被提交。
自动更新(使用FullSaveAssociations)
在第二个示例中,如果你需要更新关联数据,可以通过在会话中设置FullSaveAssociations: true来启用这一行为。这会使GORM在更新记录时同时更新关联的数据。
使用db.Session(&gorm.Session{FullSaveAssociations: true}).Updates(&user)时,GORM不仅会尝试更新user记录,还会更新或插入关联的地址、电子邮件等数据。如果存在重复的键(即尝试插入已存在的记录),则会更新那些记录的相关字段(ON DUPLICATE KEY SET column=VALUES(column))。
**这种方法使得管理复杂的对象及其关系变得更加简单,因为开发者不需要手动编写用于更新每个关联记录的代码。**GORM的这些特性大大减少了处理关系型数据时的工作量,并且帮助保持代码的清晰和简洁。
跳过自动创建、更新:
若要在创建、更新时跳过自动保存,你可以使用Select或Omit,例如:
user := User{Name: "jinzhu",BillingAddress: Address{Address1: "Billing Address - Address 1"},ShippingAddress: Address{Address1: "Shipping Address - Address 1"},Emails: []Email{{Email: "jinzhu@example.com"},{Email: "jinzhu-2@example.com"},},Languages: []Language{{Name: "ZH"},{Name: "EN"},},
}db.Select("Name").Create(&user)
// INSERT INTO "users" (name) VALUES ("jinzhu", 1, 2);db.Omit("BillingAddress").Create(&user)
// Skip create BillingAddress when creating a userdb.Omit(clause.Associations).Create(&user)
// Skip all associations when creating a userNote:对于many2many关联,GORM在创建连接表引用之前,会先upsert关联,如果你想跳过upsert关联,你可以这样做:
db.Omit("Languages.*").Create(&user)下面的代码将跳过创建关联及其引用
db.Omit("Languages").Create(&user)解读:
这段内容介绍了在使用GORM进行数据创建和更新操作时,如何跳过自动保存关联数据的方法。 GORM默认会自动保存实体及其关联的引用数据,但在某些情况下,你可能不希望自动创建或更新某些关联数据。为了实现这一点,GORM提供了Select和Omit方法,让你可以精确控制哪些字段或关联应该被包括或排除在创建和更新操作之外。
使用Select跳过自动创建、更新
Select方法允许你指定在操作中应该包括哪些字段。这意味着只有明确指定的字段会被创建或更新,其他未被包括的字段和关联则会被自动跳过。
示例解释:
db.Select("Name").Create(&user)这条命令会在创建user时仅包括Name字段,其他如BillingAddress、ShippingAddress、Emails、Languages等关联数据都不会被自动创建。
使用Omit跳过自动创建、更新
Omit方法与Select相反,它允许你指定在操作中应该排除哪些字段或关联。 这意味着除了被排除的字段或关联,其他所有数据都会被正常创建或更新。
示例解释:
db.Omit("BillingAddress").Create(&user)当创建user时,会跳过BillingAddress的创建,但其他信息(如Name、ShippingAddress、Emails、Languages)将正常保存。
db.Omit(clause.Associations).Create(&user)这将在创建user时跳过所有的关联数据。clause.Associations是一个特殊的标识符,用于表示所有关联。这将在创建user时跳过所有的关联数据。clause.Associations是一个特殊的标识符,用于表示所有关联。
跳过many2many关联的upsert
有时候,你可能还想跳过在创建数据时自动处理many2many关联的upsert操作(即更新或插入操作)。
db.Omit("Languages.*").Create(&user)这将跳过Languages关联的upsert操作,但仍然会创建user的其他数据和关联(除了Languages之外)。
db.Omit("Languages").Create(&user)这条命令会跳过创建Languages关联及其在连接表中的引用,完全不处理Languages数据。
总结
通过使用Select和Omit方法,GORM为开发者提供了灵活的数据操作控制,允许细粒度地选择哪些数据应该被创建或更新,哪些应该被忽略。这对于处理复杂的数据模型和关联关系非常有用,特别是当你需要优化性能或遵守特定的数据处理逻辑时。
Select/Omit关联字段
user := User{Name: "jinzhu",BillingAddress: Address{Address1: "Billing Address - Address 1", Address2: "addr2"},ShippingAddress: Address{Address1: "Shipping Address - Address 1", Address2: "addr2"},
}// 创建 user 及其 BillingAddress、ShippingAddress
// 在创建 BillingAddress 时,仅使用其 address1、address2 字段,忽略其它字段
db.Select("BillingAddress.Address1", "BillingAddress.Address2").Create(&user)db.Omit("BillingAddress.Address2", "BillingAddress.CreatedAt").Create(&user)解读:
db.Select("BillingAddress.Address1", "BillingAddress.Address2").Create(&user)在创建user记录时,这条命令指示GORM仅使用BillingAddress的Address1和Address2字段,而忽略BillingAddress中的其他字段。这意味着,尽管BillingAddress可能包含多个字段,但只有Address1和Address2被保存。
db.Omit("BillingAddress.Address2", "BillingAddress.CreatedAt").Create(&user)这条命令在创建user时会保存BillingAddress,但会忽略BillingAddress中的Address2和CreatedAt字段。即使这些字段在BillingAddress模型中有值,它们也不会被保存到数据库中。
关联模式
关联模式包含一些在处理关系时有用的方法
// 开始关联模式
var user User
db.Model(&user).Association("Languages")
// `user` 是源模型,它的主键不能为空
// 关系的字段名是 `Languages`
// 如果匹配了上面两个要求,会开始关联模式,否则会返回错误
db.Model(&user).Association("Languages").Error解读:
这段内容介绍了GORM中的“关联模式(Association Mode)”,它提供了一系列方法来处理模型之间的关系,如添加、删除或更新关联数据。关联模式特别适用于处理复杂的关系操作,使得这些操作更加直观和方便。
开始关联模式
要启动关联模式,你需要通过模型(db.Model(&user))调用Association方法,并传入关联字段的名称(在这个例子中是Languages)。这个方法用于指定你想要操作的特定关联。
示例:
db.Model(&user).Association("Languages")db.Model(&user):指定操作的源模型,这里是user。
.Association(“Languages”):指定要操作的关联字段,这里是user模型中的Languages字段。
在这个过程中,GORM会检查几个要求:
源模型的主键不能为空:这意味着你想操作的模型(在这个例子中是user)必须已经存在于数据库中,且其ID字段(或其他作为主键的字段)必须有值。这是因为关联操作通常依赖于主键来找到正确的记录。
关系字段名必须匹配:你指定的字段名(如Languages)必须是源模型中存在的一个有效的关联字段。
如果上述条件满足,GORM就会进入关联模式,允许你对指定的关系执行各种操作,比如查询、添加、删除等。
错误处理
db.Model(&user).Association("Languages").Error在执行关联操作时,你可以通过访问.Error属性来检查是否有任何错误发生。这对于调试和错误处理非常有用,可以帮助你确认操作是否成功,或者在出现问题时获取更多信息。
查找关联
查找所有匹配的关联记录:
db.Model(&user).Association("Languages").Find(&languages)这样看可能有点抽象,我来举个例子,看看什么效果:
假设我们有一个社交网络应用,其中User模型代表用户,Language模型代表用户会说的语言。一个用户可能会说多种语言,因此User和Language之间存在多对多的关系。我们想要找出特定用户会说的所有语言。
首先,我们定义User和Language模型:
type User struct {gorm.ModelName stringLanguages []Language `gorm:"many2many:user_languages;"`
}type Language struct {gorm.ModelName string
}user_languages是连接表,存储用户和语言之间的关联。
现在,假设我们有一个用户叫做"John",我们已经知道他的ID,想要找出他会说的所有语言。
var user User
var languages []Language// 假设我们已经知道John的ID,这里我们直接设置为1
user.ID = 1// 使用GORM的关联模式查找所有匹配的关联记录
db.Model(&user).Association("Languages").Find(&languages)在这个例子中,db.Model(&user).Association(“Languages”).Find(&languages)这行代码的作用是:
db.Model(&user): 指定我们正在操作的模型实例,即ID为1的用户(John)。
.Association(“Languages”): 表明我们对User模型中的Languages关联感兴趣。这告诉GORM我们想要操作的是用户会说的语言这一关联数据。
.Find(&languages): 指示GORM查找并填充所有与指定用户(John)相关联的Language记录到languages切片中。
**执行完这行代码后,languages切片将包含所有John会说的语言的记录。**这样,我们就可以轻松获取任何用户的语言信息,而不需要直接查询连接表或编写复杂的SQL查询。这是GORM提供的强大功能之一,让开发者可以更高效地处理关系数据。
查找带条件的关联:
codes := []string{"zh-CN", "en-US", "ja-JP"}
db.Model(&user).Where("code IN ?", codes).Association("Languages").Find(&languages)db.Model(&user).Where("code IN ?", codes).Order("code desc").Association("Languages").Find(&languages)这个就是在上面的基础上多了个where查询条件。
添加关联:
为many to many、has many添加新的关联,为has one,belongs to替换当前的关联:
db.Model(&user).Association("Languages").Append([]Language{languageZH, languageEN})db.Model(&user).Association("Languages").Append(&Language{Name: "DE"})db.Model(&user).Association("CreditCard").Append(&CreditCard{Number: "411111111111"})
解读:
这段内容说明了如何使用GORM的Append方法向关联字段添加新的关联数据。这个方法根据关联的类型(如"Many To Many"、“Has Many”、“Has One”、“Belongs To”)来决定是添加新的关联还是替换当前的关联。
添加关联的操作
对于**“Many To Many"和"Has Many”**关系,Append方法会添加新的关联记录。这意味着如果你对一个用户添加新的语言,这些新的语言将被添加到用户会说的语言列表中,而不会影响到已存在的语言记录。
对于**"Has One"和"Belongs To**"关系,Append会替换当前的关联。这意味着如果一个用户已经有了一个信用卡关联,使用Append添加新的信用卡会替换掉原有的信用卡关联。
示例解释
为"Many To Many"或"Has Many"关系添加新的关联
db.Model(&user).Association("Languages").Append([]Language{languageZH, languageEN})这条命令会向user的Languages关联字段添加两种新的语言(假设这里的languageZH和languageEN是两个已经定义好的Language实例,分别代表中文和英文)。这不会影响user原先已经关联的任何语言。
db.Model(&user).Association("Languages").Append(&Language{Name: "DE"})这条命令向user的Languages关联字段添加了一个新的语言实例(德语)。同样,这不会影响到user原先的语言关联。
为"Has One"或"Belongs To"关系替换当前的关联
db.Model(&user).Association("CreditCard").Append(&CreditCard{Number: "411111111111"})如果user模型有一个CreditCard字段表示用户的信用卡信息,并且这个字段是"Has One"关系,那么使用Append添加新的CreditCard实例将会替换掉用户原有的信用卡关联。
我这里举个非常形象的例子:
假设我们有一个用户John,他原本会说英文(EN)。现在我们要添加中文(ZH)和德语(DE)到他会说的语言列表中,并更新他的信用卡信息。
操作前:
John的语言列表:[EN]
John的信用卡号:123456789
执行操作:
添加[中文(ZH), 德语(DE)]到语言列表。
更新信用卡信息为411111111111。
操作后:
John的语言列表变为:[EN, ZH, DE]
John的信用卡号变为:411111111111
通过这种方式,GORM的Append方法提供了灵活的关联数据管理,允许开发者根据关系类型轻松地添加或替换关联数据。
替换关联
用一个新的关联替换当前的关联
db.Model(&user).Association("Languages").Replace([]Language{languageZH, languageEN})db.Model(&user).Association("Languages").Replace(Language{Name: "DE"}, languageEN)解读:
这段内容讲述了如何使用GORM的Replace方法来用一个或多个新的关联记录替换一个模型当前的关联记录。这个方法特别适用于**"Many To Many"和"Has Many"关系**,当你想更新模型的关联数据集合时,而不仅仅是向现有集合添加新元素。
Replace操作的含义
当使用Replace方法时,GORM会先移除源模型当前所有的关联记录(在这个例子中是user的所有Languages),然后再添加Replace方法中指定的新关联记录。
示例解释
假设我们有一个User模型,它与Language模型存在"Many To Many"关系。用户可以会说多种语言,并且我们希望更新某个用户会说的语言列表。
替换所有关联
db.Model(&user).Association("Languages").Replace([]Language{languageZH, languageEN})这条命令会将用户当前会说的所有语言替换为中文(languageZH)和英文(languageEN)。如果用户原先会说德语和法语,那么这两种语言会被中文和英文取代。
替换部分关联
db.Model(&user).Association("Languages").Replace(Language{Name: "DE"}, languageEN)这条命令意图可能有些误导,因为Replace通常用于替换所有关联记录。这里的意思是将用户会说的所有语言替换为德语(Language{Name: “DE”})和英文(languageEN),而不是只替换其中一两种语言。如果用户原先会说中文和法语,那么这两种语言会被德语和英文取代。
结果的变化示例
假设我们有一个用户John,他原本会说英文(EN)和法语(FR)。
操作前:
John的语言列表:[EN, FR]
执行操作:
使用Replace将语言列表替换为[中文(ZH), 德语(DE)]。
操作后:
John的语言列表变为:[ZH, DE]
通过使用Replace方法,John原本会说的语言列表被完全更新为新的语言集合,原有的语言关联被移除,新的语言关联被添加。
总结:
GORM的Replace方法为关联数据的更新提供了强大的灵活性,使得管理复杂的关系数据变得更简单、更直观。
删除关联:
如果存在,则删除源模型与参数之间的关系,只会删除引用,不会从数据库中删除这些对象。
db.Model(&user).Association("Languages").Delete([]Language{languageZH, languageEN})
db.Model(&user).Association("Languages").Delete(languageZH, languageEN)解读:
这段内容说明了如何使用GORM的Delete方法在关联模型间删除关系引用,而不实际删除关联对象本身。在"Many To Many"和"Has Many"关系中,这意味着操作只会移除两个模型之间的关系记录,而不会从数据库中删除这些模型的数据记录。
解释"删除引用,不会从数据库中删除这些对象"
当你在使用Delete方法移除模型间的关联时(比如用户和语言之间的关系),**GORM不会删除Language模型的记录本身,即不会从languages表中删除任何行。相反,它只会删除连接表(用于存储用户和语言之间关系的表,如user_languages)中的相关记录。**这样,Language实例仍然存在于数据库中,但不再与特定的User实例相关联。
示例
假设有一个用户(User模型实例)原先会说多种语言(Language模型实例),这些语言通过一个连接表(比如user_languages)来表示User和Language之间的关系。
操作前
用户John会说中文(ZH)和英文(EN)。
user_languages表中有两条记录,将John与中文(ZH)、英文(EN)相连。
执行删除关联操作
db.Model(&user).Association("Languages").Delete([]Language{languageZH, languageEN})或者
db.Model(&user).Association("Languages").Delete(languageZH, languageEN)这些命令会删除user_languages连接表中,将John与中文(ZH)、英文(EN)相连的记录。
操作后
John不再会说中文(ZH)和英文(EN)——至少根据数据库记录。
languages表中的中文(ZH)和英文(EN)的记录依旧存在,没有被删除。
user_languages连接表中关联John与中文(ZH)、英文(EN)的记录被删除。
总结:
通过这种方式,Delete方法允许你灵活地管理模型之间的关联关系,而不需要担心会误删数据。这对于处理复杂的数据模型关系尤其重要,因为它保证了数据的完整性和一致性。
清空关联:
删除源模型与关联之间的所有引用,但不会删除这些关联
db.Model(&user).Association("Languages").Clear()和上面一个性质,但是这个就是直接全删。
关联计数
返回当前关联的计数
db.Model(&user).Association("Languages").Count()// 条件计数
codes := []string{"zh-CN", "en-US", "ja-JP"}
db.Model(&user).Where("code IN ?", codes).Association("Languages").Count()解读:
这段内容说明了如何使用GORM的Count方法来获取当前模型关联字段的记录数量。这个方法非常有用,因为它允许你快速地了解一个模型与其关联数据之间的关系密度,比如一个用户会说多少种语言。
返回当前关联的计数
Count方法可以直接调用在一个模型的关联上,来获取这个关联当前有多少条记录。这个数字反映了数据库中实际存在的、与给定模型相关联的记录数。
条件计数
你还可以在调用Count之前使用Where方法来应用条件,这样Count返回的就是满足特定条件的关联记录数量。 这在你需要获取符合特定条件的关联数量时非常有用。
示例解释
假设我们有一个社交应用,其中User模型表示用户,Language模型表示用户可以交流的语言。一个用户可以会说多种语言,因此User和Language之间存在"Many To Many"关系。
示例:计算用户会说的语言数量
// 假设user代表一个特定的用户实例
var user User = ... // 用户实例,已经初始化// 获取这个用户会说的语言总数
count := db.Model(&user).Association("Languages").Count()在这个示例中,Count方法会返回与user实例关联的Languages记录的数量,即这个用户会说多少种语言。
示例:条件计数
假设我们想要知道用户会说的特定一组语言中有多少种:
codes := []string{"zh-CN", "en-US", "ja-JP"}
count := db.Model(&user).Where("code IN ?", codes).Association("Languages").Count()这里,我们首先定义了一个语言代码的列表codes,包含中文、英文和日文。然后,我们使用Where(“code IN ?”, codes)来指定条件,最后调用Count来获取用户会说的、列表中包含的语言数量。
结果的变化示例
假设用户John会说四种语言:中文、英文、日文和德文。
操作前:
John会说的语言:[ZH, EN, JA, DE]
执行操作:
计算John会说的语言总数:4
计算John会说的特定语言(中文、英文、日文)数量:3
操作后:
John会说的语言数量没有变化,但我们通过Count了解到John总共会说4种语言,并且在我们关心的语言列表(中文、英文、日文)中,他会说其中的3种。
总结:
通过这种方式,Count方法为开发者提供了一个高效的工具,用于分析和理解模型之间的关联密度和特性。
批量处理数据
关联模式也支持批量处理,例如:
// 查询所有用户的所有角色
db.Model(&users).Association("Role").Find(&roles)// 从所有 team 中删除 user A
db.Model(&users).Association("Team").Delete(&userA)// 获取去重的用户所属 team 数量
db.Model(&users).Association("Team").Count()// 对于批量数据的 `Append`、`Replace`,参数的长度必须与数据的长度相同,否则会返回 error
var users = []User{user1, user2, user3}
// 例如:现在有三个 user,Append userA 到 user1 的 team,Append userB 到 user2 的 team,Append userA、userB 和 userC 到 user3 的 team
db.Model(&users).Association("Team").Append(&userA, &userB, &[]User{userA, userB, userC})
// 重置 user1 team 为 userA,重置 user2 的 team 为 userB,重置 user3 的 team 为 userA、 userB 和 userC
db.Model(&users).Association("Team").Replace(&userA, &userB, &[]User{userA, userB, userC})这段内容介绍了GORM中处理模型关联的几种高级用法,特别是在处理多对多(Many To Many)或一对多(Has Many)关系时,如用户(User)和角色(Role)或团队(Team)之间的关系。让我们逐一解读每个操作的含义和应用场景。
查询所有用户的所有角色
db.Model(&users).Association("Role").Find(&roles)这个操作是为了查询所有用户(users)关联的角色(Role)并将结果填充到roles变量中。这意味着如果你有多个用户,该操作将汇总这些用户所拥有的所有角色,并存储在roles中。
从所有团队中删除特定用户
db.Model(&users).Association("Team").Delete(&userA)这个操作将会从与users变量关联的所有团队(Team)中删除指定的用户(userA)。注意,这里的users可能表示多个用户实例的集合,意味着userA将会从所有这些用户所属的团队中被移除。
获取去重的用户所属团队数量
db.Model(&users).Association("Team").Count()此操作用于计算与users关联的、去重后的团队(Team)数量。如果多个用户属于相同的团队,那么这个团队只会被计数一次,这有助于了解有多少独特的团队与给定的用户集合相关联。
批量数据的Append和Replace
对于批量数据的关联操作,如Append和Replace,如果你要对多个用户同时进行操作,你需要确保传递给这些方法的参数数量与你操作的用户数量一致,否则GORM会返回错误。
批量Append示例
db.Model(&users).Association("Team").Append(&userA, &userB, &[]User{userA, userB, userC})这条命令尝试将userA添加到user1的团队、userB到user2的团队,以及userA、userB和userC到user3的团队。这里,users是一个包含user1、user2、user3的用户集合。 为了成功执行,每个Append操作的参数数量必须匹配users集合中的用户数量。
批量Replace示例
db.Model(&users).Association("Team").Replace(&userA, &userB, &[]User{userA, userB, userC})与Append操作类似,这条命令尝试重置user1的团队为userA,user2的团队为userB,以及user3的团队为userA、userB和userC。这种操作用于完全替换现有的关联而不仅仅是添加新的关联。
结果的变化示例
考虑到上述解释,我们可以看到如下变化:
查询所有用户的所有角色:将为所有用户聚合并列出他们的角色。
从所有团队中删除特定用户:指定用户将不再属于任何通过users变量关联的团队。
获取去重的用户所属团队数量:将返回一个数字,代表不同的团队总数。
批量Append和Replace:根据操作,用户的团队关联将被相应地添加或替换。
总结:
这些操作展示了GORM提供的灵活性和强大功能,允许开发者以高效、简洁的方式处理复杂的关系数据。
带Select的删除
你可以在删除记录时通过Select来删除具有has one、has many、many2many关系的记录,例如”
// 删除 user 时,也删除 user 的 account
db.Select("Account").Delete(&user)// 删除 user 时,也删除 user 的 Orders、CreditCards 记录
db.Select("Orders", "CreditCards").Delete(&user)// 删除 user 时,也删除用户所有 has one/many、many2many 记录
db.Select(clause.Associations).Delete(&user)// 删除 users 时,也删除每一个 user 的 account
db.Select("Account").Delete(&users)注意,只有当记录的主键不为空时,关联才会被删除,GORM会使用这些主键作为条件。
// DOESN'T WORK
db.Select("Account").Where("name = ?", "jinzhu").Delete(&User{})
// 会删除所有 name=`jinzhu` 的 user,但这些 user 的 account 不会被删除db.Select("Account").Where("name = ?", "jinzhu").Delete(&User{ID: 1})
// 会删除 name = `jinzhu` 且 id = `1` 的 user,并且 user `1` 的 account 也会被删除db.Select("Account").Delete(&User{ID: 1})
// 会删除 id = `1` 的 user,并且 user `1` 的 account 也会被删除解读:
先解读第一个疑问,// 删除 user 时,也删除 user 的 account,有人可能会问这个account到底是什么?
在这个上下文中,account指的是与用户模型(User)通过has one或has many关系关联的另一个模型(Account)的实例。简而言之,account代表的是与用户直接相关联的账户信息,如银行账户、用户配置账户等。
示例解释
假设我们有以下模型定义:
type User struct {gorm.ModelName stringAccount Account // 假设一个用户有一个账户Orders []Order // 假设一个用户可以有多个订单// 其他字段...
}type Account struct {gorm.ModelUserID uint// 账户详细信息...
}如果你执行db.Select(“Account”).Delete(&user),那么指定的用户及其账户将会被从数据库中删除。 这意味着,不仅users表中对应的用户记录会被删除,accounts表中与该用户关联的账户记录也会被删除。但是,这个操作不会删除用户的订单(Orders),除非你在Select方法中也指定了Orders。
文档例子解读:
这段内容说明了如何在使用GORM删除一个记录时,同时删除与之关联的其他记录。这是通过使用Select方法实现的,它允许你指定在执行删除操作时应该一同考虑的关联。
带Select的删除操作
删除用户及其账户:
db.Select("Account").Delete(&user)这条命令会删除指定的用户(user)以及与该用户通过has one或has many关联的账户(Account)。
删除用户及其订单和信用卡记录:
db.Select("Orders", "CreditCards").Delete(&user)**这会删除用户(user)及其订单(Orders)和信用卡(CreditCards)记录。**这里的Orders和CreditCards是与用户有has many或many2many关系的关联字段名。
删除用户及其所有关联记录:
db.Select(clause.Associations).Delete(&user)使用clause.Associations可以指示GORM删除用户(user)及其所有的关联记录,包括has one、has many和many2many关系的记录。
对于多个用户的情况,上述操作同样适用:
db.Select("Account").Delete(&users)这条命令会删除多个用户(users)及其各自的账户(Account)。
注意事项
当记录的主键不为空时,关联删除操作才会生效。GORM使用这些主键作为条件来确定哪些关联记录应该被删除。
关联标签:
gorm会话
先了解会话的概念:
数据库会话(Database Session)是与数据库进行交互的一个上下文或连接实例。在一个会话中,你可以执行SQL查询、更新、插入和删除等操作。**会话控制着与数据库的交互方式,包括事务管理、连接状态和配置选项等。**它是进行数据库操作的基础,确保数据的读写操作是按照预定的方式执行的。
会话的用途和重要性
1.事务管理:会话允许你控制事务的开始、提交和回滚。事务是数据库操作的一个单位,确保了数据的一致性和完整性。在一个事务中,要么所有的操作都成功执行并被提交,要么在遇到错误时所有的操作都被回滚,以避免数据不一致。
2.隔离级别控制:数据库会话允许设置事务的隔离级别,这直接影响到事务的并发性能和数据一致性。不同的隔离级别可以解决脏读、不可重复读和幻读等问题,但同时也可能会引入锁等待和死锁问题。
3.性能优化:会话可以被配置为缓存预编译的SQL语句,减少数据库编译SQL的次数,从而提高应用性能。此外,会话配置还可以包括连接池管理,合理利用数据库连接资源。
4.上下文管理:在一些框架中,数据库会话还可以携带上下文信息(如用户会话信息、请求ID等),用于日志记录、审计和安全控制等。
5.灵活的配置和日志记录:会话允许在执行数据库操作时动态改变配置(如日志级别、是否执行Dry Run等),这对于调试和性能分析非常有用。
例子
在使用ORM工具(如GORM)时,数据库会话的概念尤为重要。例如,你可以创建一个新的会话来执行特定的数据库操作,同时设置特定的会话选项,如开启Dry Run模式查看生成的SQL语句,或者设置自定义的日志记录器来跟踪操作:
// 创建一个新的会话,开启Dry Run模式
dbSession := db.Session(&gorm.Session{DryRun: true})// 使用这个会话执行查询,不会真正访问数据库,但可以查看生成的SQL
dbSession.Find(&user)数据库会话是数据库操作的基础,理解和正确使用会话对于开发高效、可靠和安全的数据库应用至关重要。
来看看gorm文档的知识:
gorm提供了Session方法,这是一个New Session Method,它允许创建带配置的新建会话模式:
// Session 配置
type Session struct {DryRun boolPrepareStmt boolNewDB boolSkipHooks boolSkipDefaultTransaction boolAllowGlobalUpdate boolFullSaveAssociations boolContext context.ContextLogger logger.InterfaceNowFunc func() time.Time
}解读:
GORM提供的Session结构体,它用于配置和创建一个新的数据库会话。通过这个Session结构体,你可以自定义会话的行为和特性,使其适应特定的操作需求。下面是Session结构体各个字段的作用:
DryRun: 如果设置为true,则GORM会生成但不执行SQL语句。这对于测试和调试SQL语句非常有用,因为你可以看到将要执行的SQL而不实际对数据库进行更改。
PrepareStmt: 当设置为true时,GORM会缓存预编译的SQL语句,以提高后续执行相同SQL语句的性能。
NewDB: 如果为true,则会创建一个新的DB实例,而不是复用当前的DB实例。这允许会话具有独立的配置和状态,而不影响其他会话。
SkipHooks: 设置为true时,GORM在此会话中执行的操作将跳过所有的钩子函数。钩子函数是在如创建、更新等操作前后执行的自定义逻辑。
SkipDefaultTransaction: 如果为true,则对当前会话中的操作不会自动使用事务包裹。默认情况下,GORM会为Create、Update、Delete操作使用事务。
AllowGlobalUpdate: 默认情况下,GORM禁止不带Where条件的全局更新和删除操作,以防止意外更改所有记录。将此设置为true将允许这种操作。
FullSaveAssociations: 当设置为true时,GORM在保存一个模型时也会保存所有关联的模型,即使这些关联模型没有被修改。
Context: 允许你为会话指定一个context.Context,这对于传递请求范围的数据、控制取消操作等场景很有用。
Logger: 你可以为会话指定一个自定义的日志记录器,用于记录GORM的操作日志。
NowFunc: 允许自定义返回当前时间的函数,这在需要控制或模拟时间行为时非常有用。
使用示例
假设你想执行一个不实际更改数据库的DryRun操作来查看生成的SQL语句:
db.Session(&gorm.Session{DryRun: true}).Find(&user).Statement.SQL.String()创建了一个配置为DryRun的新会话,并执行了一个查询操作。由于DryRun为true,这个操作不会实际执行查询,而是允许我们获取将要执行的SQL语句。
这里我深入解读一下,因为我一开始对语法结构上有些不懂,有几个问题需要解答:
1.db.Session()调用了会返回什么
2.为什么可以调用Statement
3.这个Statement又是什么,为什么它能够又调用一个SQL.String()
解答:
1.当你在GORM中执行db.Session(&gorm.Session{DryRun: true}).Find(&user)这样的链式调用时,整个表达式不直接返回查询结果,而是返回一个*gorm.DB实例,这个实例代表了当前的数据库操作会话。 在GORM中,数据库操作(如查询、插入、更新等)并不立即执行,而是构建相应的操作上下文,直到调用执行(如Create、Find、Save、Delete等)方法时才真正执行。这就是为什么可以链式调用.Statement的原因。
2.在GORM中,Statement是一个结构体,它代表了一次数据库操作的上下文和状态。每当你使用GORM执行一个查询、插入、更新或删除操作时,GORM会构建一个Statement实例来封装和管理这次操作的所有相关信息。这包括但不限于构建的SQL语句、绑定的参数、预编译的语句等。
3.直接看它的结构体:
type Statement struct {// 数据库操作的基础信息DB *DBSchema *SchemaModel interface{}Table stringClauses map[string]ClauseDest interface{}ReflectValue reflect.ValueCurDestIndex []intContext context.Context// SQL 语句构建相关SQL strings.BuilderVars []interface{}NamedVars []sql.NamedArgSelects []stringOmittedFields map[string]struct{}Joins map[string][]interface{}Preloads map[string]preloadWhereConditions []interface{}HavingConditions []interface{}JoinConditions []interface{}GroupByConditions []interface{}OrderByConditions []interface{}Limit intOffset int// 钩子函数执行相关BeforeHooks []func(*DB) errorAfterHooks []func(*DB) error// 错误处理Error error// 其他执行选项SkipHooks boolIgnoreOrderQuery boolDryRun boolPrepareStmt boolAllowGlobalUpdate boolQueryFields boolCreateBatchSize int// ... 可能还有更多字段
}总之就是它的结构体还是很复杂的,这里知道了这样的语法结构,至少看代码会舒服很多。继续来看这个例子:
在Statement结构体中,SQL字段是一个封装了构建好的SQL语句的对象。它包含了执行当前数据库操作所需的完整SQL字符串及其绑定的参数。
DryRun
// 新建会话模式
stmt := db.Session(&Session{DryRun: true}).First(&user, 1).Statement
stmt.SQL.String() //=> SELECT * FROM `users` WHERE `id` = $1 ORDER BY `id`
stmt.Vars //=> []interface{}{1}// 全局 DryRun 模式
db, err := gorm.Open(sqlite.Open("gorm.db"), &gorm.Config{DryRun: true})// 不同的数据库生成不同的 SQL
stmt := db.Find(&user, 1).Statement
stmt.SQL.String() //=> SELECT * FROM `users` WHERE `id` = $1 // PostgreSQL
stmt.SQL.String() //=> SELECT * FROM `users` WHERE `id` = ? // MySQL
stmt.Vars //=> []interface{}{1}你可以使用下面的代码生成最终的SQL:
// 注意:SQL 并不总是能安全地执行,GORM 仅将其用于日志,它可能导致会 SQL 注入
db.Dialector.Explain(stmt.SQL.String(), stmt.Vars...)
// SELECT * FROM `users` WHERE `id` = 1解读:
stmt := db.Session(&Session{DryRun: true}).First(&user, 1).Statement
stmt.SQL.String() //=> SELECT * FROM `users` WHERE `id` = $1 ORDER BY `id`
stmt.Vars //=> []interface{}{1}
首先就是新建会话设置了DryRun:true,在这种模式下,GORM会构建SQL语句,但不会执行它们。这对于检查生成的SQL语句非常有用。然后调用了查询,然后获取了构建的上下文。
这行代码尝试获取ID为1的用户,但由于是在DryRun模式下,它只构建了相应的SQL查询而没有实际执行。
stmt.SQL.String()返回构建的SQL查询字符串。
stmt.Vars展示了SQL查询中使用的参数值,这里是1,代表用户ID。
全局DryRun模式
接下来,示例展示了如何在打开数据库连接时全局启用DryRun模式。这意味着所有通过这个db实例执行的操作都将只构建SQL语句而不执行它们。
db, err := gorm.Open(sqlite.Open("gorm.db"), &gorm.Config{DryRun: true})这里通过gorm.Config{DryRun: true}全局设置DryRun模式。
不同数据库生成不同的SQL
由于GORM支持多种数据库,所以它会根据不同的数据库方言(Dialector)构建适合该数据库的SQL语句。例如,对于PostgreSQL,参数占位符是$1;而对于MySQL,是?。
生成最终的SQL
尽管DryRun模式下生成的SQL语句和参数是分开的,你可能需要一个完整的SQL语句进行测试或其他目的。这时,可以使用db.Dialector.Explain方法:
db.Dialector.Explain(stmt.SQL.String(), stmt.Vars...)这行代码将参数值替换到SQL语句中的占位符,生成一个可执行的SQL语句。 这对于调试非常有用,但要注意,直接拼接参数到SQL语句可能导致SQL注入风险,因此这种生成的SQL语句主要用于日志记录或调试,而不是直接执行。
注意事项
虽然Explain方法可以生成包含参数的完整SQL语句,但直接使用这种方式拼接SQL语句和参数可能会有SQL注入的风险。GORM本身在执行查询时会采取措施防止SQL注入,如使用参数化查询。因此,Explain方法生成的SQL应谨慎使用,主要用于日志记录和调试目的。
预编译
PreparedStmt 在执行任何SQL时都会创建一个prepared statement并将其缓存,以提高后续的效率,例如:
// 全局模式,所有 DB 操作都会创建并缓存预编译语句
db, err := gorm.Open(sqlite.Open("gorm.db"), &gorm.Config{PrepareStmt: true,
})// 会话模式
tx := db.Session(&Session{PrepareStmt: true})
tx.First(&user, 1)
tx.Find(&users)
tx.Model(&user).Update("Age", 18)// returns prepared statements manager
stmtManger, ok := tx.ConnPool.(*PreparedStmtDB)// 关闭 *当前会话* 的预编译模式
stmtManger.Close()// 为 *当前会话* 预编译 SQL
stmtManger.PreparedSQL // => []string{}// 为当前数据库连接池的(所有会话)开启预编译模式
stmtManger.Stmts // map[string]*sql.Stmtfor sql, stmt := range stmtManger.Stmts {sql // 预编译 SQLstmt // 预编译模式stmt.Close() // 关闭预编译模式
}解读:
这段内容介绍了GORM中预编译语句(Prepared Statement)的使用方法,包括如何在全局和会话级别启用预编译,以及如何管理预编译语句。预编译语句是一种数据库性能优化技术,它允许SQL语句模板一次编译,多次执行,减少了数据库的编译时间,并可以避免SQL注入攻击。
全局模式
在全局模式下,通过在打开数据库连接时设置PrepareStmt: true,可以让GORM自动为所有数据库操作创建并缓存预编译语句。
db, err := gorm.Open(sqlite.Open("gorm.db"), &gorm.Config{PrepareStmt: true,
})这意味着,从这个db实例发起的所有操作(查询、更新、删除等)都会使用预编译语句,提高了操作的效率。
会话模式
你也可以为特定的数据库会话启用预编译模式,而不影响其他会话。
tx := db.Session(&Session{PrepareStmt: true})在这个会话中,所有操作(如First、Find、Update)都会使用预编译语句。这为细粒度控制提供了灵活性,允许你根据需要为特定操作启用预编译。
管理预编译语句
GORM提供了直接访问和管理预编译语句的能力。通过类型断言,你可以获取到PreparedStmtDB,这是GORM用于管理预编译语句的结构体。
stmtManger, ok := tx.ConnPool.(*PreparedStmtDB)我一开始看到这个我的问题出在语法出了点问题,因为我不是很了解这个tx里面的字段。
解读:
这段代码中的 tx.ConnPool.(*PreparedStmtDB) 使用了 Go 语言的类型断言特性,来检查 tx.ConnPool 是否是 *PreparedStmtDB 类型。让我逐步解释这个表达式的含义和用法。类型断言就是(x).T。
tx.ConnPool:这部分引用了tx对象(一个GORM的DB类型,代表数据库操作的会话)的ConnPool属性*。ConnPool是一个接口类型,通常用于抽象不同的数据库连接池实现。在GORM中,这可以是一个标准的数据库连接池,也可以是一个支持预编译语句管理的特殊连接池。
.(*PreparedStmtDB):这是一个类型断言,它尝试将ConnPool接口的实例转换为PreparedStmtDB类型。**PreparedStmtDB是GORM内部用于管理预编译SQL语句的结构体类型。**如果ConnPool实际上是PreparedStmtDB类型(或者说,它底层的实现是*PreparedStmtDB),这个断言就会成功。
stmtManger, ok :=:这是Go语言的多值赋值语法,用于接收类型断言的结果。类型断言可以返回两个值:第一个值是断言到的目标类型的值(如果断言成功),第二个值是一个布尔值,表示断言是否成功。 如果ConnPool确实是*PreparedStmtDB类型,那么ok将为true,并且stmtManger将被赋予相应的值;如果不是,ok将为false,而stmtManger将为nil。
简而言之,这行代码的目的是尝试从GORM的数据库会话中获取预编译语句管理器(PreparedStmtDB),以便可以直接操作预编译语句(如查看、关闭等)。这是一种高级用法,通常在需要深入控制或优化数据库操作性能时使用。
通过stmtManger,你可以:
查看为当前会话预编译的SQL语句(PreparedSQL)。
访问和管理当前数据库连接池中所有会话的预编译语句(Stmts),包括关闭预编译语句。
关闭预编译模式
关闭预编译模式意味着释放与预编译语句相关的资源。你可以关闭特定预编译语句,或者关闭当前会话的所有预编译语句。
stmt.Close() // 关闭单个预编译语句
stmtManger.Close() // 关闭当前会话的所有预编译语句了解了stmtManger的获取方式后,我们可以进一步解读这部分内容:
// 为 *当前会话* 预编译 SQL
stmtManger.PreparedSQL // => []string{}这行代码访问了stmtManger(即预编译语句管理器PreparedStmtDB的实例)的PreparedSQL字段,它是一个字符串切片([]string),包含了当前会话中所有已经预编译的SQL语句。由于这是一个新的会话,或者还没有任何SQL语句被预编译,所以这个切片可能是空的。
// 为当前数据库连接池的(所有会话)开启预编译模式
stmtManger.Stmts // map[string]*sql.Stmt这行代码访问了stmtManger的Stmts字段,它是一个映射(map[string]sql.Stmt),其中键(string)是SQL语句,值(sql.Stmt)是对应的预编译语句对象。这个映射包含了当前数据库连接池中所有会话共享的预编译语句。这意味着,一旦一个SQL语句在任何会话中被预编译,它就可以被其他会话重用,从而提高整个应用的性能。
for sql, stmt := range stmtManger.Stmts {sql // 预编译 SQLstmt // 预编译模式stmt.Close() // 关闭预编译模式
}这段代码遍历了stmtManger.Stmts中的所有预编译语句,并逐个关闭它们。关闭预编译语句是一个好习惯,特别是在不再需要这些语句时,因为它可以释放数据库资源。sql变量包含了预编译的SQL语句的文本,而stmt是对应的预编译语句对象,可以被执行多次而不需要重新编译SQL语句。调用stmt.Close()方法会关闭预编译语句并释放相关资源。
总之,通过管理预编译语句,GORM提供了一种方式来优化数据库操作的性能,尤其是在执行大量相似查询的场景下。同时,正确管理(如关闭不再需要的预编译语句)这些预编译语句也是维护数据库应用性能和稳定性的关键部分。
使用场景:
预编译语句在执行大量相似查询时特别有用,因为它可以减少数据库的编译时间,提高应用性能。同时,它还增加了应用的安全性,因为预编译的参数化查询可以有效防止SQL注入攻击。
总之,GORM的预编译功能提供了一种高效和安全的方式来执行数据库操作,特别适合于性能敏感和安全要求高的应用场景。
NewDB
通过NewDB选项创建一个不带之前条件的新DB,例如:
tx := db.Where("name = ?", "jinzhu").Session(&gorm.Session{NewDB: true})tx.First(&user)
// SELECT * FROM users ORDER BY id LIMIT 1tx.First(&user, "id = ?", 10)
// SELECT * FROM users WHERE id = 10 ORDER BY id// 不带 `NewDB` 选项
tx2 := db.Where("name = ?", "jinzhu").Session(&gorm.Session{})
tx2.First(&user)
// SELECT * FROM users WHERE name = "jinzhu" ORDER BY id解读:
展示了如何在GORM中通过使用NewDB选项在会话(Session)中创建一个新的数据库操作对象(DB),以及如何在不使用NewDB选项的情况下继续使用当前的条件。
使用NewDB选项
当你使用NewDB: true选项创建一个会话时,你实际上是在创建一个全新的数据库操作对象(DB),这个新的DB对象不会携带任何之前定义的条件(如Where条件、限制、排序等)。
tx := db.Where("name = ?", "jinzhu").Session(&gorm.Session{NewDB: true})在这个例子中,即使我们在创建tx之前使用了.Where(“name = ?”, “jinzhu”)指定了一个条件,这个条件也不会应用到tx上,因为NewDB: true确保了tx是一个全新的、不带任何之前状态或条件的DB对象。
因此,当你使用tx.First(&user)和tx.First(&user, “id = ?”, 10)进行查询时,这些查询不会包含最初的Where(“name = ?”, “jinzhu”)条件。它们直接按照指定的查询条件执行,第一个查询按id排序并获取第一条记录,第二个查询获取id为10的记录。
不带NewDB选项
相比之下,如果你创建一个会话时不使用NewDB选项:
tx2 := db.Where("name = ?", "jinzhu").Session(&gorm.Session{})在这种情况下,tx2会话继承了创建它时的条件(这里是.Where(“name = ?”, “jinzhu”))。因此,当你使用tx2.First(&user)进行查询时,这个查询会自动包含之前定义的Where条件,即查找名字为"jinzhu"的用户的第一条记录。
使用NewDB: true可以创建一个全新的、不带任何先前条件或设置的DB对象。这对于确保接下来的操作不受之前操作影响时非常有用。
不使用NewDB选项则意味着新会话将继承之前DB对象的所有条件和设置,适用于当你想在一系列操作中保持某些条件时。
这种灵活性允许GORM适应不同的使用场景,既可以保证操作的独立性,也可以方便地进行连贯的数据处理。
跳过钩子
如果你想跳过钩子方法,你可以使用SkipHooks会话模式
DB.Session(&gorm.Session{SkipHooks: true}).Create(&user)DB.Session(&gorm.Session{SkipHooks: true}).Create(&users)DB.Session(&gorm.Session{SkipHooks: true}).CreateInBatches(users, 100)DB.Session(&gorm.Session{SkipHooks: true}).Find(&user)DB.Session(&gorm.Session{SkipHooks: true}).Delete(&user)DB.Session(&gorm.Session{SkipHooks: true}).Model(User{}).Where("age > ?", 18).Updates(&user)禁用嵌套事务
在一个DB事务中使用Transaction方法,GORM会使用SavePoint(savePointName),RollbackTo(savedPointName)为你提供嵌套事务支持,你可以通过DisableNestedTransaction选项关闭它,例如:
db.Session(&gorm.Session{DisableNestedTransaction: true,
}).CreateInBatches(&users, 100)解读:
先知道什么是嵌套事务:
嵌套事务是数据库管理系统中的一个概念,**它允许在一个已经开启的事务内部再开启新的事务。这些内部事务被称为子事务,它们可以独立于外部事务提交或回滚。**嵌套事务提供了更细粒度的控制,使得你可以在复杂的操作中更灵活地管理事务。然而,并非所有的数据库系统都直接支持嵌套事务的概念,但是可以通过保存点(Savepoints)来模拟嵌套事务的行为。
嵌套事务和保存点
保存点(Savepoint):是事务内的一个标记点,你可以回滚到这个点而不是回滚整个事务。这意味着,如果事务中的一部分操作失败,你可以回滚到某个保存点,而不必丢弃整个事务的所有操作。
嵌套事务:通过使用保存点,可以模拟出嵌套事务的效果。当开始一个"子事务"时,实际上是在当前事务中创建一个保存点。如果"子事务"失败,可以回滚到这个保存点,而不影响外部事务的其他部分。
示例:使用保存点模拟嵌套事务
假设有一个电商应用,你需要处理一个订单,这个过程包括更新库存、记录订单详情和更新用户积分。这三个操作都应该在一个事务中完成,但是每个操作也可以视为一个独立的子事务。
1.开始事务:开始处理订单的整个事务。
2.更新库存:作为第一个子事务,如果更新成功,继续;如果失败,回滚这部分并退出整个事务。
3.记录订单详情:开始第二个子事务,如果记录成功,继续;如果失败,回滚到更新库存后的状态。
4.更新用户积分:最后一个子事务,如果更新成功,提交整个事务;如果失败,回滚到记录订单详情之后的状态。
**如果不使用嵌套事务或保存点,任何步骤的失败都需要回滚整个事务,即使某些操作已经成功完成。**通过使用保存点,可以在事务的不同阶段提供更多的灵活性和控制。
GORM中的嵌套事务
GORM通过SavePoint和RollbackTo方法提供了嵌套事务的支持。然而,GORM默认会为每个事务自动创建保存点,以便实现嵌套事务的效果。如果你不希望使用这个特性,可以通过DisableNestedTransaction: true在会话中禁用它。
db.Session(&gorm.Session{DisableNestedTransaction: true,
}).CreateInBatches(&users, 100)在这个例子中,DisableNestedTransaction: true选项告诉GORM在执行CreateInBatches操作时不自动使用保存点来模拟嵌套事务。这对于简化事务管理或当你的数据库操作不需要这种级别的控制时很有用。
总结,嵌套事务和保存点提供了更复杂事务管理的强大工具,使开发者能够在保证数据一致性和完整性的同时,更灵活地处理数据库操作中的错误和异常情况。
AllowGlobalUpdate:
GORM默认不允许进行全局update/delete,该操作会返回ErrMissingWhereClause错误。您可以通过将一个选项设置为true来启用它,例如:
db.Session(&gorm.Session{AllowGlobalUpdate: true,
}).Model(&User{}).Update("name", "jinzhu")
// UPDATE users SET `name` = "jinzhu"解读:
段内容介绍了GORM的一个安全特性,即默认情况下,GORM不允许执行没有WHERE子句的全局update或delete操作。这是一个预防措施,用来避免不小心执行可能影响到数据库中所有记录的操作,从而导致数据丢失或损坏。如果尝试执行这样的操作,GORM会返回一个ErrMissingWhereClause错误,提示开发者没有指定更新或删除操作的条件。
允许全局更新(AllowGlobalUpdate)
虽然GORM默认禁止这种潜在的危险操作,但在某些情况下,你可能确实需要执行全局更新或删除。例如,你可能想要重置数据库中所有用户的状态,或者删除所有过时的记录。在这种情况下,你可以通过设置AllowGlobalUpdate: true来覆盖GORM的默认行为,从而允许执行全局更新或删除操作。
示例解释
db.Session(&gorm.Session{AllowGlobalUpdate: true,
}).Model(&User{}).Update("name", "jinzhu")db.Session(&gorm.Session{AllowGlobalUpdate: true})创建了一个新的会话,并通过设置AllowGlobalUpdate: true来允许在这个会话中执行全局更新或删除操作。
.Model(&User{})指定了这次操作的模型是User。
.Update(“name”, “jinzhu”)执行一个更新操作,将所有用户的名字更改为"jinzhu"。因为在这个会话中允许全局更新,所以这个操作不需要WHERE子句就可以执行。
使用注意事项
虽然AllowGlobalUpdate选项提供了灵活性,使你能够根据需要执行全局更新或删除,但使用这个选项需要极其小心。在没有明确的WHERE条件的情况下执行更新或删除操作,可能会不小心修改或删除数据库中的大量数据,导致难以恢复的数据丢失。因此,除非绝对必要,并且你完全了解操作的后果,否则最好避免使用这个选项。
FullSaveAssociations:
在创建、更新记录时,GORM会通过Upsert自动保存管理及其引用记录。如果你想要更新关联的数据,你应该使用FullSaveAssociation模式,例如:
db.Session(&gorm.Session{FullSaveAssociations: true}).Updates(&user)
// ...
// INSERT INTO "addresses" (address1) VALUES ("Billing Address - Address 1"), ("Shipping Address - Address 1") ON DUPLICATE KEY SET address1=VALUES(address1);
// INSERT INTO "users" (name,billing_address_id,shipping_address_id) VALUES ("jinzhu", 1, 2);
// INSERT INTO "emails" (user_id,email) VALUES (111, "jinzhu@example.com"), (111, "jinzhu-2@example.com") ON DUPLICATE KEY SET email=VALUES(email);
// ...解读:
这段内容介绍了GORM的FullSaveAssociations选项,它用于在创建或更新记录时同时保存或更新这条记录的所有关联数据。当你设置FullSaveAssociations: true时,GORM会检查模型中的所有关联字段,自动执行必要的插入或更新操作,以确保关联数据的一致性。
db.Session(&gorm.Session{FullSaveAssociations: true}).Updates(&user)在这个示例中,假设user对象包含了多个关联字段,比如用户的地址信息(BillingAddress和ShippingAddress)和电子邮件地址(Emails):
地址信息:user对象中的地址信息将被插入到addresses表中。如果这些地址记录已经存在(例如,通过某个唯一键识别),则会更新这些记录而不是插入新的记录,这是通过ON DUPLICATE KEY SET实现的。
用户信息:user的基本信息(如姓名和地址ID)将被更新或插入到users表中。
电子邮件地址:user的电子邮件地址将被插入到emails表中。如果相应的电子邮件记录已经存在,它们也会被更新。
使用场景
FullSaveAssociations非常适合于那些需要同时更新一个实体及其所有关联实体的场景。 例如,在用户信息编辑页面,用户既可以更改他们的基本信息,也可以更改他们的地址信息和联系方式。使用FullSaveAssociations可以确保所有这些更改都在一个操作中被保存,这样可以保持数据的一致性和完整性。
Context
通过Context选项,您也可以传入Context来追踪 SQL操作,例如:
timeoutCtx, _ := context.WithTimeout(context.Background(), time.Second)
tx := db.Session(&Session{Context: timeoutCtx})tx.First(&user) // 带 timeoutCtx 的查询
tx.Model(&user).Update("role", "admin") // 带 timeoutCtx 的更新GORM也提供了快捷调用方法WithContext,其实现如下:
func (db *DB) WithContext(ctx context.Context) *DB {return db.Session(&Session{Context: ctx})
}context.Context来控制SQL操作的执行上下文。Context可以用于传递请求的元数据、控制取消操作、设置超时等。
使用Context控制SQL操作
通过在GORM会话中设置Context,你可以为数据库操作(如查询、更新等)设置超时限制或可取消的执行上下文。这对于构建需要响应快速和可控制数据库操作的应用程序非常有用。
示例解释
timeoutCtx, _ := context.WithTimeout(context.Background(), time.Second)
tx := db.Session(&Session{Context: timeoutCtx})context.WithTimeout(context.Background(), time.Second)创建了一个新的Context,它会在1秒后超时。这意味着任何使用这个Context的操作,如果在1秒内没有完成,就会被取消。
db.Session(&Session{Context: timeoutCtx})创建了一个新的GORM会话,并将带有超时设置的Context传入。这样,使用这个会话的所有数据库操作都会受到这个超时设置的约束。
tx.First(&user) // 带 timeoutCtx 的查询
tx.Model(&user).Update("role", "admin") // 带 timeoutCtx 的更新这些操作使用了设置了超时Context的会话tx。如果First查询或Update更新操作在超时时间内未能完成,操作将被取消,并返回一个错误。
WithContext快捷方法
GORM提供了WithContext方法,作为设置操作Context的快捷方式。
func (db *DB) WithContext(ctx context.Context) *DB {return db.Session(&Session{Context: ctx})
}WithContext方法接受一个context.Context作为参数,并返回一个新的GORM会话,这个会话的所有操作都会使用传入的Context。
这是一个便利方法,让你不必每次都创建一个新的Session实例来设置Context。
Logger
GORM允许使用Logger选项自定义内建Logger,例如:
newLogger := logger.New(log.New(os.Stdout, "\r\n", log.LstdFlags),logger.Config{SlowThreshold: time.Second,LogLevel: logger.Silent,Colorful: false,})
db.Session(&Session{Logger: newLogger})db.Session(&Session{Logger: logger.Default.LogMode(logger.Silent)})解读:
介绍了如何在GORM中通过Logger选项自定义内置的日志记录器。GORM的日志系统是一个灵活的组件,允许开发者根据需要调整日志输出的详细程度、格式以及其他配置,以适应不同的开发和生产需求。
自定义Logger
首先,示例展示了如何创建一个新的日志记录器并应用到GORM会话中:
newLogger := logger.New(log.New(os.Stdout, "\r\n", log.LstdFlags),logger.Config{SlowThreshold: time.Second,LogLevel: logger.Silent,Colorful: false,})
db.Session(&Session{Logger: newLogger})创建Logger:使用logger.New创建一个新的日志记录器实例。这里使用标准库log.New创建一个基础的Logger,输出到标准输出(os.Stdout),每条日志前有换行(\r\n),并使用标准的日志标志(log.LstdFlags)。
Logger配置:logger.Config允许你定制日志记录器的行为,包括:
SlowThreshold:设置慢查询的阈值。在这个例子中,任何执行时间超过1秒的查询都会被视为慢查询。
LogLevel:设置日志记录的级别。logger.Silent意味着不记录任何日志。
Colorful:设置日志输出是否使用颜色。false表示不使用颜色,使得日志输出更适合存储在文件中或查看在不支持颜色的环境里。
应用Logger到会话:通过db.Session(&Session{Logger: newLogger})将新创建的日志记录器应用到一个新的GORM会话中。
使用默认Logger设置日志模式
接下来,示例展示了如何使用GORM的默认日志记录器,但修改其日志模式为Silent,即不输出任何日志:
db.Session(&Session{Logger: logger.Default.LogMode(logger.Silent)})logger.Default.LogMode(logger.Silent):这调用了GORM默认日志记录器的LogMode方法,并将日志级别设置为Silent,从而创建了一个不输出日志的日志记录器实例。
应用到会话:通过db.Session将这个调整后的默认日志记录器应用到新的会话中。
NowFunc
NowFunc允许改变GORM获取当前时间的实现,例如:
db.Session(&Session{NowFunc: func() time.Time {return time.Now().Local()},
})解读:
自定义NowFunc:通过创建一个新的会话并设置NowFunc为一个匿名函数,该函数调用time.Now().Local()来获取当前的本地时间。
应用于会话:这个自定义的NowFunc随后应用于通过db.Session创建的新会话中。这意味着,在这个会话中,每当GORM需要获取“当前时间”时(比如自动设置CreatedAt或UpdatedAt字段值时),它将使用这个函数的返回值,而不是GORM默认的时间获取方式。
使用场景
自定义NowFunc在多种场景下都非常有用,例如:
测试:在单元测试或集成测试中,你可能需要控制时间的流逝,以测试时间相关的逻辑,如过期检查、定时任务等。通过自定义NowFunc,你可以让GORM使用固定的时间或根据测试需要变化的时间,而不是实际的当前时间。
时区处理:如果你的应用需要在特定的时区下处理时间,而不是使用服务器的本地时区或UTC,你可以通过NowFunc来确保GORM总是使用正确的时区。
时间模拟:在开发某些功能时,可能需要模拟时间向前或向后移动的效果。通过自定义NowFunc,你可以轻松实现这一点,而无需更改系统时间或使用复杂的时间管理逻辑。
Debug
Debug只是将会话的Logger修改为调试模式的快捷方法,其实现如下:
func (db *DB) Debug() (tx *DB) {return db.Session(&Session{Logger: db.Logger.LogMode(logger.Info),})
}GORM中Debug方法的工作原理。Debug方法是一个便捷方式,用于将数据库操作会话的日志级别设置为调试模式,以便能够输出更多的日志信息,帮助开发者在开发过程中调试和跟踪数据库操作。
Debug方法的实现
func (db *DB) Debug() (tx *DB) {return db.Session(&Session{Logger: db.Logger.LogMode(logger.Info),})
}方法签名:Debug是DB类型的一个方法,它返回一个新的DB实例(在这里用tx表示),这个新实例的日志级别被设置为调试模式。
创建新会话:通过调用db.Session(&Session{Logger: db.Logger.LogMode(logger.Info)}),Debug方法创建了一个新的GORM会话。这个新会话继承了原始db的所有设置,但它的Logger被设置为一个新的日志记录器实例,这个实例的日志模式被设置为logger.Info。
日志模式:虽然方法名是Debug,实际上这里使用的是logger.Info级别。这可能是为了示例简化,或者是要表达在这个上下文中,Info级别足以作为调试目的(通常,你可能期望使用logger.Debug级别来获取更详细的日志输出)。在实际应用中,如果需要更详细的日志,可以修改这部分以使用logger.Debug级别。
使用场景
在开发和调试阶段,你可能需要详细了解GORM执行的SQL语句和相关的操作细节。**使用Debug方法可以临时增加日志输出的详细程度,而不需要更改全局的日志配置。**这对于诊断问题和优化数据库操作非常有帮助。
QueryFields
db.Session(&gorm.Session{QueryFields: true}).Find(&user)
// SELECT `users`.`name`, `users`.`age`, ... FROM `users` // 带该选项
// SELECT * FROM `users` // 不带该选项解读:QueryFields是GORM提供的一个选项,当设置为true时,它会改变GORM生成的SQL查询的行为。具体来说,这个选项使GORM在构建SELECT语句时,明确指定要查询的字段名,而不是使用*来选择所有字段。
CreateBatchSize
users = [5000]User{{Name: "jinzhu", Pets: []Pet{pet1, pet2, pet3}}...}db.Session(&gorm.Session{CreateBatchSize: 1000}).Create(&users)
// INSERT INTO users xxx (需 5 次)
// INSERT INTO pets xxx (需 15 次)GORM中CreateBatchSize选项的使用,它允许在执行批量插入操作时,指定每批次插入记录的数量。通过这个选项,GORM可以将大量的插入操作分割成多个较小的批次,每个批次包含指定数量的记录,从而提高插入操作的效率和性能。
![[数学建模] 计算差分方程的收敛点](https://img-blog.csdnimg.cn/direct/d8a3b6f02852475294257906aad2eabe.png#pic_center)