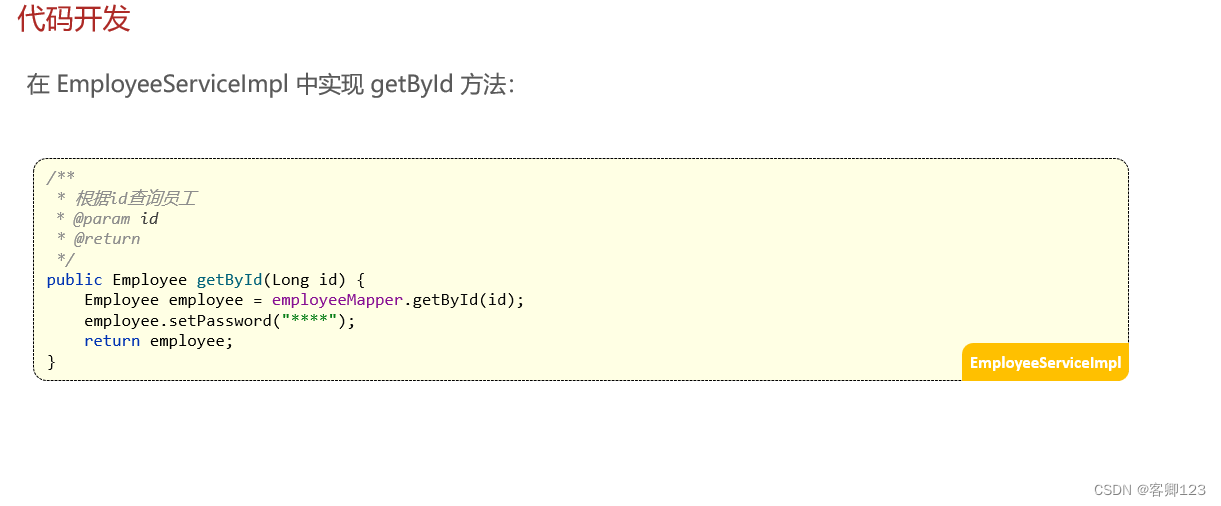
不同检索方式说明
最近在做搜索召回提升相关的研究工作。对比了稀疏检索和稠密向量检索的效果。其中使用的搜索引擎为elasticsearch8.x版本。稀疏检索包括BM25的检索方式,以及es官方在8.8之后版本提供的稀疏向量模型的方式。稠密向量检索,是指借助机器学习的模型做文本嵌入,然后用es8.x以后版本提供的向量检索。
测试数据说明
测试数据包括了中文和英文,涉及了法律和新闻数据。
一、先说结论
相比较BM25检索,借助机器学习模型做文本嵌入的向量检索方式,有不错的效果。
同时,ES的稀疏向量模型,在英文场景下,相比较BM25和向量检索,仍然取得了更好的召回率提升效果。
BM25和向量检索以及稀疏向量检索之间的关系?
从测试数据来看,三者之间是互补的。
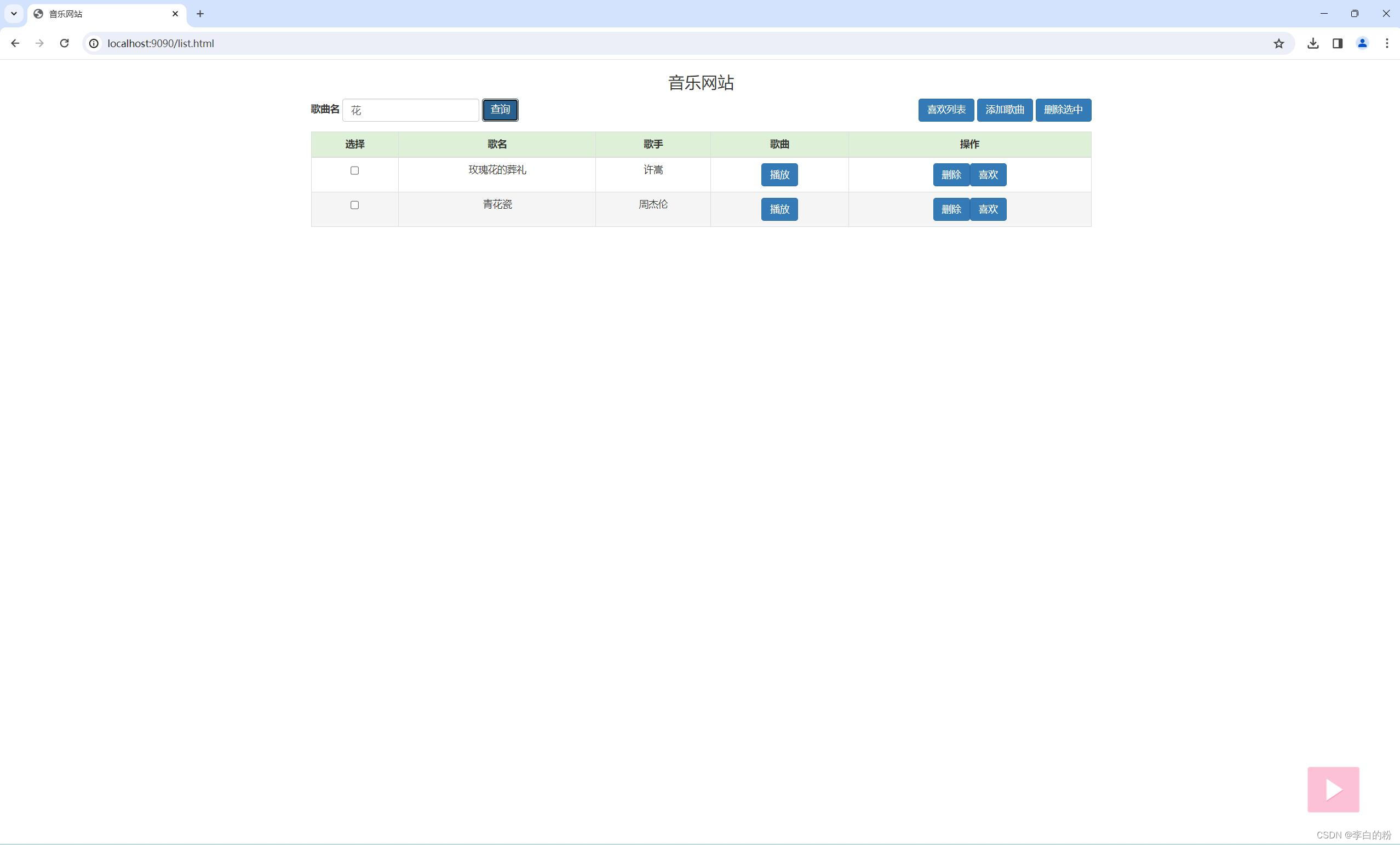
二、三种不同召回方式成功召回率对比效果
声明:这里取top50,如果命中标准答案则认为召回。
以一个测试集为例(法律数据),该测试集是有人工整理的198个问题,包含了问题和答案,相对质量较高。
在下图中,可以看到BM25成功召回177(89%)。

向量检索成功召回156个(79%)

稀疏向量成功召回187个( 94%)
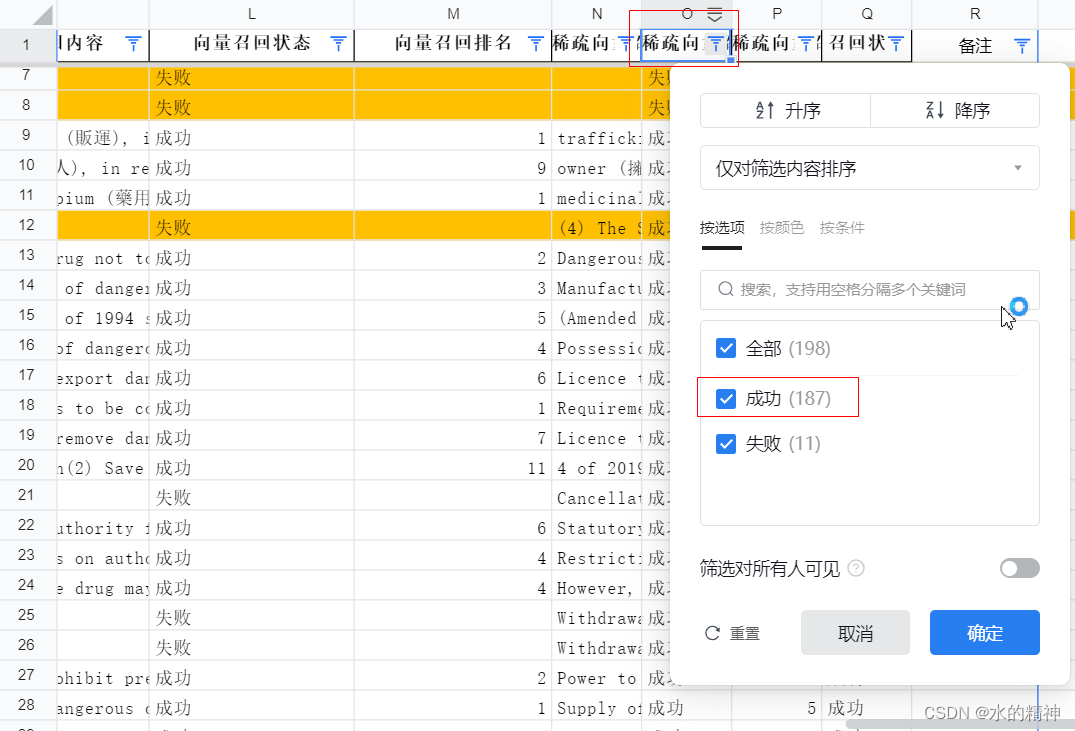
结论一:稀疏向量召回率 >BM25 > 稠密向量
只看每一种召回方式,召回效果。
稀疏向量成功召回187( 94%) > BM25 成功召回177(89%)> 稠密向量成功召回156 (79%)
请注意这个结论!!! 其中向量检索的效果,会和向量模型有着非常密切的关系,会和测试数据集有非常密切的关系。关于BM25的召回效果好于向量检索,我自己也是不认可的。请看结论四。
结论二:三者是可以互补的
再看三路混合检索整体的召回效果,成功召回189,召回率95%,整体大于任何一个单个检索方式。

结论三:BM25 和 稠密向量可以互补。
稀疏向量是收费才能使用的功能,且只针对英文效果出色。所以这里只看Bm25和稠密向量的方式。
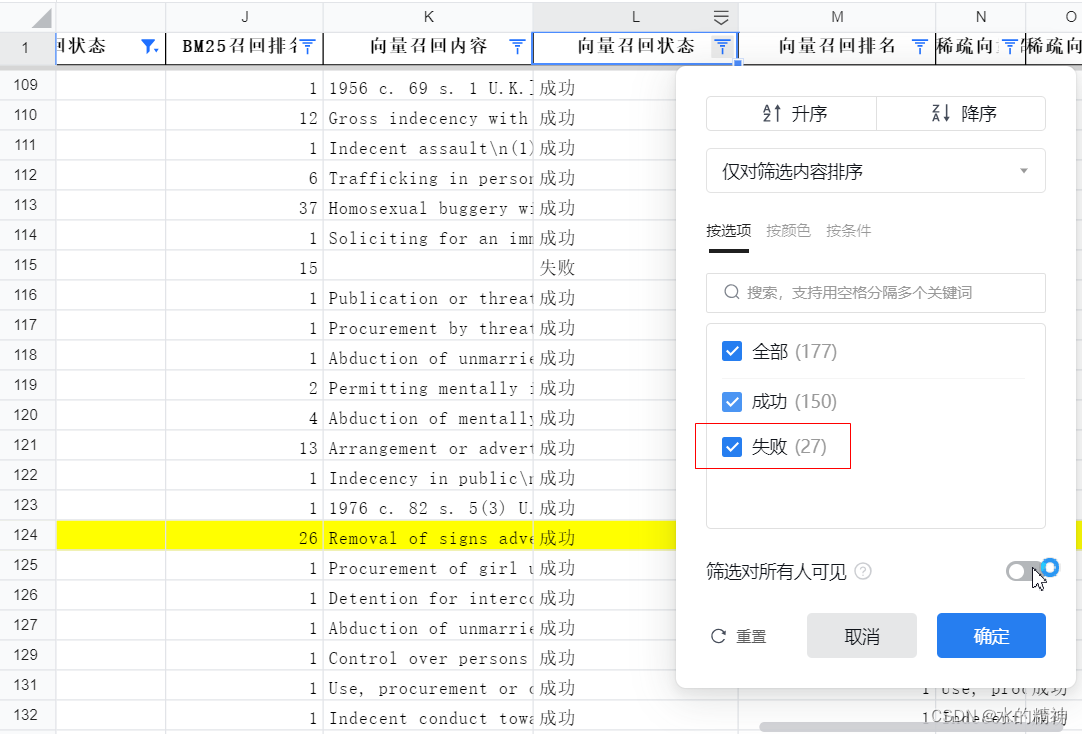
统计1:其中BM25召回成功的,向量检索召回失败的有27个。13%
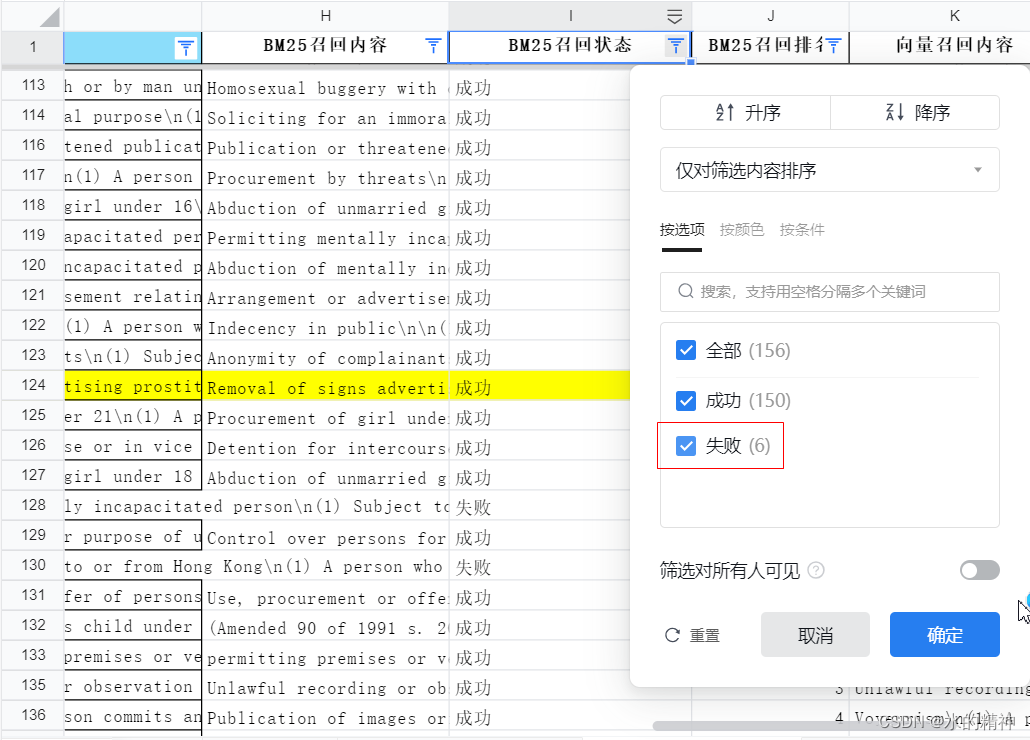
统计2:其中向量召回成功,但是BM25召回失败的有6个。3%
结论四:BM25是否真的好于向量检索?
其中向量检索,严重依赖外部的文本嵌入的模型,假如模型没有训练过某个领域的知识,则在向量embedding过程中,一定会都是语义,所以效果表现不佳,甚至是低于Bm25的召回效果。
于是又对比了不同的测试数据集: 这次是中文的新闻数据。共1704个case。向量召回率98% >bm
25召回率 95%
即使这样,我依然无法下一个结论说向量检索效果比BM25好,或者说差。还是取决于文本嵌入模型的能力,以及测试集样本。但是总是可以得出,而知没有绝对的谁领先,而是互补,1+1 >2的效果!
其中BM25 成功召回 1619,召回率95%。
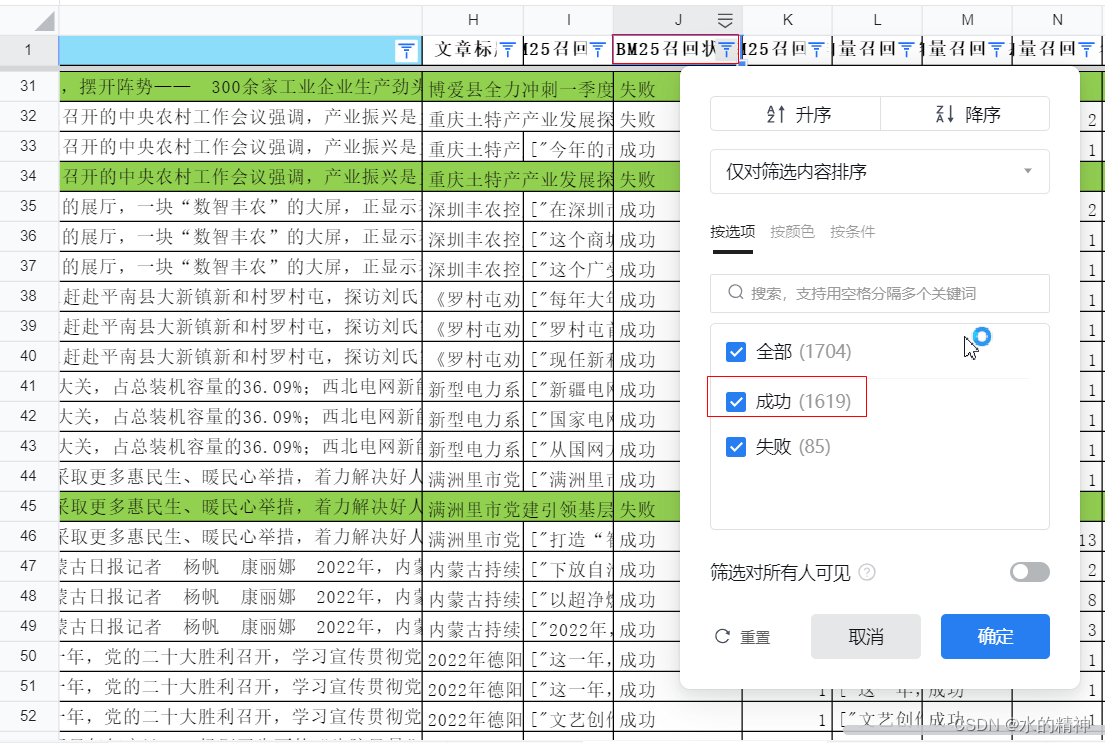
其中向量 成功召回 1675,召回率98.2%。

整体召回率,98.8%。两者可以互补的结论依然成立。
三、稀疏向量的提升效果
在英文场景下,稀疏向量的召回率相比较BM25,提升明显!提升到了100%,提升了14%

topK召回率有很大提升,top1提升了31%,top5提升了28.5%,top10提升了22%


四、应该如何选用召回方式
其中Bm25 是花费资源最少得检索方式。向量检索是花费资源最多的方式,因为要使用模型,其并发能力会受到资源限制。稀疏向量需要依赖官方提供的模型,是收费的功能,并且价格昂贵,且只支持英文场景,无法做多语言的混合场景,亲测中英混合的情况下,效果下降明显。