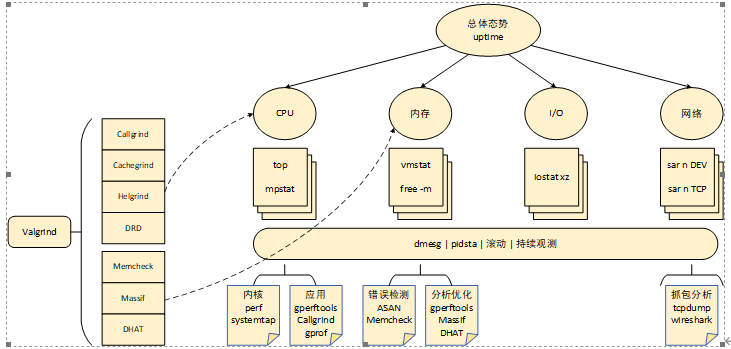
Linux性能分析大师Brendan Gregg有一篇非常著名的博客,介绍在性能分析开始的60秒内,利用标准的Linux命令行工具,执行一次充分的性能检查,获得系统资源利用率和进程运行情况的整体概念,查看是否存在异常、评估饱和度。本文在大师的肩上进一步扩展,根据实际工作经验介绍几款工具,可以在定位到程序性能问题之后,进一步详细分析解决问题,故名Linux程序性能分析60秒+。
本文不介绍相关软件安装和详细使用,只介绍基本用法,作为快速检查单使用。
01 60秒速查指令
运行以下10个命令,可以在60秒内,快速获得系统资源利用率和进程运行情况的整体概念。查看是否存在异常、评估饱和度。
-
uptime

可以快速查看平均负载的指令,表示等待运行的任务(进程)数量。在Linux系统中,这些数字包含等待CPU运行的进程数,也包括不间断I/O阻塞的进程数(通常是磁盘I/O)。系统平均负载高,可能是由于CPU密集型程序导致,也可能是I/O密集型程序导致。
命令的输出分别表示 1 分钟、5 分钟、15 分钟的平均负载情况。通过这三个数据,可以了解负载是在趋于紧张还是缓解,亦或稳定。如果负载紧张,则需要下文指令进一步分析。
-
dmesg | tail

该命令可以查看最近10条系统消息(如果有)。查找可能导致性能问题的错误。上面的示例包括oom-killer和TCP丢弃请求。不要错过这一步!dmesg 总是值得检查。这些日志可以帮助排查性能问题。
-
vmstat

该命令每行会输出一些系统核心指标,这些指标可以让我们更详细的了解系统状态。后面跟的参数1,表示每秒输出一次统计信息,表头提示了每一列的含义,这里介绍一些和性能调优相关的列:
-
r:等待在CPU资源的进程数量。这个数据比平均负载更加能够体现CPU负载情况,数据中不包含等待IO的进程。如果这个数值大于机器CPU核数,那么机器的CPU资源已经饱和;
-
free:系统可用内存数(以千字节为单位),如果剩余内存不足,也会导致系统性能问题。下文介绍到的free命令,可以更详细的了解系统内存的使用情况;
-
si, so:交换区写入和读取的数量。如果这个数据不为0,说明系统已经在使用交换区(swap),机器物理内存已经不足;
-
us, sy, id, wa, st:这些都代表了CPU时间的消耗,它们分别表示用户时间(user)、系统(内核)时间(sys)、空闲时间(idle)、IO等待时间(wait)和被偷走的时间(stolen,一般被其他虚拟机消耗);
上述这些CPU时间,可以让我们快速了解CPU是否处于繁忙状态。一般情况下,如果用户时间和系统时间相加非常大,CPU忙于执行指令。如果IO等待时间很长,那么系统的瓶颈可能在磁盘IO。示例命令的输出可以看见,大量 CPU时间消耗在用户态,也就是用户应用程序消耗了CPU时间。但这不一定是性能问题,需要结合r队列,一起分析。
-
mpstat -P ALL 1

该命令可以显示每个CPU的占用情况,如果有一个CPU占用率特别高,那么有可能是一个单线程应用程序引起的。
-
pidstat 1

pidstat命令输出进程的CPU占用率,该命令会持续输出,并且不会覆盖之前的数据,可以方便观察系统动态。
-
iostat -xz 1

iostat命令主要用于查看机器磁盘IO情况。该命令输出的列,主要含义是:
-
r/s, w/s, rkB/s, wkB/s:分别表示每秒读写次数和每秒读写数据量(千字节)。读写量过大,可能会引起性能问题;
-
await:IO操作的平均等待时间,单位是毫秒。这是应用程序在和磁盘交互时,需要消耗的时间,包括IO等待和实际操作的耗时。如果这个数值过大,可能是硬件设备遇到了瓶颈或者出现故障;
-
avgqu-sz:向设备发出的请求平均数量。如果这个数值大于1,可能是硬件设备已经饱和(部分前端硬件设备支持并行写入);
-
%util:设备利用率。这个数值表示设备的繁忙程度,经验值是如果超过60,可能会影响IO性能(可以参照IO操作平均等待时间)。如果到达100%,说明硬件设备已经饱和;
如果显示的是逻辑设备数据,那么设备利用率不代表后端实际的硬件设备已经饱和。值得注意的是,即使IO性能不理想,也不一定意味应用程序会出现性能问题,可以利用诸如预读取、写缓存等策略提升应用性能。
-
free –m

free 命令可以查看系统内存的使用情况,-m参数表示按照兆字节展示。最后两列分别表示用于IO缓存的内存数,和用于文件系统页缓存的内存数。需要注意的是,第二行-/+buffers/cache,看上去缓存占用了大量内存空间。这是Linux系统的内存使用策略,尽可能的利用内存,如果应用程序需要内存,这部分内存会立即被回收并分配给应用程序。因此,这部分内存一般也被当成是可用内存。如果可用内存非常少,系统可能会动用交换区(如果配置了的话),这样会增加 IO 开销(可以在 iostat 命令中体现),降低系统性能。
-
sar -n DEV 1

sar命令在这里可以查看网络设备的吞吐率。在排查性能问题时,可以通过网络设备的吞吐量,判断网络设备是否已经饱和。如示例输出中,eth0网卡设备,吞吐率大概在22Mbytes/s,即176Mbits/sec,没有达到1Gbit/sec的硬件上限。
-
sar -n TCP,ETCP 1

sar 命令在这里用于查看 TCP 连接状态,其中包括:
-
active/s:每秒本地发起的 TCP 连接数,既通过 connect 调用创建的 TCP 连接;
-
passive/s:每秒远程发起的 TCP 连接数,即通过 accept 调用创建的 TCP 连接;
-
retrans/s:每秒 TCP 重传数量;
TCP连接数可以用来判断性能问题是否由于建立了过多的连接,进一步可以判断是主动发起的连接,还是被动接受的连接。TCP 重传可能是因为网络环境恶劣,或者服务器压力过大导致丢包。
-
top

top命令包含了前面好几个命令的检查的内容。比如系统负载情况(uptime)、系统内存使用情况(free)、系统 CPU 使用情况(vmstat)等。因此通过这个命令,可以相对全面地查看系统负载的来源。同时,top命令支持排序,可以按照不同的列排序(按键M,内存排序显示;按键P,CPU排序显示),方便查找出诸如内存占用最多的进程、CPU 占用率最高的进程等。但是,top命令相对于前面一些命令,输出是一个瞬间值,如果不持续观察,可能会错过一些线索。这时可能需要暂停 top 命令刷新,来记录和比对数据。
相关视频推荐
linux操作系统入门到精通全套教程(含pdf文档),linux小白、linux零基础也能快速学会![]() https://www.bilibili.com/video/BV1Sg4y1X7Ap/
https://www.bilibili.com/video/BV1Sg4y1X7Ap/
Linux C/C++开发(后端/音视频/游戏/嵌入式/高性能网络/存储/基础架构/安全)
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
02 60秒+分析工具
上述指令可以快速分析系统、程序是否存在异常,但是有了问题之后更要解决问题,使用下面的各项工具可以详细分析问题,进而解决问题。下述各项工具基本都是在开发阶段使用,为了更好的定位问题,保证分析工具生成数据准确,建议编译选项添加如下设置,保留调试信息和保留帧栈指针。下文设置编译选项时不再单独说明。
-fno-omit-frame-pointer -gCPU问题分析
CPU问题主要表现在程序CPU占用高,要解决CPU占用高问题,需要对程序热点函数进行统计分析。根据内核程序和应用程序区分,分别有以下工具。内核工具可以使用在应用上,反之则否。
-
内核程序CPU分析工具:
perfperf命令(performance 的缩写),是Linux系统提供的性能分析工具集,包含多种子工具,能够监测多种硬件及软件性能指标,包括cpu、内存、io等,这些可监测指标我们称为event。Brendan Gregg的文章中总结了perf 支持的event结构图,详情可见:
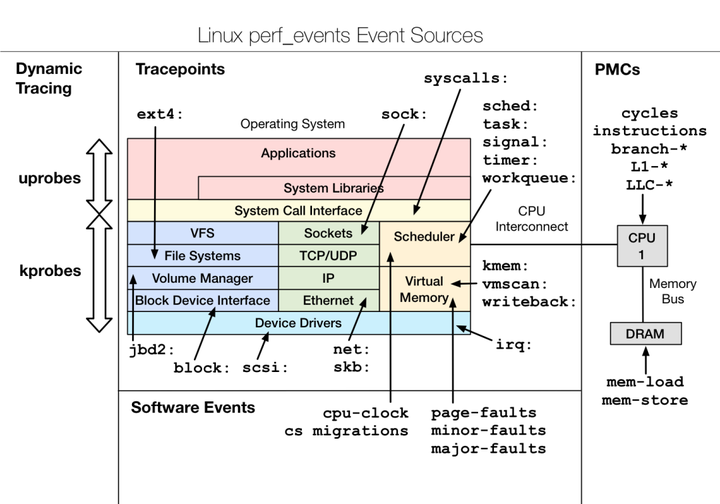
perf基本使用指令如下:
perf top
perf top类似top命令,主要用于实时分析各个函数在某个性能事件上的热度,能够快速定位热点函数,包括应用程序函数、模块函数与内核函数,甚至能够定位到热点指令。执行需要root权限。
perf top -K -g -p [PID]perf recordperf record是采样模式,perf收集采样信息并记录在文件中,可以离线分析。默认生成perf.data分析数据。
perf record -F 999 -g -p [PID] --sleep 30perf report & perf script
perf report主要用来分析上面perf record生成的perf.data文件。一般通过perf report分析的结果不直观,所以使用perf script将perf.data输出可读性文本,配合火焰图分析。火焰图工具地址:
https://github.com/brendangregg/FlameGraph.git
执行指令:
perf record -F 999 -g -p [PID] --sleep 30
perf script -i perf.data &> perf.unfold
FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded
FlameGraph/flamegraph.pl perf.folded > psystemtap
systemtap可以动态hook内核代码,其底层就是使用的kprobe接口。systemtap在kprobe的基础上,加上脚本解析和内核模块编译运行单元,使开发人员在应用层即可实现hook内核,简化了动态跟踪开发流程。工作原理是通过将脚本语句翻译成C语句,编译成内核模块。模块加载之后,将所有探测的事件以钩子的方式挂到内核上,当任何处理器上的某个事件发生时,相应钩子上句柄就会被执行。最后,当systemtap会话结束之后,钩子从内核上取下,移除模块。整个过程用一个命令stap就可以完成。systemtap的核心思想是定义一个事件(event),以及给出处理该事件的句柄(Handler)。当一个特定的事件发生时,内核运行该处理句柄,就像快速调用一个子函数一样,处理完之后恢复到内核原始状态。编写systemtap脚本就是一个找到符合需求的事件,并编写事件处理流程的过程。具体语法不再细述,下图是整体架构图。
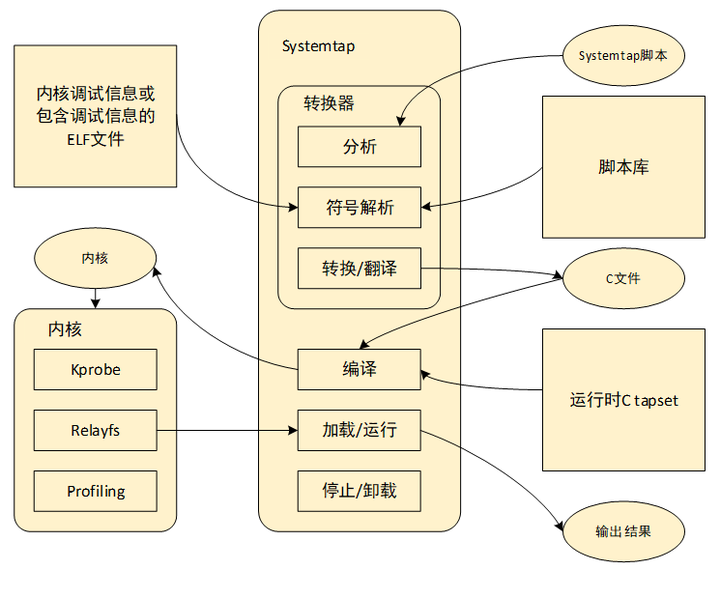
-
应用程序CPU分析工具:
gperftools
gperftools是一套Google开源的基于TCMalloc的性能分析、内存检测工具集。主要包含以下几个工具:pprof、TCMalloc、heap-checker、heap-profiler、cpu-profiler,cpu分析使用cpu-profiler。使用gperftools cpu-profiler可以实现非重新编译应用程序的CPU分析,使用指令如下,其中LD_PRELOAD需要填写libprofiler.so实际位置。
LD_PRELOAD="/usr/lib/libprofiler.so" CPUPROFILE=[name].prof ./[bin同样可以在编译时链接libprofiler.so,编译完成之后执行如下指令分析程序。
env CPUPROFILE=[name].prof [bin]在正常运行工具一段时间后,程序路径下会生成分析数据[name].prof。CPU的性能分析和优化都是基于对这些文件的分析。使用pprof工具解析数据,其中--text可以替换为--pdf、--dot生成图形分析结果。
pprof --text ./[bin] --lib_prefix=/usr/local/lib64,/usr/local/lib [name].prof > [name].txtpprof --pdf ./[bin] [name].heap > [name].pdfpprof --dot ./[bin] [name].heap > [name].dot
dot -Tsvg -Kfdp [name].dot -o [name].svggprof
gprof(GNU profiler)是GNU binutils工具集中的自带工具。如果使用GCC编译器,可以使用它分析程序性能:函数调用时间、调用次数和调用关系,找出程序的瓶颈所在。
使用gprof分析程序性能,需要在编译的时候添加-pg编译选项。
典型的GCC编译指令如下:
gcc -pg -o test test.c如果使用CMake,指令如下:
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -pg")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -pg")正常执行编译后的可执行程序,如果生成gmon.out文件,说明gprof正常运行。这个文件就是记录程序运行的性能、调用关系、调用次数等信息的数据文件。使用gprof命令来分析记录程序运行信息的gmon.out文件。
gprof ./[bin] gmon.out > [name].txt如果只是单纯的看TXT分析结果,对于一些大型程序还是不直观,所以可以使用gprof2dot.py工具将TXT转换成DOT,然后再转换成图片。gprof2dot.py工具地址:
https://github.com/jrfonseca/gprof2dot.git使用如下命令:
gprof2dot.py -n0 -e0 -s -w [name].txt > [name].dot
dot -Tpng [name].dot -o [name].pngvalgrind->Callgrind
valgrind是一套Linux下,开放源代码(GPL V2)的仿真调试工具的集合。valgrind由内核(core)以及基于内核的调试工具组成。内核类似于一个框架(framework),它模拟了一个CPU环境,并提供服务给其它工具;而其它工具则类似于插件 (plug-in),利用内核提供的服务完成各种特定的调试分析任务。

valgrind有一系列工具组成,作用分别如下。
-
Memcheck:内存检查器,能够发现开发中绝大多数内存错误使用情况,比如:使用未初始化的内存,使用已经释放了的内存,内存访问越界等;
-
Callgrind:它主要用来检查程序中函数调用过程中出现的问题,分析热点函数,函数调用流程;
-
Cachegrind:它主要用来检查程序中缓存使用出现的问题;
-
Helgrind:它主要用来检查多线程程序中出现的竞争问题;
-
Massif:它主要用来检查程序中堆栈使用中出现的问题;
-
DRD:它用于检测多线程C和C++程序中错误的工具。该工具适用于任何使用POSIX线程原语或使用在POSIX线程基元之上构建的线程概念的程序;
-
DHAT:它是一个用于检查程序如何使用堆分配的工具。它跟踪分配的内存块,并检查每次内存访问;
CPU分析主要使用Callgrind,使用指令如下,[bin]是需要分析的程序。
valgrind --tool=callgrind ./[bin]执行完毕后,就会在当前目录下生成一个文件,文件名为“callgrind.out.进程号”。如果调试的程序是多线程,也可以在命令行中加一个参数 -separate-threads=yes。这样就会为每个线程单独生成一个性能分析文件。如下:
valgrind --tool=callgrind --separate-threads=yes ./[bin]可以使用gprof2dot.py脚本,把Callgrind生成的性能分析数据转换成dot格式的数据,方便使用dot把分析数据图形化。
python gprof2dot.py -f callgrind -n10 -s callgrind.out.31113 > valgrind.dot
dot -Tpng valgrind.dot -o valgrind.png也可以使用kcachegrind软件分析Callgrind生成的数据,基于图形化的界面,可以针对函数搜索分析。
-
使用建议
如果是调试内核程序,那可以优先使用perf初步定位问题,然后再根据实际分析结果确认是否还需要使用systemtap;如果是应用程序,可以使用perf初步定位问题,然后可以使用gperftools详细分析CPU占用,如果需要进一步分析优化多线程,可以使用valgrind->Callgrind或者Helgrind。valgrind基于模拟器实现,运行速度非常缓慢,而gpertools在用户代码嵌入代码实现,相对较快。内存问题分析内存问题可以分为两大类,一种是内存错误,比如内存访问越界、内存泄漏;一种是内存占用,在实际产品设备上,需要尽量减少内存占用以减低产品成本。所以工具对应的也可以分为两类:内存错误检测工具、内存占用分析工具。
-
内存错误检测工具
ASAN
ASAN(Address Sanitizer)是Google开源的针对C/C++的快速内存错误检测工具,在运行时检测C/C++代码中的多种内存错误。ASAN已经在GCC(>4.8版本以上)和Clang编译器内置支持。
使用ASAN时,需要添加编译选项-fsanitize=address,然后执行程序。如果程序存在上述内存错误,在检测出来第一个错误时程序便会终止,同时打印错误信息。如果每次出现错误便终止程序,调试起来效率不高,所以更常规的用法是,设置程序一直执行,然后将检测出来的错误打印到日志文件中。方法如下。
-
添加编译选项:-fsanitize=address、-fsanitize-recover=address;
-
在程序运行时使用环境变量控制:
export ASAN_OPTIONS=halt_on_error=0:log_path=err.log
./[bin]Valgrind->Memcheck
使用valgrind->Memcheck也可以检测程序内存错误,但是执行速度会很慢。如果编译器不支持ASAN,可以使用该工具完成内存错误检测。使用指令如下,在生成的日志文件中会提示检测出来的内存错误。
valgrind --tool=memcheck --leak-check=full --show-leak-kinds=all --trace-children=yes --log-file=debug.txt ./[bin]-
使用建议
内存检测工具还有很多,可以检测的内存错误对比如下。对比可以看出,ASAN和Memcheck支持检测的内存错误最多,且ASAN是编译器支持的检测工具,所以在开发阶段,可以优先使用ASAN完成程序内存错误检测,如果编译器不支持ASAN,则可以使用Memcheck。

-
内存占用分析工具
gperftools
gperftools->heap-profiler可以分析内存占用,在程序执行时生成分析数据,然后可以分析程序内存占用,定位内存占用的大头。
使用gperftools heap-profiler可以实现非重新编译应用程序的内存分析,使用指令如下,其中LD_PRELOAD需要填写libtcmalloc.so实际位置。
LD_PRELOAD="/usr/lib/libtcmalloc.so" HEAPPROFILE=heap.hprof ./[bin]同样可以在编译时链接libtcmalloc.so,编译完成之后执行如下指令分析程序。
env HEAPPROFILE=heap.hprof ./[bin]在程序路径下会生成分析数据,类似[name].0001.heap。同样使用pprof分析数据,--text可以替换为--pdf、--dot。
pprof --text ./[bin] [name].0001.heappprof --pdf ./[bin] [name].heap > [name].pdfpprof --dot ./[bin] [name].heap > [name].dot
dot -Tsvg -Kfdp [name].dot -o [name].svgValgrind->Massif
valgrind->Massif支持堆内存分析,分析内存占用大头,基本使用如下。
valgrind --tool=massif ./[bin]在程序执行目录下会生成类似massif.out.1204的分析文件。使用massif-visualizer可以加载分析数据,生成图形化的分析结果。
Valgrind->DHAT还可以使用valgrind->DHAT进一步详细分析堆内存,但是除了申请和释放,堆空间还有其他问题,比如堆空间的使用率、使用周期等。通过分析这些问题,可以对程序代码进行优化以提高性能。Massif只支持内存申请和释放分析,而DHAT可以分析堆内存使用效率,避免过度分配而导致的内存浪费或者无用的内存分配。基本使用如下,根据Valgrind版本不同,--tool可能设置为dhat,具体可以查看对应版本的使用说明。生成的log文件会记录200个(--show-top-n参数设置)内存分析点数据,说明该处内存分配的大小和使用率。
valgrind --tool=exp-dhat --trace-children=yes --show-top-n=200 --log-file=dhat.log ./[bin]-
使用建议
在程序开发过程中,应当首先使用内存错误检测工具保证没有内存错误,然后在功能开发基本完成时,使用内存占用分析工具优化内存占用。内存分析占用可以优先使用gperftools完成大块内存的定位分析,然后再使用DHAT进一步分析内存使用效率,确定优化方案。
网络问题分析网络涉及到多层和多种协议,所以针对具体的网络层和网络协议需要具体分析,最常用的分析工具主要是tcpdump和wireshark,一般在设备上使用tcpdump抓取网络包,然后在开发环境下使用wireshark图形化界面分析数据。
tcpdump
tcpdump可以将网络中传送的数据包完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助去掉无用的信息,参数设置说明可以参考下图。

简单使用指令示例如下,抓取eth0网卡且目的地址是192.168.1.100的数据包,保持在data.pcap数据中。
tcpdump -i eth0 dst 192.168.1.100 -w data.pcapwireshark
wireshark功能与tcpdump类似,但是有图形化操作界面,可以使用tcpdump抓取数据,wireshark详细分析数据。
每种工具都有各自的使用场景和优缺点,需要根据具体问题选择合适的工具,下图可以作为使用参考。