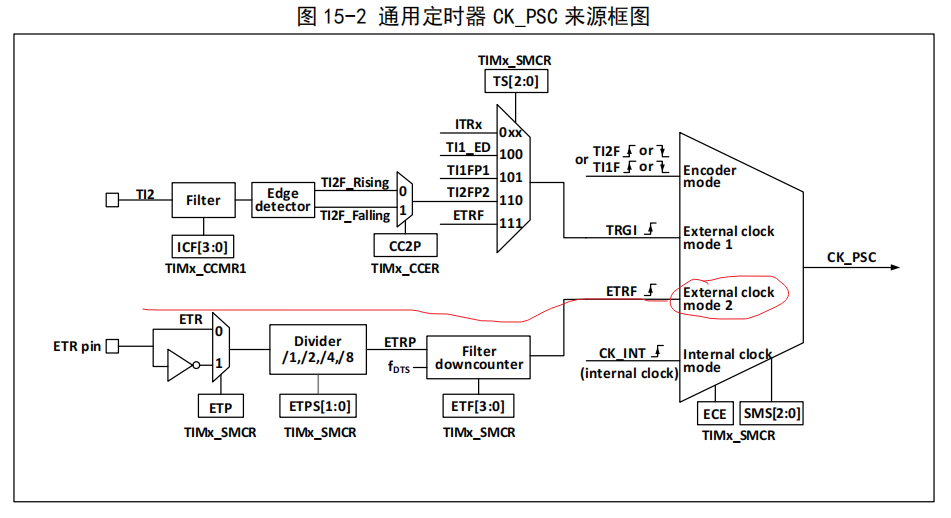
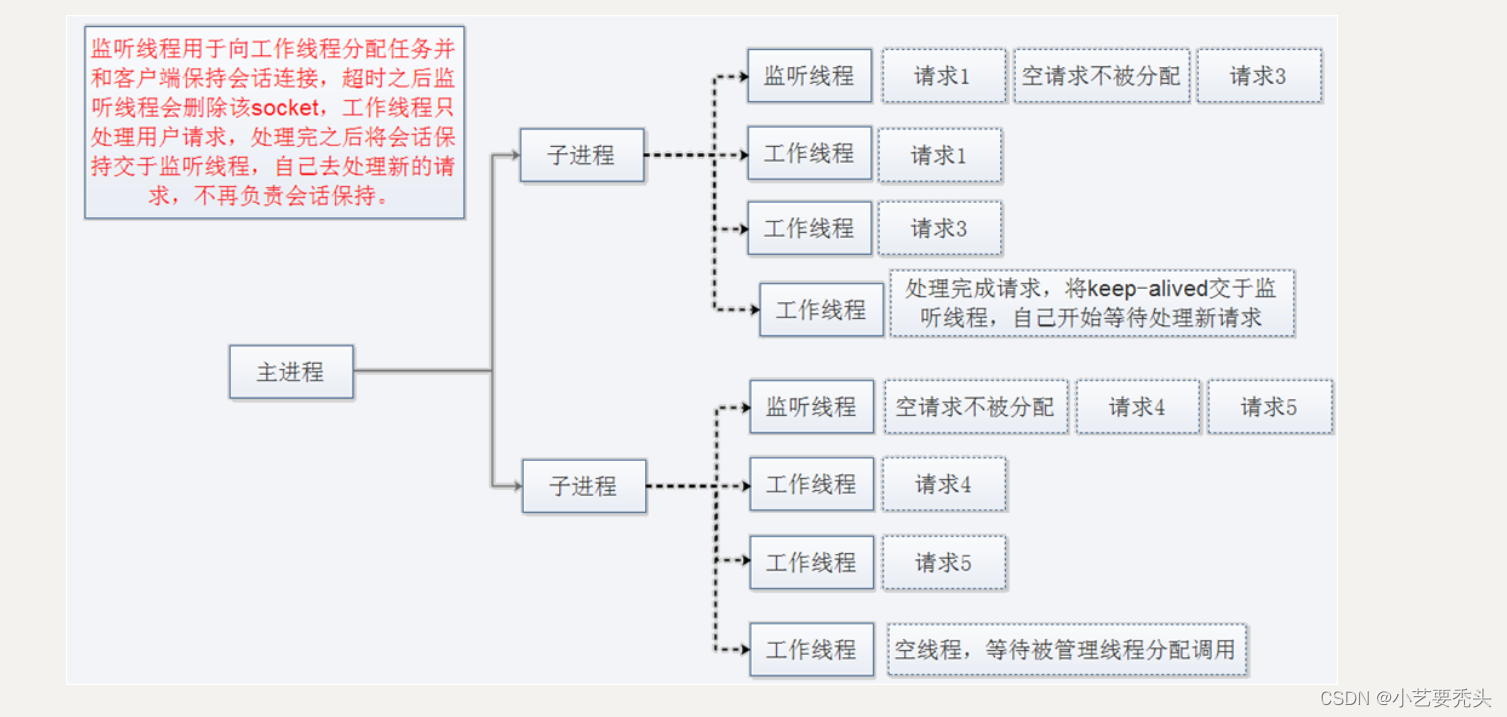
1.来自普林斯顿大学的研究团队及其合作者提出了 TutorEval 和 TutorChat。TutorEval 是首个结合了长上下文、自由形式生成和跨学科科学知识的基准,它有助于衡量 LMs 作为科学助手在现实生活中的可用性。TutorChat 是一个包含 80000 篇关于教科书的长篇合成对话的数据集,用于对带有 7B 和 34B 参数的 Llemma 模型进行微调。
论文链接:
https://arxiv.org/abs/2402.11111
项目地址:
https://github.com/princeton-nlp/LM-Science-Tutor
2.来自南洋理工大学、清华大学、微软公司、加州大学和新加坡管理大学的研究团队提出了一种新的任务设置——工具增强的科学推理。它利用可扩展的工具集对大模型进行补充。研究团队构建了一个包含超过 30000 个样本和大约 6000 种工具的名为 MathFunc 的工具增强训练语料库,并在其基础上开发了 SciAgent,用于检索、理解并在必要时使用工具解决科学问题。
论文链接:
https://arxiv.org/abs/2402.11451
3.来自复旦大学的研究团队提出了一种基于多智能体协作的方法——LongAgent,它可以将 LLMs(如 LLaMA)扩展到 128K 的上下文。LongAgent 为长文本处理提供了新的选择。与 GPT-4 相比,使用 LLaMA-7B 的智能体团队在 128k 长文本检索、多跳问答等任务中取得了显著改进。
论文链接:
https://arxiv.org/abs/2402.11550
4.来自复旦大学、Multimodal Art Projection(MAP)和上海人工智能实验室的研究团队提出了一种任意对任意(any-to-any)的多模态语言模型——AnyGPT,它利用离散表示统一处理包括语音、文本、图像和音乐在内的各种模态。
论文链接:
https://arxiv.org/abs/2402.12226
项目地址:
https://junzhan2000.github.io/AnyGPT.github.io/
5.来自不列颠哥伦比亚大学和 Invertible AI 的研究团队提出了一套基于 Mistral-7b 模型构建的、为金融分析定制的最新多模态大型语言模型(LLMs)——FinTral。FinTral 模型采用先进的工具和检索方法进行直接偏好优化训练,显示出卓越的零样本性能,它在所有任务中的表现都优于 ChatGPT-3.5,并在九个任务中的五个任务中超过了 GPT-4。
论文链接:
https://arxiv.org/abs/2402.10986
6.由于训练数据中英语语料库的主导地位,大型语言模型(LLMs)倾向于偏重某些文化。来自微软公司和中科院软件研究院的研究团队提出了一种将文化差异纳入 LLM 的经济高效的解决方案——CultureLLM。在 60 个与文化相关的数据集上进行的广泛实验表明,CultureLLM 的性能明显优于 GPT-3.5 (高出8.1%)和 Gemini Pro(高出9.5%)等同类产品,并与 GPT-4 的性能相当甚至更好。
论文链接:
https://arxiv.org/abs/2402.10946
7.Google DeepMind 提出了对机器人代码编写 LLMs 进行微调来记住它们在上下文中的交互,并提高它们的可教性——它们适应人类输入的效率(以用户认为任务成功之前的平均修正次数来衡量)。
论文链接:
https://arxiv.org/abs/2402.11450
项目地址:
https://robot-teaching.github.io/
8.自然界是无限分辨率的。现有的扩散模型(如Diffusion Transformers)在处理其训练领域之外的图像分辨率时往往面临挑战。为此,来自上海人工智能实验室的研究团队及其合作者提出了一个专门用于生成无限制分辨率和长宽比图像的 Transformer 架构——Flexible Vision Transformer(FiT)。
论文链接:
https://arxiv.org/abs/2402.12376
项目地址:
https://github.com/whlzy/FiT
9.来自清华大学、密西根大学和香港大学的研究团队提出了一个基于现有心理理论的基准——EmoBench。EmoBench 包括一套 400 道人工精心设计的中英文问题。研究表明,现有 LLMs 的情感指数与普通人之间存在相当大的差距。
论文链接:
https://arxiv.org/abs/2402.12071
项目地址:
https://github.com/Sahandfer/EmoBench