目录
- 1.SparkSQL特点
- 1.1易整合
- 1.2统一的数据访问
- 1.3兼容Hive
- 1.4标准的数据连接
- 2 SparkSQL编程模型=DataFrame=DataSet
- 2.1 SQL
- 2.2 DataFrame是什么
- 2.3 DataSet是什么
- 2.4 RDD,DataSet,DataFrame
- 3 SparkSQL核心编程
- 3.1 编程入口
- 3.2 SparkSQL基本编程
- 3.2.1编程入口SparkSession
- 3.2.2 DSL语法 -->结合SQL中关键字作为函数(算子)的名字传递参数进行编程方式-->接近于RDD编程
- 3.2.3 导入SparkSession中隐式转换操作,增强sql功能
- 3.2.4 SQL语法 -->直接写SQL或者HQL语言进行编程【算是SparkSQL主流】
SparkSQL是Spark用于结构化数据处理的Spark模块,是Spark生态体系中的构建在SparkCore基础之上的一个基于SQL的计算模块,不依赖于Hive。
SparkSQL与基本的SparkRDDAPI不同,SparksQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。在内部,SparkSQL使用这些额外的信息来执行额外的优化。有几种与SparkSQL交互的方法,包括SQL和DatasetAPI。计算结果时,将使用相同的执行引擎,这与用于表示计算的API/语言无关。这种统一意味着开发人员可以轻松地在不同的API之间来回切换,基于API的切换提供了表示给定转换的最自然的方式
- 结构化数据是什么?
存储在关系型数据库中的数据,就是结构化数据。 - 半结构化数据是什么?
类似xml、json等的格式的数据被称之为半结构化数据。 - 非结构化数据是什么?
音频、视频、图片等为非结构化数据。
换句话说,SparkSQL处理的就是【二维表数据】。
1.SparkSQL特点
1.1易整合

1.2统一的数据访问
使用相同的连接方式连接不同的数据源

1.3兼容Hive
在已有的仓库上直接运行SQL或HQL

1.4标准的数据连接
采用JDBC或者ODBC直接连接

2 SparkSQL编程模型=DataFrame=DataSet
- 通过两种方式操作SparkSQL,一种就是SQL,一种就是DataFrame和DataSet。
2.1 SQL
SQL操作的是表,所以要想用SQL进行操作,就需要把SparkSQL对应的编程模型转化为一张表才可以。
2.2 DataFrame是什么
在Spark中, DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SOL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD, 由于无从得知所存数据元素的具体内部结构,SparkCore只能在stage层面进行简单、通用的流水线优化。
同时,与Hive类似,DataFrame也支持嵌套数据类型struct、array和map)。从API易用性的角度上看,DataFraneAPI提供的是一套高层的关系操作,比函数式的RDDAPI要更加友好,门槛更低。
RDD也是一张的二维表,不过没有表头,表名,字段,字段类型等信息。
DataFrame和DataSet是含有表头,表名,字段,字段类型的一张mysql中的二维表。
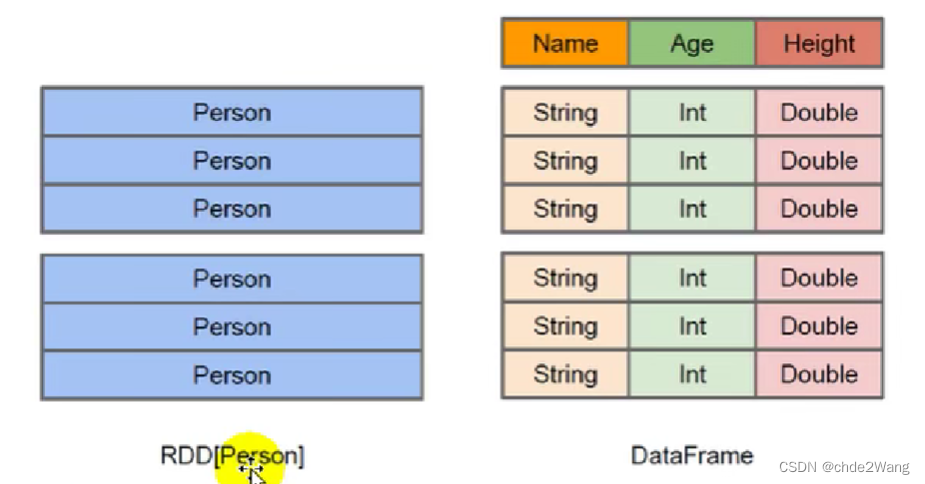
左侧的RDD[Person]虽然以Person为类型参数,但Spak框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL 可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。
2.3 DataSet是什么
DataSet是分布式数据集合。DataSet是Spark1.6中添加的一个新抽象,是DataFrame的一个扩展。它提供了RDD的优势(强类型,使用强大的lambda函数的能力)以及SparkSQL优化执行引擎的优点。DataSet也可以使用功能性的转换(操作map, fatMap, filter等等)。
- DataSet是DataFrameAPI的一个扩展,是SparkQL最新的数据抽象
- 用户友好的API风格,既具有类型安全检查也具有DataFrame的查询优化特性;
- 用样例类来对DataSet中定义数据的结构信息,样例类中每个属性的名称直接映射到DataSet中的字段名称;
- DataSet是强类型的。比如可以有DataSet[Car], DataSet[Person]
- DataFrame是DataSet的特列,DataFrame=DataSet[Row],所以可以通过as方法将DataFrame转换为DataSet。Row是一个类型,跟Car、Person这些的类型一样,所有的表结构信息都用Row来表示。获取数据时需要指定顺序。
一般的,将RDD称之为Spark体系中的第一代编程模型:DataFrame比RDD多了一个Schema元数据信息,被称之为Spark体系中的第二代编程模型:Dataset吸收了RDD的优点(强类型推断和强大的函数式编程)和DataFrame中的优化(SQL优化引擎,内存列存储),成为Spark的最新一代的编程模型
2.4 RDD,DataSet,DataFrame
- RDD
【弹性分布式数据集】,是Spark对数据进行的一种抽象,可以理解为Spark对数据的一种组织方式,更简单些说,RDD就是一种数据结构,里面包含了数据和操作数据的方法。
从字面上就能看出的几个特点:- 弹性:
- 数据可完全放内存或完全放磁盘,也可部分存放在内存,部分存放在磁盘,并可以自动切换
- RDD出错后可自动重新计算(通过血缘自动容错)
- 可checkpoint(设置检查点,用于容错),可persist或cache(缓存)里面的数据是分片的(也叫分区,partition),分片的大小可自由设置和细粒度调整
- 分布式:
- RDD中的数据可存放在多个节点上
- 数据集:
- 数据的集合
- 弹性:
相对于与DataFrame和Dataset,RDD是Spark最底层的抽象,目前是开发者用的最多的,但逐步会转向DataFrame和Dataset(当然,这是Spark的发展趋势)
- DataFrame
DataFrame:理解了RDD,DataFrame就容易理解些,DataFrame的思想来源于Python的pandas库,RDD是一个数据集,DataFrame在RDD的基础上加了Schema 描述数据的信息,可以认为是元数据,DataFrame曾经就有个名字叫SchemaRDD)
设RDD中的两行数据长这样:
| 1 | 张三 | 20 |
|---|---|---|
| 2 | 李四 | 21 |
| 3 | 王五 | 22 |
那么在DataFrame中数据变成这样:
| ID:Int | Name:String | Age:Int |
|---|---|---|
| 1 | 张三 | 20 |
| 2 | 李四 | 21 |
| 3 | 王五 | 22 |
从上面两个表格可以看出,DataFrame比RDD多了一个表头信息 (Schema),像一张表了,DataFrame还配套了新的操作数据的方法等,有了DataFrame这个高一层的抽象后,我们处理数据更加简单了,甚至可以用SQL来处理数据了,对开发者来说,易用性有了很大的提升,不仅如此,通过DataFrameAPI或SQL处理数据,会自动经过Spark优化器(Catalyst)的优化,即使你写的程序或SQL不高效,也可以运行的很快
- DataSet
相对于RDD,Dataset提供了强类型支持,也是在RDD的每行数据加了类型约束
设RDD中的两行数据长这样:
| 1 | 张三 | 20 |
|---|---|---|
| 2 | 李四 | 21 |
| 3 | 王五 | 22 |
那么在DataFrame中数据变成这样:
| ID:Int | Name:String | Age:Int |
|---|---|---|
| 1 | 张三 | 20 |
| 2 | 李四 | 21 |
| 3 | 王五 | 22 |
那么在DataSet中数据变成这样:
| Person(id:Int,Name:String,Age:Int) |
|---|
| Person(1,张三,20) |
| Person(2,李四,21) |
| Person(3,王五,22) |
目前仅支持Scala、JavaAPI,尚未提供Python的API(所以一定要学习
Scala),相比DataFrame,Dataset提供了编译时类型检查,对于分布式程
序来讲,提交一次作业太费劲了(要编译、打包、上传、运行),到提交到集群运行时才发现错误,实在麻烦,这也是引入Dataset的一个重要原因。
使用DataFrame的代码json文件中并没有score字段,但是能编译通过,但是运行时会报异常,如下图代码所示:
val df1 = spark.read.json("/tmp/people.json")//json文件中没有score字段,但是能编译通过val df2 = df1.filter("score>60").show()
而使用Dataset实现,会在IDE中报错,出错提前到了编译之前:
val ds1 = spark.read.json(("/tmp/people.json")).as[ People]
// 使用dataset这样写,在IDE中就能发现错误
val ds2 = ds1.filter(_.score < 60)
val ds3 = ds1.filter(_.age < 60)
// 打印
ds3.show()
3 SparkSQL核心编程
3.1 编程入口
SparkCore中,如果想要执行应用程序,需要首先构建上下文环境对象SpakContext,SparkSQL其实可以理解为对SparkCore的一种封装,不仅仅在模型上进行了封装,上下文环境对象也进行了封装。
在老的版本中,SparkSQL提供两种SQL查询起始点:一个叫SQLContext,用于Spark自己提供的SQL查询;一个HiveContext 用于连接Hive的查询。
SparkSession是Spark最新的SQL查询起始点,实质上是SQLContext和HiveContext的组合,所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext ,所以计算实际上是由SpakContext完成的。
SparkSession的构建需要依赖SparkConf或者SparkContext。使用工厂构建器(Builder方式)模式创建SparkSession。
3.2 SparkSQL基本编程
3.2.1编程入口SparkSession
val session = SparkSession.builder.appName("test") // 执行项目名称.master("local[*]") //选中本地执行方式// .enableHiveSupport() //开启支持Hive相关操作.getOrCreate() //创建session对象
3.2.2 DSL语法 -->结合SQL中关键字作为函数(算子)的名字传递参数进行编程方式–>接近于RDD编程
//无法读取表结构,优化为下行
// val frame: DataFrame = session.read.json("data/people.json") val frame: DataFrame = session.read.json(session.sparkContext.wholeTextFiles("data/people.json").values)//DSL语法 -->结合SQL中关键字作为函数(算子)的名字传递参数进行编程方式// -->接近于RDD编程frame.printSchema() //查看二维表结构/*运行结果:root|-- age: long (nullable = true)|-- height: double (nullable = true)|-- name: string (nullable = true)|-- province: string (nullable = true)*/frame.show() //相当于查看表中信息-->select * from people/*运行结果:+---+------+-------+--------+|age|height| name|province|+---+------+-------+--------+| 10| 168.8|Michael| 广东|| 30| 168.8| Andy| 福建|| 19| 169.8| Justin| 浙江|| 32| 188.8| 王启峰| 广东|| 10| 168.8| John| 河南|| 19| 179.8| Domu| 浙江|+---+------+-------+--------+*/frame.show(3) //相当于查看表中前3行信息/*运行结果:+---+------+-------+--------+|age|height| name|province|+---+------+-------+--------+| 10| 168.8|Michael| 广东|| 30| 168.8| Andy| 福建|| 19| 169.8| Justin| 浙江|+---+------+-------+--------+only showing top 3 rows*///针对性查询某列数据-->select name,age from peopleframe.select("name","age").show()/*运行结果:+-------+---+| name|age|+-------+---+|Michael| 10|| Andy| 30|| Justin| 19|| 王启峰| 32|| John| 10|| Domu| 19|+-------+---+*/
3.2.3 导入SparkSession中隐式转换操作,增强sql功能
import session.implicits._frame.select($"name",$"age").show()/*运行结果:+-------+---+| name|age|+-------+---+|Michael| 10|| Andy| 30|| Justin| 19|| 王启峰| 32|| John| 10|| Domu| 19|+-------+---+*///涉及到列运算时,每列都必须使用$符号//涉及到列运算时,每列也可以使用单引号字段名形式//等价于 select name,height-1,age+10 from peopleframe.select($"name",$"height"-1,'age+10).show()/*运行结果:+-------+------------+----------+| name|(height - 1)|(age + 10)|+-------+------------+----------+|Michael| 167.8| 20|| Andy| 167.8| 40|| Justin| 168.8| 29|| 王启峰| 187.8| 42|| John| 167.8| 20|| Domu| 178.8| 29|+-------+------------+----------+*///涉及到列运算时,也可以使用new Column方式//可以使用as修改列的别名//等价于select age+10 as age from peopleframe.select(new Column(name="age").+(10)).show()/*运行结果:+----------+|(age + 10)|+----------+| 20|| 40|| 29|| 42|| 20|| 29|+----------+*/frame.select(new Column(name="age").+(10).as("age")).show()/*运行结果:+---+|age|+---+| 20|| 40|| 29|| 42|| 20|| 29|+---+*///分组聚合-->统计不用年龄的人数frame.select("age").groupBy("age").count().show()/*运行结果:+---+-----+|age|count|+---+-----+| 19| 2|| 32| 1|| 10| 2|| 30| 1|+---+-----+*///条件查询-->获取年龄超过18岁的frame.select("name","age","height").where("age>20").limit(4).show()/*运行结果:+------+---+------+| name|age|height|+------+---+------+| Andy| 30| 168.8||王启峰| 32| 188.8|+------+---+------+*/
3.2.4 SQL语法 -->直接写SQL或者HQL语言进行编程【算是SparkSQL主流】
注意:如果使用SQL的必要前提就是需要将数据转换为表
/*PS:创建表的参数为表名SQL语法操作中提供两种表:createOrReplaceTempView -->创建普通的临时表,作用域为当前session应用范围内有效createOrReplaceGlobalTempView -->创建普通的全局临时表,是当前application中可以使用,会覆盖原来数据createGlobalTempView --> 创建全局临时表,作用域为在整个当前application范围内有效,不会覆盖原来数据使用全局临时表时需要全路径访问:如global_temp.表名没有Replace关键字的global,不会覆盖,如创建,再创建,会报错有Replace关键字的global,会覆盖,如已经创建,再创建,会覆盖*/frame.createGlobalTempView("people")session.sql("""|select * from global_temp.people|""".stripMargin).show()/*运行结果:+---+------+-------+--------+|age|height| name|province|+---+------+-------+--------+| 10| 168.8|Michael| 广东|| 30| 168.8| Andy| 福建|| 19| 169.8| Justin| 浙江|| 32| 188.8| 王启峰| 广东|| 10| 168.8| John| 河南|| 19| 179.8| Domu| 浙江|+---+------+-------+--------+*/frame.createOrReplaceGlobalTempView("people_2")frame.createOrReplaceTempView("people_1") //这个操作比较常用session.sql("""|select|age,|count(1) as countz|from people_1|group by age|""".stripMargin).show()/*运行结果:+---+------+|age|countz|+---+------+| 19| 2|| 32| 1|| 10| 2|| 30| 1|+---+------+*/
参考自:https://www.bilibili.com/video/BV1WA411273z?p=5&spm_id_from=pageDriver&vd_source=6bd7b38d1d3cdff6e483a47870f6d418