摘要:本文整理自阿里巴巴算法专家赵伟波,在 Flink Forward Asia 2023 AI特征工程专场的分享。本篇内容主要分为以下四部分:
- Flink ML 概况
- 在线学习的设计与应用
- 在线推理的设计与应用
- 特征工程算法与应用
一、Flink ML 概况
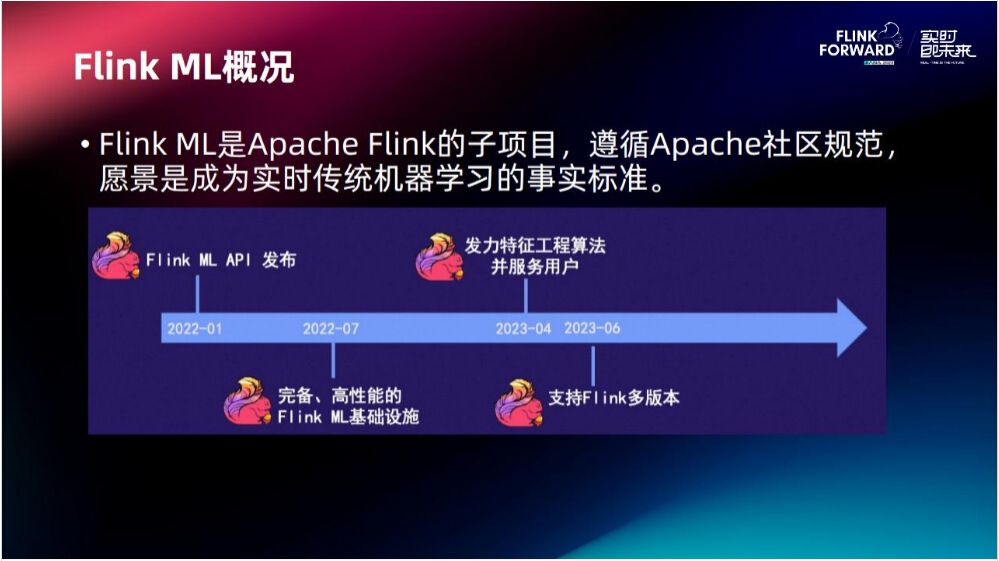
Flink ML 是 Apache Flink 的子项目,遵循 Apache 社区规范,愿景是成为实时传统机器学习的事实标准。
2022年1月份 Flink ML API 发布,7月份发布完备、高性能的 Flink ML 基础设施,2023年4月份发力特征工程算法并服务用户,6月份支持 Flink 多版本。
二、在线学习的设计与应用
2.1 在线机器学习工作流样例
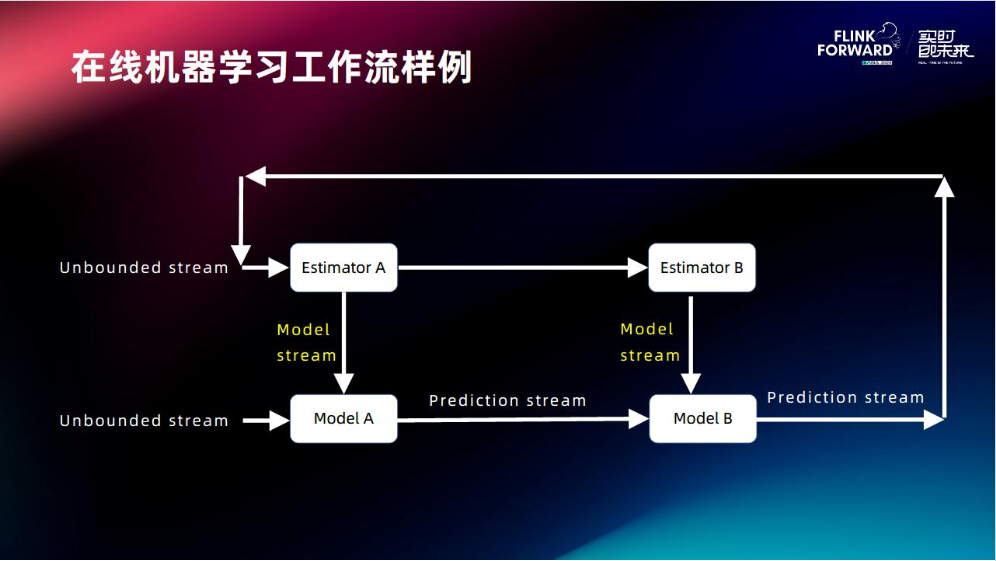
有两个模型AB,用 online 在线学习的方式去训练这两个模型,并且使用模型去进行在线推理,在推理过程中这个模型是流动形式,叫做 Model stream (模型流),以模型流的方式将模型不断地流入链路中,使模型具有更好的实时性。推理结束之后,推理样本会推荐给一些前方的客户,客户对结果进行反馈,再进行一些样本的拼接,最后返回到训练的数据流形成闭环,这就是工作流样例。
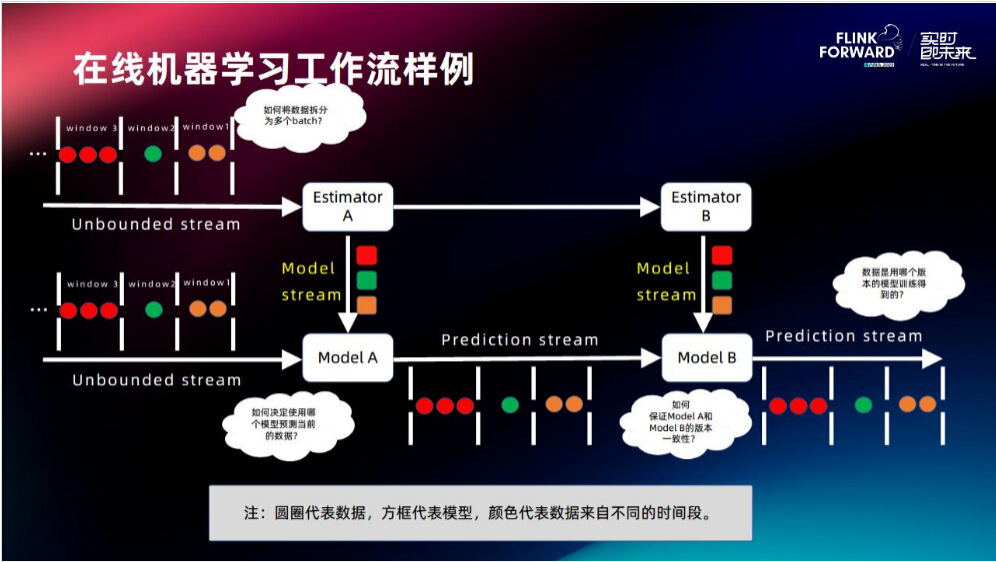
接下来以工作流样例来介绍在线学习的设计。训练数据进行切分后,切成不同的 window,每个 window 在经过 Estimator 的时候需要更新里面的模型,之后该模型会流到下面推理的链路中,随着数据的不断流入,模型会一个接一个的往推理的链路中流动,这就是 Model stream(模型流),其思路是通过把模型做成一个队列的方式去支持推理以达到更好的时效性。
存在的问题:
- 如何使数据拆分更加合理?对不同的业务有不同的要求,有的希望用时间,有的希望用大小,都需要一些策略。
- 因为数据和模型都是流动的,两个往同一个地方去流,那么如何决定一条样本来了之后用哪个模型进行推理?
- 如何保证模型的一致性?因为链路中有两个模型,如果两个模型的训练数据不一致会导致出现一些问题。
- 数据是用哪一个模型推理出来的?每一条样本是哪个模型推理出来的,预测的好坏需要去追溯源头。
2.2 在线机器学习的设计

针对四个问题,有四条设计需求:
- 支持将输入数据划分为多个 window 进行训练,产生一个模型流。
- 支持使用输入的模型流来对数据进行预测。
- 支持用户指定推理数据和当前模型数据的时间差。每一条样本来了之后,我们希望用最新的模型去进行推理,但是最新的模型可能还没有训练出来,这个时候就需要设定一个时间差,允许它用非最新的模型进行推理。
- 支持在输出数据中暴露预测每条数据时使用的模型版本。从预测结果追溯出模型的需求。
针对这些需求,我们的设计方案是:
- 增加 HasWindows 接口。
允许用户声明划分数据的不同策略。 - 为 ModelData 增加 model version 和 timestamp。
model version 的值从 0 开始,每次增加 1。
模型数据的时间戳为训练得到该模型的数据的最大时间戳。 - 增加 HasMaxAllowedModelDelayMs 接口。
允许用户指定预测数据 D 时,使用的模型数据 M 早于 D 的时间小于等于设定的阈值。 - 增加 HasModelVersionCol 接口。
推理过程中,允许用户输出预测每条数据时使用的模型版本。
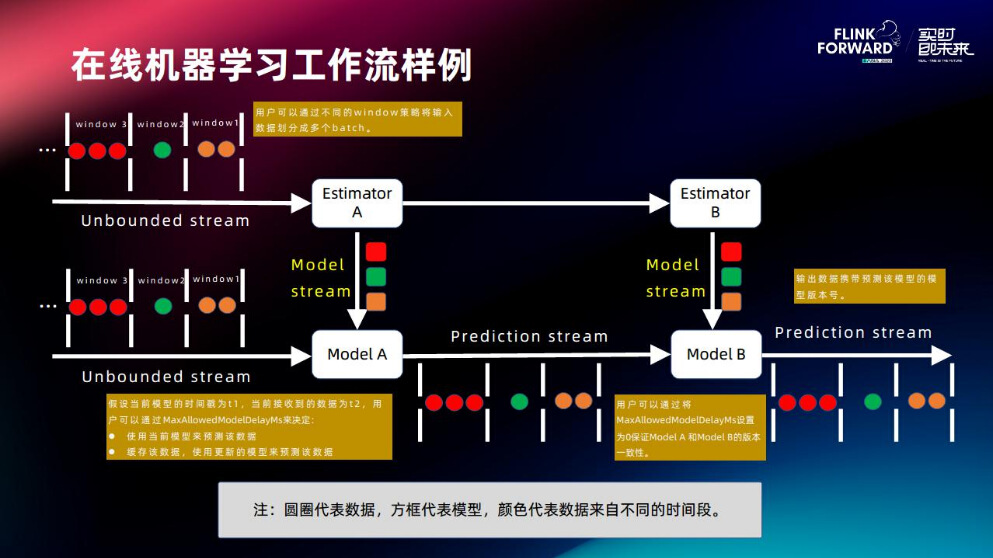
有了方案之后再回来看问题:
- 怎么切分 window:
提供 window 策略,用户可以根据自己的需求去做一些适合自己业务场景的切分。 - 选择哪一种模型来推理当前数据:
通过阈值参数设定允许离当前数据多远的模型进行推理;理论上可以用最新模型,但是可能会造成等待之类的问题。 - 关于模型的一致性:
每一条样本在预测的时候都会带一个模型版本,经过第一个模型预测再到第二个模型推理的时候会自动获取版本号,两边用同样的版本进行推理,最后输出的结果会带有一个版本号。
这样就把最初提的四个问题解决了。
2.3 在线学习在阿里云实时日志聚类的应用

阿里云 ABM 运维中心会把阿里所有平台的日志都收集到一起,然后会针对错误日志做一个聚类,把错误日志发送到对应的部门,去进行后续的处理。
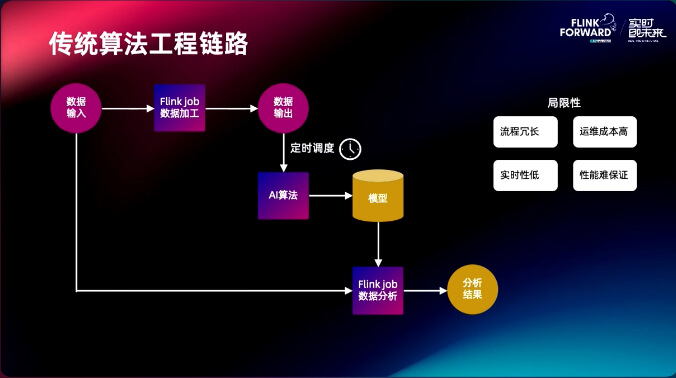
传统算法工程链路首先进行数据输入,用 Flink job 进行数据加工处理,数据会落盘,之后通过定时调度来拉起聚类算法,然后写出模型,这个模型再通过加载的方式拉起 Flink job 进行数据预测,但是整个链路具有局限性,流程比较复杂,运维成本比较高,实时性低,并且性能难以保证。
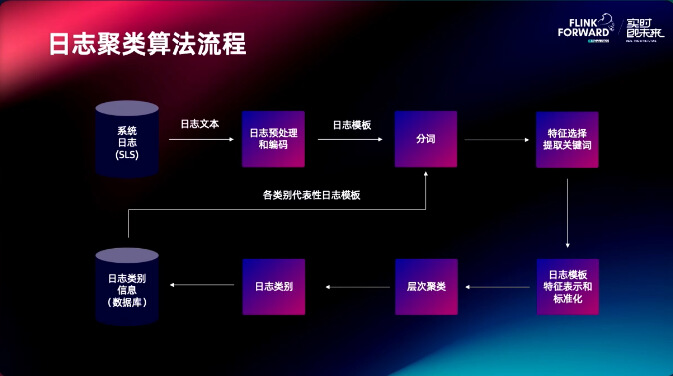
日志聚类算法流程把系统日志进行预处理和编码后分词,做特征选择提取关键词,然后做日志的特征表示和标准化,再做层次聚类,日志的类别,最后写出到数据库,用来指导分词。
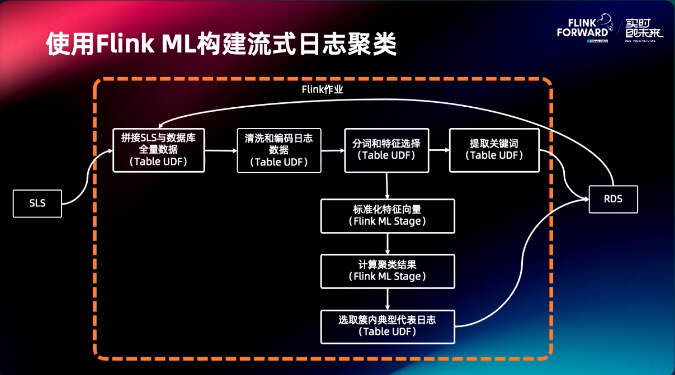
针对该流程我们使用 Flink ML 构建流式日志聚类就可以把这个流程串起来。通过 Flink job 拼接 SLS 与数据库全量数据,接着进行清洗和编码日志数据,然后分词和标准化,计算聚类结果,最后选取簇内典型代表日志。
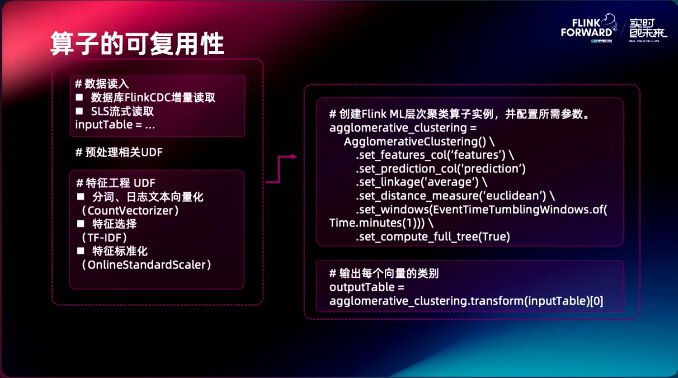
把这个案例中的算子进行抽取,像 SLS 流式读取,分词,日志的向量化,特征选择,特征的标准化,这些并不是业务独有的,而是很多在线学习业务都需要的算子,把它抽取出来,做成一个独立的组件,客户需要做在线学习流程的时候可以来复用这些算子。
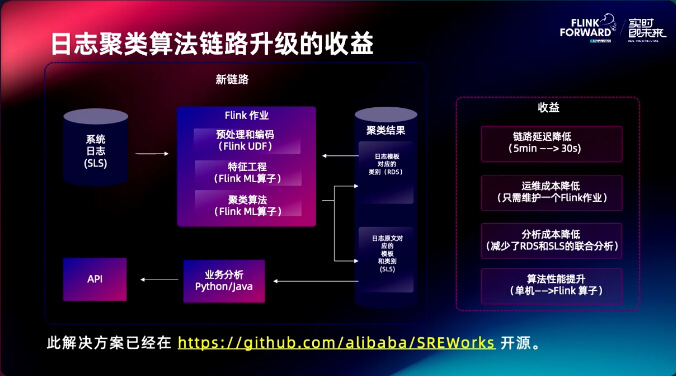
日志聚类算法链路升级的收益:
- 在链路延迟方面,将原来 5 min 的延迟降低到 30s
- 运营成本降低,现在只需要维持 1 个 Flink 作业
- 分析成本降低
- 算法性能提升
三、在线推理的设计与应用

推理主要分为:
- 批量推理:例如,有 100w 条数据落盘,然后起一个批的任务对这100万条数据进行推理,再进行落盘。
- Near-line (近线)推理:基于 Flink 的任务,读取 Kafka 数据,通过 Transformer 的方式对流式的数据进行推理。这种推理有一个比较大的问题是延迟比较高,一般在百毫秒量级,在实际的业务场景中,推理需要很低的延迟,一般是几十毫秒甚至几毫秒,这就需要我们做一个推理框架去适应高要求的业务场景。

在做这个之前我们对 Spark ML 的推理进行了一个调研。后来发现 Spark ML 本身是没有推理模块的,它有一个 mleap,把 Spark 推理这部分做成一个推理框架,这个推理框架与引擎 Runtime 完全无关,减少依赖冲突,是一个更轻量的框架,另外这个新框架可以为推理重写计算逻辑代码,拥有更大的优化空间。
3.1 设计需求

设计需求借鉴了 mleap 的做法:
1. 数据表示(与 Flink Runtime 无关)
单条数据表示:Row
批量数据表示:DataFrame
数据类型表示,提供 Vector、Matrix 等类型的支持
2. 推理逻辑表示
3. 模型加载
支持从 Model/Transoformer#save 的文件中加载
支持动态加载模型数据,而不需要重启
4. Utils
支持检查 Transformer/PipelineModel 是否支持在线推理
串联多个推理逻辑成单个推理逻辑
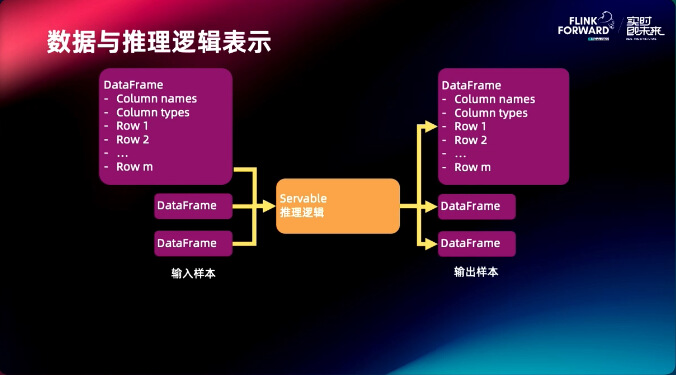
在这个设计需求下,左边是推理的数据结构 DataFrame,包含了 Column names, Column types, Row,进入推理逻辑之后输出还是同样的数据结构,这样整个推理结构就可以串起来,不需要有数据结构转换。
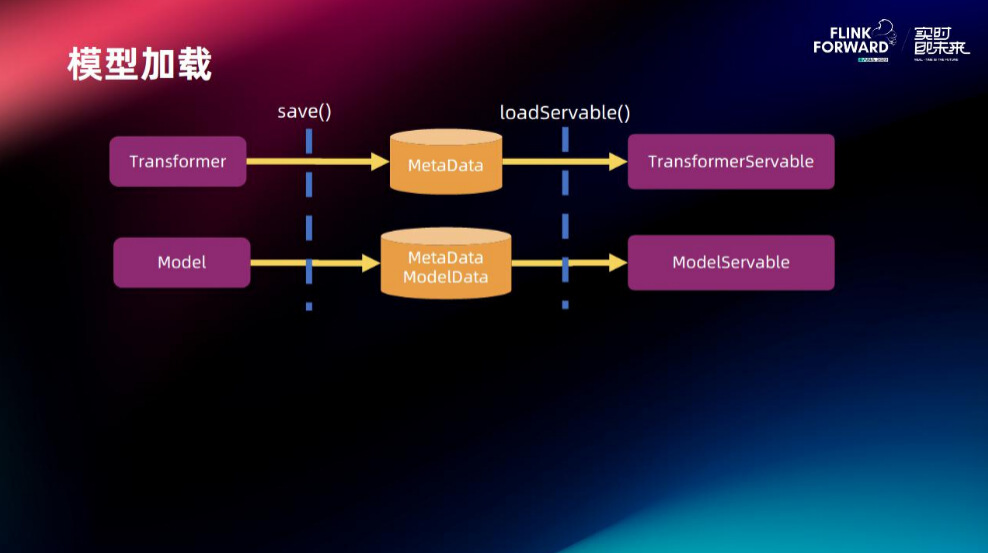
模型加载这边都是通过 save 函数将模型写入到磁盘,左边的 save 是 Flink ML 做的事情,右边的 loadServable 是推理框架做的事情,通过这两个函数实现了模型的保存加载和推理。
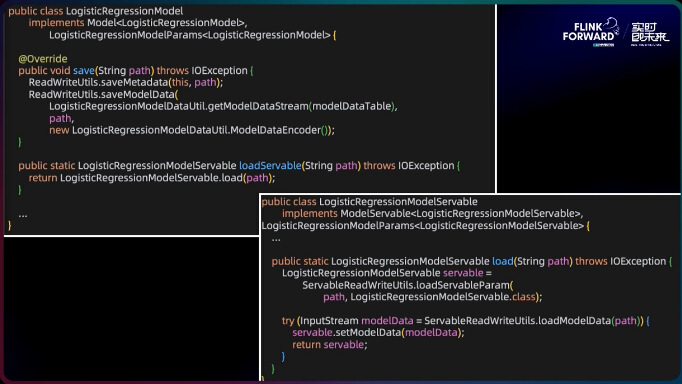
接下来以逻辑回归为例来看代码的实现,通过 save 函数把模型写出到指定的目录,下面的 load 是推理框架做的事情,以 load 模型的文件去做推理。
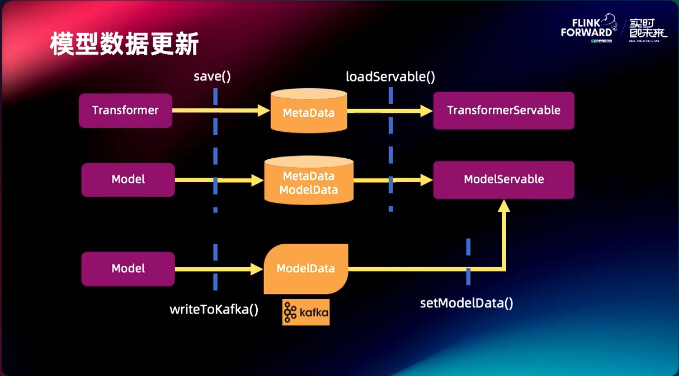
模型的数据更新这部分是通过把一个模型写入到 kafka 里面,kafka 再 set 到模型的 Servable 里面,当把模型写入到 kafka 里的时候模型会自然而然的流入到 Servable 里面,最终实现模型的动态更新。
下面是代码
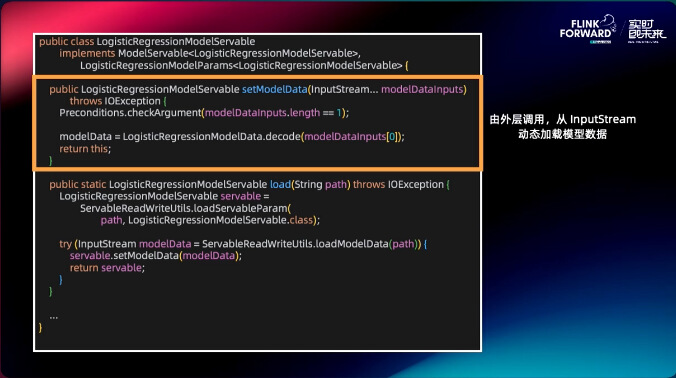
setModelData 的输入是 InputStream,它可以从 kafka 里读入,当更新 kafka 里的数据时它就可以更新到模型里面。
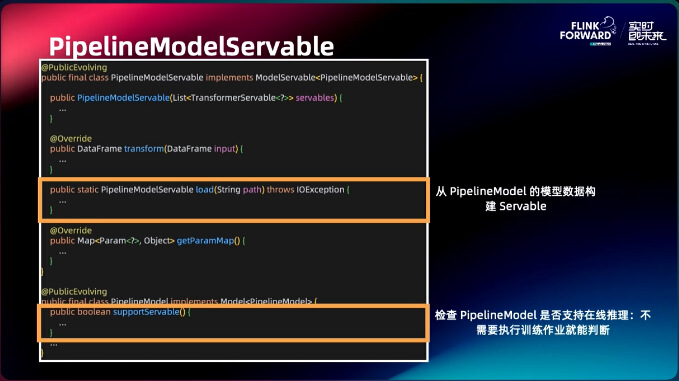
另外我们也支持 PipelineModel 推理,可以从 PipelineModel 的模型数据构建 Servable, 检查 PipelineModel 是否支持在线推理,不需要执行训练作业就能判断。
3.2 使用场景
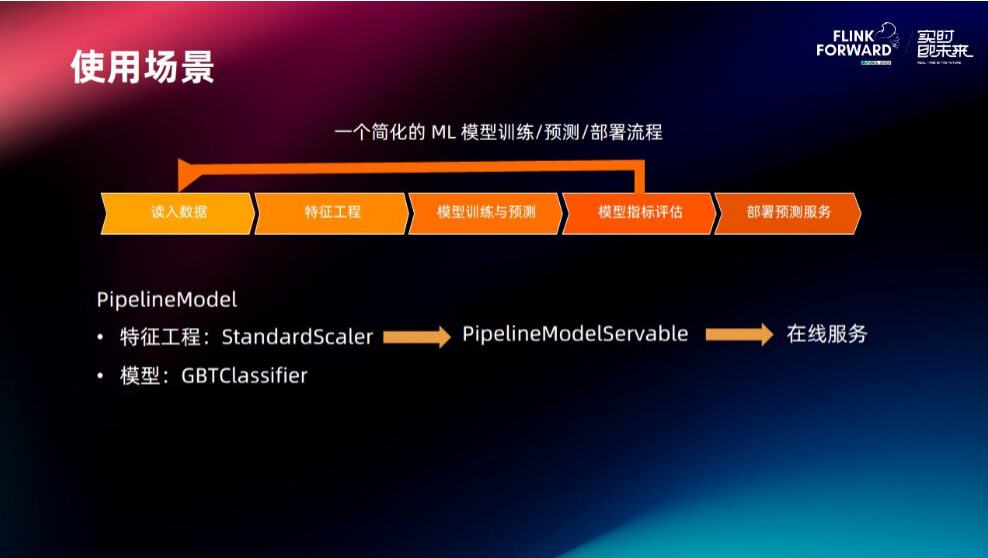
最后来看使用场景,这是一个简化的 ML 模型训练、预测和部署的流程。首先是读入数据,做特征工程,然后做评估和部署。这边使用 PipelineModel 将标准化和 GBT 分类这两个模型打到 Pipeline 里面去,再去做在线的推理服务。
以下是代码
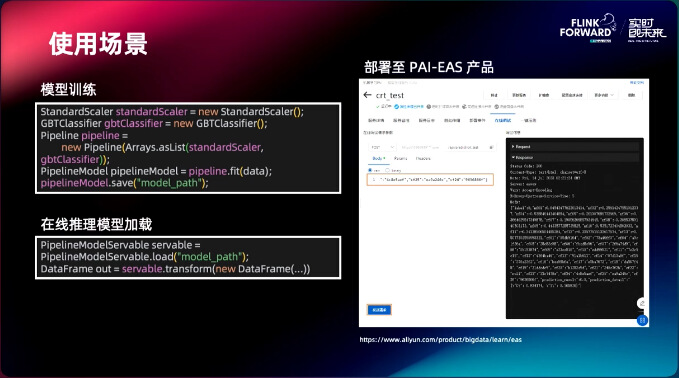
将标准化和 GBT 两个模型通过 Pipeline 写出去,在推理模块中最终实现 Pipeline 的推理,并且推理支持写出和动态加载。
四、特征工程算法与应用
4.1 特征工程算法

新增27个算法,总共33个,基本覆盖常用算法。
4.2 特征工程的应用

首先是做推荐,广告的评估,都需要特征的处理。第二个应用场景是用于实现一些复杂的算法,以 GBT 为例,处理数值特征和处理类别型特征。另外在大语言模型这块,Flink ML 也做了一些设计。

接下来以大语言模型为例,来看特征工程的业务。高质量的文本输入可以获得更好的大语言模型,而文本近似去重能提高文本质量。对于互联网数据来说,文本重复的比例通常 20%-60% 之间,文本规模越大,重复比例越高。

针对这个问题,我们设计了近似去重流程:
- 不同于精确去重:不要求完全一致,或者子串关系
- 基于局部敏感性哈希 Locality-sensitive hashing:相似的样本更容易被 Hash 到相同的 buckets 内
- 对于文本数据来说,通常基于文本特征化后的 Jaccard 距离,使用 MinHashLSH 来找到相似文本

通过这些组件,可以完成文本去重流程:
- Tokenizer:进行分词
- HashingTF:将文本变换为 Binary 特征
- MinHash:计算文本签名
- MinHashLSH:进行 SimilarityJoin,找到相似对

最后是性能的测试,这是手动构造的 Benchmark 数据集,直接通过复制、删除之类的操作拿到一个数据集。对于5亿的数据,重复率为 50%,耗时大概 1.5h,后面是对应的去重效果。