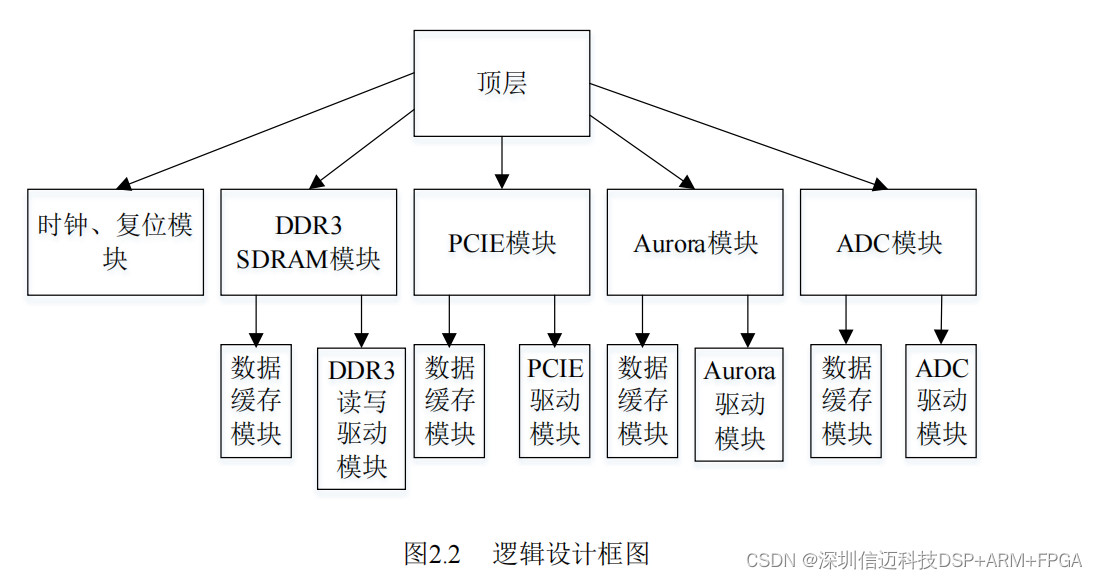
input:(2, 3, 300, 300)
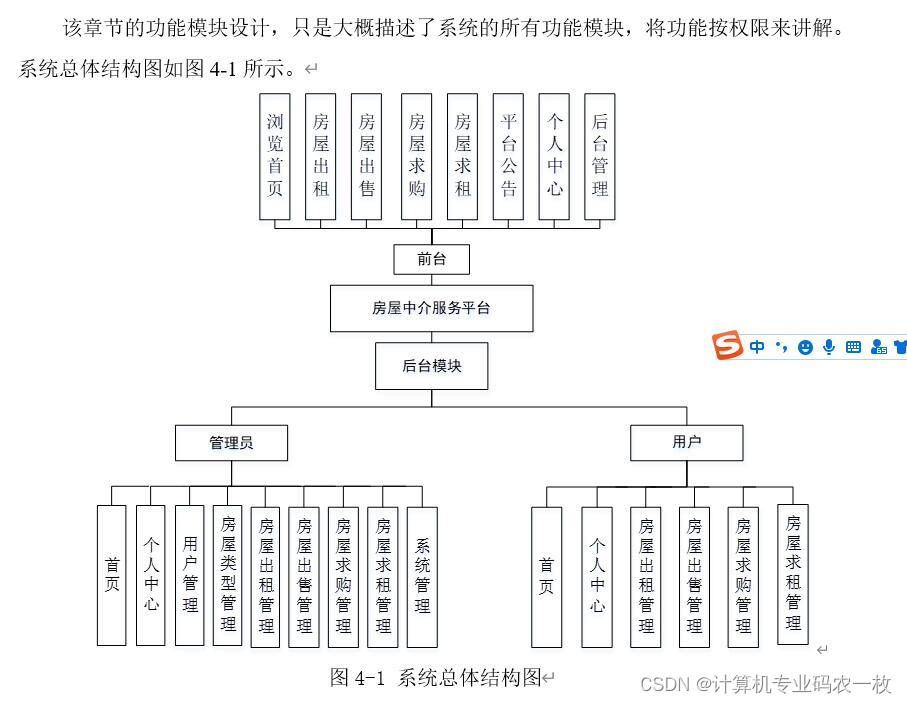
backbone:在VGG16的基础上进行改动。取vgg16的conv5_3,在mmdet的实现中没用BN,只有conv、ReLU、maxpool层,conv5_3是第30层,输出大小为(2, 512, 19, 19)。接着用3×3-s1-p1的maxpool取代原来的2×2-s2的maxpool,用3×3的卷积层conv6和1×1的卷积层conv7分别代替原来的fc6和fc7,并且conv6采用了dilation_rate=6的空洞卷积,增大了感受野。增加的5层具体如下

输出如下
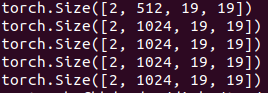
取22和34层(index从0开始)即conv4_3和conv7作为输出用于后续的检测。
接着后面又加了8层卷积层,具体如下
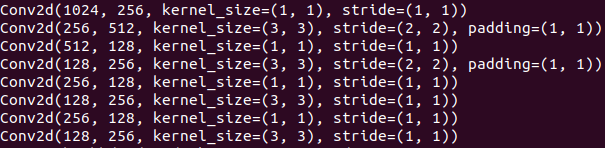
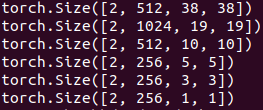
并取出conv8_2,conv9_2,conv10_2,conv11_2加上前面的conv4_3,conv7共6个特征图作为backbone的输出。shape如下
因为conv4_3比较靠前,norm较大,因此作者对conv4_3专门加了L2 Normalization处理(注意这里是对取出的6个特征图中的conv4_3做了L2 Norm,而不是在网络中的conv4_3层后面加了一层L2 Norm)。
L2 Norm的代码如下所示,其中n_dims=512是conv4_3层的channel,具体而言是对每个像素点在channel维度做归一化。
class L2Norm(nn.Module):def __init__(self, n_dims=512, scale=20., eps=1e-10):"""L2 normalization layer.Args:n_dims (int): Number of dimensions to be normalizedscale (float, optional): Defaults to 20..eps (float, optional): Used to avoid division by zero.Defaults to 1e-10."""super(L2Norm, self).__init__()self.n_dims = n_dimsself.weight = nn.Parameter(torch.Tensor(self.n_dims))self.eps = epsself.scale = scaledef forward(self, x):"""Forward function."""# normalization layer convert to FP32 in FP16 trainingx_float = x.float()norm = x_float.pow(2).sum(1, keepdim=True).sqrt() + self.epsreturn (self.weight[None, :, None, None].float().expand_as(x_float) *x_float / norm).type_as(x)
anchor_generator:backbone的6个输出特征图的尺度分别为(38,38)、(19,19)、(10,10)、(5,5)、(3,3)、(1,1),对于不同尺度的特征图,先验框即anchor的尺度也不一样,其遵循线性递增的规则,特征图尺度越小,anchor的尺度越大,具体如下
其中m是特征图的个数,但这里是5,因为conv4_3层是单独设置的。是anchor大小相对于原图的比例,
head:对于backbone阶段6个不同尺度的输出, 每个特征图后分别接两个3×3卷积得到对应该尺度的分类和回归结果,voc数据集共有20类,在mmdet的实现中分类输出额外加了一个bg类别,以conv4_3为例,
参考 目标检测|SSD原理与实现 - 知乎