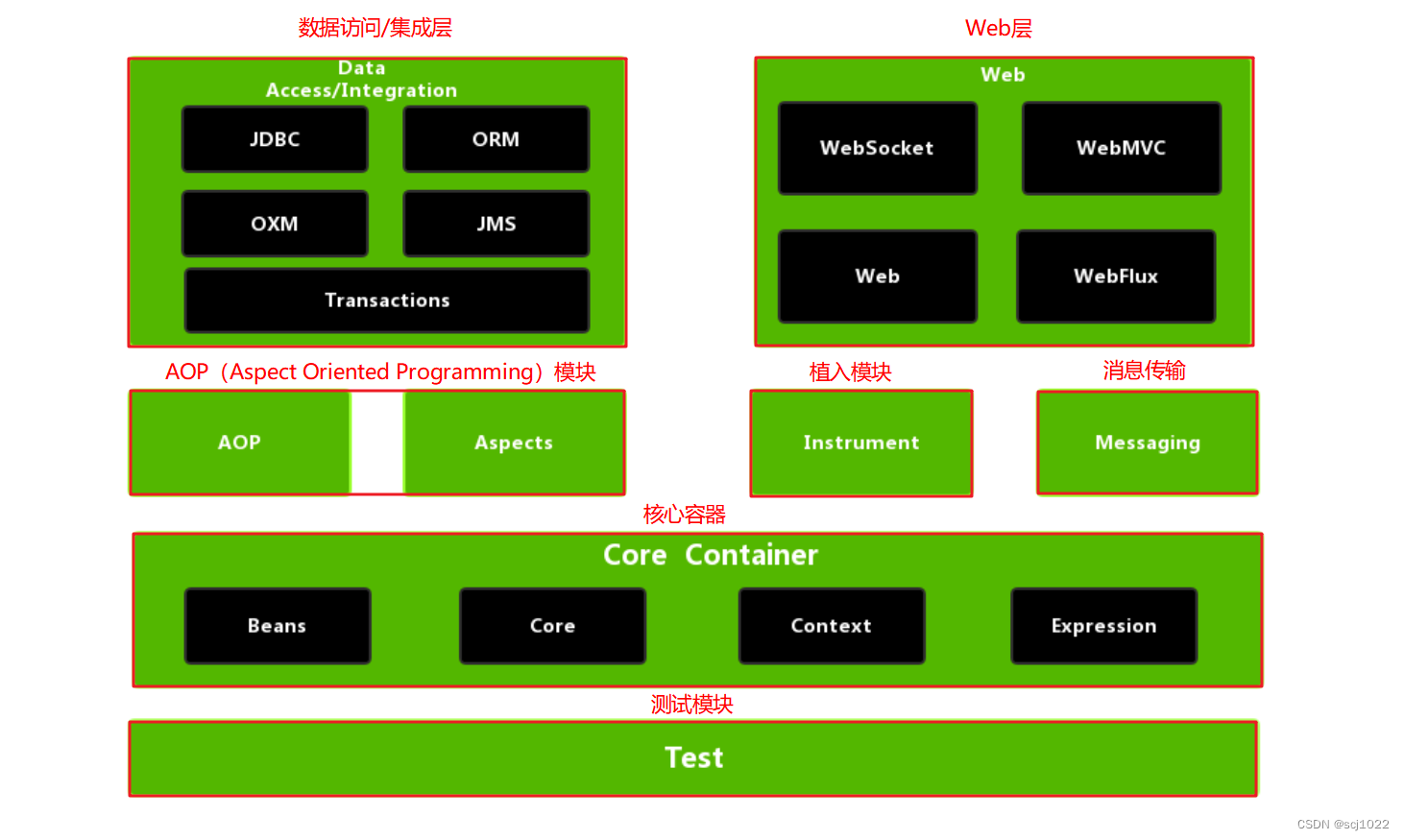
目录
一、编程规范基础知识
1、头文件
2、程序的板式风格
3、命名规则
二、表达式和基本语句
1、运算符的优先级
2、复合表达式
3、if语句
4、循环语句的效率
5、for循环语句
6、switch语句
三、常量
1、#define和const比较
2、常量定义规则
四、函数设计
1、参数规则
2、返回值规则
3、函数内部实现规则
4、断言
五、内存管理
1、内存分配
2、指针与数组
3、free和delete
4、动态内存释放
5、内存耗尽
6、malloc和free使用
一、编程规范基础知识
1、头文件
(1)防止头文件被重复包含
首先,和大家聊一聊头文件为什么会被被重复包含呢。这一错误操作主要是因为include嵌套造成的。举个例子,在a.h文件中#include "c.h",而在b.c文件中#include "a.h"和#include "c.h"。此时,就造成了c.h重复包含。
头文件被重复引用会引起哪些后果呢?有些头文件重复引用,只是增加了编译工作的工作量,不会引起太大的问题,仅仅是编译效率低一些,但是对于大工程而言编译效率就是很重要的了;有些头文件重复包含,会引起编译错误,比如在头文件中定义了全局变量或写了函数的实现而不是声明(虽然这种方式不被推荐,但确实是C规范允许的),这种会引起重复定义。
那,么如何避免头文件被重复包含呢?我们可以使用#ifndef/#define/#endif方式,下面我们给出该用法如何来使用:
#ifndef __XXX_H__ //意思是 "if not define __XXX_H__" 也就是没包含XXX.h#define __XXX_H__ //就定义__XXX_H__... //此处放头文件中本来应该写的代码#endif //否则不需要定义 (2)引用头文件
- < >头文件:引用标准库的头文件,编译器将,从标准目录开始搜索。
- " "头文件:引用非标准库的头文件,将从用户的工作目录开始搜索,用户自己创建的头文件。
2、程序的板式风格
清晰、美观,是程序风格的重要构成因素。
(1)空行
我们在编程时可以使用空行(起着分隔程序段落的作用)。关于空行,和大家聊一下以下三点规则:空行不会浪费内存;在每个类声明之后、每个函数定义结束之后都要加空行;在一个函数体内,逻揖上密切相关的语句之间不加空行,其它地方应加空行分隔。
(2)代码行
一行代码只做一件事情,如只定义一个变量,或只写一条语句。这样的代码容易阅读,并且方便于写注释。关于代码行,主要是以下几点规则:
规则一:if、for、while、do等语句独自占一行,执行语句不得紧跟其后。不论执行语句有多少后面都要加{}。这样可以防止书写失误。
规则二:关键字之后要留空格。像 const、virtual、inline、case 等关键字之后至少要留一个空格,否则无法辨析关键字。像 if、for、while 等关键字之后应留一个空格再跟左括号‘(’,以突出关键字。
规则三:如果‘;’不是一行的结束符号,其后要留空格,如for(initialization; condition; update)。
规则四:赋值操作符、比较操作符、算术操作符、逻辑操作符、位域操作符,如“=”、“+=” “>=”、“<=”、“+”、“”、“%”、“&&”、“||”、“<<”,“^”等二元操作符的前后应当加空格。
(3)对齐
关于对齐讲两点规则:
规则一:程序的分界符‘{’和‘}’应独占一行并且位于同一列,同时与引用它们的语句左对齐。
规则二:{ }之内的代码块在‘{’右边数格处左对齐。

(4)长行拆分
每条代码行不要过长,不利于观看和打印。长表达式要在低优先级操作符处拆分成新行,操作符放在新行之首(以便突出操作符)。拆分出的新行要进行适当的缩进,使排版整齐,语句可读。

(5)修饰符
修饰符位置: * 和 & 紧靠变量名。
int* x, y; // 这样写,y容易被误解为指针变量。应该修改为int *x, y,这样y就不会再被误解成指针了。
(6)注释
如果代码本来就是清楚的,则不必加注释。否则多此一举,令人厌烦。注释的花样要少 。注释的位置应与描述的代码相邻,可以放在代码的上方或有方,不可放在下方。当代码比较长,特别是有多重循环,应当在一些段落的结束处加注释,便于阅读。
3、命名规则
Windows应用程序的标识符通常采用“大小写”混排的方式,如 AddChild。而 Unix 应用程序的标识符通常采用“小写加下划线”的方式,如 add_child。接下来讲几点常见规则:
规则一:类名和函数名用大写字母开头的单词组成。
规则二:变量和参数用小写字母开头的单词组成。
规则三:常量全用大写字母,用下划线分割单词。
规则四:静态变量加前缀s_(表示static)。
规则五:如果使用全局变量,则使全局变量加前缀g_(表示global)。
二、表达式和基本语句
1、运算符的优先级
如果代码行中的运算符比较多,用括号确定表达式的操作顺序,避免使用运算符默认的优先级。
比如:if ((a | b) && (a & c)) 2、复合表达式
关于复合表达式,在这里讲解以下三点规则:
规则一:不要编写太复杂的复合表达式。
规则二:不要有多用途的复合表达式。例如:d = (a = b + c) + r , 该表达式既求 a 值又求 d 值。应该拆分为两个独立的语句。
规则三:不要把程序中的复合表达式与“真正的数学表达式”混淆。 例如: if (a < b < c) 。在这条语句里a < b < c 是数学表达式而不是程序表达式,所以该语句并不表示 if ((a<b) && (b<c)) ;而是成了令人费解的 if ( (a<b)<c )。
3、if语句
(1)布尔变量与零值比较
不可将布尔变量直接与 TRUE、FALSE 或者 1、0 进行比较。根据布尔类型的语义,零值为“假”(记为 FALSE),任何非零值都是“真”(记为TRUE)。
假设布尔变量名字为 flag,它与零值比较的标准 if 语句如下:
- if (flag) 表示 flag 为真
- if (!flag) 表示 flag 为假
(2)整型变量与零值比较
应当将整型变量用“==”或“!=”直接与 0 比较。假设整型变量的名字为 value,它与零值比较的标准 if 语句如下:
if (value == 0)
if (value != 0)
(3)浮点变量与零值比较
不可将浮点变量用“==”或“!=”与任何数字比较。无论是 float 还是 double 类型的变量,都有精度限制。一定要避免将浮点变量用“==”或“!=”与数字比较,应该设法转化成“>=”或“<=”形式。
假设浮点变量的名字为 x,应当将if (x == 0.0)隐含错误的比较,转化为if ((x>=-EPSINON) && (x<=EPSINON)) //其中 EPSINON 是允许的误差(即精度)。EPSINON是e的负10次方,该数表示接近于0的小正数。
(4)指针变量与零值比较
应当将指针变量用“==”或“!=”与 NULL 比较。指针变量的零值是“空”(记为 NULL)。尽管NULL 的值与 0 相同但是两者意义不同。假设指针变量的名字为 p,它与零值比较的标准 if 语句如下:
if (p == NULL) // p 与 NULL 显式比较,强调 p 是指针变量 if (p != NULL)
4、循环语句的效率
本块重点讲述循环体的效率。提高循环体效率的基本办法是降低循环体的复杂性。接下来讲解两种主要规则:
规则一:在多重循环,如果有可能,应当将最长的循环放在最内层,最短的循环放在最外层,以减少cpu跨切循环层的次数。如下图所示:
for (i=0; i<5; i++ )
{for (j=0; j<100; j++) { sum = sum + a[j][i]; }
}
规则二:如果循环体内存在逻辑判断,并且循环次数很大,宜将逻辑判断移到循环体外面。如下图所示:
for (i=0; i<N; i++)
{ if (condition) DoSomething(); else DoOtherthing();
} 转化为
if (condition)
{ for (i=0; i<N; i++) DoSomething();
}
else
{ for (i=0; i<N; i++) DoOtherthing();
}
5、for循环语句
不可在for循环内修改循环变量,防止for循环失去控制。建议for循环控制变量的取值采用"半开半闭区间的写法"。如图:

6、switch语句
switch是多分支语句,格式如下:
switch (variable)
{ case value1:break; case value2: break; default:break;
}
规则一:每个case语句的结尾不要忘了加break,否则将导致多个分支重叠(除非有意使用多个分支重叠)。
规则二:不要忘记最后那个default分支。即使程序真的不需要default处理,也应该保留语句default:break;那样做并非多此一举,而是为了防止别人误以为你忘了default处理。
三、常量
1、#define和const比较
(1) const常量有数据类型,而宏常量没有类型。编译器可以对前者进行类型安全检查。而对后者只进行字符替换,没有类型安全检查,并且字符替换可能会产生意料不到的错误(边际效应)。
(2) 有些集成化的调试工具可以对const常量进行调试,但是不能对宏常量进行调试。
(3) 在c++程序中只使用const常量而不使用宏常量,即const常量完全替代宏常量。
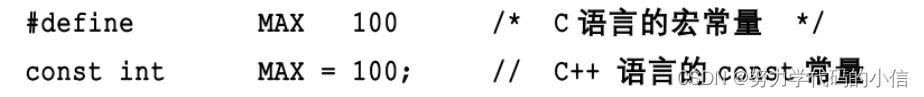
2、常量定义规则
规则一:需要对外公开的常量放在头文件中,不需要对外公开的常量在定义文件的头部。为便于管理,可以把不同模块的常量集中存放在一个公共的头文件中。
规则二:如果某一常量与其它常量密切相关,应在定义中包含这种关系,而不应给出一些孤立的值。例如:
const float RADIUS = 100;
const float DIAMETER = RADIUS * 2;
四、函数设计
函数接口的两个要素是参数和返回值。C语言中,函数的参数和返回值的传递方式有两种:值传递和指针传递。C++语言中多了引用传递(引用传递的性质像指针传递,而使用方式却像值传递)。
1、参数规则
规则一:参数的书写要完整。如果函数没有参数,则用 void 填充。
规则二:参数命名要恰当,顺序要合理。一般应将目的参数放在前面,源参数放在后面。
规则三:如果参数是指针,且仅作输入用,则应在类型前加 const,以防止该指针在函数体内被意外修改。
void StringCopy(char *strDestination,const char *strSource);
规则四:如果输入参数以值传递的方式传递对象,则宜用"const &" 方式来传递,这样可以省去临时对象的构造和分析过程,从而提高效率。
2、返回值规则
(1)不要省略返回值的类型
C语言中,凡不加类型说明的函数,一律自动按整型处理。这样做易被误认为是 void类型。C++语言有严格的类型安全检查,不允许上述情况发生。由于C++可以调用C函数,为了避免混乱,规定任何c/c++函数都必须有类型。如果函数没有返回值,那么应声明为void类型。
(2)函数名字与返回值类型在语义上不可冲突

(3) 不要将正常值和错误标志混在一起返回。正常值用输出参数获得,而错误标志用return语句返回
在正常情况下,getchar的确返回单个字符。但如果getchar碰到文件结束标志或发生读错误,它必须返回一个标志EOF。为了区别于正常的字符,只好将EOF定义为负数(通常为-1)。因此函数getchar就成了int类型。
3、函数内部实现规则
(1) 在函数的"入口处",对参数的有效性进行检查
很多程序错误是由非法参数引起的,应当充分理解并正确使用断言"assert" 来防止此类错误。
(2) 在函数的"出口处",对return语句的正确性和效率进行检查。
return语句不可返回指向"栈内存"的"指针"或者"引用",因为该内存在函数体结束时被自动销毁。强行使用,会造成非法访问(等于访问了一块不再属于你的空间)。
4、断言
程序一般分为Debug版本和Release版本,Debug版本用于内部调试,Release版本发行给用户使用。
断言assert是仅在Debug版本起作用的宏,他用于检查"不应该"发生的情况。在运行过程中assert的参数为假,那么程序就会终止。
如果程序在assert处终止了,并不是说含有该assert的函数有错误,而是调用者出了差错,assert可以帮助我们找到发生错误的原因。
(1) 使用断言捕捉不应该发生的非法情况。不要混淆非法情况与错误情况之间的区别,错误情况是必然存在的并且一定要做出处理。
(2) 在函数的入口处,使用断言检查参数的有效性(合法性)。
(3) 在编写函数时要进行反复考察,如果不可能的事情的确发生了,则要用断言进行报警。

五、内存管理
1、内存分配
内存分配方式有三种:
(1)从静态存储区域分配
内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static 变量。
(2)在栈上创建
在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
(3)从堆上分配,亦称动态内存分配
程序在运行的时候用 malloc 或 new 申请任意多少的内存,程序员自己负责在何时用 free 或 delete 释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多。
在这里关于内存分配不过多赘述了,对这里不熟悉的同学,推荐看这篇文章---《C语言内存空间布局》,讲解十分详细。
在简单总结一下内存分配的几种常见错误吧!
(1)内存分配未成功,却使用了它。
(2)内存分配成功,但尚未初始化就引用它。
(3)内存分配成功并且已初始化,但操作越过了内存的边界。
(4)忘了释放内存。动态内存的申请与释放必须配对,程序中malloc与free的次数一定要相同,否则肯定有错误(new与delete同理)。
(5)内存释放了却继续使用它。
2、指针与数组
(1)对比
数组在静态存储区(全局数组)或者在栈上被创建。数组名对应着(而不是指向)一块内存,其地址与容量在生命期内保持不变,只有数组的内容可以改变。
指针可以随时指向任意类型的内存块,它的特征是"可变",常用指针来操作动态内存。指针远比数组灵活,但也更危险。
(2)内容的复制与比较
不能对数组名进行直接复制与比较。若想把数组a的内容复制给数组b,应该用标准库函数strcpy进行复制。比较a与b的内容是否相等,应该也用标准库函数strcmp进行比较。
若要复制数组a的内容,应用malloc申请strlen(a)+1个字节的内存空间,再用strcpy进行字符串复制。
(3)内存容量
用运算符sizeof可以计算出数组的容量(字节数)。
C/C++没有办法知道指针所指的内存容量,除非在申请内存时记住它。
3、free和delete
free和delete只是把指针所指向的空间释放掉,但并没有把指针本身干掉。

切记要初始化指针,释放指针后要置成空指针。要么将指针设置为 NULL,要么让它指向合法的内存。例如:
char *p = NULL; *char *str = (char *) malloc(100);
4、动态内存释放

(1) 指针消亡了,并不表示他所指的内存会被自动释放。
(2) 内存被释放了,并不表示指针会消亡或者成了NULL指针。
(3)程序终止运行,一切指针都会消亡,动态内存会被操作系统回收。
5、内存耗尽
如果在申请动态内存时找不到足够大的内存块,malloc 和 new 将返回 NULL 指针,宣告内存申请失败。通常有三种方式处理“内存耗尽”问题。
(1) 判断指针是否为NULL,如果是则马上用return语句终止本函数。
(2) 判断指针是否为NUL,如果是则马上用exit(1)终止整个程序的运行。
(3) 为new和malloc设置异常处理函数。
对于 32 位以上的应用程序而言,无论怎样使用malloc 与 new,几乎不可能导致“内存耗尽”。
6、malloc和free使用
malloc函数原型如下:
int *p = (int *) malloc(sizeof(int) * length);
(1)malloc返回值是void* ,在调用malloc时要显式地进行类型转换,将void*转换成所需要的指针类型。
(2)malloc函数本身不识别要申请的内存是什么类型,他只关心内存的总字节数。
(3)在malloc的"()"中使用sizeof运算符是良好的风格。
free函数原型如下:
void free(void *memblock);为什么free函数不像malloc函数那样复杂呢?这是因为指针的类型以及它所指向的内存的容量事先都是知道的,语句free()能正确地释放内存。如果该指针是NULL指针,那么free对指针无论操作多少次都不会出现问题。如果该指针不是NULL指针,那么free连续操作两次就会导致程序运行错误。
本篇文章是我在学习林锐博士的《高质量的C/C++编程》及一些其他网络资料之后进行的一篇自我学习总结。由于对C++还不是很熟悉,所以本篇文章主要总结了C语言部分,在日后深入学习C++时,在进行详细补充。如果本篇文章哪里出现问题,感谢大家能够指正。