#ai作画
目录
一.AI绘画的概念
1. 数据集准备:
2. 模型训练:
3. 生成绘画:
二.AI绘画的应用领域
三.AI绘画的发展
四.AI绘画背后的技术剖析
1.AI绘画的底层原理
2.主流模型的发展趋势
2.1VAE — 伊始之门
2.2GAN
2.2.1GAN相较于Diffusion有什么不足?
2.3Diffusion — 当今首峰
2.4CLIP—图文匹配
2.5Lora模型
2.6Controlnet模型
五.AI绘画实例
六.未来AI的发展趋势
一.AI绘画的概念
AI 绘画是一种利用人工智能技术生成绘画作品的方法。它基于机器学习和深度学习算法,通过对大量的图像数据进行训练,模型学习到了图像的特征和规律,从而能够生成新的图像。
AI 绘画的过程通常包括以下几个步骤:1. 数据集准备:
收集大量的图像数据,这些数据可以包括各种风格、主题的绘画作品。
2. 模型训练:
使用准备好的数据集对 AI 模型进行训练,让模型学习图像的特征和规律
3. 生成绘画:
输入一些关键词、描述或参考图像等信息,模型根据这些信息生成新的绘画作品。

AI 绘画技术可以生成各种风格的图像,例如写实、抽象、漫画、油画等。它可以帮助艺术家和设计师更快地创建概念设计、探索不同的风格,也可以为普通人提供一种创造艺术的新方式。



二.AI绘画的应用领域
- 设计行业:在广告、游戏、影视等领域,帮助设计师更快地生成概念图和原型。
- 艺术创作:艺术家可以利用 AI 绘画来探索新的风格和创意,或者与 AI 共同创作。
- 教育领域:学生可以通过 AI 绘画工具学习绘画技巧和艺术风格。
- 社交媒体:用户可以用 AI 生成的图像来装饰自己的社交媒体账号。
- 虚拟现实和增强现实:为这些应用创建虚拟场景和角色的图像。


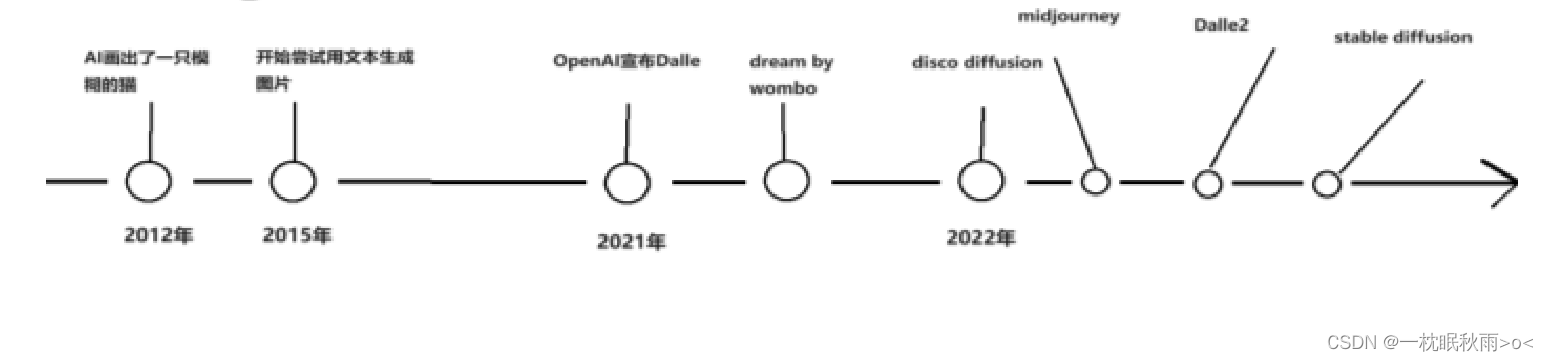
三.AI绘画的发展
Diffusion 一般指 Diffusion Model(扩散模型),是一种基于深度学习的生成模型,常用于图像生成领域。Diffusion Model 的训练可以分为正向扩散和反向扩散两部分。
正向扩散过程逐步对输入图像加入高斯噪声,一共有 T 步,该过程将产生一系列噪声图像样本 x₁, ..., x_T。当 T → ∞ 时,最终的结果将变成一张完全包含噪声的图像。
反向扩散过程则是去除图像中的噪声。通过不断迭代去噪,模型可以学习到如何从噪声中恢复出原始图像,从而实现图像生成。
除此之外,Diffusion 还可能指 Stable Diffusion,它是一款免费、开源的 AI 图像生成器,由 Stability AI 公司于2022年8月推出。Stable Diffusion 应用于 AI 软件,用户可以随意输入自己想要的内容,然后系统就会自动生成非常优秀的艺术渲染作品。



Midjourney是一个基于人工智能技术的图像生成程序,由UISDC研究实验室开发。它可以根据用户输入的文本自动生成图片。该程序自2022年7月12日开始公开测试,主要通过Discord平台上的机器人指令进行操作,允许用户创造各种图像作品。
Midjourney利用深度学习和神经网络等先进技术,对大量图像进行学习和训练,从而提升图像的质量和准确性。

Dalle是美国人工智能非营利组织OpenAI于2021年1月份推出的一个可以根据书面文字生成图像的人工智能系统,该名称来源于著名画家达利(Dalí)和机器人总动员(Wall-E)。

四.AI绘画背后的技术剖析
1.AI绘画的底层原理
神经网络左侧输入一些列数字,神经网络会按照圆圈里的计算规则及连线的权重,把数字从左到右计算和传递,最终,从最右侧的圆圈输出一系列数字。
然后将一串数字输入到没有训练过得神经网络模型,也会生成一串数字,只不过解码后可能就是一张乱码图片,所以需要大量数据和不断调整算法参数的权重
2.主流模型的发展趋势
2.1VAE — 伊始之门
VAE(变分自编码器)是一个深度生成模型,其最终目的是生成出概率分布P(x)。在VAE中,通过高斯混合模型(Gaussian Mixture Model)来生成P(x),也就是说P(x)是由一系列高斯分布叠加而成的,每一个高斯分布都有它自己的参数μ和σ。
为了找到隐变量Z与观察数据X之间的映射关系,VAE使用神经网络来拟合。具体来说,假设隐变量Z服从N(0, I)分布,并寻找一个映射关系将向量z映射成这一系列高斯分布的参数向量μ和σ。有了这一系列高斯分布的参数,就可以得到叠加后的P(x)的形式。
VAE模型与EM算法的推导有相似之处,但区别在于VAE模型中的隐变量Z是一个连续的无穷维向量,而EM算法中的隐变量是离散的。在VAE的参数估计中,由于隐变量数量假设是高维无限的,所以用神经网络去拟合,而不是使用极大似然估计1。
2.2GAN
GAN 是由生成器和判别器组成的网络,生成器试图生成逼真的假图像,而判别器则试图区分真假图像。在训练过程中,生成器不断地改进自己的生成能力,而判别器则不断地提高自己的识别能力。最终,生成器可以生成与真实图像难以区分的假图像。
生成器使用的是卷积神经网络(CNN),它可以对图像进行特征提取和分类。CNN 可以将图像分成不同的层,每一层都代表了图像的不同特征。生成器使用这些特征来生成新的图像。
判别器使用的是循环神经网络(RNN),它可以对序列数据进行处理,如文本描述。RNN 可以对序列中的每个元素进行处理,并将其与之前的元素进行关联,以更好地理解整个序列。生成器使用的是卷积神经网络(CNN),它可以对图像进行特征提取和分类。CNN 可以将图像分成不同的层,每一层都代表了图像的不同特征。生成器使用这些特征来生成新的图像。
GAN的应用场景有哪些?
GAN的应用场景非常广泛,在图像生成,生成不存在的人物、物体、动物;图像修复、图像增强、风格化和艺术的图像创造等。不一一列举,想要详细了解的可以看链接:
2.2.1GAN相较于Diffusion有什么不足?
1.GAN的训练过程过程相对不稳定,生成器和判别器之间的平衡很容易打破,容易导致模型崩溃或崩塌问题;
2.判别器不需要考虑生成样品的种类,而只关注于确定每个样品是否真实,这使得生成器只需要生成少数高质量的图像就足以愚弄判别者;
3.生成的图像分辨率较低;
因此,以GAN模型难以创作出有创意的新图像,也不能通过文字提示生成新图像。
2.3Diffusion — 当今首峰
扩散模型是一种深度生成模型,主要用于图像和音频的生成。它们在生成模型领域中表现出色,例如在图像生成方面,Dalle2和稳定扩散模型就是基于扩散模型的优秀代表。扩散模型的基本思想是通过一个前向扩散过程逐渐破坏数据分布中的结构,然后通过学习反向扩散过程来恢复这些结构,从而生成高度灵活且易于处理的数据。在训练过程中,模型会学习预测每个时间步的噪声,最终能够从高斯噪声输入中生成高分辨率的图像。扩散模型由两个阶段组成:使用时间表来缩放平均值和方差,并在每个时间步添加噪声。前向过程的数学定义可以表示为:q(xₜ|xₜ₋₁) = N(xₜ; sqrt{1-βₜ}xₜ, βₜI),其中正态分布由均值和方差参数化。
2.4CLIP—图文匹配
CLIP 模型 是一项由 OpenAI 开发的预训练模型,主要用于对比语言-图像的预训练任务。以下是关于 CLIP 的一些详细信息:
1.全称:CLIP代表Contrastive Language-Image Pre-Training,即对比语言-图像预训练。
2.主要功能:CLIP旨在通过大规模的图像-文本对数据进行对比性训练,以实现图像和文本的嵌入空间的对齐,以及跨模态的语义对齐。
3.结构:CLIP包含两个模态,分别是文本模态和视觉模态。文本模态负责对文本进行编码,得到其Embedding;视觉模态负责对图片进行编码,也得到其Embedding。这两个Embedding都是单向向量的长度。
4.训练原理:在训练过程中,CLIP会将文本和图像成对地进行编码,然后计算它们的相似度。对于每个批次的训练样本,CLIP会预测出所有可能的文本-图像对的相似度,这些相似度是通过文本特征和图像特征的余弦相似性计算的。
5.应用场景:CLIP不仅在文本图像检索方面表现出色,还可以应用于Zero-Shot Learning,即在没有特定训练的情况下识别新事物的视觉概念。
6.训练数据:CLIP的训练数据主要是文本-图像对,其中包括一张图像及其对应的文本描述。这种数据形式使得CLIP能够在互联网的海量数据中发现相关联的信息。
7.性能:CLIP在多个任务上的表现达到目前最佳水平
综上所述,CLIP 模型是一个多模态预训练模型,它在自然语言理解和计算机视觉分析之间建立了联系,并在多个领域展示了出色的性能和应用潜力。
2.5Lora模型
LoRA模型全称是:Low-Rank Adaptation of Large Language Models,可以理解为Stable-Diffusion中的一个插件,仅需要少量的数据就可以进行训练的一种模型。在生成图片时,LoRA模型会与大模型结合使用,从而实现对输出图片结果的调整。
2.6Controlnet模型
Controlnet就是控制网的意思,其实就是在大模型外部通过叠加一个神经网络来达到精准控制输出的内容。很好的解决了单纯的关键词的控制方式无法满足对细节控制的需要,比微调模型更进一步对图像生成的控制。









五.AI绘画实例
宇宙之中,众星环绕,有一颗独特且耀眼的恒星

六.未来AI的发展趋势
未来AI绘画可能会有以下发展趋势:
- 个性化创作:AI绘画将能够根据用户的喜好和情绪来创作作品,通过深度学习和大数据分析,描绘出丰富多元的艺术作品。
- 人机协作:艺术家可以与AI系统合作,将人的创意与机器的计算能力结合在一起,创作出前所未有的艺术作品。这样的协作可以拓展艺术的边界,开创更多的可能性。
- 虚拟现实(VR)与增强现实(AR)的结合:AI绘画将与这些技术结合,为用户提供更加沉浸和互动的艺术体验。
- 实时艺术创作:AI绘画将实现实时创作,即艺术作品可以根据实时数据和事件进行动态的变化和调整。


![[rust] 10 project, crate, mod, pub, use: 项目目录层级组织, 概念和实战](https://img-blog.csdnimg.cn/direct/6efe237d8eb641bda3e4fd1ea0fef2fc.png)




![Python算法题集_实现 Trie [前缀树]](https://img-blog.csdnimg.cn/direct/5a897d6e99aa4f639286febc56714d68.png#pic_left)
![[electron]官方示例解析](https://img-blog.csdnimg.cn/direct/fdd74d254f754b21964f63e454af6ebb.png)