本文介绍在autodl.com搭建gpu服务器,实现stable-diffusion-webui+sadTalker功能,图片+音频 可生成视频。
autodl租GPU
自己本地部署SD环境会遇到各种问题,网络问题(比如huggingface是无法访问),所以最好的方式是租用GPU,可以通过以下视频了解如何使用autodl.com
AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
炼丹平台AutoDL的简单使用_哔哩哔哩_bilibili
autoDL比较好的点就是上边有很多大佬已经部署好的环境镜像,直接使用就行。

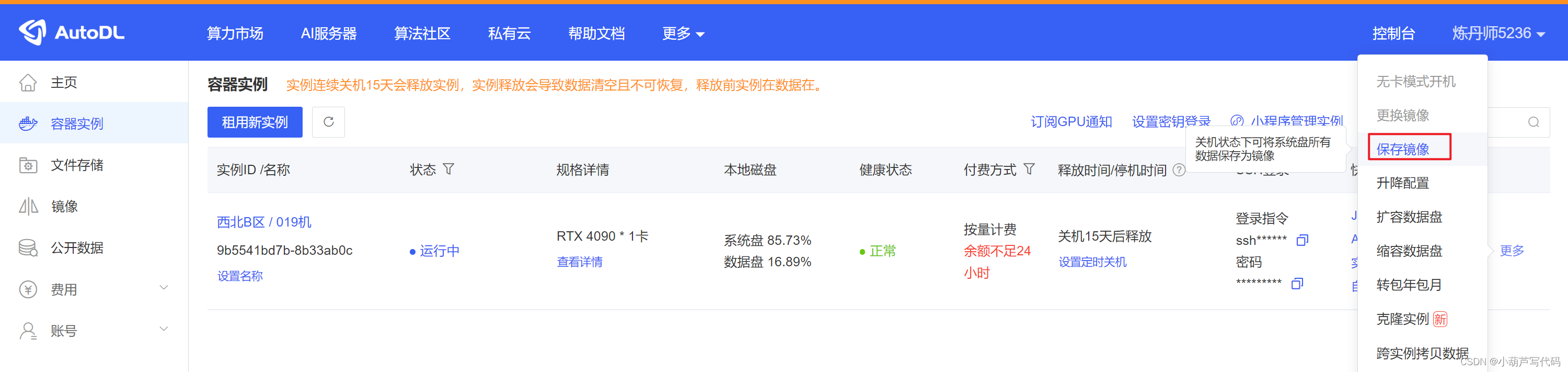
如图是我租用的一个GPU实例。
选择的镜像是 小李xiaolxl AUTOMATIC1111/stable-diffusion-webui的v15.3版本。

镜像使用说明见大佬的视频介绍:
AI绘画云端部署-整合版4.0正式发布 | 全新重构启动3.0 | 全流程教程_哔哩哔哩_bilibili
安装SadTalker
SadTalker git 点击这里。
sadTalker插件安装
stable-diffusion-webui安装SadTalker插件的方式很多,我这里使用从url安装的方式。

别忘了开启加速

插件安装成功后,开始下载模型。
模型下载
SadTalker需要两种模型,checkpoints和gfpgan。下载方式推荐如下两种。
从git下载

阿里云魔搭下载
魔搭社区

模型下载好,需要将模型放到GPU服务器上。
autodl.com支持直接从云盘把文件拷贝到实例,详细可参考如下:
AutoDL帮助文档
我用的是阿里云盘,因为百度云盘的鉴权比骄麻烦。我这边实测如果从阿里云盘拷贝模型到autodl.com,速度能达到10MB/s以上。

模型文件放置的位置如下:
stable-diffusioni-webui/SadTalker下建立两个文件夹,checkpoints和gfpgan



这里有个要注意的点:模型文件的权限都要改成777(chmod -R 777 ./*),因为sd-webui启动时会切换到其他的user,如果模型文件没有访问权限,就会重新发起模型下载

重启webui
在extension里点击 apply and quit,就会重启webui重新加载。

测试生成视频
sadTalker的使用方式是 图片+声音 生成视频。
文字转语音工具
我使用的微信小程序,搜索:配音家,使用很方便,文字输入就能导出音频。

测试生成视频

保存当前镜像
autodl.com支持把当前的环境保存成自己的镜像,以后自己直接使用,非常方便。