目录
- 1. 问题所示
- 2. 基本知识
- 3. API Demo
- 4. 示例Demo
- 5. 彩蛋
1. 问题所示
从实战上手基础知识
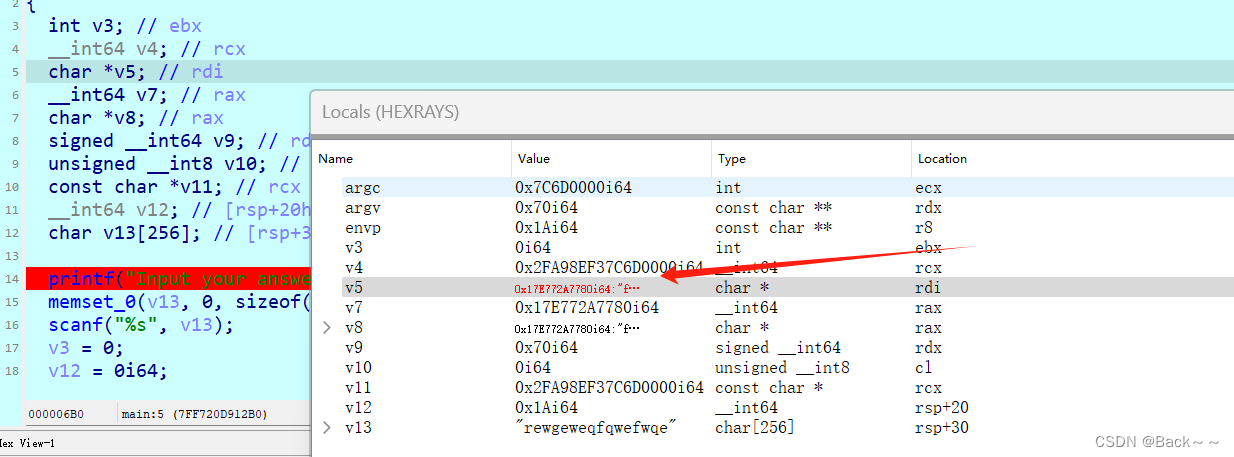
一开始遇到这个Bug:
TypeError: unsupported operand type(s) for -: 'str' and 'float'
后面经了解执行减法运算时发生了错误,其中一个操作数是字符串类型,另一个操作数是浮点数类型
例如:
x = "5"
y = 3.14
result = x - y # 尝试对字符串和浮点数执行减法运算
要解决这个问题必须强转化某个类型!
但是转化好之后发现还是报错:TypeError: cannot convert the series to <class 'float'>
说明不能这么转化!
例如:
import pandas as pd# 创建一个包含字符串的Series对象
s = pd.Series(['1.2', '3.4', '5.6'])# 尝试将Series对象转换为float类型
s_float = float(s)
为了解决这个问题,先确保Series对象中的所有值都可以被转换为float类型
可以使用pd.to_numeric()函数来尝试将Series中的值转换为数值类型
示例如下:
import pandas as pd# 创建一个包含字符串的Series对象
s = pd.Series(['1.2', '3.4', '5.6'])# 尝试将Series对象转换为float类型
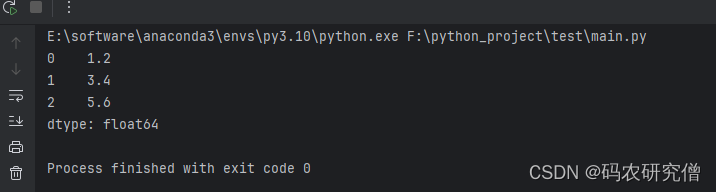
try:s_float = pd.to_numeric(s)print(s_float)
except ValueError as e:print("Error:", e)
截图如下:
以上主要是一个Demo层层递进,为了引出Series对象
实际在工作中Bug如下:
res['days'] = res['堆存期'].astype(int) - res['free'].astype(int)
res['天数差额'] = float(res['天']) - res['days']
对应修改为:
# 将 '天' 列转换为浮点数类型
res['天'] = res['天'].astype(float)# 执行数学运算
res['days'] = res['堆存期'].astype(int) - res['free'].astype(int)
res['天数差额'] = res['天'] - res['days']
2. 基本知识
-
Pandas 库中的一种基本数据结构,它类似于带有索引的一维数组
-
由一组数据以及与之相关联的索引组成,可以存储不同类型的数据,并提供了许多方便的方法和功能,使数据的处理和分析变得更加简单和高效
Series 对象的作用:
- 数据存储:Series 可以存储各种类型的数据,包括整数、浮点数、字符串、日期等
- 数据操作:提供了丰富的方法和功能,可以对数据进行快速、灵活的操作和处理,如索引、切片、过滤、排序、聚合等
- 数据对齐:在进行数学运算或操作时,Series 对象会根据索引自动对齐数据,确保相同索引的数据进行对应操作
- 数据可视化:可以方便地利用 Series 对象进行数据可视化,如绘制折线图、柱状图等
3. API Demo
常用API如下:
| 方法 | 具体描述 |
|---|---|
| pd.Series(data, index=index) | 创建一个 Series 对象,其中 data 可以是列表、字典、数组等,index 是可选参数,用于指定索引 |
| series.values | 返回 Series 对象的值,以 NumPy 数组形式返回 |
| series.index | 返回 Series 对象的索引 |
| series.head(n) | 返回 Series 对象的前 n 个值,默认为前 5 个 |
| series.tail(n) | 返回 Series 对象的后 n 个值,默认为后 5 个 |
| series.astype(dtype) | 将 Series 对象的数据类型转换为指定类型 |
| series.isnull() / series.notnull() | 返回一个布尔型的 Series 对象,用于判断是否缺失数据 |
| series.dropna() | 删除缺失数据 |
| series.fillna(value) | 填充缺失数据 |
| series.unique() | 返回 Series 对象中的唯一值 |
| series.nunique() | 返回 Series 对象中的唯一值的数量 |
| series.describe() | 返回 Series 对象的描述统计信息 |
| series.map(func) | 对 Series 对象的每个元素应用指定的函数 |
通过Demo更好的了解其接口含义
pd.Series(data, index=index)
创建一个 Series 对象,其中 data 可以是列表、字典、数组等,index 是可选参数,用于指定索引
下面是通过列表创建:
import pandas as pd
import numpy as np# pd.Series(data, index=index)
data_list = [1, 2, 3, 4, 5]
index_list = ['A', 'B', 'C', 'D', 'E']
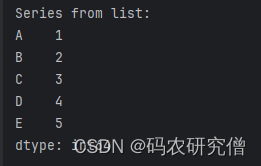
series_from_list = pd.Series(data_list, index=index_list)
print("Series from list:")
print(series_from_list)
输出结果如下:
这是从一个字典中抽取,注意与上面的区别:
series_from_list 输出值是从一个列表创建的,使用了指定的索引。series_from_dict 输出值是从一个字典创建的,字典的键被用作索引。
data_dict = {'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5}
series_from_dict = pd.Series(data_dict)
print("\nSeries from dictionary:")
print(series_from_dict)
输出结果如下:
(输出结果与上面一样,虽然两者都创建了类似的 Series 对象,但是数据的来源和索引的指定方式略有不同)

这是从一个数组中抽取:
data_array = np.array([1, 2, 3, 4, 5])
index_array = ['A', 'B', 'C', 'D', 'E']
series_from_array = pd.Series(data_array, index=index_array)
print("\nSeries from array:")
print(series_from_array)
截图如下(与上面一致):

以下为一些属性输出


配合其属性值输出,此时本身为数组
- 此时强转换为list:
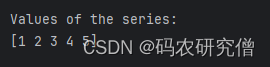
# series.values
print("\nValues of the series:")
print(series_from_list.values) # 输出
截图如下:
- 对应查看index索引值:
# series.index
print("\nIndex of the series:")
print(series_from_list.index)
截图如下:

- 返回 Series 对象的前 n 个值:
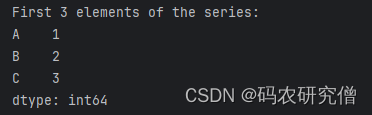
# series.head(n)
print("\nFirst 3 elements of the series:")
print(series_from_list.head(3))
截图如下:
- 返回 Series 对象的后 n 个值
# series.tail(n)
print("\nLast 3 elements of the series:")
print(series_from_list.tail(3))
截图如下:

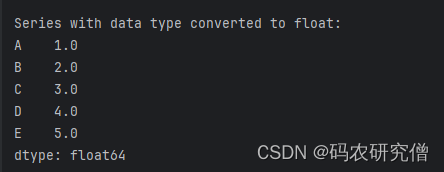
- 将 Series 对象的数据类型转换为指定类型
# series.astype(dtype)
print("\nSeries with data type converted to float:")
print(series_from_list.astype(float))
截图如下:
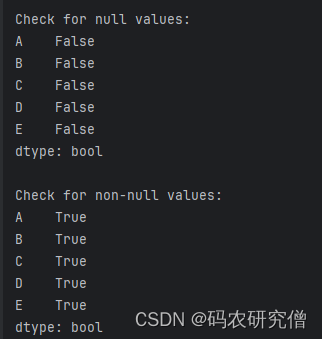
- 返回一个布尔型的 Series 对象,用于判断是否缺失数据
# series.isnull() / series.notnull()
print("\nCheck for null values:")
print(series_from_list.isnull())
print("\nCheck for non-null values:")
print(series_from_list.notnull())
截图如下:
- 删除缺失数据
# series.dropna()
series_with_nan = pd.Series([1, 2, np.nan, 4, np.nan])
print("\nSeries with NaN values:")
print(series_with_nan)
print("\nSeries with NaN values dropped:")
print(series_with_nan.dropna())
截图如下:

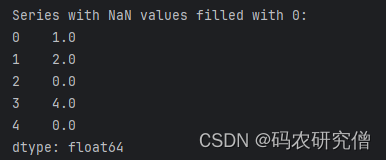
- 填充缺失数据
# series.fillna(value)
print("\nSeries with NaN values filled with 0:")
print(series_with_nan.fillna(0))
截图如下:
- 返回 Series 对象中的唯一值
# series.unique()
series_with_duplicates = pd.Series([1, 2, 2, 3, 3, 4, 4])
print("\nSeries with duplicates:")
print(series_with_duplicates)
print("\nUnique values in the series:")
print(series_with_duplicates.unique())
截图如下:

- 返回 Series 对象中的唯一值的数量
# series.nunique()
print("\nNumber of unique values in the series:")
print(series_with_duplicates.nunique())
截图如下:

- 返回 Series 对象的描述统计信息
# series.describe()
print("\nDescription of the series:")
print(series_with_duplicates.describe())
截图如下:

- 对 Series 对象的每个元素应用指定的函数
# series.map(func)
def square(x):return x ** 2print("\nSeries with each element squared:")
print(series_from_list.map(square))
截图如下:

4. 示例Demo
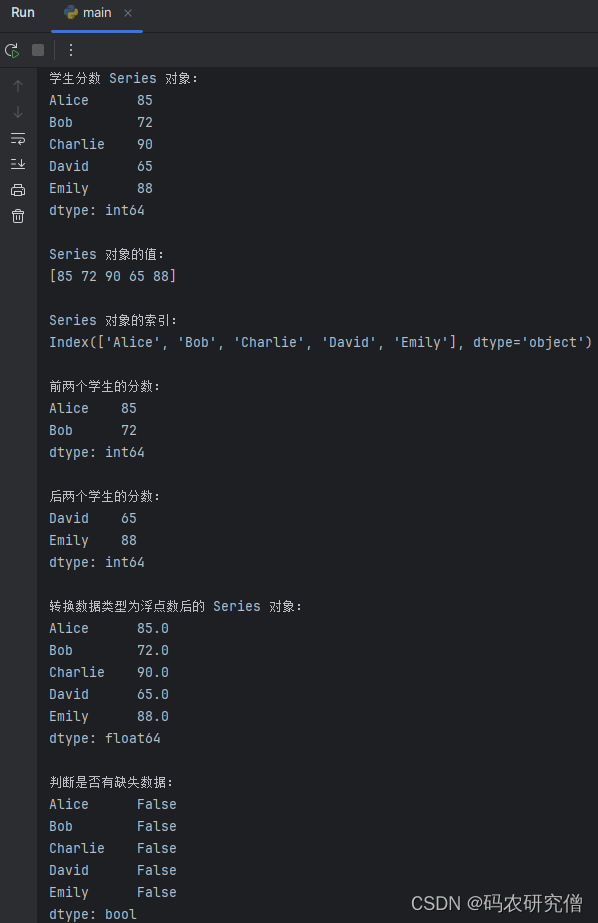
上述的API可能还有些抽象,放在实战Demo中加深印象:
import pandas as pd# 创建学生分数的字典
student_scores = {'Alice': 85, 'Bob': 72, 'Charlie': 90, 'David': 65, 'Emily': 88}# 创建 Series 对象
scores_series = pd.Series(student_scores)# 输出 Series 对象
print("学生分数 Series 对象:")
print(scores_series)# 输出 Series 对象的值和索引
print("\nSeries 对象的值:")
print(scores_series.values)
print("\nSeries 对象的索引:")
print(scores_series.index)# 输出前两个学生的分数
print("\n前两个学生的分数:")
print(scores_series.head(2))# 输出后两个学生的分数
print("\n后两个学生的分数:")
print(scores_series.tail(2))# 将分数的数据类型转换为浮点数
scores_series_float = scores_series.astype(float)
print("\n转换数据类型为浮点数后的 Series 对象:")
print(scores_series_float)# 判断是否有缺失数据
print("\n判断是否有缺失数据:")
print(scores_series.isnull())# 输出分数不为空的学生分数
print("\n分数不为空的学生分数:")
print(scores_series.dropna())# 填充缺失数据为0
scores_series_fillna = scores_series.fillna(0)
print("\n填充缺失数据为0后的 Series 对象:")
print(scores_series_fillna)# 输出学生分数的描述统计信息
print("\n学生分数的描述统计信息:")
print(scores_series.describe())# 对学生分数应用一个函数,比如加分10分
def add_bonus(score):return score + 10scores_series_bonus = scores_series.map(add_bonus)
print("\n每个学生的分数加10分后的 Series 对象:")
print(scores_series_bonus)
对应的结果截图如下:
以及
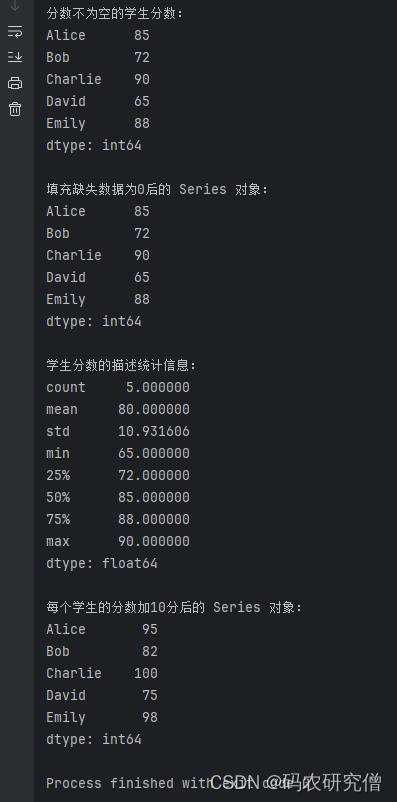
5. 彩蛋
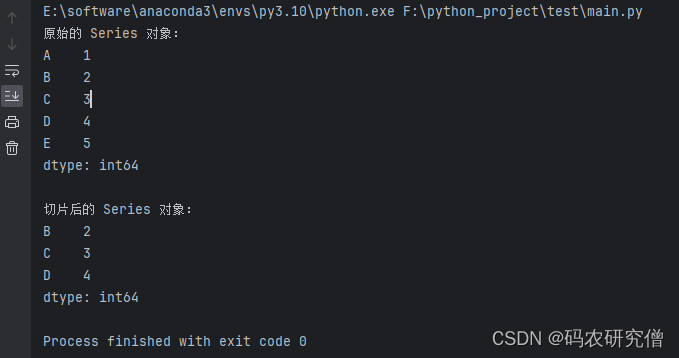
忘记补充一个知识点了,切片同样也可运用在该对象中
import pandas as pd# 创建一个 Series 对象
data = {'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5}
index = ['A', 'B', 'C', 'D', 'E']
series = pd.Series(data, index=index)# 输出原始的 Series 对象
print("原始的 Series 对象:")
print(series)# 切片操作:选取索引为'B'到'D'之间的元素
sliced_series = series['B':'D']# 输出切片后的 Series 对象
print("\n切片后的 Series 对象:")
print(sliced_series)
截图如下: