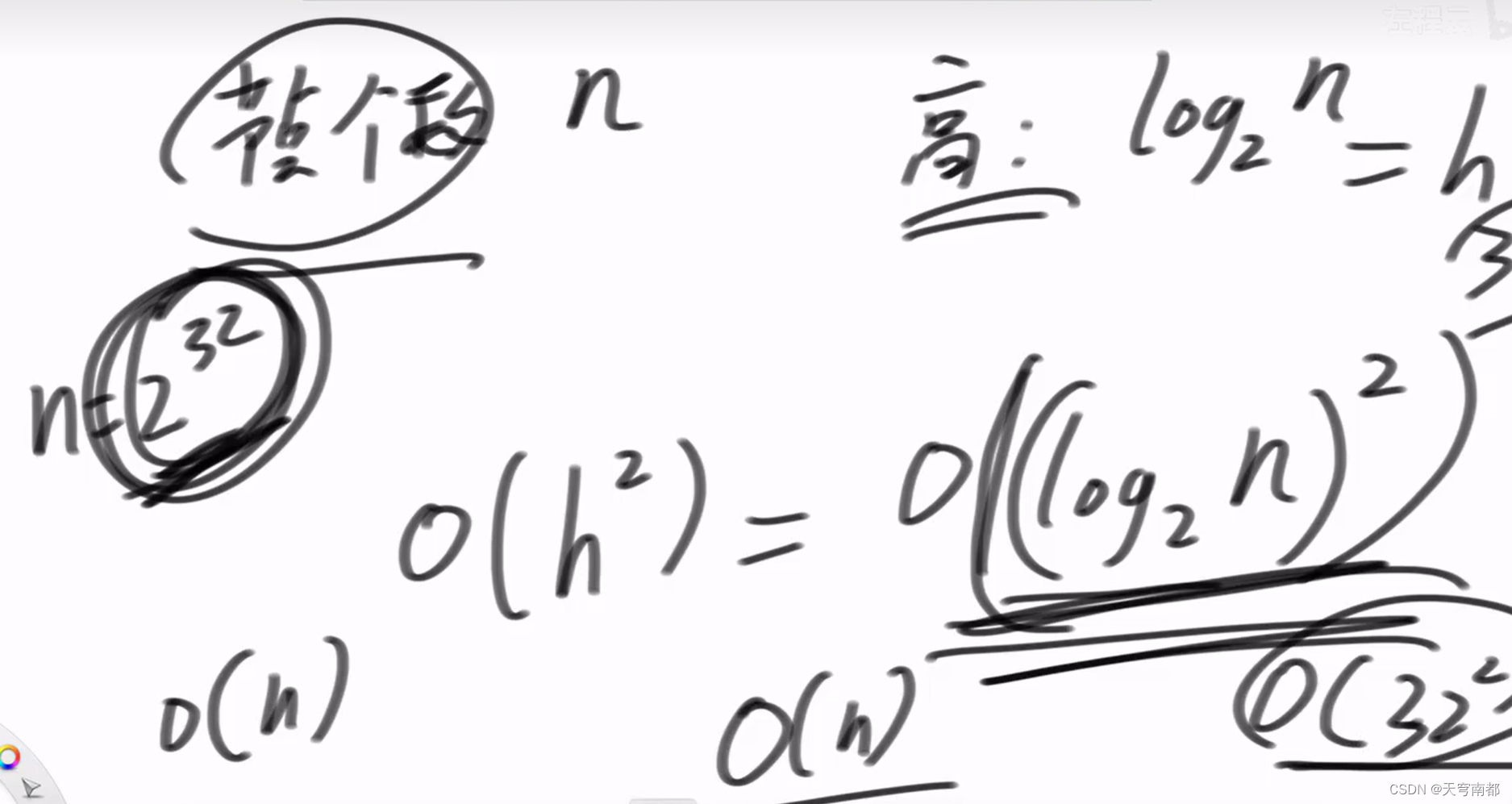set和map的使用
- 一.关联式容器:
- 1.简单概念:
- 2.<key , value>--->键值对
- 3.set和map的底层结构(平衡搜索树或者红黑树)
- 二.set
- 1.set (排序+不重复)
- 1.模板参数:
- 2.set是一个有序存储的容器:
- 3.set中每个数据有且只有一个:
- 4.set底层的特殊结构:
- 5.find和erase的使用:
- 6.count返回数值个数:
- 2.multiset(排序+允许重复)
- 1.set和multiset区别:
- 2.count的用武之地:
- 三.map
- 1.map(排序+不重复)
- 1.简单概念:
- 2.插入数据和多种初始化方式:
- 3.查找和删除:
- 4.count计数:
- 5.不允许重复key值插入:
- 6.数据统计:
- 7.operator[]的重载:(数据统计优化)
- 2.multimap(排序+允许重复)
- 1.map和mulitmap区别:
- 2.count的用武之地:
- 3.总结:multimap和map唯一不同的是:map中的key是唯一的,而multimap中的key值是可以重复的。
一.关联式容器:
1.简单概念:
1,map 和 set 是一个关联式容器,比较vector,queue , stack ,序列式的容器来说。关联式容器的结构对于数据的检索是更加方便的。
2.map和set是一种<key , value>的结构。
2.<key , value>—>键值对
SGI_STL中的键值对
通过类的模板参数实现不同类型数据的一一对应:
namespace sfpy {template<class T1, class T2>struct pair {typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;prir():first(T1()), second(T2()){}prir(const T1& a, const T2& b):first(a),second(b){}};
}
3.set和map的底层结构(平衡搜索树或者红黑树)
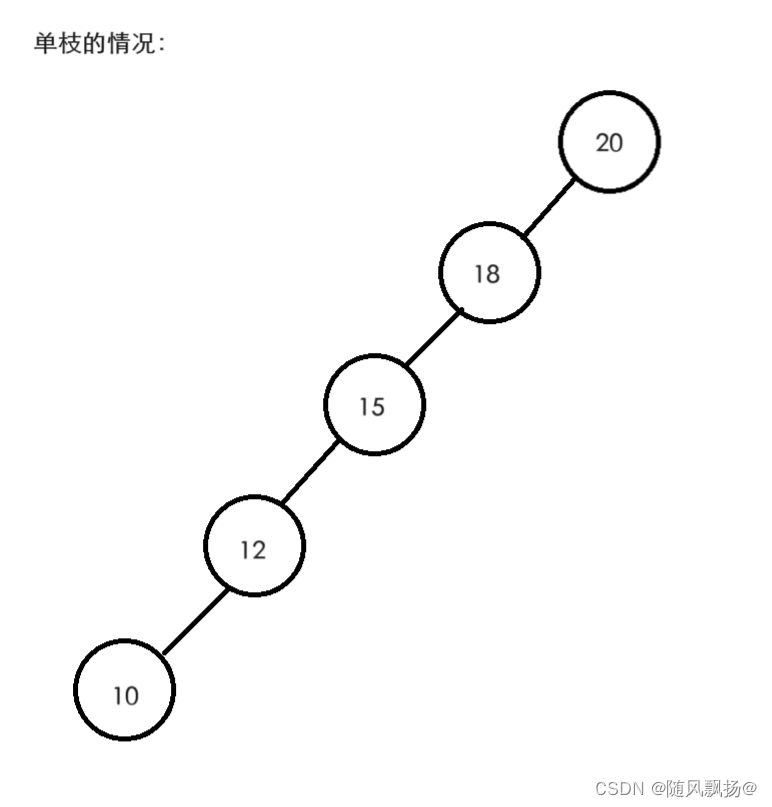
1.在特殊情况下我们的搜索二叉树会变成一个单枝的情况。
2.搜索的时间复杂度就大大降低,从高度到个数的复杂度变化。
3.平衡搜索树或者红黑树会在相同可能产生单枝的情况下进行数据的平衡调整,从而保证树的平衡性。
二.set
1.set (排序+不重复)
1.模板参数:

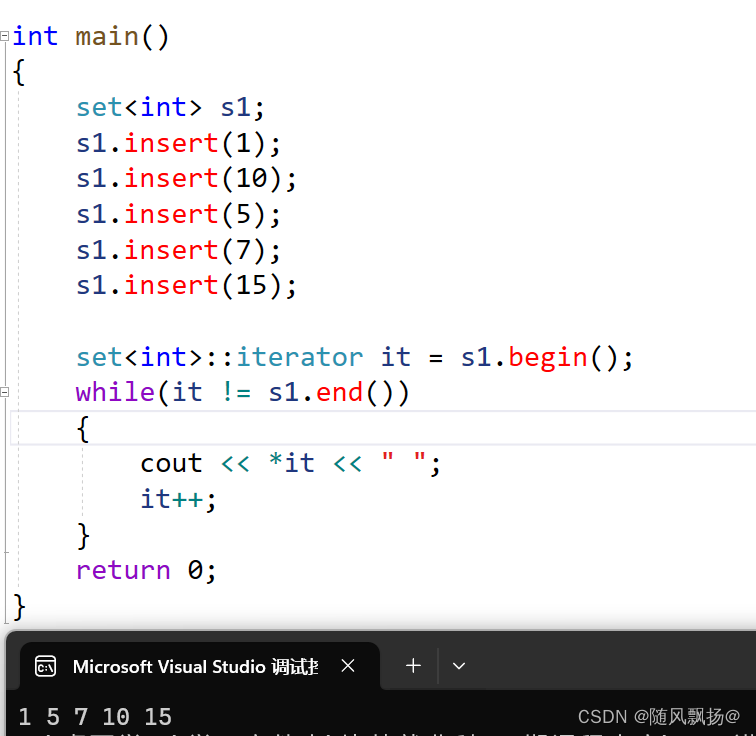
2.set是一个有序存储的容器:
1.insert进行数据的插入。
2.使用迭代器遍历数据。
3.set默认的比较方式是一个升序。
4.set中的数据是不可以随便进行修改的需要保证有序
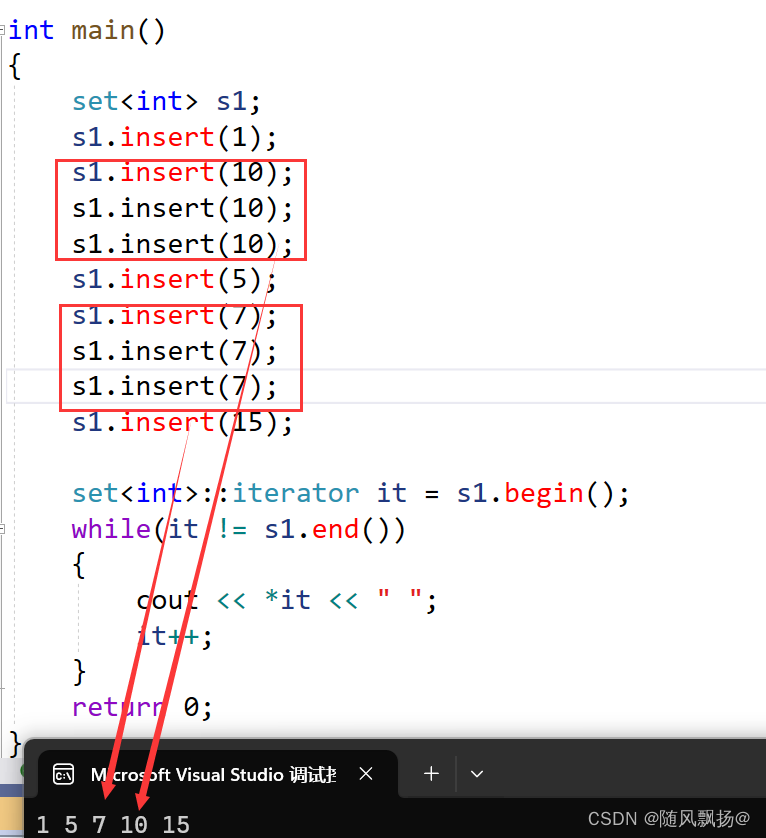
3.set中每个数据有且只有一个:
1.相同的数据不能存贮多个在set中。
2.set中每个数据有且只有一个。
4.set底层的特殊结构:
1.set中不存在<< key value>>的结构—>实际底层是 << value value>> 的结构
2.set在插入数据的时候其实对底层的pair的两个value都插入数据但是在上层我们只需要去插入一个数据,不需要考虑pair的存在。
5.find和erase的使用:


情况一
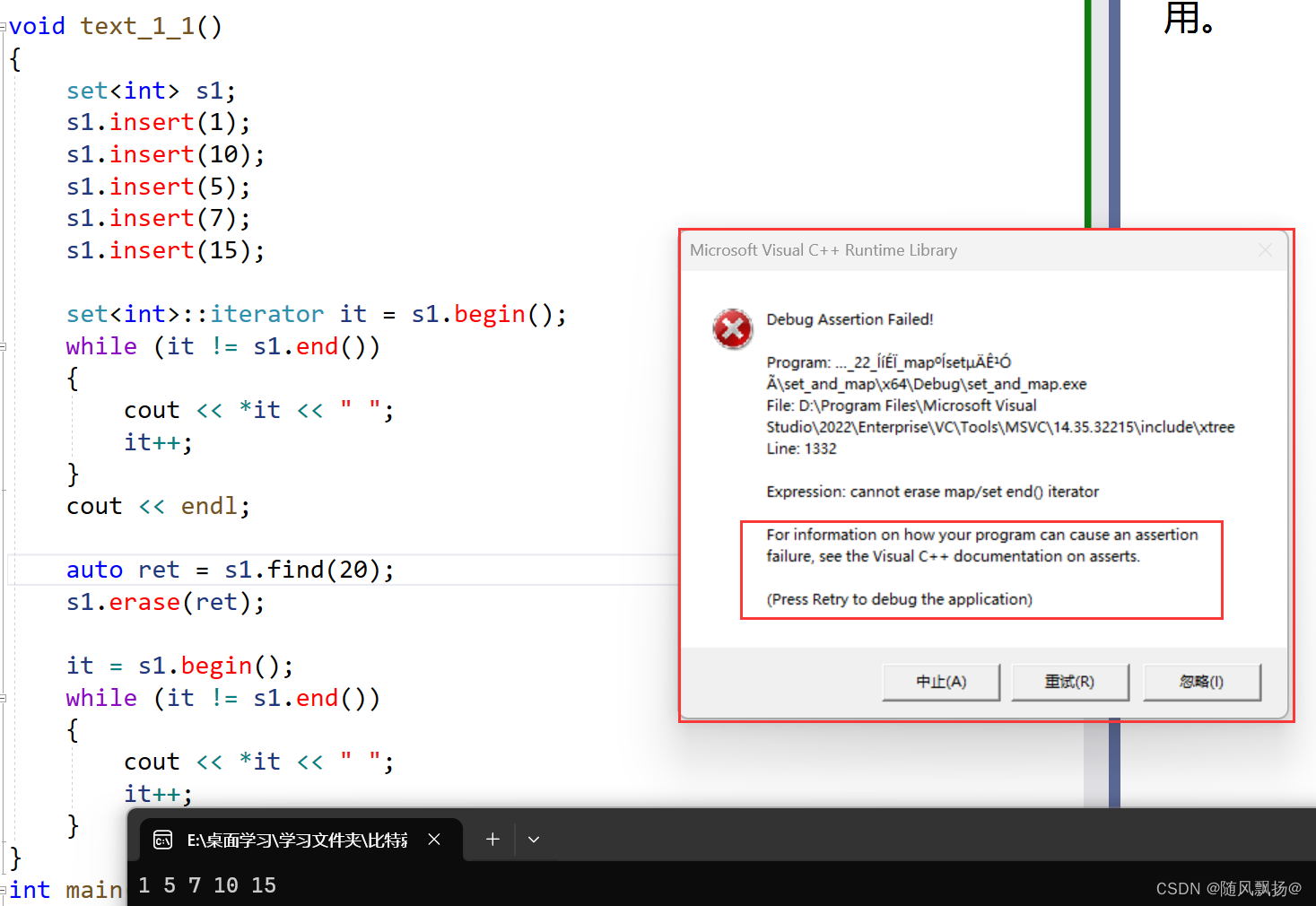
1,传数据的值,返回相同数据的迭代器,如果数据的不存在返回最后一个数值迭代器的下一个。
2.erase的重载一进行配合使用:
3.缺点:删除的数据一定存在否则一定报错。
删除数据存在的情况:
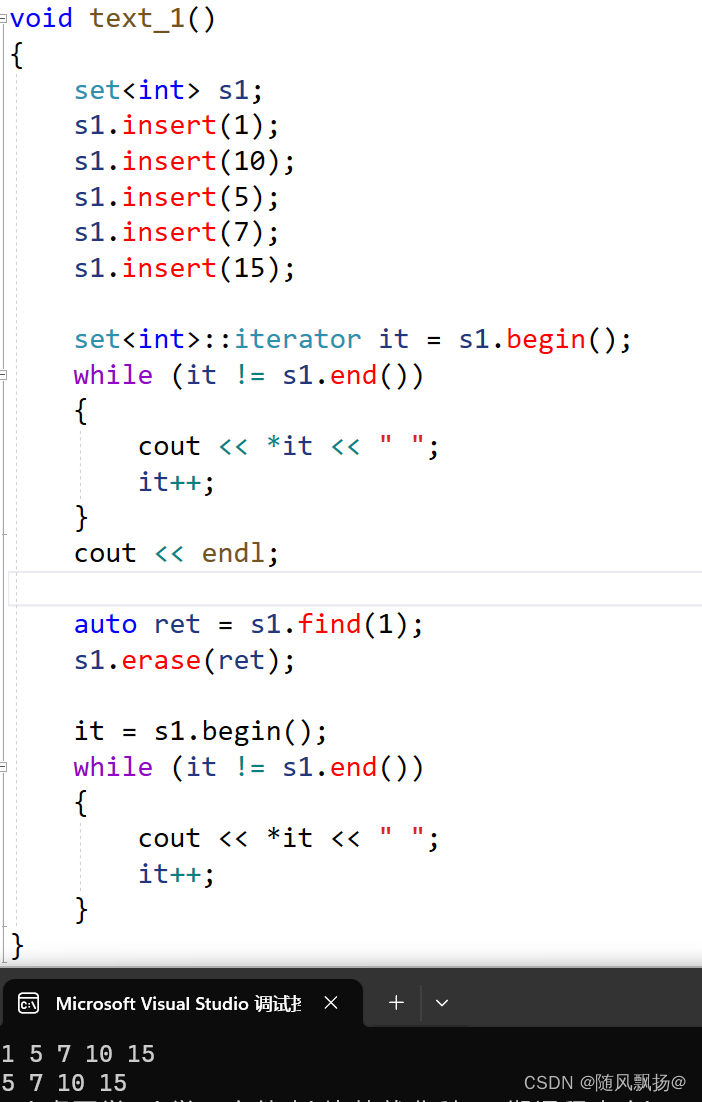
删除的数据不存在的情况:
情况二:
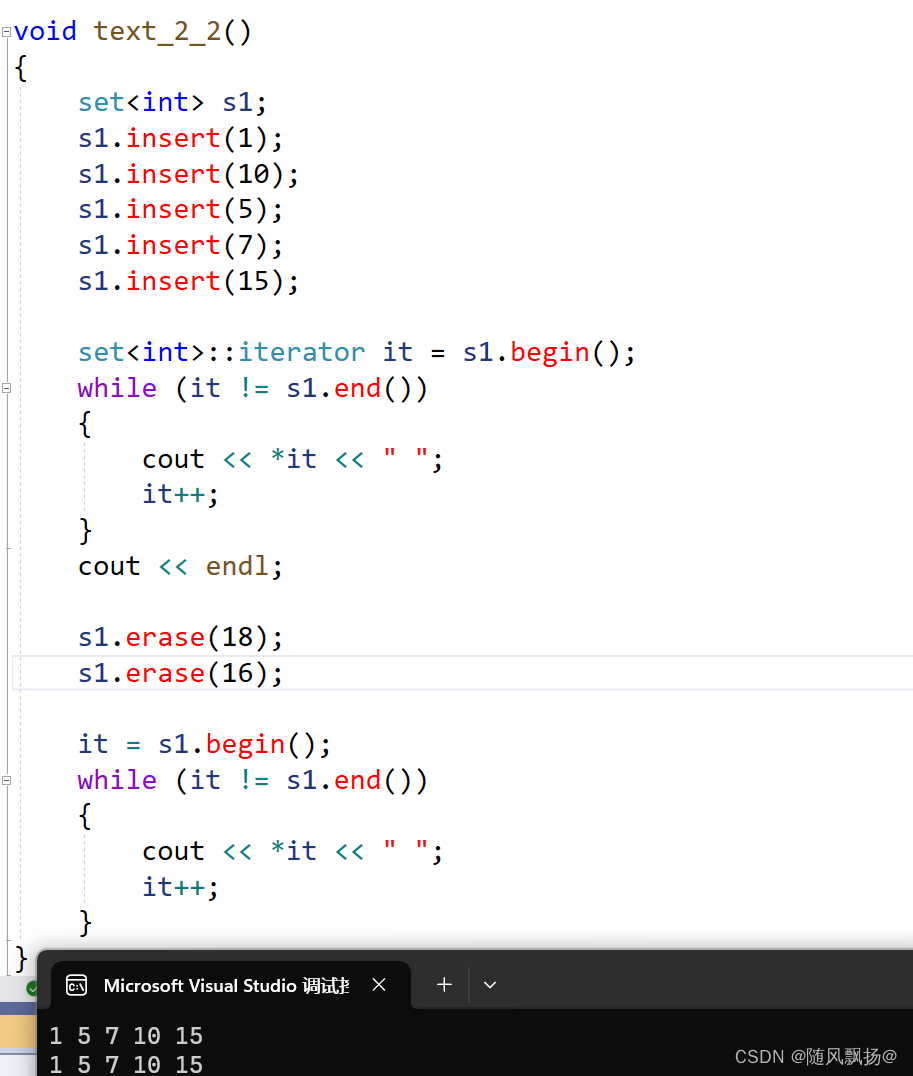
1.可以直接对erase传需要删除的数据的值。
2.情况一:存在就删除。
3.情况二:不存在就不删除,不会产生越界的问题。
情况一:存在就删除。
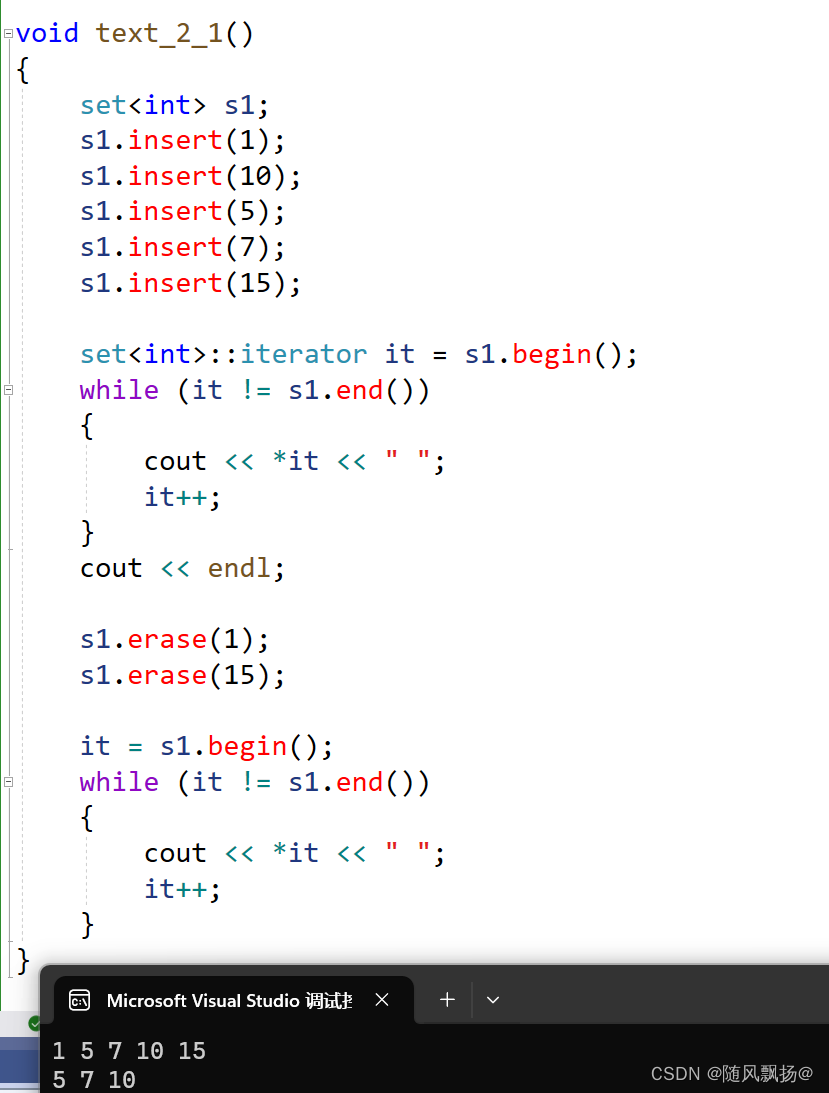
情况二:不存在就不删除,不会产生越界的问题
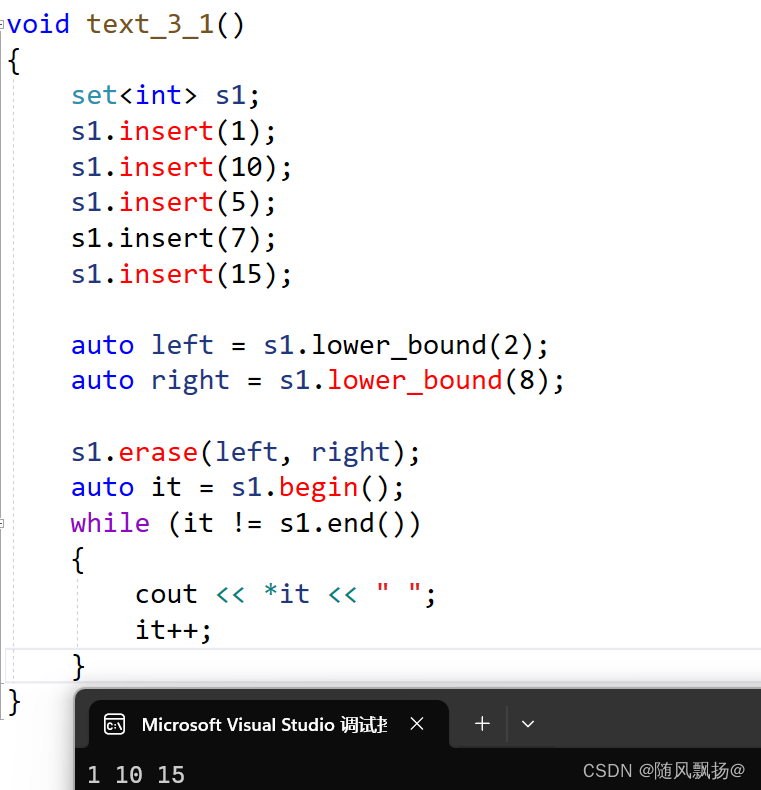
情况三:范围删除
1set的erase的范围删除是需要满足左闭右开的一个范围删除。
2.find的使用就不能非常好的满足条件?
3.find查找数据的依据是传参的数值是否在set中存在!
4.显然find的查找范围就非常的不靠谱,set中提供了两个方法。
5.lower_bound 和 upper_bound


6.count返回数值个数:
1,因为set要求(排序+不重复)特殊结构 ,count只有两个数值0或者1
2.multiset(排序+允许重复)
1.set和multiset区别:
1.允许key值的冗余。
2.数据的插入比较随意但是考虑平衡性。
3.find的查找存在多个返回中序的第一个相同数据的迭代器。4.multiset中的数据是不可以随便进行修改的需要保证有序
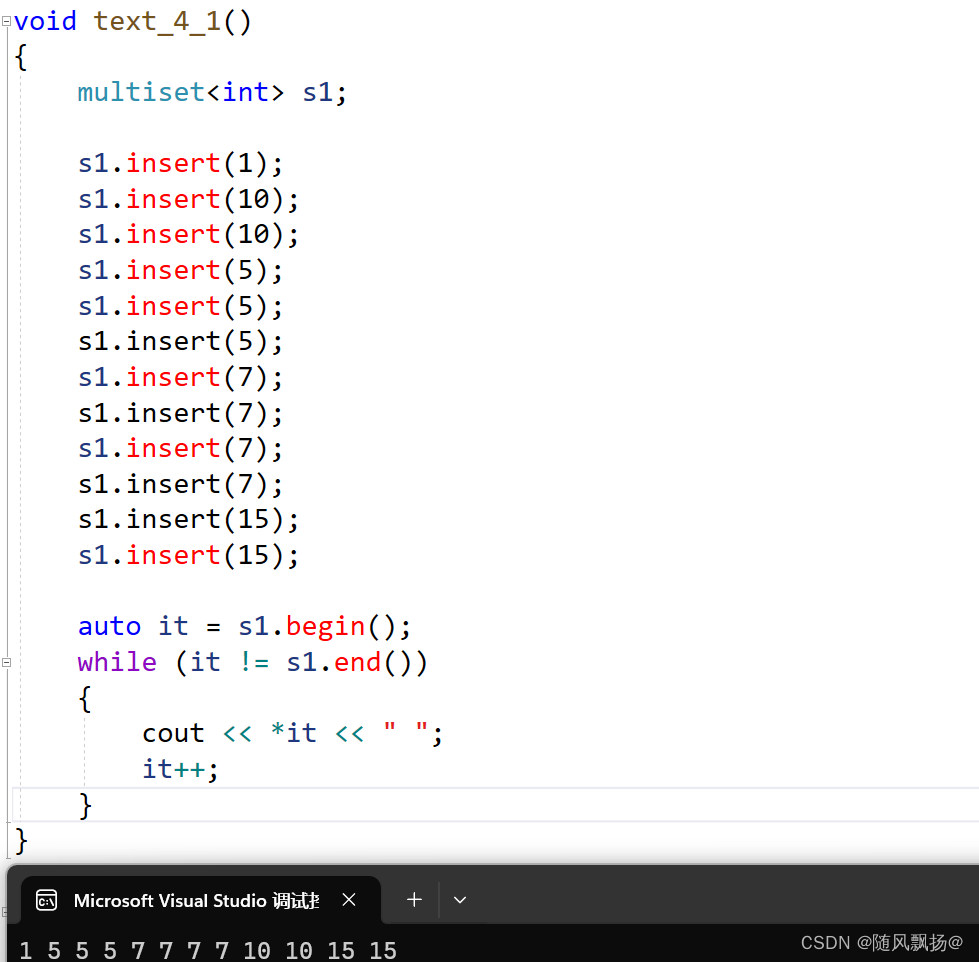
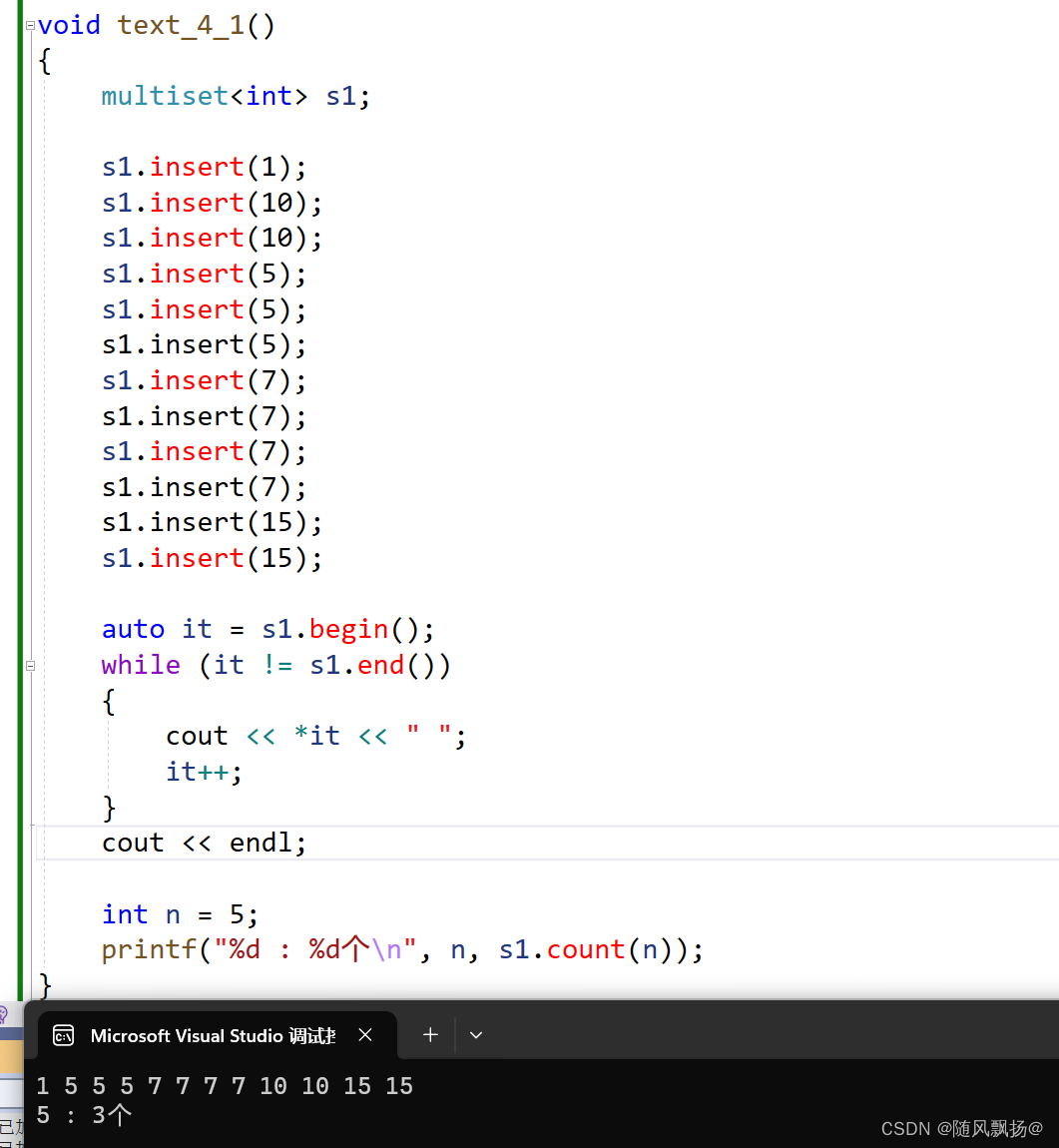
2.count的用武之地:
1.统计重复的数据的个数:
三.map
1.map(排序+不重复)

1.简单概念:
1.map是一个关联性容器底层存储一个pair类。
2.对于pair来说==< key value>== 两个对象的类型可能是不相同的。
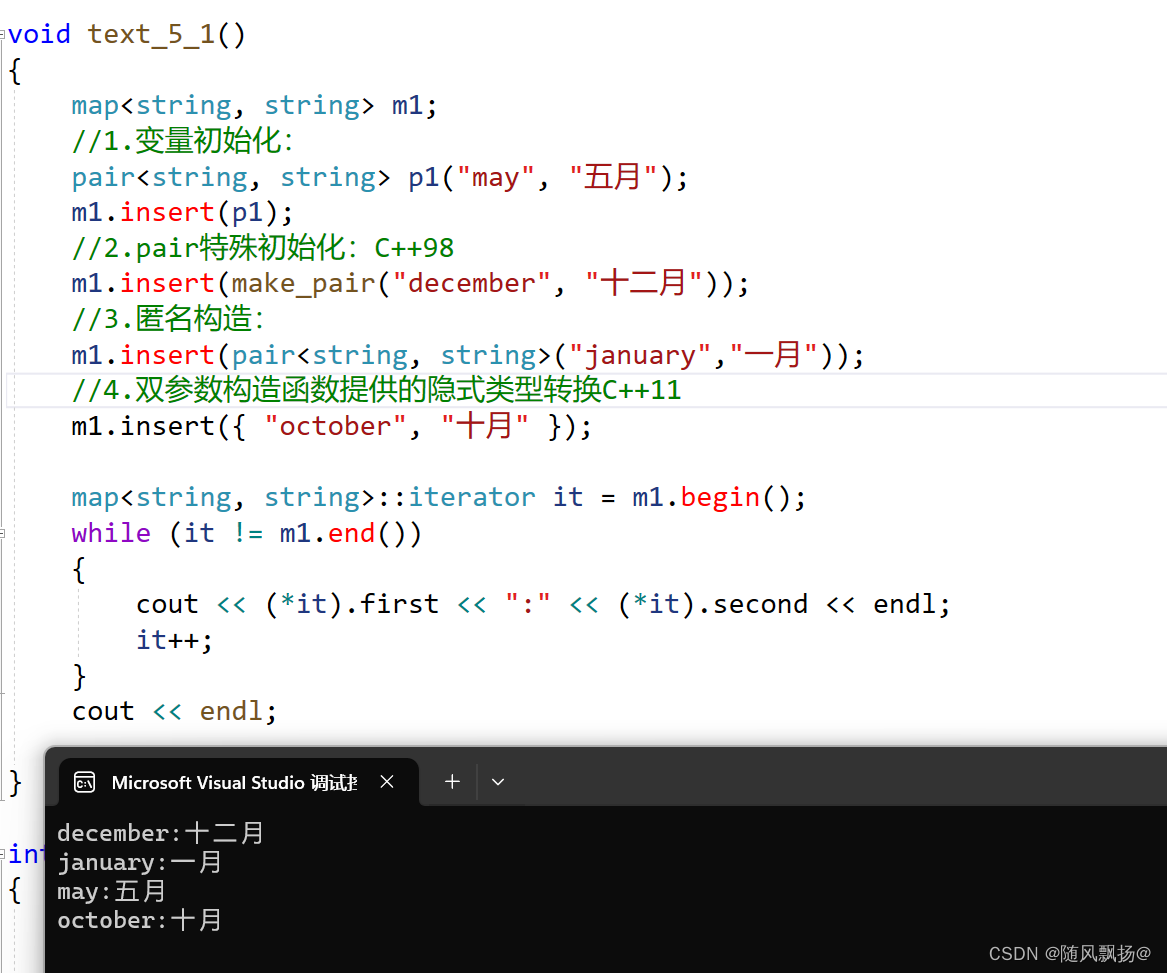
2.插入数据和多种初始化方式:
1.构建对象然后传参
2.使用make_pair
3.多参数构造函数提供的隐式类型转换。
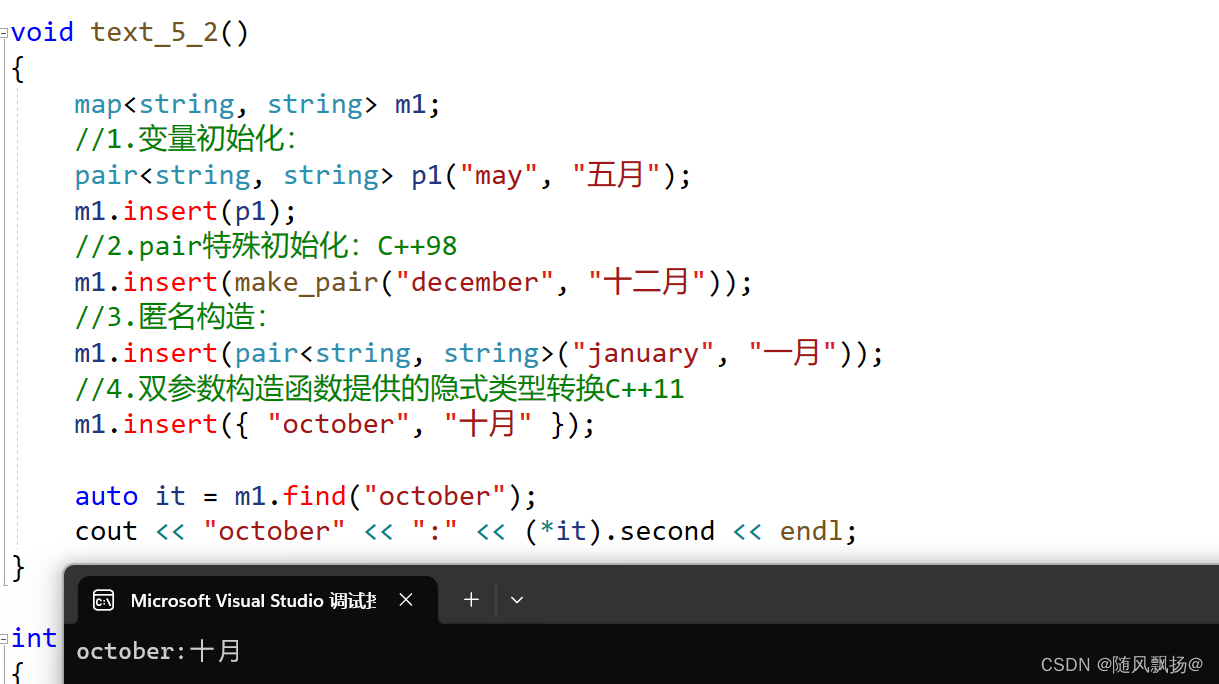
3.查找和删除:

1.An iterator to the element, if an element with specified key is found, or map::end otherwise.—传数据的值,返回相同数据的迭代器,如果数据的不存在返回最后一个数值迭代器的下一个。

1.这些内容和set中都是一样的,但是注意每次都是通过key值去进行考虑的,value值是不参与的。
4.count计数:
1.不允许重复key数据的出现所以count在map中同样也i是0或者1.
5.不允许重复key值插入:
进行测试:
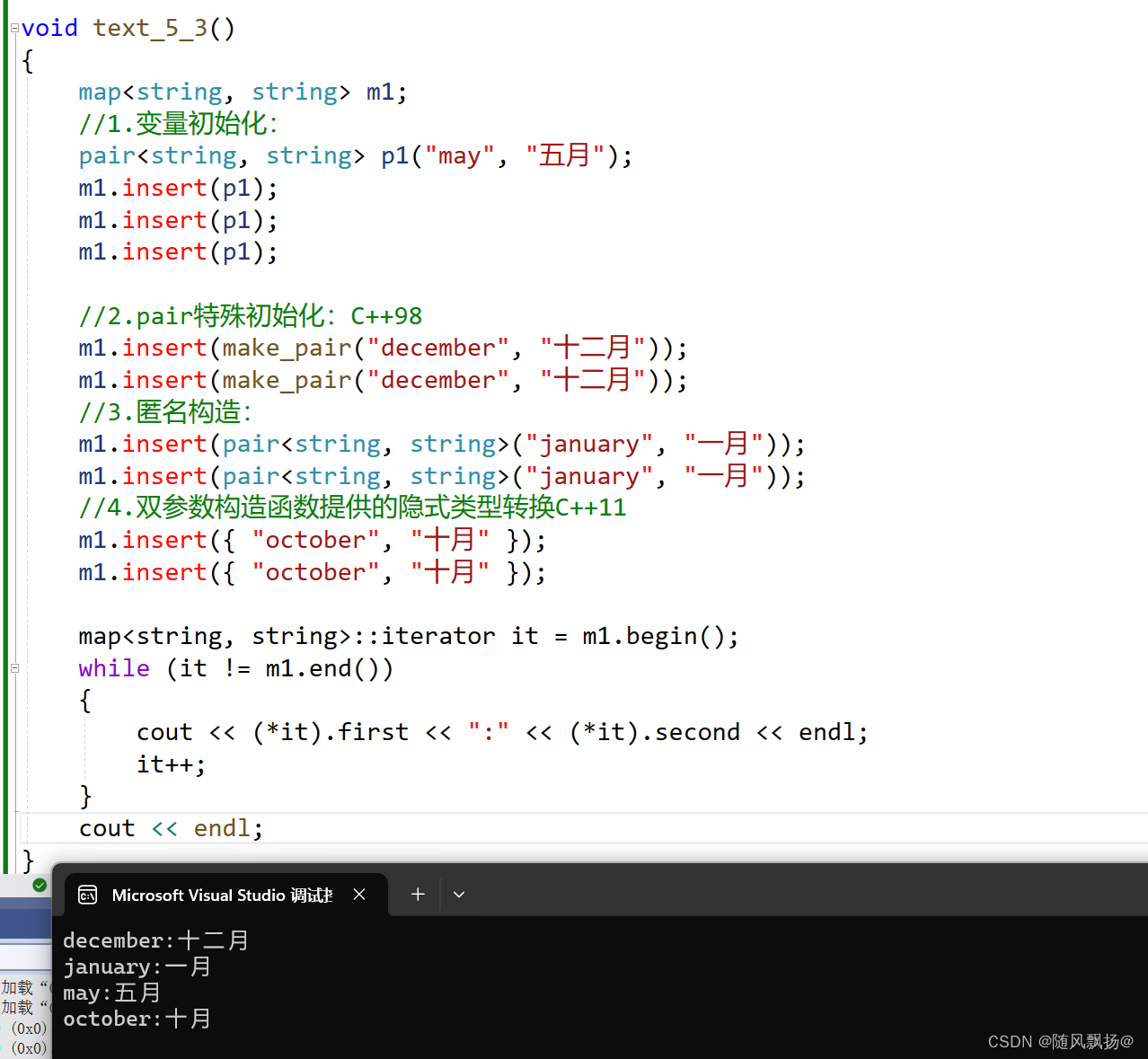
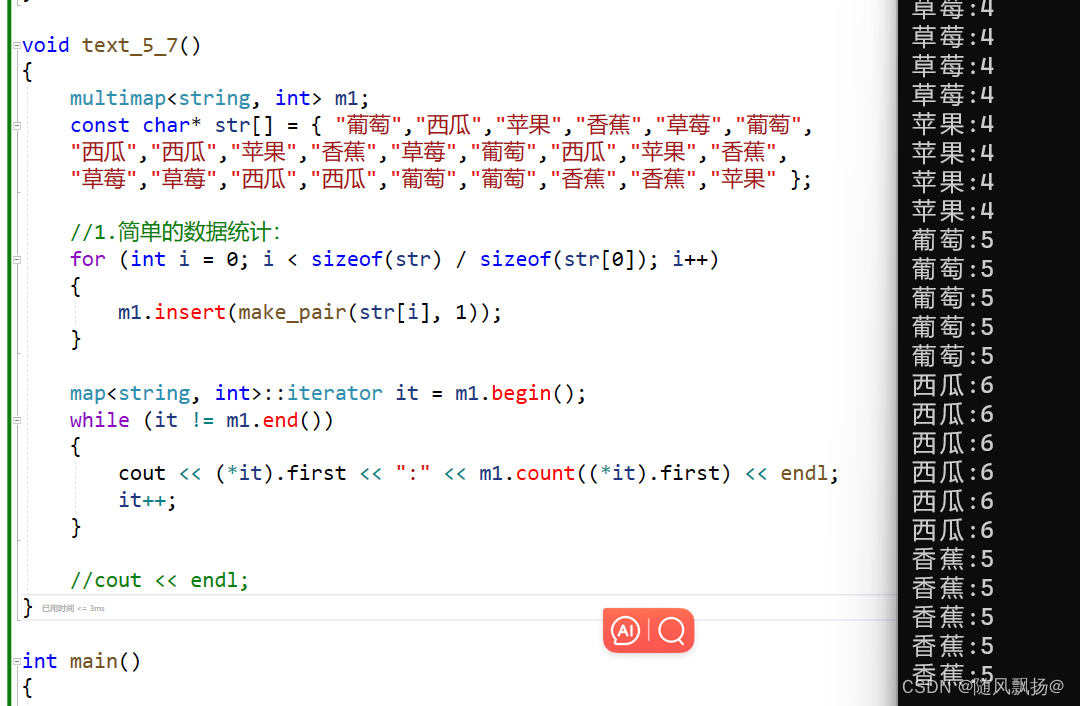
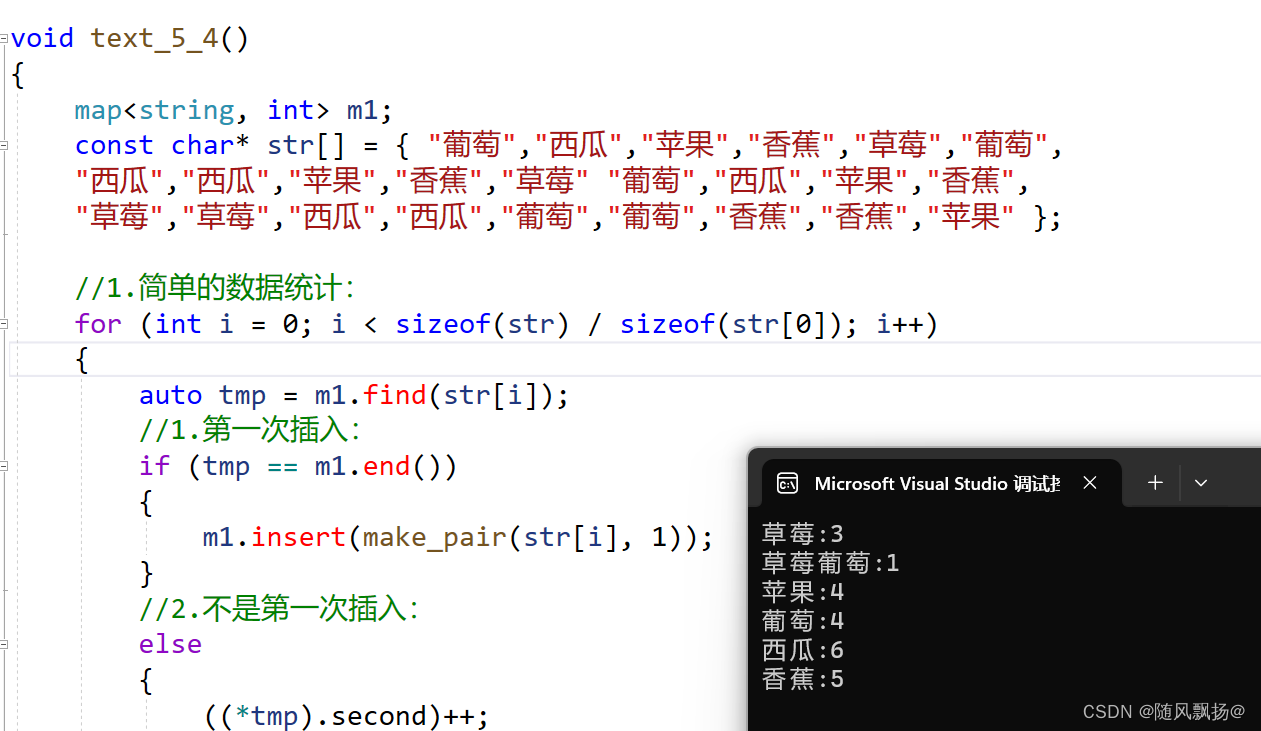
6.数据统计:
方法一:find+insert:
void text_5_4()
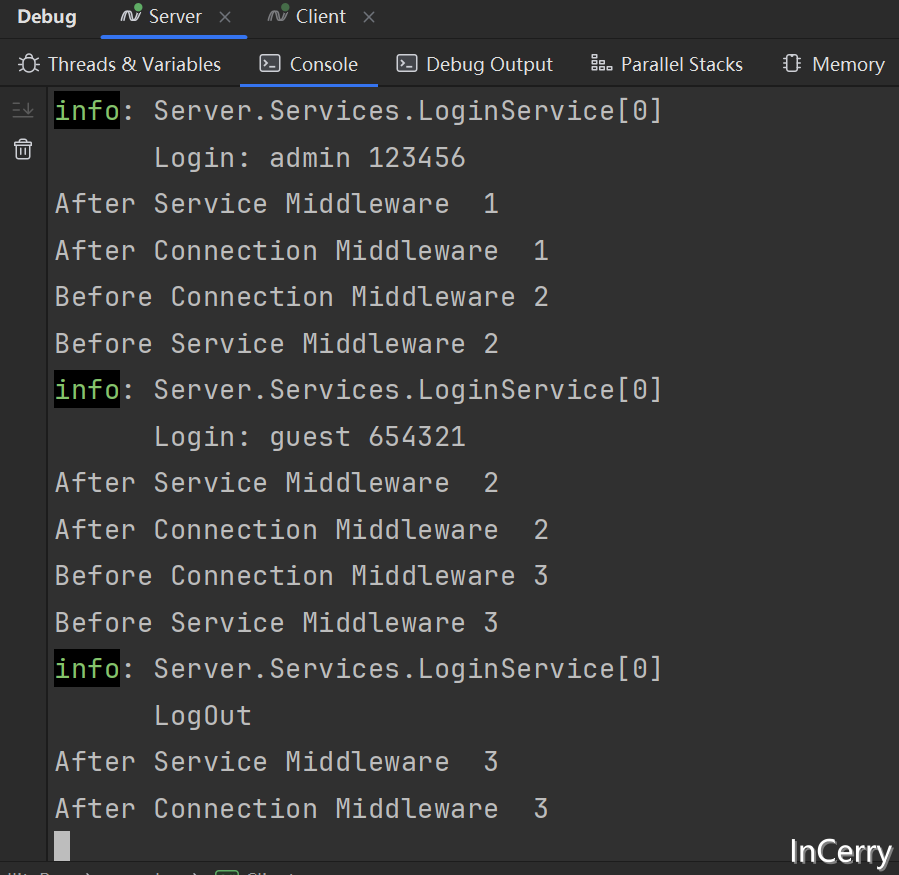
{map<string, int> m1;const char* str[] = { "葡萄","西瓜","苹果","香蕉","草莓","葡萄","西瓜","西瓜","苹果","香蕉","草莓" "葡萄","西瓜","苹果","香蕉","草莓","草莓","西瓜","西瓜","葡萄","葡萄","香蕉","香蕉","苹果" };//1.简单的数据统计:for (int i = 0; i < sizeof(str) / sizeof(str[0]); i++){auto tmp = m1.find(str[i]);//1.第一次插入:if (tmp == m1.end()){m1.insert(make_pair(str[i], 1));}//2.不是第一次插入:else{((*tmp).second)++;}}map<string, int>::iterator it = m1.begin();while (it != m1.end()){cout << (*it).first << ":" << (*it).second << endl;it++;}cout << endl;
}
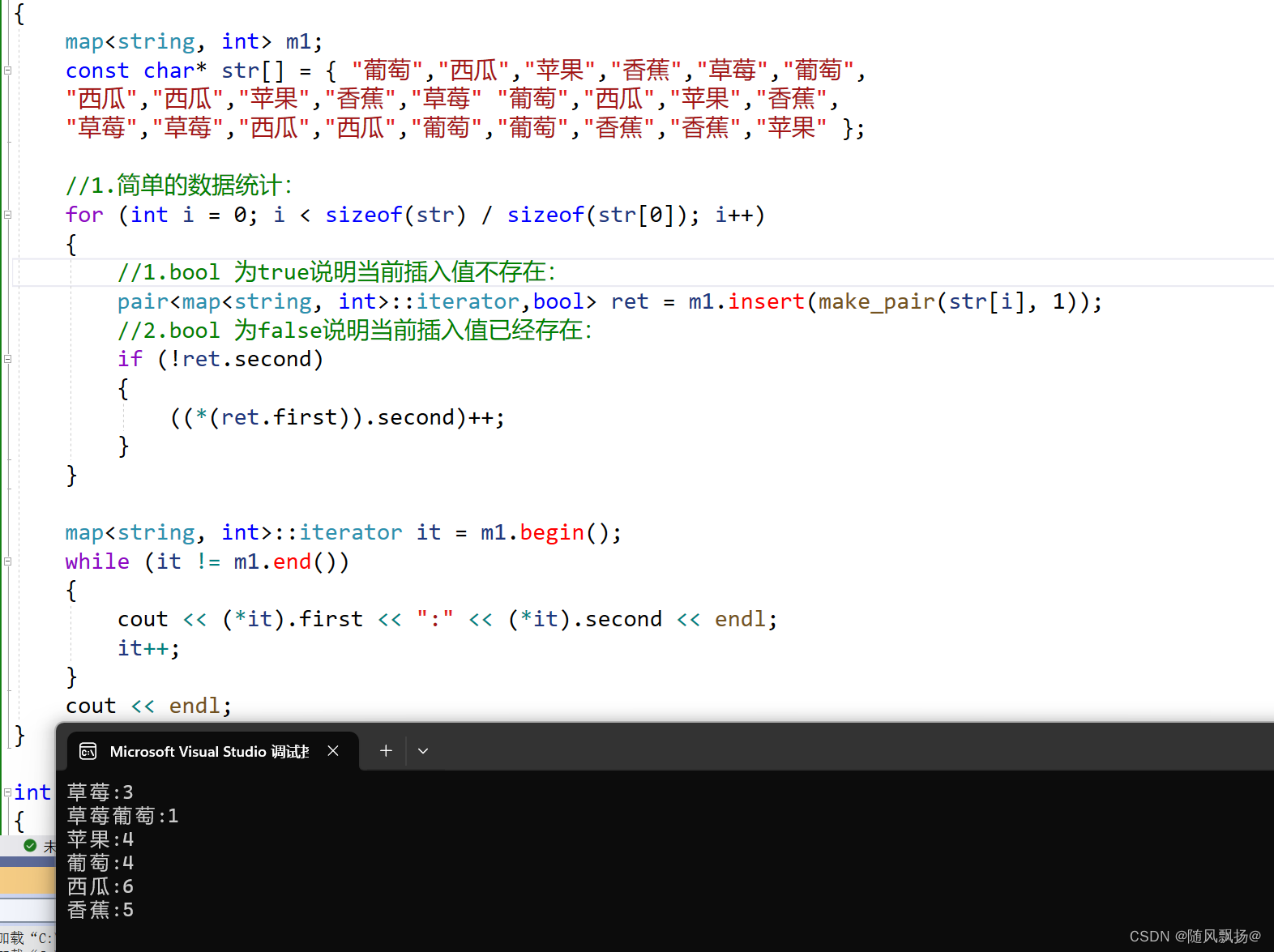
方法二:insert返回值pair类型:
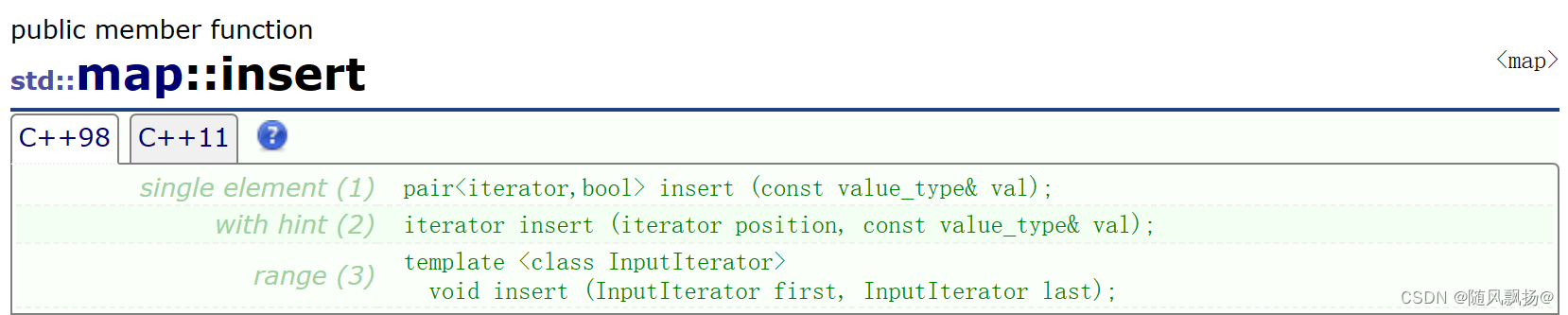
void text_5_5()
{map<string, int> m1;const char* str[] = { "葡萄","西瓜","苹果","香蕉","草莓","葡萄","西瓜","西瓜","苹果","香蕉","草莓" "葡萄","西瓜","苹果","香蕉","草莓","草莓","西瓜","西瓜","葡萄","葡萄","香蕉","香蕉","苹果" };//1.简单的数据统计:for (int i = 0; i < sizeof(str) / sizeof(str[0]); i++){//1.bool 为true说明当前插入值不存在:pair<map<string, int>::iterator,bool> ret = m1.insert(make_pair(str[i], 1));//2.bool 为false说明当前插入值已经存在:if (!ret.second){((*(ret.first)).second)++;}}map<string, int>::iterator it = m1.begin();while (it != m1.end()){cout << (*it).first << ":" << (*it).second << endl;it++;}cout << endl;
}
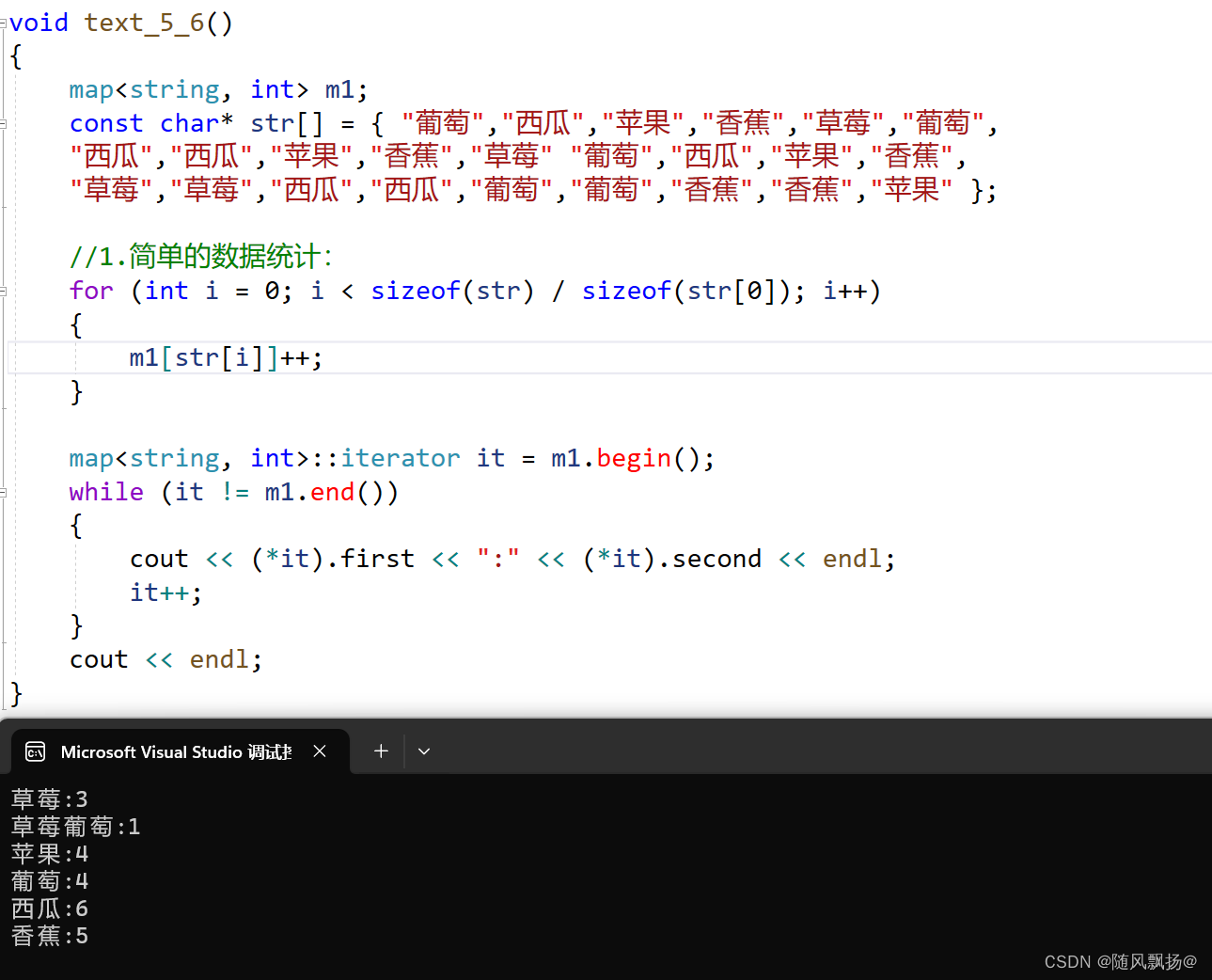
7.operator[]的重载:(数据统计优化)

void text_5_6()
{map<string, int> m1;const char* str[] = { "葡萄","西瓜","苹果","香蕉","草莓","葡萄","西瓜","西瓜","苹果","香蕉","草莓" "葡萄","西瓜","苹果","香蕉","草莓","草莓","西瓜","西瓜","葡萄","葡萄","香蕉","香蕉","苹果" };//1.简单的数据统计:for (int i = 0; i < sizeof(str) / sizeof(str[0]); i++){m1[str[i]]++;}map<string, int>::iterator it = m1.begin();while (it != m1.end()){cout << (*it).first << ":" << (*it).second << endl;it++;}cout << endl;
}
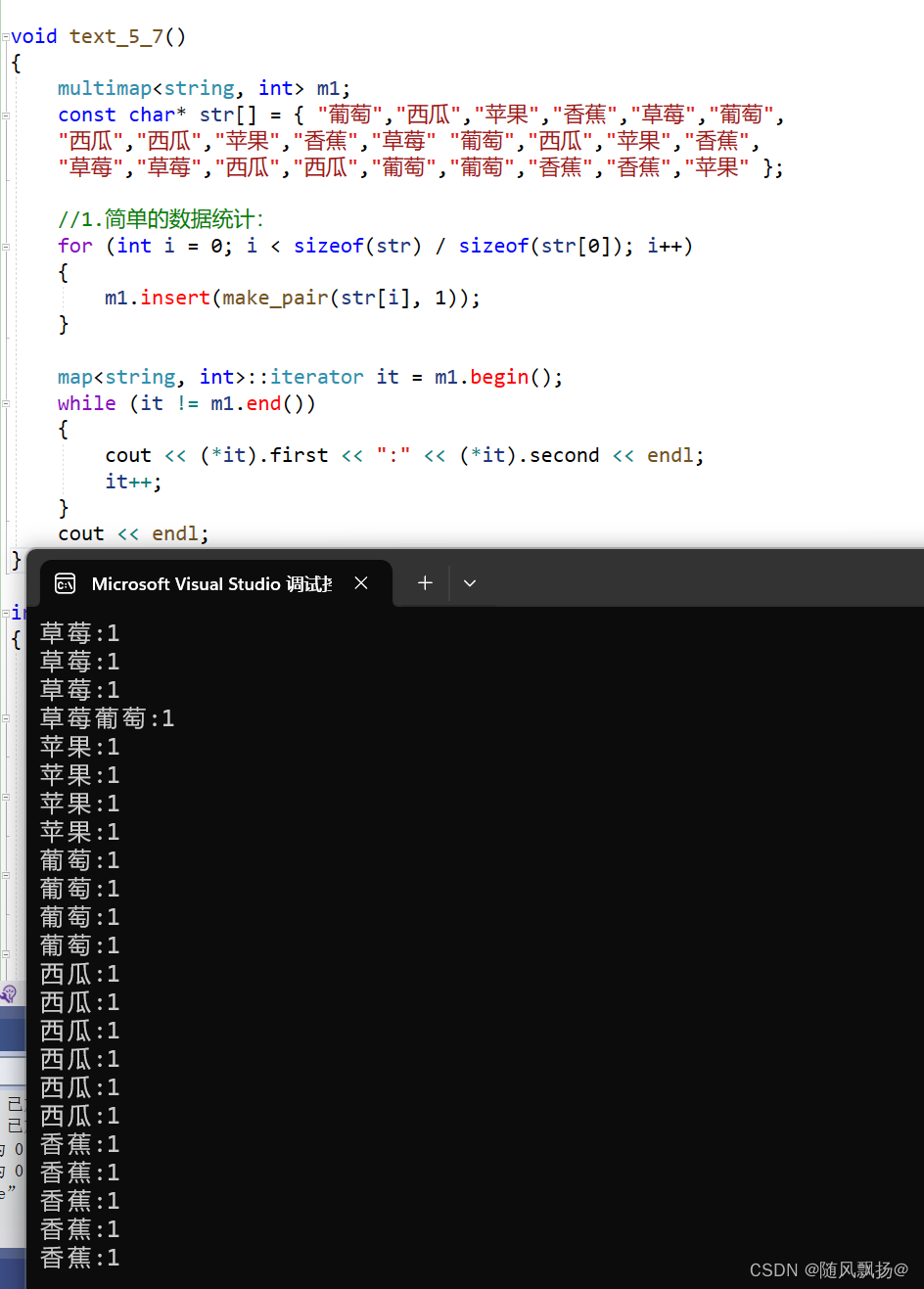
2.multimap(排序+允许重复)
1.map和mulitmap区别:
1.multimap不适合用于数据统计可以存放相同类型的key值。
2.count的用武之地: