目录
- Hadoop
- Hadoop的优势
- Hadoop的组成
- HDFS架构设计
- Yarn架构设计
- MapReduce架构设计
- 总结
在大数据时代,Hadoop作为一种开源的分布式计算框架,已经成为处理大规模数据的首选工具。它采用了分布式存储和计算的方式,能够高效地处理海量数据。Hadoop的核心由三大组件组成:HDFS、MapReduce和YARN。本文将为您逐一介绍这三个组件。
Hadoop
Hadoop是一个开源的分布式计算和存储框架,主要解决海量数据的存储和海量数据的分析计算。
Hadoop的优势
-
高可扩展性:Hadoop可以轻松地扩展到大规模集群,并处理大量的数据。它采用分布式计算的方式,将工作负载分布在集群中的多个节点上,使得系统能够处理海量的数据和高并发请求。
-
高容错性:Hadoop具有高度的容错能力,即使在设备或任务发生故障的情况下,也能保持数据的完整性和系统的可用性。它通过数据的冗余复制和自动故障转移等机制,确保数据的安全和系统的稳定性。
-
高效性:通过并行处理和分布式计算,Hadoop能够实现快速的数据处理。它可以将大规模的数据分解为小的任务并在多个节点上并行执行,从而提高处理效率和速度。
-
处理多种数据类型:Hadoop可以处理各种类型的数据,包括结构化数据、半结构化数据和非结构化数据。它能够灵活地存储和处理数据,支持分布式存储和处理大规模的文本、图像、音频、视频等数据类型。
-
异构性:Hadoop支持不同类型的硬件和操作系统,并且能够与其他开源工具和框架无缝集成。它提供了统一的接口和API,使得用户可以用各种编程语言编写应用程序,并在Hadoop上运行。
-
成本效益:相比于传统的数据存储和处理方式,Hadoop具有较低的成本。它使用商业化的廉价硬件,可以通过纵向和横向扩展实现高性能和高可用性,降低了硬件和软件成本。
Hadoop的组成
HDFS架构设计
Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop生态系统中的一个重要组成部分,是用于存储和处理大数据的分布式文件系统。
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
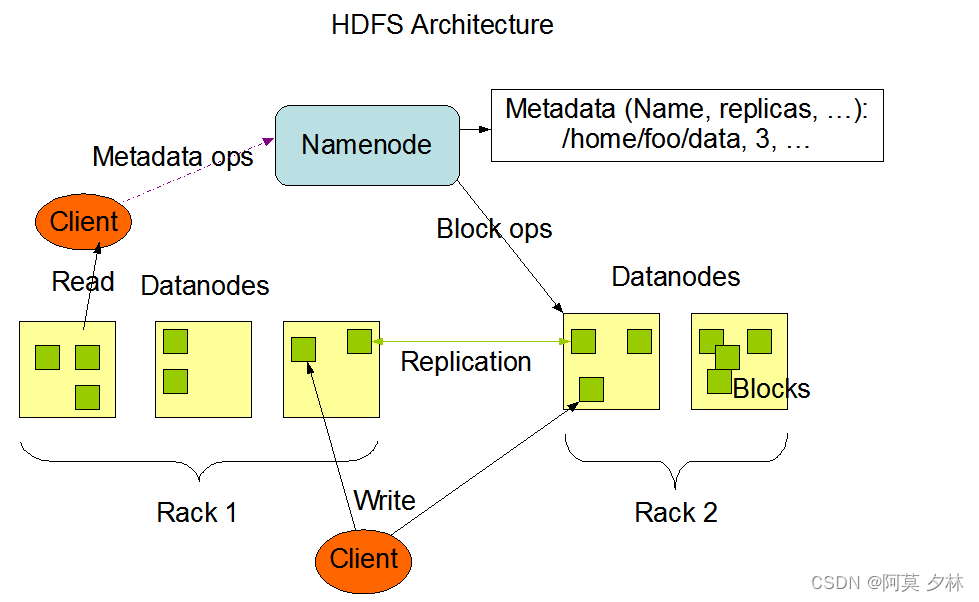
其架构详细概述如下:
-
NameNode(nn):
NameNode是HDFS的主节点,负责管理整个文件系统的命名空间和数据块的元数据信息。它维护文件系统的目录结构、文件的安全权限信息和数据块的位置信息等。NameNode还处理客户端的文件系统操作请求,如文件的读写和块的创建、复制和删除等。 -
DataNode(dn):
DataNode是HDFS的工作节点,负责实际存储文件数据和执行文件系统操作的任务。每个DataNode负责管理一定数量的数据块,并定期向NameNode报告数据块的存储信息。DataNode还处理来自客户端和其他DataNode的读取和写入请求,以及数据块的复制和恢复等。 -
存储指定副本:
HDFS中的文件被分成一系列的数据块,这些数据块会被复制到不同的Datanode上。根据副本配置参数,每个数据块在HDFS中会有多个副本,这样可以提高数据的可靠性和容错性。HDFS会尽量将这些副本存储在不同的机架、节点和硬盘上,以防止硬件故障或网络故障导致的数据丢失。 -
客户端(Client):
客户端是使用HDFS的应用程序。它们通过与Namenode和Datanode进行通信来读取和写入文件。客户端向Namenode请求文件的元数据信息,根据元数据信息确定所需数据块的位置,并从Datanode获取数据。客户端还负责处理文件系统的操作,如创建、删除、重命名和移动文件等。
Yarn架构设计
YARN(Yet Another Resource Negotiator)的基本思想是将资源管理和作业调度/监视的功能拆分为单独的守护进程。这个想法是有一个全局的ResourceManager (RM)和每个应用的ApplicationMaster (AM)。应用程序可以是单个作业,也可以是作业DAG。它的架构设计如下:
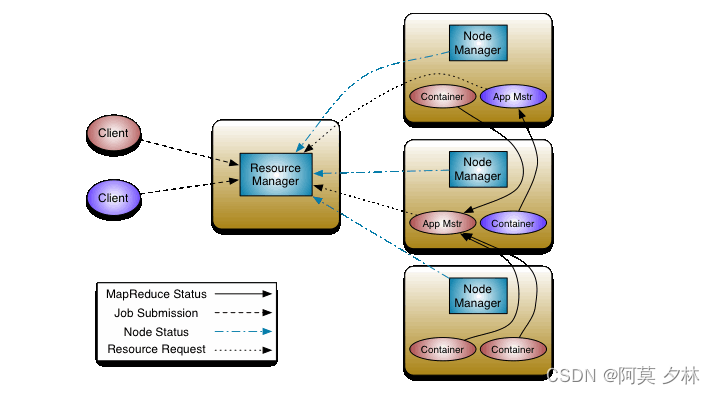
-
ResourceManager(资源管理器):
ResourceManager是YARN集群的主节点,负责整个集群的资源管理和任务调度。它接收来自客户端、应用程序和NodeManager的资源请求,分配和调度集群中的资源。ResourceManager还负责监控集群的健康状态,处理故障和任务的重新分配,以确保高可用性和稳定性。 -
NodeManager(节点管理器):
NodeManager是YARN集群中每个节点上的组件,负责管理和监控该节点上的计算资源。NodeManager通过向ResourceManager注册自己的资源和容器信息,将自身纳入到集群的资源管理中。它负责启动和监控容器,接收来自ResourceManager的资源分配指令,并向ResourceManager报告计算资源的使用情况。 -
ApplicationMaster(应用程序管理器):
每个在YARN上运行的应用程序都会有一个ApplicationMaster。ApplicationMaster负责协调和管理应用程序的资源需求,与ResourceManager通信并向其申请资源。它还监控应用程序的运行状态和容器的健康度,并处理容器的启动、停止和失败等情况。ApplicationMaster执行应用程序的逻辑,将整个应用程序划分为一系列的任务,并与NodeManager通信来启动和管理任务的执行。 -
Container(容器):
在YARN中,任务被封装到一个个容器中。容器是对计算资源的抽象,它由ResourceManager分配给ApplicationMaster,并由ApplicationMaster分配给具体的任务执行。每个容器拥有自己的计算和存储资源,并在NodeManager上创建和运行任务相关的进程。容器提供了高度的隔离性和资源限制,确保应用程序之间不会相互干扰。
ResourceManager有两个主要组件:Scheduler和ApplicationsManager。
Scheduler负责将资源分配给各种正在运行的应用程序,这些应用程序受到熟悉的容量、队列等约束。Scheduler是纯粹的Scheduler,因为它不监视或跟踪应用程序的状态。此外,它不能保证重新启动由于应用程序故障或硬件故障而失败的任务。调度程序根据应用程序的资源需求执行调度功能;它是基于资源容器的抽象概念来实现的,资源容器包含了诸如内存、cpu、磁盘、网络等元素。
ApplicationsManager 负责接受作业提交、协商第一个容器来执行应用程序特定的 ApplicationMaster 并提供在失败时重新启动 ApplicationMaster 容器的服务。每个应用程序的 ApplicationMaster 负责与 Scheduler 协商适当的资源容器,跟踪其状态并监控进度。
MapReduce架构设计
MapReduce是一种分布式计算编程模型,用于处理大规模数据集。它的架构设计包括以下几个组件:
-
JobTracker(作业调度器):
JobTracker是MapReduce作业的主节点,负责整个作业的调度和执行。它接收来自客户端的作业请求,将作业划分为多个任务,并分配给各个TaskTracker进行执行。JobTracker还负责监控任务的进度和状态,处理任务的失败和重新分配,以确保作业的顺利运行。 -
TaskTracker(任务执行器):
TaskTracker是在每个集群节点上运行的组件,负责执行作业中的任务。它接收来自JobTracker的任务分配指令,并在该节点上启动和管理任务的执行。TaskTracker将任务划分为Map任务和Reduce任务,并负责处理任务的输入输出数据,以及任务的进度和状态更新。 -
MapTask(映射任务):
MapTask是MapReduce作业的计算阶段。每个MapTask从输入数据中抽取一部分数据,经过映射函数的处理后生成键值对(key-value pair)。MapTask独立进行执行,处理输入数据的分片,将处理后的中间结果写入本地磁盘。 -
ReduceTask(归约任务):
ReduceTask是MapReduce作业的归约阶段。每个ReduceTask接收来自Mapper的输出结果,并按照键进行归约操作,将具有相同键的数据进行合并和计算生成最终结果。ReduceTask也独立执行,将归约后的结果写入最终输出文件。 -
分布式文件系统:
MapReduce框架通常与分布式文件系统(如HDFS)结合使用,用于存储输入数据和输出结果。分布式文件系统提供了高可靠性和容错性,并支持数据的高并发访问。
通过这种架构设计,MapReduce就可以实现任务的分布式执行和并行计算,并能够高效处理大规模数据集。
Map阶段将计算任务分布到不同的节点上进行并行处理,Reduce阶段将中间结果进行合并和计算生成最终结果。这种框架设计适用于各种数据处理场景,如数据排序、数据过滤、数据聚合等。同时,MapReduce框架也提供了一些其他功能,如容错性、动态负载均衡和数据本地化等,以提高作业的执行效率和数据处理速度。
总结
Hadoop的三大核心组件HDFS、MapReduce和YARN共同构成了一个完整的分布式计算框架。HDFS提供了高可靠性的分布式文件存储,MapReduce实现了高效的并行计算,而YARN则管理着集群的资源和任务。通过这三个组件的配合,Hadoop能够处理大规模数据集的存储、计算和调度,为大数据处理提供了强大的支持。
![基于51单片机的智能监护与健康检测[proteus仿真]](https://img-blog.csdnimg.cn/direct/60d7f9d236c7413ab0e32ce0e2eddae8.png)