文章目录
- 平台无关性如何实现?
- JVM如何加载 .class文件?
- 什么是反射?
- 谈谈ClassLoader
- 谈谈类的双亲委派机制
- 类的加载方式
- Java的内存模型?
- JVM内存模型-jdk8
- 程序计数器:
- Java虚拟机栈
- 局部变量表和操作数栈:
- Java内存模型中堆和栈的区别-内存分配策略
- 不同JDK版本之间的intern()方法的区别?
- 谈谈你了解的垃圾回收算法?
- 标记-清除算法(Mark and Sweep)
- 复制算法
- 标记-整理算法(Compacting)
- 分代收集算法(Generational Collector)
- 常见的垃圾收集器
- JVM的运行模式
- 垃圾收集器之间的联系
- 年轻代中常见的垃圾收集器:
- 老年代常见的垃圾收集器
- JAVA中的强引用,软引用,弱引用,虚引用有什么用?
- 强引用(Strong References):
- 软引用(Soft Reference):
- 弱引用(Weak Reference)
- 虚引用(PhantomReference)
- Redis常用的数据类型?
- 从海量key里查询出某一固定前缀的key?
- 如何通过Redis实现分布式锁?
- 如何使用Redis做异步队列?
- Redis如何做持久化?
- RDB(快照)持久化
- AOF(Append-Only-File)日志追加
- Redis同步机制
- 主从同步原理
- 全同步过程:
- 增量同步过程
- Liunx中常见的面试问题?
- 持续更新中...
平台无关性如何实现?
通过javac执行java源文件,会生成一个 .class 的二进制字节码文件
JDK自带的反编译器: javap -help -查看帮助文档
javap -c java源文件名 ------ 就可以反汇编了
.java文件 ------------ > .class 文件 ------------ > JVM解析
Java源码首先被编译成字节码,再由不同平台的JVM解析,Java语言在不同平台上运行时不需要重新进行编译,Java虚拟机在执行字节码的时候,会把字节码装换成具体平台上的机器指令。
为什么JVM不直接将源码解析成机器码去执行?
准备工作:每次执行都需要各种检查
兼容性:也可以将别的语言解释成字节码
JVM如何加载 .class文件?
Java虚拟机:Java虚拟机是内存中的虚拟机,JVM的存储就是在内存中

- ClassLoder: 依据特定格式,加载class文件到内存
- Excution Engine: 对命令进行解析
- Native Interface: 融合不同开发语言的原生库为Java所用
- Runtime Data Area: JVM内存空间模型
什么是反射?
JAVA反射机制是指在运行状态中,对于任意一个类,都能够知道这个类 的所有属性和方法,对于任意一个对象,都能够调用他的任意方法和属性,这种动态获取信息以及动态调用对象方法的功能称为Java语言的反射机制。
写一个放射的例子?
通过Class.forName(“类的全限定名”),拿到类的class对象,假如为clazz
通过clazz.newInstance()方法创建 一个该类的对象
通过clazz.getDeclareMethod()获取类的私有方法(既可以获取该类中的所有方法),但不能获取到父类的方法,或者是实现的接口中的方法,同时需要关闭安全检查getHello.setAccessible(true);
通过getMethod可以获取公有的方法,同时可以获取父类和实现接口中的方法
谈谈ClassLoader
ClassLoader在Java中有卓非常重要的作用,它主要工作在Class装载的加载阶段,其主要作用是从系统外部获得Class二进制数据流,它是Java的核心组件,所有的Class都是由ClassLoader进行加载的,ClassLoafer负责通过将Class文件里的二进制数据流装载进系统,然后交给Java虚拟机进行连接,初始化等操作。
ClassLoader源码分析:核心方法loadClass , parent也是一个ClassLoader
ClassLoader的种类:
- BootStrapClassLoader: C++编写,加载核心库java.*,例如java.lang包 ----- 用户看不到
- ExtClassLoader: Java编写,加载扩展库 javax.* ---- javaWeb的核心类库 ------ 用户可以看到
- AppClassLoder; Java编写,加载程序目录 ------- 用户可以看到
- 自定义ClassLoader,需要继承系统的ClassLoader: Java编写,定制化加载
- 重写关键函数:findClass ----- 用户寻找类文件
- return defineClass,参数为一个字节数组 ------- 用户加载类文件
谈谈类的双亲委派机制

避免多份同样字节码的加载,因为内存是宝贵的,没必要保存同样两份类的字节码
类的加载方式
- 隐式加载:new ,通过该方式支持带惨的构造器
- 显示加载:loadClass,forName — 不支持传入参数
类的装载过程:
- 加载:通过ClassLoader加载class字节码文件,生成Class对象
- 链接
- 校验:检查加载的class的正确性和安全性
- 准备:为类变量分配存储空间并设置类变量的初始值
- 解析:JVM将常量池内的符号引用转为直接引用
- 初始化:执行变量赋值和静态代码块
loadClass和forName的区别:
- loadClass只是加载 了这个类,并没有进行链接和初始化的
- forName得到Class是已经完成了初始化的
Java的内存模型?
内存简介:

可寻址空间根据操作系统不同,范围也不同
地址空间的划分:
- 内核空间:主要的操作系统程序和C运行时空间,连接计算机硬件,以及提供联网和虚拟内存
- 用户空间:除去内核空间就是用户空间了,这里才是Java进程实际运行的内存空间
JVM内存模型-jdk8

程序计数器:
当前线程所执行的字节码行号指示器(逻辑)
改变计数器的值来选取下一条需要执行的字节码指令
和线程是一对一的关系,即线程私有
对Java方法计数,如果是Native方法,则计数器的值为Undefined
不会发生内存泄漏
Java虚拟机栈
Java方法执行的内存模型
包含多个栈帧
局部变量表和操作数栈:
局部变量表:包含操作方法执行过程中的所有变量
操作数栈:入栈,出栈,复制,交换,产生消费变量
递归为什么会出现StackOverFlowError?
递归过深,栈帧数超出虚拟机深度
虚拟机栈过多会引发OutOfMemoryError
元空间(MetaSpace)与永久代(PerGen)的区别?
元空间使用的是本地内存,而永久代使用的是jvm内存
优势:字符串常量池存在永久代中,容易出现性能问题和内存溢出
类和方法的信息大小难以确定,给永久代的大小指定带来困难
永久代会为GC带来不必要的复杂性
Java堆(Heap)
对象实例的分配区域
GC管理的主要区域
JVM三大性能调优参数 -Xms -Xmx -Xss的含义
- -Xss:规定了每个线程虚拟机栈(堆栈)的大小,一般设为 256k — 影响此进程中并发线程数的大小
- -Xms:堆得初始值, 若 超过该值,将会自动扩容,扩大到Xmx
- -Xmx:堆能达到的最大值,一般和Xms的值设为一样,由于在扩容时,会发生内存抖动,影城程序运行时的稳定性。
Java内存模型中堆和栈的区别-内存分配策略
- 静态存储:编译时确定每个数据目标在运行时的存储空间需求
- 栈式存储:数据区需求在编译时未知,运行时模块入口前确定
- 堆式存储:编译时和运行时都无法确定,动态分配
内存模型中堆和栈区别:
联系:引用对象,数组时,栈中定义变量保存在堆中的目标地址
管理方式:栈自动释放,堆需要GC
空间大小:栈比堆小
碎片相关:栈产生的碎片远小于堆
分配方式:栈支持静态分配和动态分配,而堆仅支持动态分配
效率:栈的效率比堆高
不同JDK版本之间的intern()方法的区别?
JDK1.6:当调用intern()方法时,如果字符串常量池先前已经创建好该字符串对象,则返回池中该字符串的引用。否则,将此字符串对象添加到字符串常量池中,并且返回该字符串对象的引用。
添加到JDK1.6之后:当调用intern()方法时,如果字符串常量池先前已经创建好该字符串对象,则返回池中该字符串的引用。否则,如果该字符串对象已经在Java堆中,则将堆中此对象的引用添加到字符串常量池中,并且返回该引用,如果堆中不存在,则在池中创建该字符串并返回其引用。
谈谈你了解的垃圾回收算法?
标记-清除算法(Mark and Sweep)
标记:从根集合进行扫描,对存活的对象进行标记 ---- 利用可达性算法找到垃圾对象
清除:对内存从头到尾进行线性遍历,回收不可达对象内存
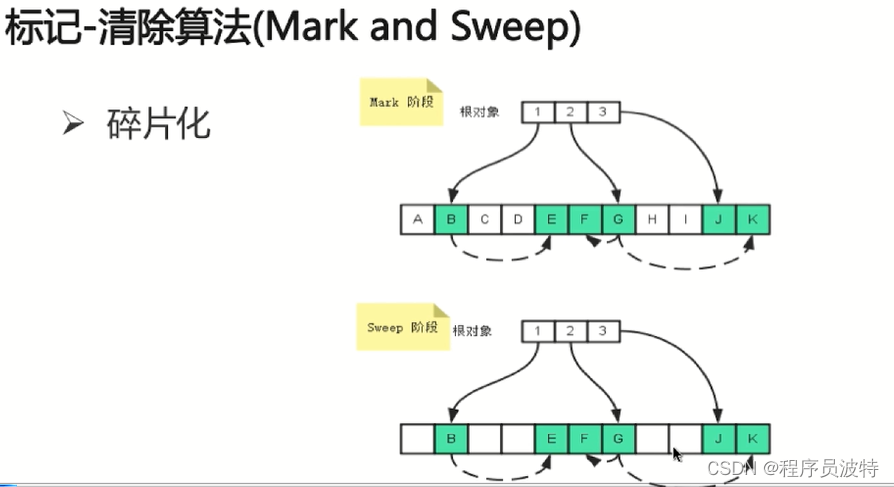
缺点:由于该算法不需要堆栈的移动,会产生大量不连续的内存碎片
复制算法
分为对象面和空闲面
对象在对象面上创建
存活的对象被从对象复制到空闲面
将对象面的所有对象内存清除
优点:
解决了碎片化问题
顺序分配内存
简单高效
适用于对象存活率低的场景

标记-整理算法(Compacting)
- 标记:从根集合进行扫描,对存活的对象进行标记
- 清除:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收
优点:
避免内存的不连续性
不用设置两块内存互换
适用于对象存活率高的场景
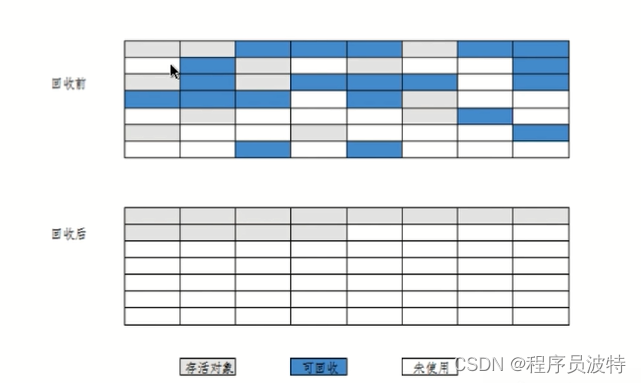
分代收集算法(Generational Collector)
垃圾回收算法的组合拳
按照对象生命周期的不同划分区域以采用不同的垃圾回收算法
目的:提高JVM的回收效率
在jdk7之前,JAVA堆内存分为年轻代,老年代,永久代
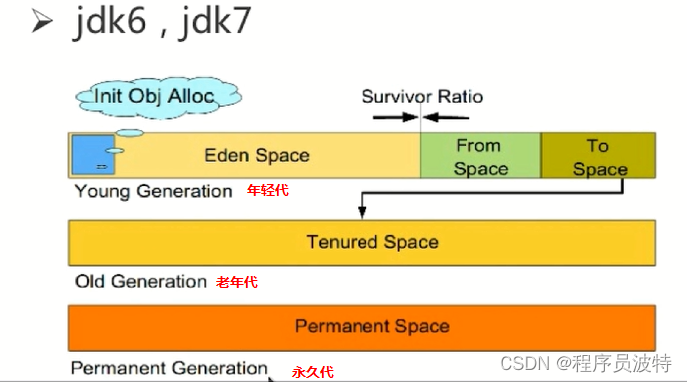
在JDK8之后,永久 代就被去掉了

年轻代的存活率低,就使用的是复制算法,老年代的存活率高,就使用的是标记整理算法
GC的分类
Minor GC: Minor GC是发生在年轻代的垃圾回收动作,所采用的是复制算法,年轻代几乎是所有对象出生的地方,以及Java对象内存的申请和存放,都是在这里,新生代是GC收集垃圾对象的频繁区域。
Full GC:与老年代相关,由于对老年代的回收,一般会伴随着年轻代对象垃圾的收集,因此,第二种GC被称为Full GC.
年轻代:尽可能快速地收集掉那些生命周期短的对象
Eden区:两个Survivor区:
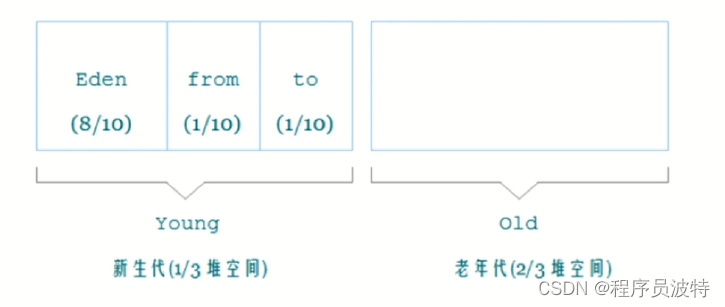
对象如晋升到老年代?
- 经历一定 Minor次数依然存活的对象
- Survivor区中存放不下的对象
- 新生成的大对象(-XX:+PretenuerSizeThreshold,超过该Size大小,就立即放入老年代中)
常用的调优参数:
- -XX:SurvivorRation: Eden和Survivor的比值,默认为8:1
- -XX:NewRation: 老年代和年轻代内存大小的比例
- -XX:MaxTenuringThreshold: 对象从年轻代晋升到老年代经过GC次数的最大阈值
老年代:存放生命周期较长的对象
标记清理算法或者标记整理算法
Full GC和 Major GC
- Full GC: 对整个堆内存进行回收
- 说Major GC一定要问清楚,是指Full GC,还是针对老年代的GC
Full GC比Minor GC要慢的多,一般会慢十倍以上,但执行频率低
触发Full GC的条件:
- 老年代空间不足----- 解决办法;不要创建太大的对象
- 永久代空间不足 ------- 针对JDK之前
- CMS GC时出现promotion failed,concurrent mode fallure
- Minor GC晋升到老年代的平均大小大于老年代的剩余空间
- 调用System.gc() -------- 该方法只是提醒虚拟机进行回收,程序员对是否回收没有绝对的控制权。
- 使用RMC来进行RPC或管理JDK应用,每小时执行一次Full gc
Stop-the-World
JVM由于要执行GC而停止了应用程序的执行
任何一种GC算法中都会发生
多数GC优化就是通过减少Stop-the-World发生的时间来提高程序的性能,从而使系统具有高吞吐,低停顿的特点。
Safepoint
分析过程中对象引用关系不会发生变化的点
产生Safepoint的地方,方法调用,循环跳转,异常跳转等
安全点数量适中
常见的垃圾收集器
JVM的运行模式
Server:启动速度较慢------启动的是重量级JVM,运行速度更快
Client:启动速度较快------启动的是轻量级JVM,运行速度慢一些
垃圾收集器之间的联系

年轻代中常见的垃圾收集器:
Serial收集器(-XX:+UseSerialGC,复制算法)
- 单线程收集,进行垃圾收集时,必须暂停所有工作线程
- 简单高效,Clien模式下默认的年轻代收集器

ParNew收集器(-XX:+UseParNewGC,复制算法) - 多线程收集,其余的行为,特点和Serial收集器一样
- 单执行效率不如Serial,在多核下执行才有优势

Parallel Scavenge收集器(-XX:+UseParallelGC,复制算法)
- 吞吐量:运行用户代码时间/(运行用户代码时间+垃圾收集时间)
- 比起关注用户线程停顿时间,更关注系统的吞吐量
- 在多核下执行才有优势,Server模式下默认的年轻代收集器
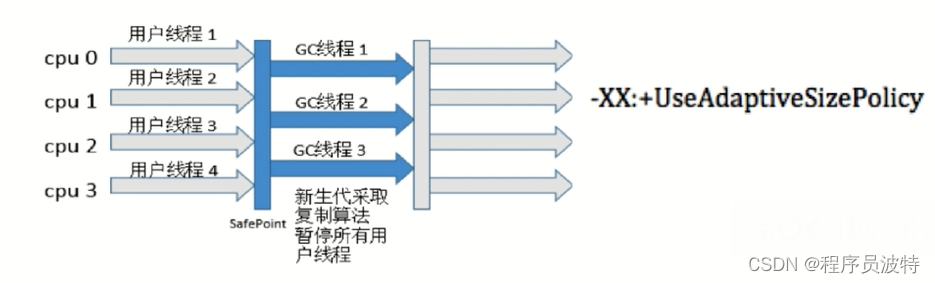
老年代常见的垃圾收集器
Serial Old收集器(-XX:UseSerialGC,标记整理算法)
- 单线程收集,进行垃圾回收时,必须暂停所有线程工作
- 简单高效,Client模式下默认的老年代收集器
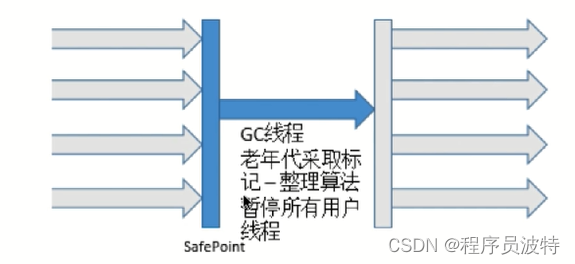
Parallel Old收集器(-XX:UseParallelGC,标记整理算法)
多线程,吞吐量优先

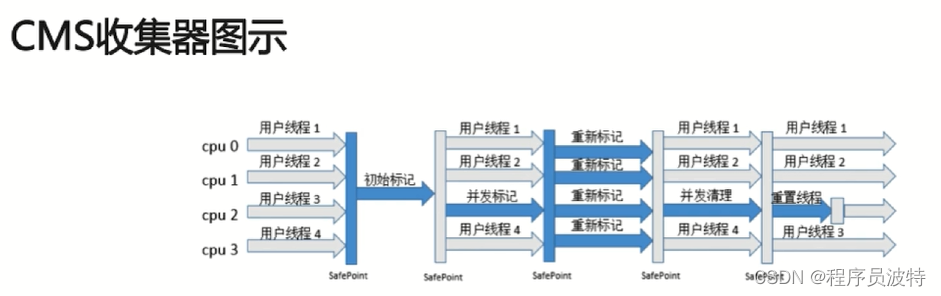
CMS收集器(-XX:+UseConcMarkSweepGC,你标记清除算法)
- 初始标记:stop-the-world
- 并发标记:并发追溯标记,程序不会停顿
- 并发预清理:查找执行并发标记阶段从年轻代晋升到老年代的对象
- 重新标记:暂停虚拟机,扫描CMS堆中剩余的对象
- 并发清理:清理垃圾对象,程序不会停顿
- 并发重置:重置CMS收集器的数据结构
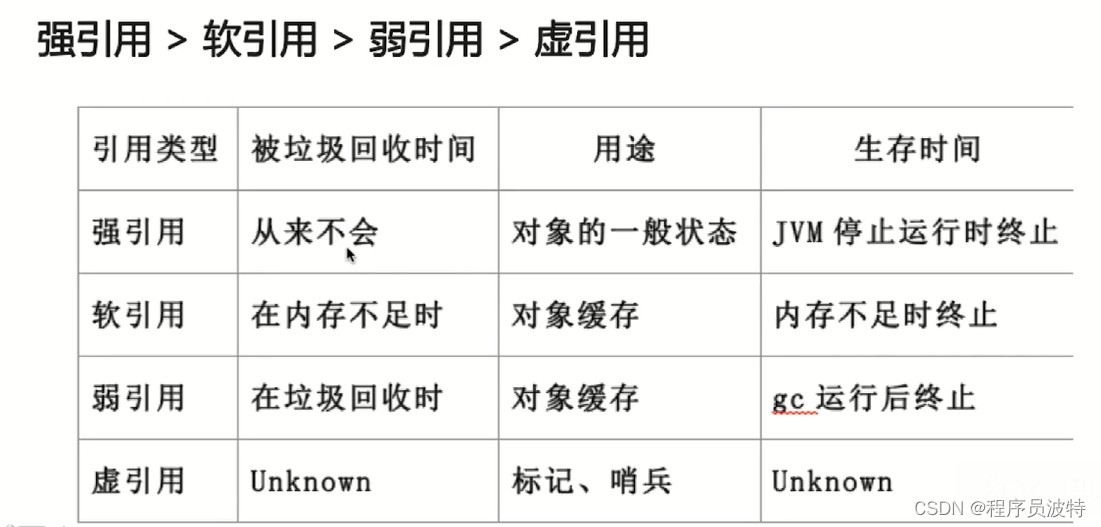
JAVA中的强引用,软引用,弱引用,虚引用有什么用?
强引用(Strong References):
最普遍的引用:Object obj = new Object();
在内存不足时,JVM宁可抛出OutOfMemoryError终止程序也不会回收
具有强引用的对象
通过将对象设置为null,来弱化引用,使其被回收
软引用(Soft Reference):
对象在有用但非必需的状态
只有当内存不足时,DC会回收该引用的对象的内存
可以用来实现高速缓存
弱引用(Weak Reference)
非必需的对象,比软引用更弱一些
GC时会被回收,不管内存是否不足
被回收的概率也不大,因为GC线程优先级较低
适用于偶尔被使用且不影响垃圾收集的对象
虚引用(PhantomReference)
不会决定对象的生命周期
任何时候都可能被垃圾回收器回收
跟踪对象被垃圾回收器回收的活动,起哨兵的作用
必须何引用队列ReferenceQueue联合使用
引用队列:ReferenceQueue
Redis常用的数据类型?
String
最基本的数据类型,二进制安全
Hash
String元素组成的字典,适合于存储对象
List
列表,按照String元素插入的顺序的排序
Set
String元素组成无序集合,通过哈希表实现,不允许重复
Zset
通过分数为集合中的成员进行从小到大的排序
从海量key里查询出某一固定前缀的key?
使用Keys线上业务的影响
keys pattern :查找所有符合给定模式pattern的key
keys指令一次性返回所有匹配的key
键的数量过大会使服务卡顿,对内存的消耗和redis服务器都是隐患
SCAN cursor [MATCH pattern] [Count count]
基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程
以0作为游标开始一次新的迭代,直到命令返回游标0完成一次遍历
不保证每次执行都返回某个给定数量的元素,支持模糊查询
一次返回的数量不可控,只能是大概count参数
第一条数据就是游标,第二条数据就是查找到的结果集,下一次迭代通过该游标进行继续迭代,通过该方式可能获取倒重复的数据,需要在Web程序去重
如何通过Redis实现分布式锁?
分布式锁需要解决的问题:
- 互斥性:任意时刻,只能有一个客户端获取到锁
- 安全性:锁只能被持有该锁的客户端删除,不能被其他客户端删除
- 死锁:获取锁的客户端由于某些原因而宕机,导致不饿能释放锁,其他客户端再也不能获取到该锁
- 容错:当部分节点(Redis节点)宕机的时候,客户端可以获取锁和释放锁
SETNX key value:如果键不存在,则创建并赋值,时间复杂度为 O(1),返回值:设置成功,返回1;设置失败,返回0
如何解决SETNX长期有效的问题?
方式一:
EXPIRE key seconds 给key设置过期时间,当key过期时,就会被自动删除
缺点:原子性得不到满足,虽然SETNX和EXPIRE指令都是原子性的,但组合起来就不是了
方式二:
SET key value [EX seconds] [PX milliseconds] [NX|XX]
- EX second :设置键的过期时间为second秒
- PX milliseconds :设置键的过期时间为millisecond毫秒
- NX:只有在键不存在时,才对键进行设置操作
- XX:只在键已经存在时,才对键进行设置
SET操作成功完成时,返回OK,否则返回 nil
大量key同时过期的注意事项:
- 集中过期,由于清除大量的key会耗时,会出现短暂的卡顿现象
- 解决方案:在设置key过期时间的时候,给每个key加上随机值
如何使用Redis做异步队列?
使用List作为队列,RPUSH生产消息,LPOP消费消息
缺点:不会等待队列有值才去消费
弥补:可以通过在应用层引入Sleep机制去调用LPOP重试
有没别的方法?
BLPOP key [key...] timeout: 阻塞直到队列有消息或者超时
缺点:只提供 一个消费者消费
如何实现生产一次,并让多个消费者消费呢?
使用pub/sub 主题订阅模式
发送者pub发送消息,订阅者sub接收消息
订阅者可以订阅任意数量的频道
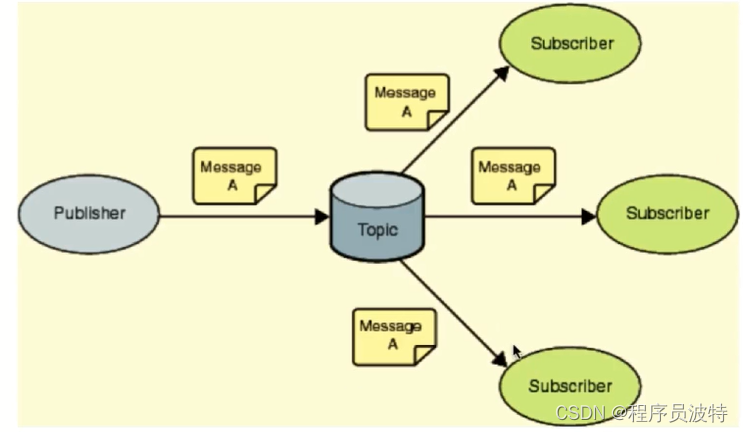
缺点:消息的发布是无状态的,无法保证可达
Redis如何做持久化?
RDB(快照)持久化
保存某个时间点的全量数据快照
SAVE:阻塞Redis的服务器进程,直到RDB文件被创建完毕
BGSAVE:Fork(派生)出一个子进程来创建RDB文件,不阻塞服务器进程
可以通过lastsave查看 上次保存RDB文件的时间
自动触发RDB持久化的方式
根据redis.conf配置里的SAVE m n 定时触发,用的是BGSAVE
主从复制时,主节点自动触发
执行Debug Reload
执行Shutdown且没有开启AOF持久化
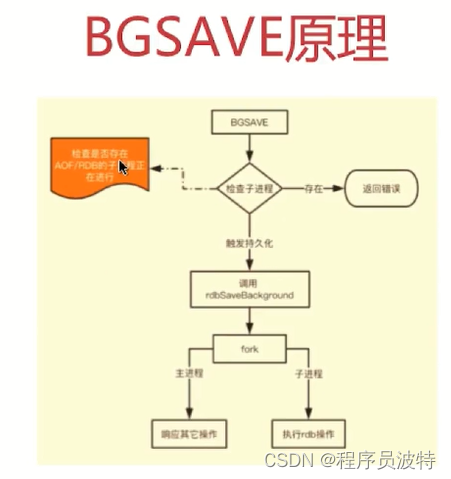
系统调用fork(): 创建进程,实现了Copy-on-Write
如果有多个调用者同时要求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针,指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用的副本给该调用者,而其他调用者所见到的最初的资源操持不变。
缺点:内存数据的全量同步,数据量大会由于I/O而严重影响性能。可能会因为Redis挂掉而丢失从当前至最近的一次快照期间的数据
AOF(Append-Only-File)日志追加
保存写状态
记录下除了查询以外的所有变更数据库的指令
以append的形式追加保存到AOF文件中
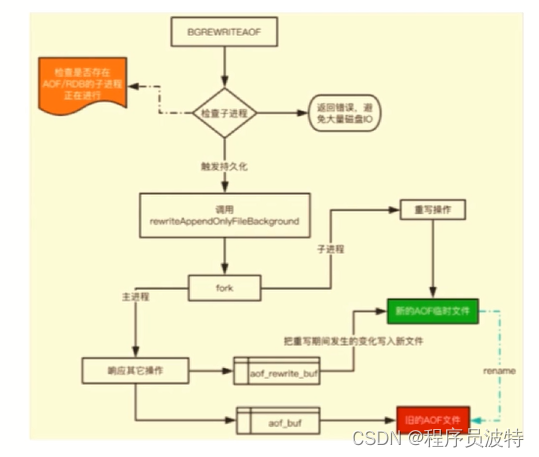
日志重写解决AOF文件大小不断增大的问题,原理如下:
调用fork,创建一个子进程
子进程把新的AOF写到一个临时文件里,不依赖原来的AOF文件
主进程持续把新的变动同时写到内存和原来的AOF里
主进程获取子进程重写AOF完成信号,往新AOF同步增量变动
使用新的AOF文件替换掉旧的AOF文件
RDB和AOF文件共存情况下的恢复流程?

RDB和AOF的优缺点
RDB优点:全量数据快照,文件小,恢复快
RDB缺点:无法保存最近一次快照之后的数据
AOF优点:可读性高,适合保存增量数据,数据不易丢失
AOF缺点:文件体积大,恢复时间长
redis4.0之后提供了RDB-AOF混合持久方式:系统默认
BGSAVE做镜像全量持久化,AOF做增量持久化
使用Pipline的好处
Pipline和Liunx的管道类似
Redis基于请求/响应模型,单个请求处理需要一一应答
Pipline批量执行指令,节省多次I/O往返的时间
有顺序依赖的指令建议分批发送
Redis同步机制

主从同步原理
全同步过程:
slave 发送sync命令到master
master启动一个后台进程,将redis中的数据快照保存到文件中
master将保存的数据快照期间接收到的写命令缓存起来
master完成文件写操作后,将该文件发送给slave
使用新的AOF文件替换掉旧的AOF文件
master将这期间收集的增量命令发送给slave端
增量同步过程
master接受到用户的操作指令。判断是否需要传播到slave
将操作记录追加到AOF文件
将操作记录传播到其他slave:1,对齐主从库 ;2,往响应缓存写入指令
将缓存中的数据发送给slave
Redis Sentinel
解决主从同步Master宕机后主从切换的问题
监控:检查主从服务器是否正常运行
提醒:通过API向管理员或其他应用程序发送故障通知
自动故障转移:主从切换
流言协议Gossip:在杂乱无章中寻求一致
每个节点都随机地与对方通信,最终所有节点的状态达成一致
种子节点定期随机向其他节点发送节点列表以及需要传播的消息
不保证信息一定会传递给所有节点,但是最终会趋于一致
如何从海量数据里快速找到所需?
分片:按照某种规则区划分数据,分散存储在多个节点上,不同的key放在不同的redis节点上
获取key的hash值,然后根据节点数取模,常规的按照哈希划分无法实现节点的动态增减
一致性哈希算法:对2的32次方取模将哈希值空间组织成虚拟的圆环,将数据key使用相同的函数hash计算出哈希值,这样就可以确定每台服务器在哈希环上的具体位置
Liunx中常见的面试问题?
在Liunx中如何让查找指定文件?
- find / -name “target.java” 精确查找文件
- find / -name “target*” 模糊查找文件
- find ~ -iname “target*” 不区分文件名大小写去查找文件
- man find: 跟多关于find指令的使用说明
检索文件常用命令?
管道操作符 |
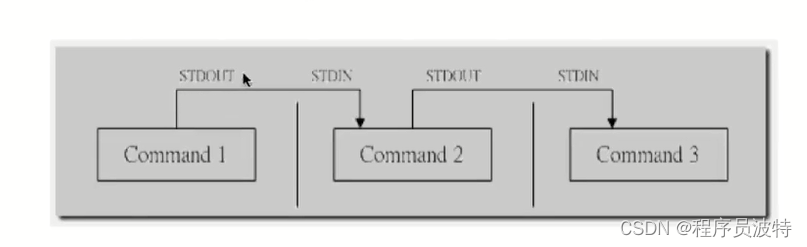
可将操作指令连接起来,前一个 指令的输出作为后一个指令的输入
注意:只处理前一个命令正确的输出,不处理错误的输出
- 在内存中查找包含某个字段的文件:grep ‘partial[true]’ bsc-plat-al-data.info.log
- 选择出符合正则表达式的内容:grep -o ‘engine[[0-9a-z]*]’
- 过滤掉包含相关字符串的内容:grep -v ‘grep’
如何对文件内容做统计?
awk --------- 适合于对表格化的数据进行处理
语法:awk [options] 'cmd' file
一次读取一行文本,按输入的分隔符进行切片,切成多个组成部分,将切片直接保存在内建的变量中,$1,$2…($0表示行的全部),支持对单个切片的判断,支持循环判断,默认分隔符为空格
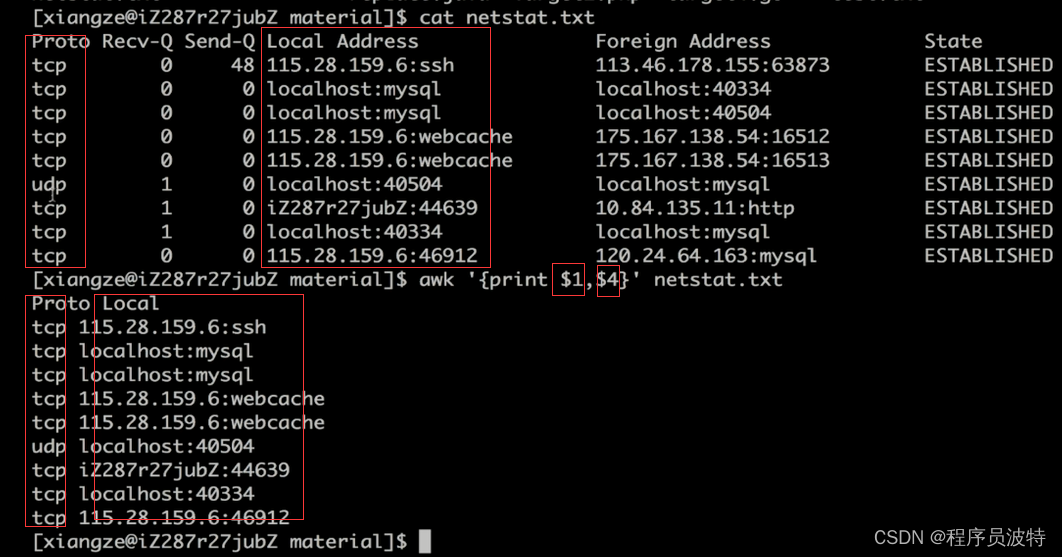
切片1,切片四即代表第一列和第四列的信息,通过print打印出来

定义一个数组名字。通过下标来保存引擎的名字,该数组的值就是对应引擎的值,一旦相同的引擎出现,则对应的值就在原来的基础上进行累加,END就是扫描结束后,要执行的操作,只要于操作相关 ,就要使用花括号,表里数组中的值,并将器其值打印出来

对内容逐行进行统计操作,并列出对应的统计结果,默认的分隔符是空格
如何批量替换文件中的内容?
sed
语法:sed [option] 'sed command' filename
全名:stream editor 流编辑器
适用于对文本的行内容进行处理

筛选出Str打头的行,并进行替换目标文件
持续更新中…
更多面试题,电子书、学习路线、视频教程等学习资源,可在我的个人网站:程序员波特 免费获取。



![[Flutter]设置应用包名、名称、版本号、最低支持版本、Icon、启动页以及环境判断、平台判断和打包](https://img-blog.csdnimg.cn/direct/7949861475f24fb49d880e1737da4f66.png)