文章目录
- 1. INTRODUCTION
- 2. LAMBDA ARCHITECTURE
- A) BATCH LAYER
- B) SPEED LAYER
- C) SERVICE LAYER
- 3. LIMITATIONS OF THE TRADITIONAL LAMBDAARCHITECTURE
- 4. A PROPOSED SOLUTION
- 1. 架构说明
- 2. 前后架构改进对比
1. INTRODUCTION
Lambda架构背后的需求是由于虽然MR能够处理大数据量,且准确性很高,但是高延迟不适用于实时计算。一个好的解决方案是通过kafka+spark组合为流模型,虽然能够提供高可用、低延迟但是准确性会有问题。
lambda架构说明
lambda架构的目标是统一批处理和流处理,并满足可拓展、高可用(对于硬件和人工的错误)需求。
The LA architecture aims to meet the needs of a robust system that is scalable and fault-tolerant against hardware failures and human mistakes
2. LAMBDA ARCHITECTURE
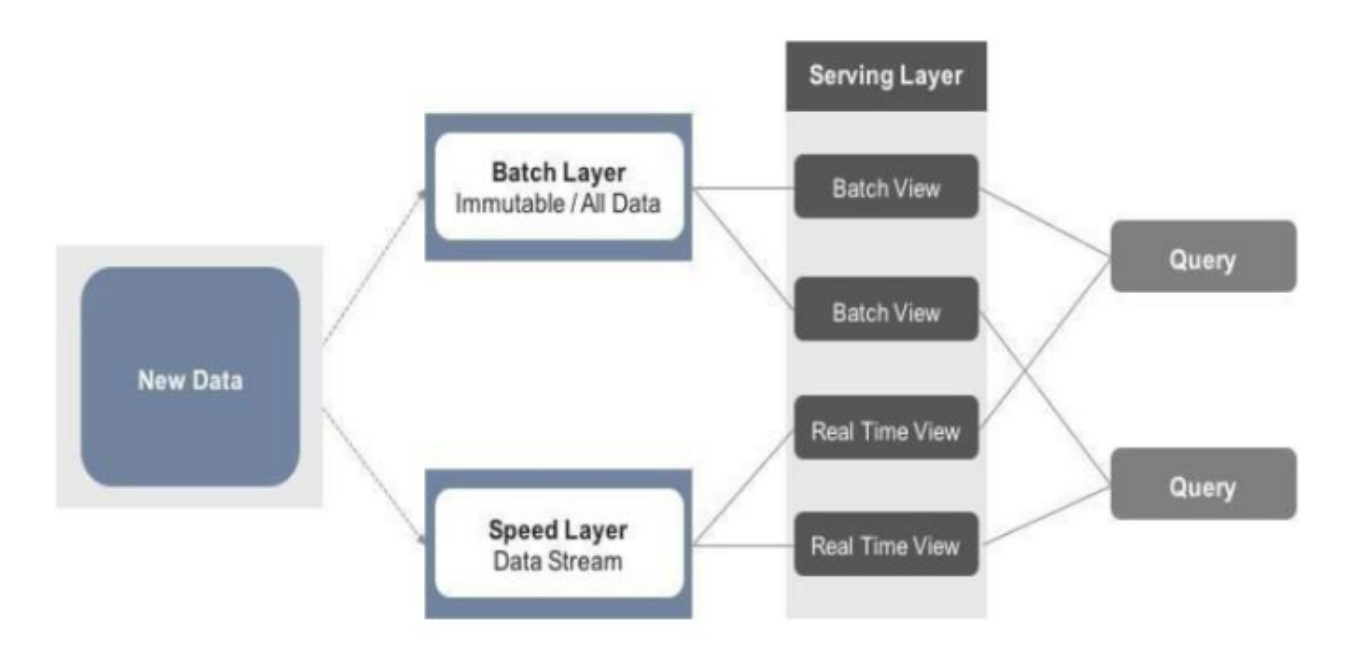
A) BATCH LAYER
不可变数据集的特点
- LA的难点在于主数据集。主数据集不断地以追加方式接收新数据。这种方式非常适合维护数据的不可变性。Marz强调不可变数据集的重要性,因为具备容错性,可以重复计算。
- 批处理层更喜欢重新计算算法而不是
增量(状态计算ing)算法。- 增量算法的问题在于无法解决人为错误所带来的挑战。批处理层的重新计算特性创建了简单的批处理视图,因为在预计算期间解决了复杂性问题。
支持数据模型简化
其次,因为
不需要对数据建立索引,所以不可变数据模型支持简化。批处理层中的主数据集不断增长,并且是体系结构中的详细数据源。主数据集允许对历史数据进行随机读取。
批处理对于机器学习的作用
此外批处理用于处理历史数据并提供准确的结果,机器学习算法需要时间来训练模型,并随着时间的推移提供更好的结果。
批处理的主要问题是高延迟性,所以需要速度层。
B) SPEED LAYER
速度层实时处理消息,虽然实时处理没有考虑到数据的完整性,但是弥补了批处理层的高延迟。
为了创建最新数据的实时视图(视图生产到服务层),速度层牺牲了吞吐量,来降低延迟。当数据接收后实时视图便生成,但不如批处理层的完整或精确。这种设计背后的想法是,一旦批处理层的准确结果到达,它们就会覆盖实时视图。
不同层次的角色分离是 Lambda 架构之美的体现。
- 批处理层通过对整个主数据集进行运行参与了资源密集型操作。
- 速度层采用不同的方法来满足低延迟的要求。与批处理层的重新计算方法相比,速度层采用增量计算。增量计算更加复杂,但速度层处理的数据规模要
小得多,而且视图是短暂的。采用随机读/随机写方法重用和更新以前的视图。
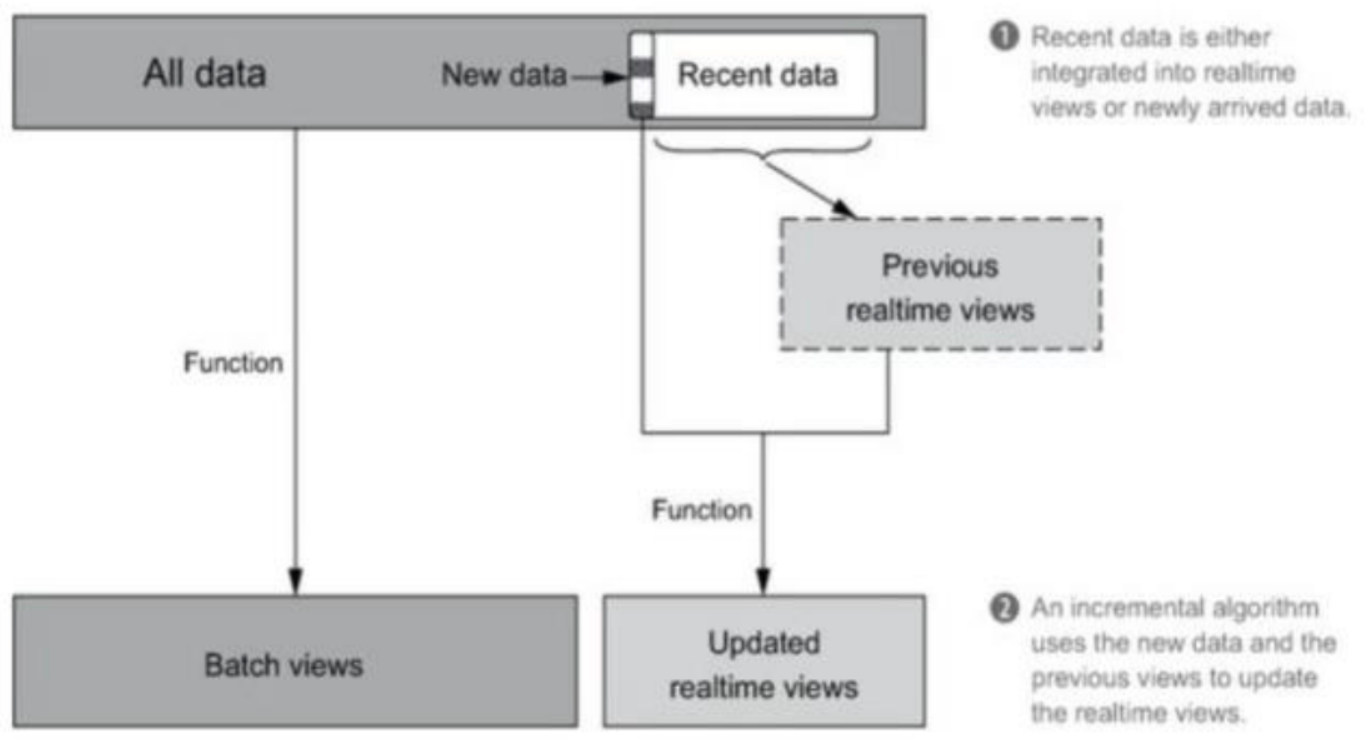
增量计算策略
基本逻辑:批处理先加载所有的数据生成批视图。实时处理当加载新数据时就会创建视图,当再有新的数据时,通过使用之前的视图+新数据来更新实时视图。
C) SERVICE LAYER
服务层负责存储批处理层和速度层的输出。
流批结果配合使用
根据架构图,每当查询 Lambda 架构时,服务层会合并批处理和实时视图,并输出结果。合并的视图可以显示在仪表板上或用于创建报告。因此,Lambda 架构将数据密集但准确的批处理层的结果与快速响应的速度层根据所需的用例进行组合。
这里的视图就是:流批任务生成的物化视图。
3. LIMITATIONS OF THE TRADITIONAL LAMBDAARCHITECTURE
一开始LA的批数据层由hadoop、MapReduce组成,速度层由storm组成,服务层由ElephantDB 和 Cassandra构成。
LA的问题:
- 开发和维护复杂
Lambda架构中对同样的业务逻辑进行两次编程:一次为批量计算的ETL系统,一次为流式计算的Streaming系统。针对同一个业务问题产生了两个代码库,维护起来麻烦。- 创建一个统一解决方案需要处理流批结果合并需求、debug问题以及操作的复杂性
- 输入数据需要同时进入到批和速度层
- 并不是那么通用:现实中许多企业要么都使用批处理系统,要么使用流处理系统去处理他们的问题
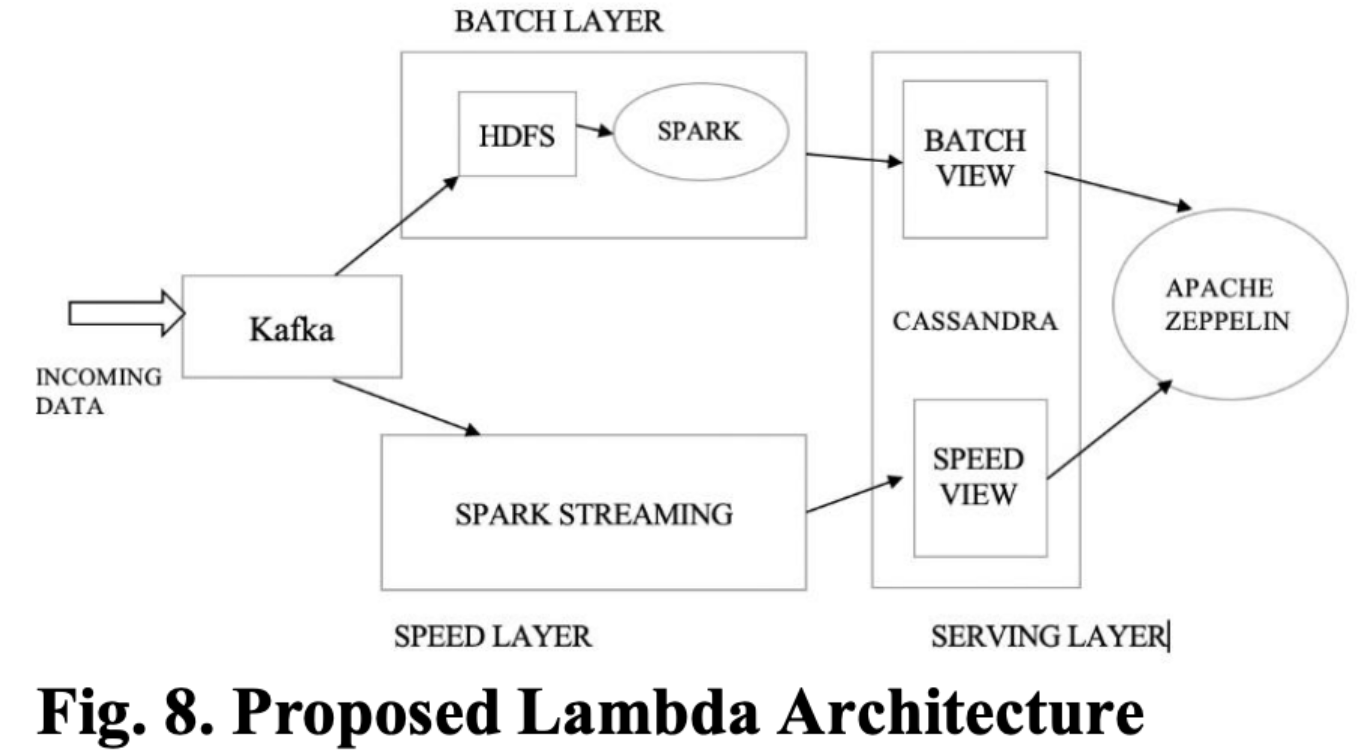
4. A PROPOSED SOLUTION
1. 架构说明
就上面描述的,LA可能会导致编码的复杂性,debug、维护的问题。可以通过组合不同的组件来实现LA,这里通过使用kafka、spark(计算引擎)、Cassandra(视图)、Zeppelin(存储层)来优化LA架构。
之前的架构中,有两套处理系统用于处理批和流数据,批模式中用HDFS+MR处理、流中使用Storm处理,此架构中使用spark作为流批一体的计算引擎。如下图:
2. 前后架构改进对比
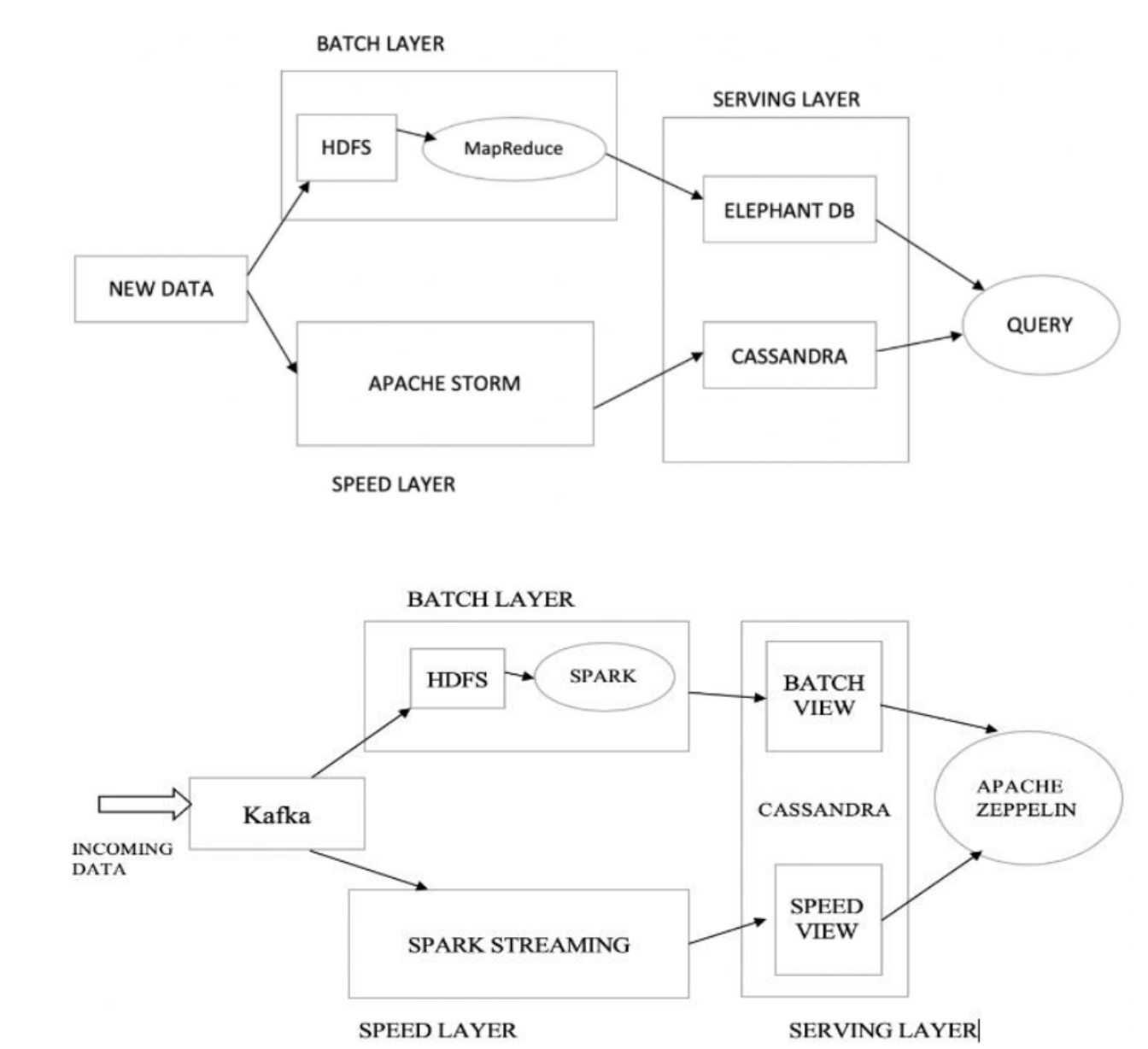
spark VS MR
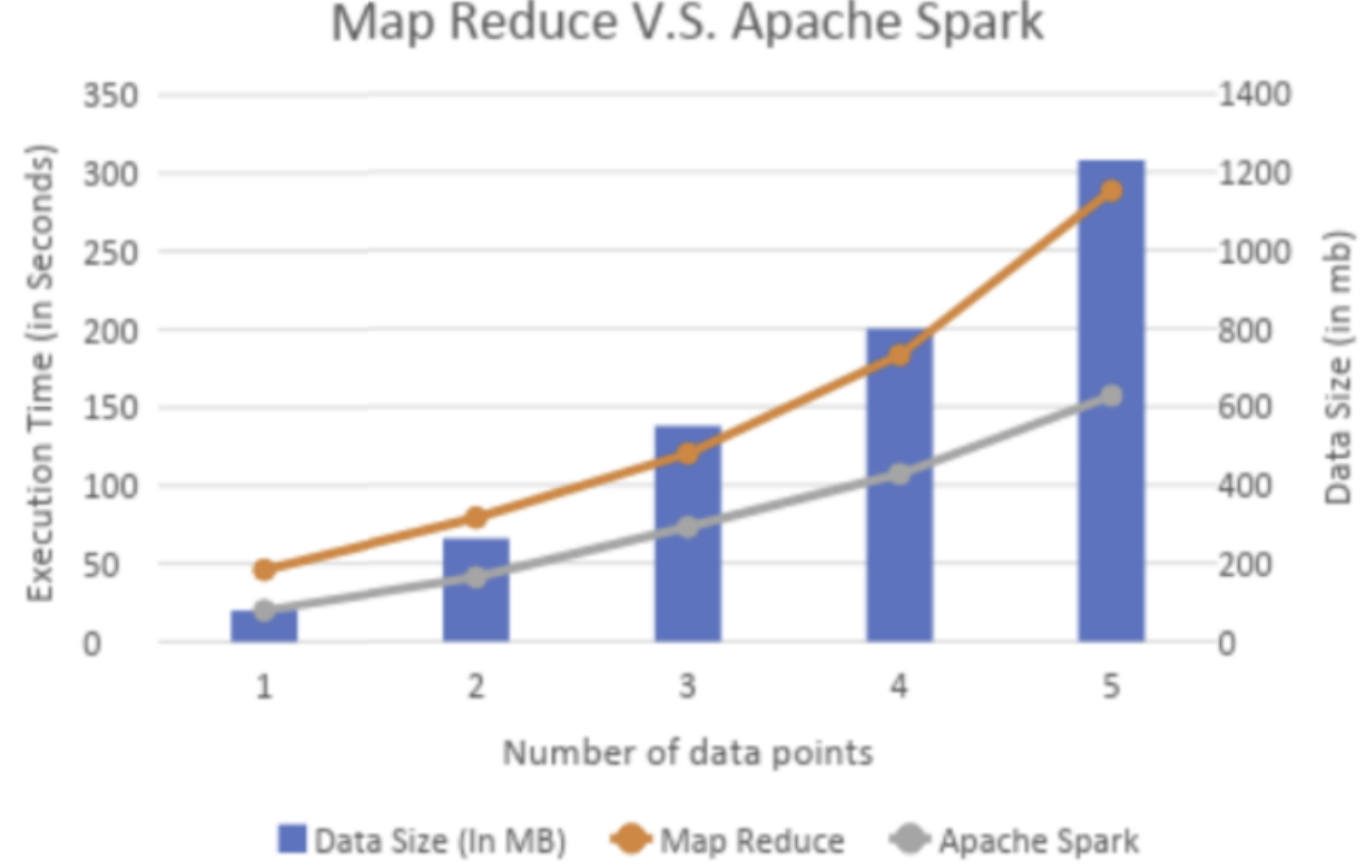
改进的架构中
- kafka减少了复制数据的开销。LA中的批和速度层可以消费kafka中的数据,这减少了复制的复杂性以及简化了架构。
- spark的流批Rich API非常适合LA架构,RDD的代码可以被重用,并且API简化了维护和debug。此外对于批处理,spark基于内存处理提高了处理速度。
- kafka的commit log对于事件流非常有效。commit log是不可变的,所以存储为追加数据。用户的历史事件可以被用于处理。
- kafka的log可以被重放,新的视图可以通过Cassandra物化。
参考:
https://download.csdn.net/download/hiliang521/88881089