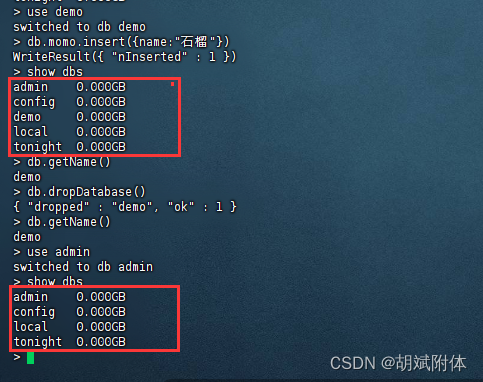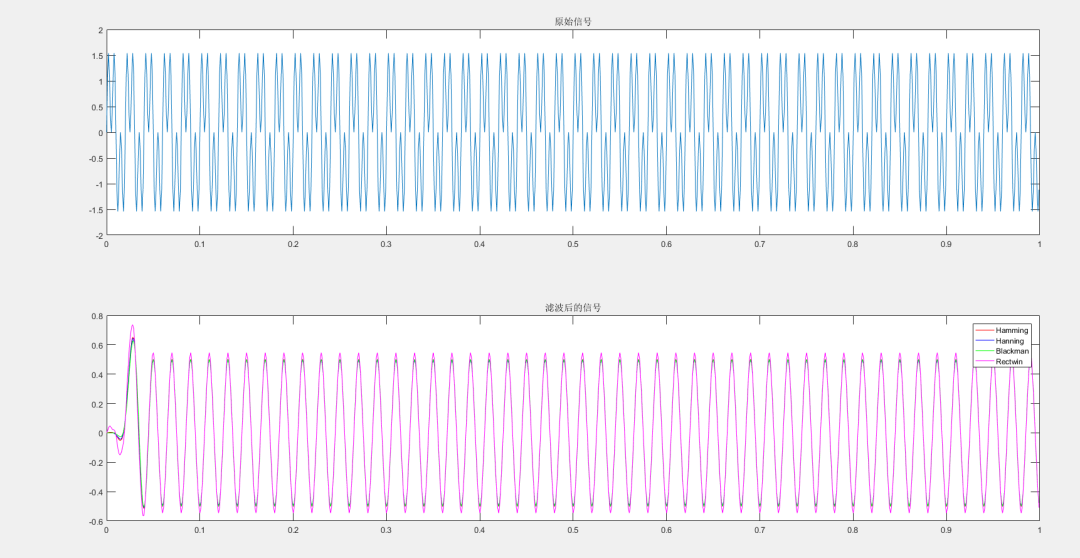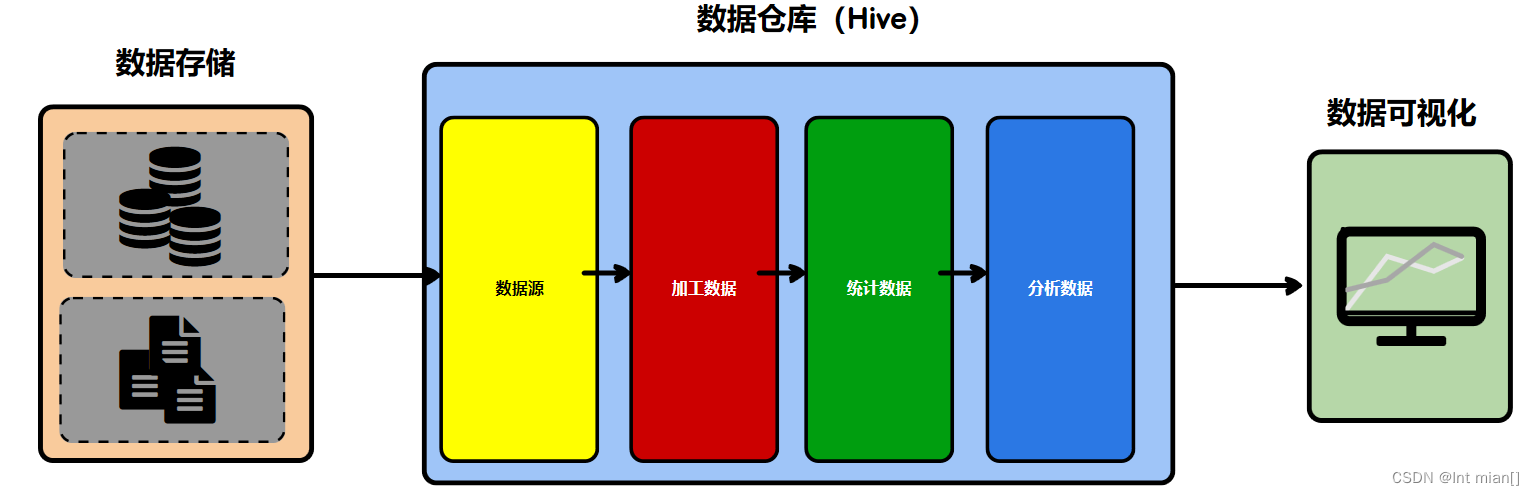
中间的几步意义就在于,缓存中间处理数据样式,避免重复计算浪费算力
分层
ODS(Operate Data Store)
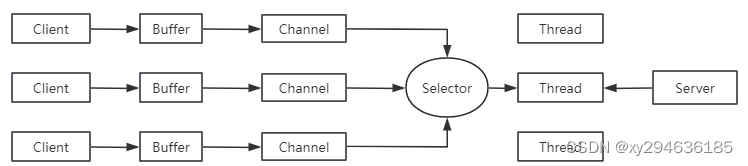
Spark计算过程中,存在shuffle的操作,而shuffle会将计算过程一分为二,前一阶段不执行完,不能执行后面
数据仓库中的不同步骤也存在同样的情况,数据仓库中不称之为阶段,称之为层,每一层就有自己的名称以及对应的逻辑
就是存数据,有一定的整合计算

DWD(Data Warehouse Detail)
对ODS层的数据进行加工处理,为了后面的统计分析做准备
这里的加工表示一个比较宽泛的概念,没有具体的操作
DWS(Data Warehouse Summary)
汇总,冗余,减少计算量
ADS(Application Data Service)
结果数据
DIM共通层(维度层)
从不同维度,几个维度,分析不同指标


之间流转
SQL,并且需要一个任务调度器
想要节省计算,建表是关键,把该有的数据都放到一个表,在操作
建模
ER模型
数据仓库之父Bill Inmon提出的建模方法是从全企业的高度,用实体关系(Entity Relationship,ER)模型来描述企业业务,并用规范化的方式表示出来,在范式理论上符合3NF。遵循的范式级别越高,数据冗余性就越低。
实体关系模型
实体表示一个对象,关系是指两个实体之间的关系,
数据库规范化
数据库规范化是使用一系列范式设计数据库(通常是关系型数据库)的过程,其目的是减少数据冗余,增强数据的一致性。
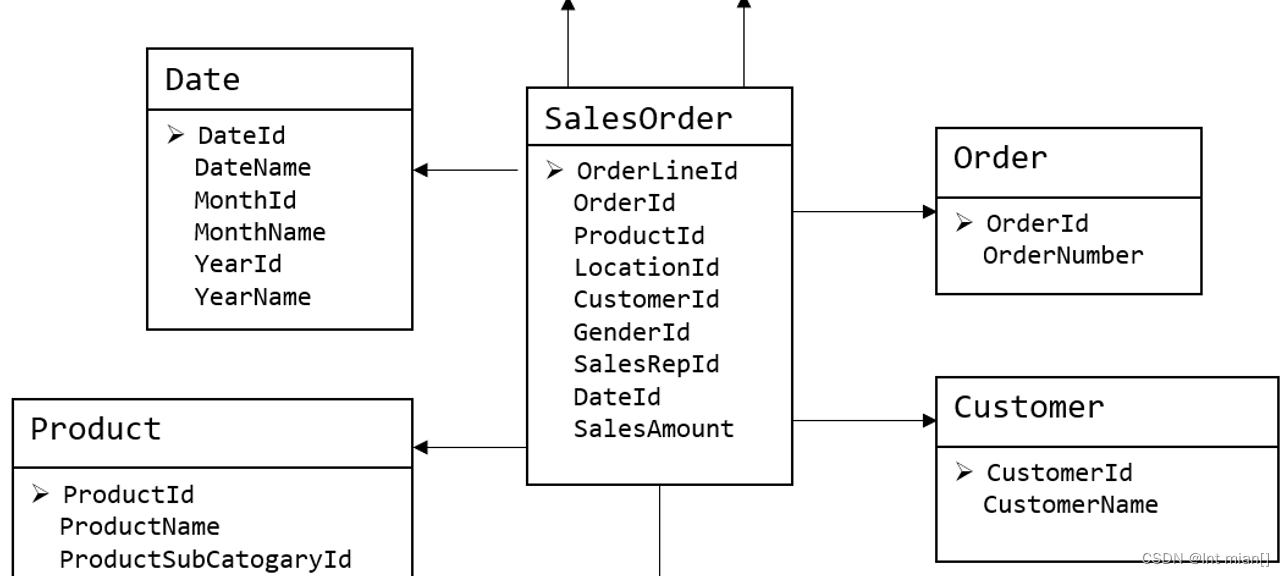
维度模型
维度模型将复杂的业务通过事实和维度两个概念进行呈现。事实通常对应业务过程,而维度通常对应业务过程发生时所处的环境。
注:业务过程可以概括为一个个不可拆分的行为事件,例如电商交易中的下单,取消订单,付款,退单等,都是业务过程。下图为一个典型的维度模型,其中位于中心的SalesOrder为事实表,其中保存的是下单这个业务过程的所有记录。位于周围每张表都是维度表,包括Date(日期),Customer(顾客),Product(产品),Location(地区)等,这些维度表就组成了每个订单发生时所处的环境,即何人、何时、在何地下单了何种产品。
数仓搭建
数仓项目6.0配置大全(hadoop/Flume/zk/kafka/mysql配置)-CSDN博客
连接DataGrip
数仓开发工具可选用DBeaver或者DataGrip。两者都需要用到JDBC协议连接到Hive,故需要启动HiveServer2。
hiveserver2后台启动及关闭_如何关闭hiveserver2后台进程-CSDN博客
模拟数据准备
在这一阶段,只要保证数仓的数据源-hdfs中有数据即可
先将HDFS上/origin_data路径下之前的数据删除。
启动hadoop、zk、ka、fl、f2
修改hadoop102节点的/opt/module/applog/application.yml文件,将mock.date,mock.clear,mock.clear.user,mock.new.user,mock.log.db.enable五个参数调整为如下的值。
#业务日期
mock.date: "2022-06-04"
#是否重置业务数据
mock.clear.busi: 1
#是否重置用户数据
mock.clear.user: 1
# 批量生成新用户数量
mock.new.user: 100
# 日志是否写入数据库一份 写入z_log表中
mock.log.db.enable: 0
执行数据生成脚本lg,生成第一天2022-06-04的历史数据
修改/opt/module/applog/application.properties文件,将mock.date、mock.clear,mock.clear.user,mock.new.user四个参数调整为如图所示的值。
#业务日期
mock.date: "2022-06-05"
#是否重置业务数据
mock.clear.busi: 0
#是否重置用户数据
mock.clear.user: 0
# 批量生成新用户
mock.new.user: 0
执行数据生成脚本,生成第二天2022-06-05的历史数据。
之后只修改/opt/module/applog/application.properties文件中的mock.date参数,依次改为2022-06-06,2022-06-07,并分别生成对应日期的数据。
删除/origin_data/gmall/log目录,将⑤中提到的参数修改为2022-06-08,并生成当日模拟数据。(数据库中有了,不需要日志)
执行全量表同步脚本
mysql_to_hdfs_full.sh all 2022-06-08
由于Maxwell支持断点续传,而上述重新生成业务数据的过程,会产生大量的binlog操作日志,这些日志我们并不需要。故此处需清除Maxwell的断点记录,令其从binlog最新的位置开始采集。
drop table maxwell.bootstrap;
drop table maxwell.columns;
drop table maxwell.databases;
drop table maxwell.heartbeats;
drop table maxwell.positions;
drop table maxwell.schemas;
drop table maxwell.tables;
vim /opt/module/maxwell/config.properties
mock_date=2022-06-08
启动Maxwell,执行增量表首日
mysql_to_kafka_inc_init.sh all
ODS层
(1)ODS层的表结构设计依托于从业务系统同步过来的数据结构。
(2)ODS层要保存全部历史数据,故其压缩格式应选择压缩比较高的,此处选择gzip(海量数据,多压,但压缩效率低)。
(3)ODS层表名的命名规范为:ods_表名_单分区增量全量标识(inc/full)。
日志表
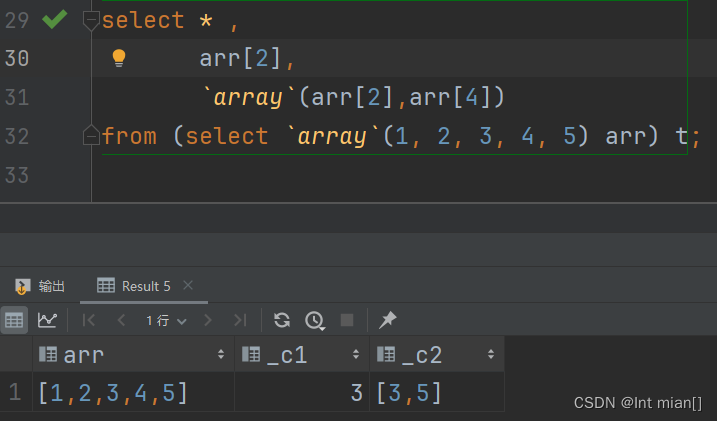
sql结构化类型小知识
DROP TABLE IF EXISTS ods_log_inc;
CREATE EXTERNAL TABLE ods_log_inc
(`common` STRUCT<ar :STRING,ba :STRING,ch :STRING,is_new :STRING,md :STRING,mid :STRING,os :STRING,sid :STRING,uid :STRING,vc :STRING> COMMENT '公共信息',`page` STRUCT<during_time :STRING,item :STRING,item_type :STRING,last_page_id :STRING,page_id :STRING,from_pos_id :STRING,from_pos_seq :STRING,refer_id :STRING> COMMENT '页面信息',`actions` ARRAY<STRUCT<action_id:STRING,item:STRING,item_type:STRING,ts:BIGINT>> COMMENT '动作信息',`displays` ARRAY<STRUCT<display_type :STRING,item :STRING,item_type :STRING,`pos_seq` :STRING,pos_id :STRING>> COMMENT '曝光信息',`start` STRUCT<entry :STRING,first_open :BIGINT,loading_time :BIGINT,open_ad_id :BIGINT,open_ad_ms :BIGINT,open_ad_skip_ms :BIGINT> COMMENT '启动信息',`err` STRUCT<error_code:BIGINT,msg:STRING> COMMENT '错误信息',`ts` BIGINT COMMENT '时间戳'
) COMMENT '活动信息表'PARTITIONED BY (`dt` STRING)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_log_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');set hive.exec.dynamic.partition.mode=nonstrict;-- 装载数据: hdfs-> hive数仓数据源表
load data inpath '/origin_data/gmall/log/topic_log/2022-06-08' into table ods_log_inc partition(dt='2022-06-08');
load data inpath '/origin_data/gmall/log/topic_log/2022-06-09' into table ods_log_inc partition(dt='2022-06-09');
load data inpath '/origin_data/gmall/log/topic_log/2022-06-10' into table ods_log_inc partition(dt='2022-06-10');业务表-活动信息表
-- 17张全量表DataX-TSV-1001 zhangsan 20,表结构和业务表保持一致即可
-- 13张增量表Maxwell-JSON-仅使用最外层的字段作为数据库列尚硅谷资料里给出了30个建表语句
执行建表,执行以下载入语句
vim hdfs_to_ods_db.sh
#!/bin/bashAPP=gmallif [ -n "$2" ] ;thendo_date=$2
else do_date=`date -d '-1 day' +%F`
fiload_data(){sql=""for i in $*; do#判断路径是否存在hadoop fs -test -e /origin_data/$APP/db/${i:4}/$do_date#路径存在方可装载数据if [[ $? = 0 ]]; thensql=$sql"load data inpath '/origin_data/$APP/db/${i:4}/$do_date' OVERWRITE into table ${APP}.$i partition(dt='$do_date');"fidonehive -e "$sql"
}case $1 in"ods_activity_info_full")load_data "ods_activity_info_full";;···················"all")load_data "ods_activity_info_full" "ods_activity_rule_full" "ods_base_category1_full" "ods_base_category2_full" "ods_base_category3_full" "ods_base_dic_full" "ods_base_province_full" "ods_base_region_full" "ods_base_trademark_full" "ods_cart_info_full" "ods_coupon_info_full" "ods_sku_attr_value_full" "ods_sku_info_full" "ods_sku_sale_attr_value_full" "ods_spu_info_full" "ods_promotion_pos_full" "ods_promotion_refer_full" "ods_cart_info_inc" "ods_comment_info_inc" "ods_coupon_use_inc" "ods_favor_info_inc" "ods_order_detail_inc" "ods_order_detail_activity_inc" "ods_order_detail_coupon_inc" "ods_order_info_inc" "ods_order_refund_info_inc" "ods_order_status_log_inc" "ods_payment_info_inc" "ods_refund_payment_inc" "ods_user_info_inc";;
esac
DIM层!!!
DIM层设计要点:
(1)DIM层的设计依据是维度建模理论,该层存储维度模型的维度表。
(2)DIM层的数据存储格式为orc列式存储+snappy压缩。
(3)DIM层表名的命名规范为dim_表名_全量表或者拉链表标识(full/zip)。
维度表是维度建模的基础和灵魂。前文提到,事实表紧紧围绕业务过程进行设计,而维度表则围绕业务过程所处的环境进行设计。维度表主要包含一个主键和各种维度字段,维度字段称为维度属性。
需要注意到,可能存在多个事实表与同一个维度都相关的情况,这种情况需保证维度的唯一性,即只创建一张维度表。(另外,如果某些维度表的维度属性很少,例如只有一个XX名称,则可不创建该维度表,而把该表的维度属性直接增加到与之相关的事实表中,这个操作称为维度退化。)
一个维度一张表,从实践来说,相关的维度设置一张表(性别、年龄)
商品维度表
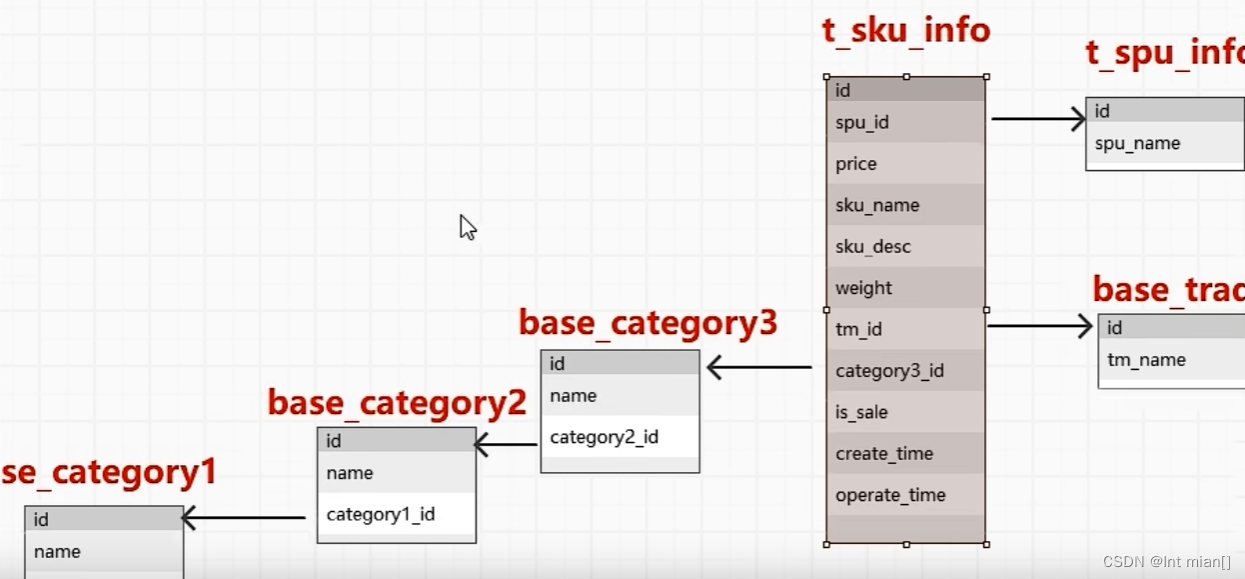
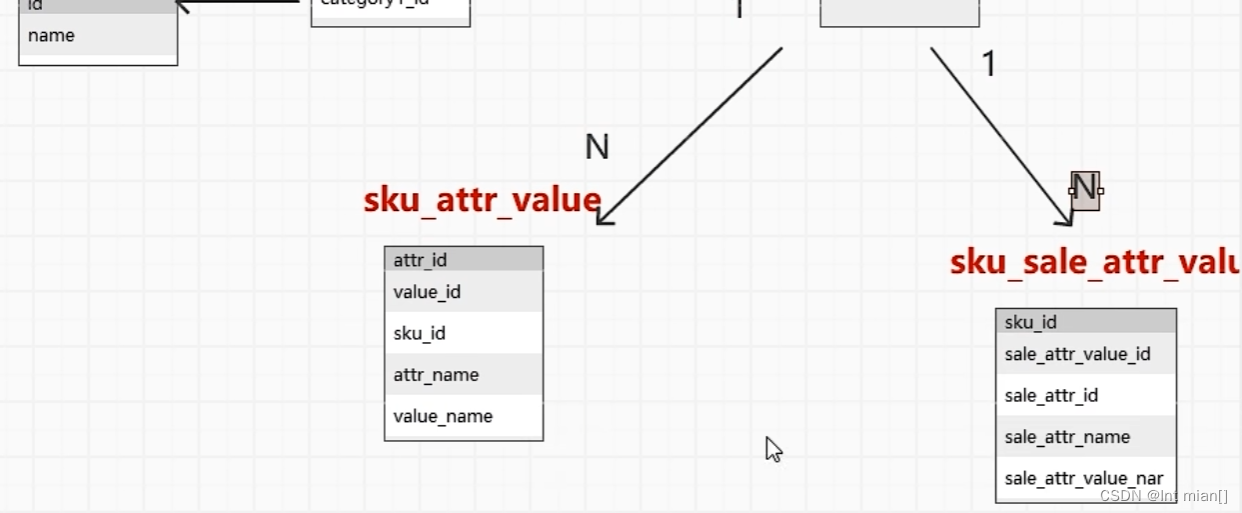

DROP TABLE IF EXISTS dim_sku_full;
CREATE EXTERNAL TABLE dim_sku_full
(`id` STRING COMMENT 'SKU_ID',`price` DECIMAL(16, 2) COMMENT '商品价格',`sku_name` STRING COMMENT '商品名称',`sku_desc` STRING COMMENT '商品描述',`weight` DECIMAL(16, 2) COMMENT '重量',`is_sale` BOOLEAN COMMENT '是否在售',`spu_id` STRING COMMENT 'SPU编号',`spu_name` STRING COMMENT 'SPU名称',`category3_id` STRING COMMENT '三级品类ID',`category3_name` STRING COMMENT '三级品类名称',`category2_id` STRING COMMENT '二级品类id',`category2_name` STRING COMMENT '二级品类名称',`category1_id` STRING COMMENT '一级品类ID',`category1_name` STRING COMMENT '一级品类名称',`tm_id` STRING COMMENT '品牌ID',`tm_name` STRING COMMENT '品牌名称',`sku_attr_values` ARRAY<STRUCT<attr_id :STRING,value_id :STRING,attr_name :STRING,value_name:STRING>> COMMENT '平台属性',`sku_sale_attr_values` ARRAY<STRUCT<sale_attr_id :STRING,sale_attr_value_id :STRING,sale_attr_name :STRING,sale_attr_value_name:STRING>> COMMENT '销售属性',`create_time` STRING COMMENT '创建时间'
) COMMENT '商品维度表'PARTITIONED BY (`dt` STRING)STORED AS ORCLOCATION '/warehouse/gmall/dim/dim_sku_full/'TBLPROPERTIES ('orc.compress' = 'snappy');-- 装载数据-- load-- save
-- 内存不够解决办法!
-- set hive.auto.convert.join=false;
-- set hive.ignore.mapjoin.hint=false;selectsku.`id` ,--STRING COMMENT 'SKU_ID',`price` ,--DECIMAL(16, 2) COMMENT '商品价格',`sku_name` ,--STRING COMMENT '商品名称',`sku_desc` ,--STRING COMMENT '商品描述',`weight` ,--DECIMAL(16, 2) COMMENT '重量',`is_sale` ,--BOOLEAN COMMENT '是否在售',`spu_id` ,--STRING COMMENT 'SPU编号',`spu_name` ,--STRING COMMENT 'SPU名称',`category3_id` ,--STRING COMMENT '三级品类ID',`category3_name` ,--STRING COMMENT '三级品类名称',`category2_id` ,--STRING COMMENT '二级品类id',`category2_name` ,--STRING COMMENT '二级品类名称',`category1_id` ,--STRING COMMENT '一级品类ID',`category1_name` ,--STRING COMMENT '一级品类名称',`tm_id` ,--STRING COMMENT '品牌ID',`tm_name` ,--STRING COMMENT '品牌名称',`sku_attr_values` ,`sku_sale_attr_values` ,`create_time` -- STRING COMMENT '创建时间'
from(select`id` ,--STRING COMMENT 'SKU_ID',`price` ,--DECIMAL(16, 2) COMMENT '商品价格',`sku_name` ,--STRING COMMENT '商品名称',`sku_desc` ,--STRING COMMENT '商品描述',`weight` ,--DECIMAL(16, 2) COMMENT '重量',`is_sale` ,--BOOLEAN COMMENT '是否在售',`spu_id` ,--STRING COMMENT 'SPU编号',
-- `spu_name` ,--STRING COMMENT 'SPU名称',`category3_id` ,--STRING COMMENT '三级品类ID',
-- `category3_name` ,--STRING COMMENT '三级品类名称',
-- `category2_id` ,--STRING COMMENT '二级品类id',
-- `category2_name` ,--STRING COMMENT '二级品类名称',
-- `category1_id` ,--STRING COMMENT '一级品类ID',
-- `category1_name` ,--STRING COMMENT '一级品类名称',`tm_id` ,--STRING COMMENT '品牌ID',
-- `tm_name` ,--STRING COMMENT '品牌名称',`create_time` --STRING COMMENT '创建时间'
from ods_sku_info_full
where dt='2022-06-08') skujoin (selectid,spu_name
from ods_spu_info_full
where dt='2022-06-08'
)spu on sku.spu_id=spu.idjoin (selectid,tm_name
from ods_base_trademark_full
where dt='2022-06-08'
) tm on sku.tm_id=tm.idjoin (selectid,name `category3_name`,category2_id
from ods_base_category3_full
where dt='2022-06-08'
)tem3 on sku.category3_id=tem3.idjoin (
selectid,name `category2_name`,category1_id
from ods_base_category2_full
where dt='2022-06-08'
)tem2 on tem3.category2_id=tem2.idjoin (
selectid,name `category1_name`
from ods_base_category1_full
where dt='2022-06-08'
)tem on tem2.category1_id=tem.idleft join (selectsku_id,collect_list(named_struct("attr_id",attr_id,"value_id",value_id,"attr_name",attr_name,"value_name",value_name)) `sku_attr_values`
from ods_sku_attr_value_full
where dt='2022-06-08'
group by sku_id
) sav on sku.id=sav.sku_idleft join (
selectsku_id,collect_list(named_struct("sale_attr_id",sale_attr_id,"sale_attr_value_id",sale_attr_value_id,"sale_attr_name",sale_attr_name,"sale_attr_value_name",sale_attr_value_name)) `sku_sale_attr_values`
from ods_sku_sale_attr_value_full
where dt='2022-06-08'
group by sku_id
) ssav on sku.id=ssav.sku_id;
省略。。。。。。。。。
用户维度表 dim_user_zip
如果进行每天的全量备份,占用空间过大,需要采取拉链表(压缩)的方式
离线数据仓库的计算周期通常为每天一次,所以可以每天保存一份全量的维度数据。这种方式的优点和缺点都很明显。
优点是简单而有效,开发和维护成本低,且方便理解和使用。
缺点是浪费存储空间,尤其是当数据的变化比例比较低时,造成重复 重复。拉链表适合于:数据会发生变化,但是变化频率并不高的维度(即:缓慢变化维)比如:用户信息会发生变化,但是每天变化的比例不高。如果数据量有一定规模,按照每日全量的方式保存效率很低。比如:1亿用户*365天,每天一份用户信息。(做每日全量效率低)

DWD层
。。。。。。。。。。。。
用脚本导入到mysql,使用superset可视化
整体复盘
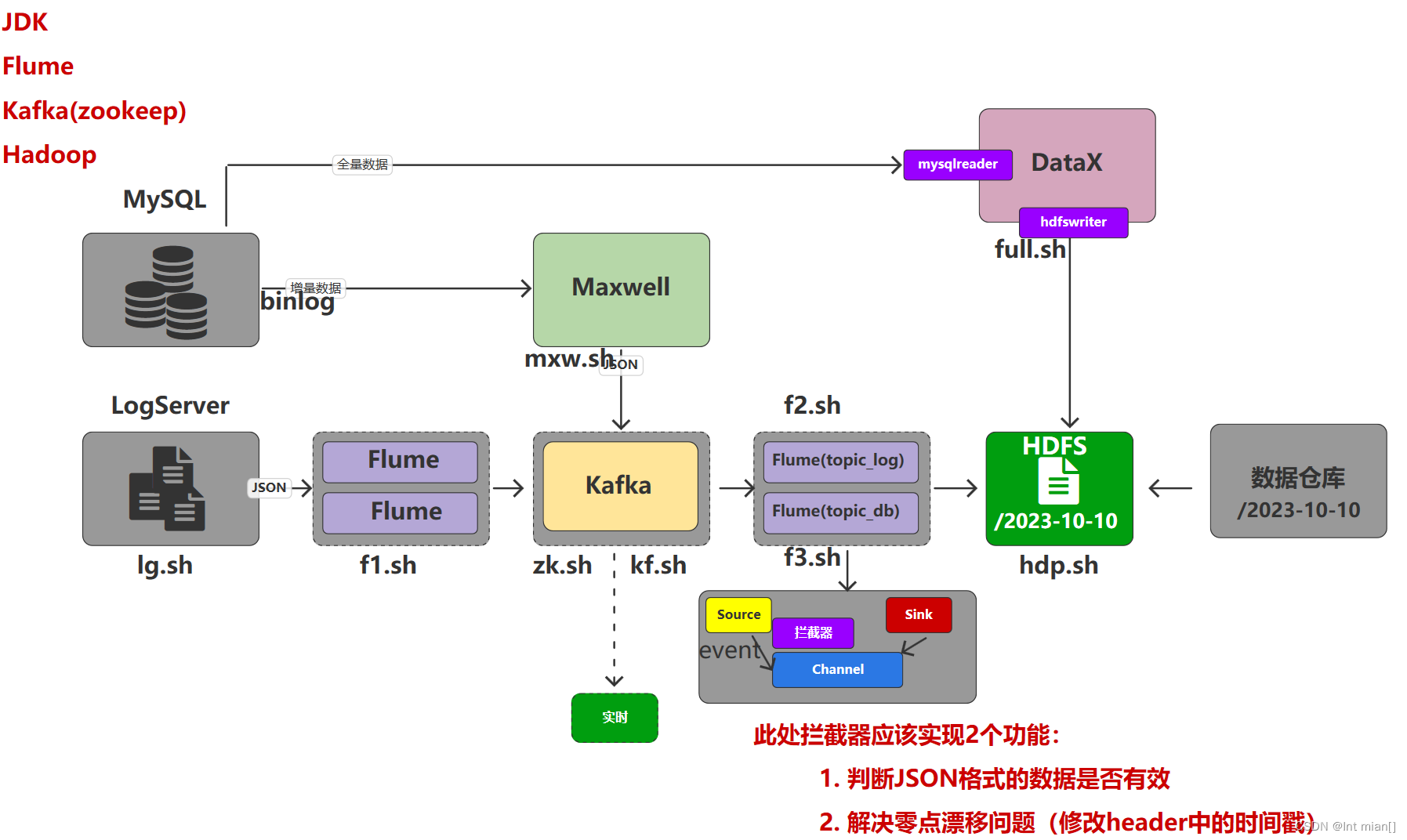
2022-06-08数仓上线首日,准备数据时需要启动hadoop、zk、ka,关掉maxwell用不上
打开3个flume通道
生成6.4-6.7的数据,删掉这几天的日志,不需要上线前的日志
生成6.8的日志与业务数据
通过生成datax配置将全量数据导入hdfs
清空maxwell,用maxwell boot初始化增量数据到kafka,f3拉取到hdfs
可以开始数仓内容
装载log、db,一系列逻辑分析之后,通过生成的datax配置到mysql可视化就行了