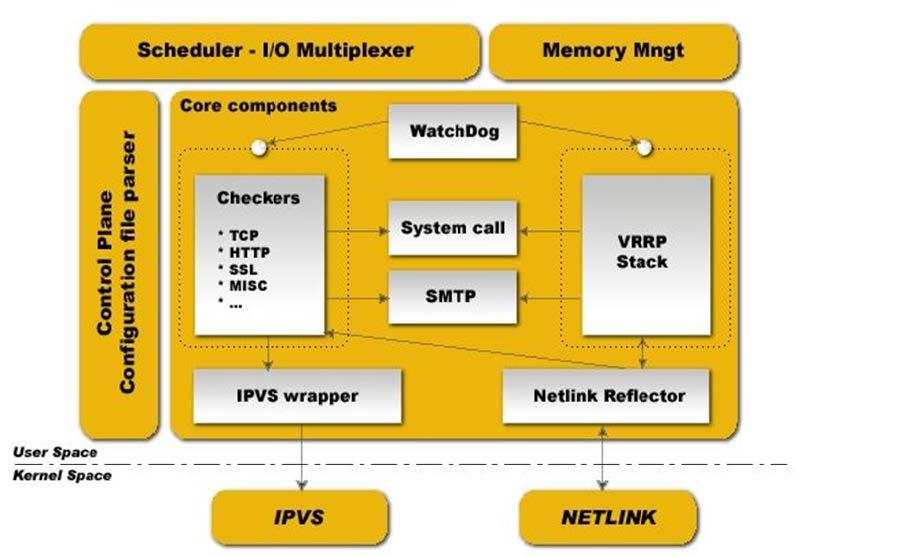
补充知识:进行AES解密需要知道四个关键字,即密钥key,向量iv,模式mode,填充方式pad
一般网页AES都是16位的,m3u8视频加密一般是AES-128格式
网页链接:https://www.jinglingshuju.com/articles
进行抓包结果返回的是密文:

一般思路,无法判断是什么加密方法,一般搜索关键字,这个关键字data太普遍了,所以可以直接搜索decrypt(
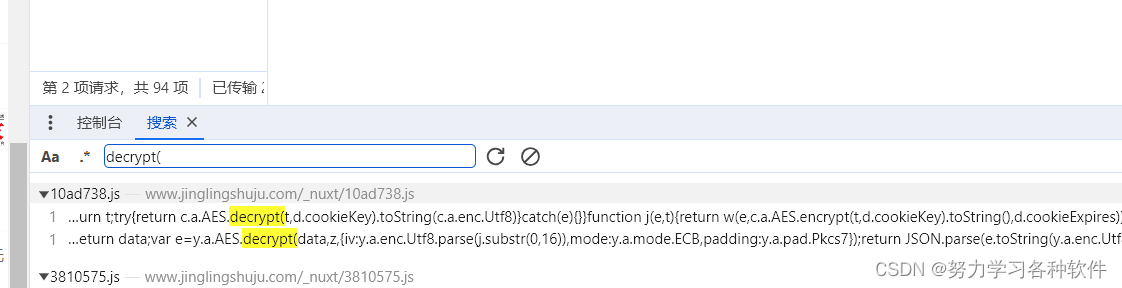
点击其中的js文件,在js文件中继续搜索decrypt(
发现了AES等关键字,一般在return 处打上断点
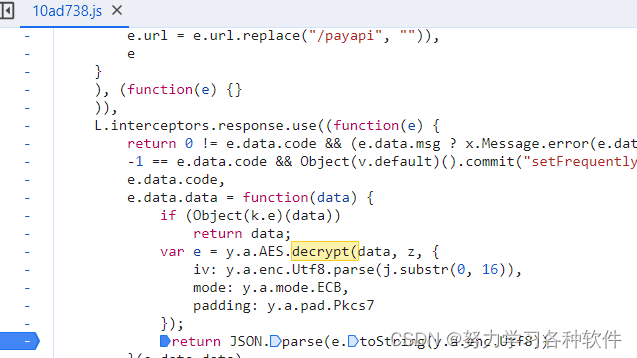
上述js中已经明确了初始向量iv,mode,和padding,z即为密钥
注意:此时必须进行翻页操作触发断点
然后再控制台输入JSON.parse(e.toString(y.a.enc.Utf8))得到下面的结果

如果控制台中有: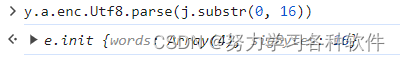
可以使用.toString()变成16位数字:
获得z的值:
如数位观察城市数据的爬取类似的密钥z的值是就j.encode("utf-8")
j的值为: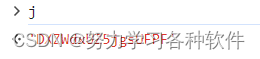
代码展现:
import requests
from Crypto.Cipher import AES # 开始解密
from Crypto.Util.Padding import unpad #去填充的逻辑
import base64
import json
url = 'https://vapi.jinglingshuju.com/Data/getNewsList'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.post(url=url,headers=headers).json()aes = AES.new(key='DXZWdxUZ5jgsUFPF'.encode('utf-8'),mode=AES.MODE_ECB)
ming_data = aes.decrypt(base64.b64decode(response['data']))
ming_data = unpad(ming_data,16)
ming = ming_data.decode('utf-8')# 原始数据# 解析JSON数据
parsed_data = json.loads(ming)# 遍历新闻列表并打印出来
for news in parsed_data['list']:print("标题:", news['title'])print("封面图标:", news['cover_icon'])print("新闻时间:", news['news_time'])print("新闻来源:", news['news_source'])print("发布时间:", news['time_str'])print("详情链接:", news['detail'])print("点击量:", news['hits'])print('作者id:',news['article_id'])结果展现:
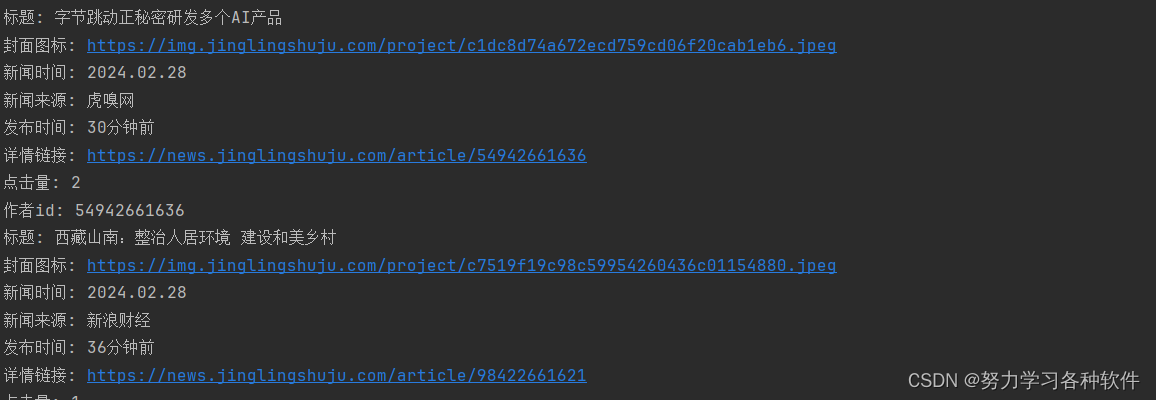
小提示:当返回的是json格式时候,如果没有用json.loads接收,可能会是下面的样子:
"title":"\u82f9\u679c\u7a81\u7136\u4e0d\u9020\u8f66\u4e86\uff0c\u9a6c\u65af\u514b\u6216\u662f\u6700\u5927\u8d62\u5bb6
这种ECB的AES解密的标准流程:
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
import base64def aes_decrypt(ciphertext, key):cipher = AES.new(key, AES.MODE_ECB)decrypted = cipher.decrypt(base64.b64decode(ciphertext))plaintext = unpad(decrypted, AES.block_size)return plaintext.decode('utf-8')iv = b'\x00' * 16 # 初始化向量,ECB模式下不需要使用
key = b'mysecretpassword' # 密钥,长度必须为16字节ciphertext = 'encrypted_text' # 待解密的密文
plaintext = aes_decrypt(ciphertext, key)
print(plaintext)