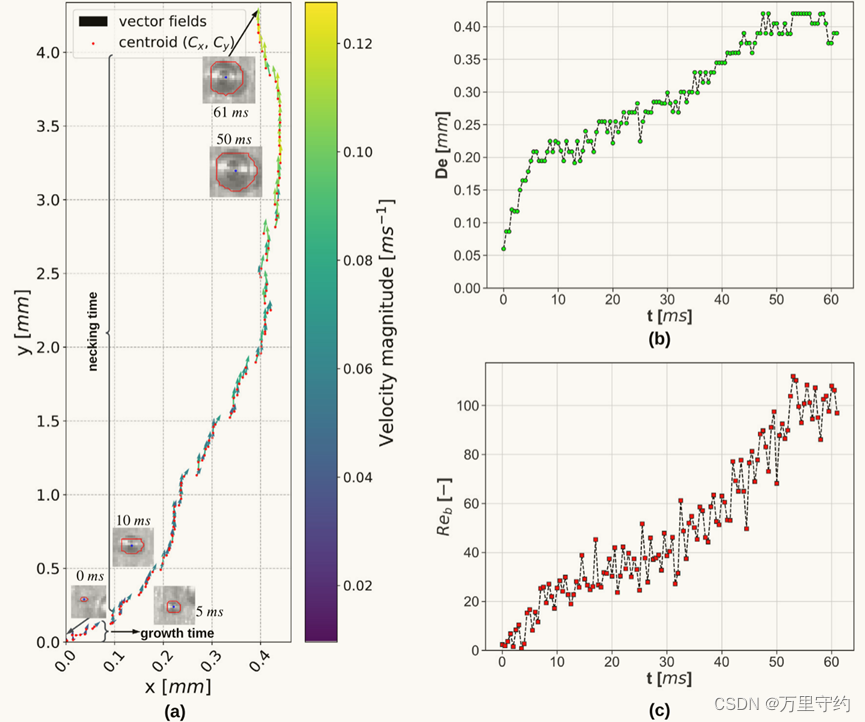
2. Diffusion Models Beat GANs on Image Synthesis
该文基于扩散模型主要做了两方面的工作:一是通过多种方式优化改进了UNet网络结构以提升扩散模型的生成效果;二是提出一种类别引导的条件生成方法,通过在多个数据集上的实验结果表明,改进后的扩散模型无论在无条件生成还是条件生成任务中都取得了媲美甚至超过GAN的性能。
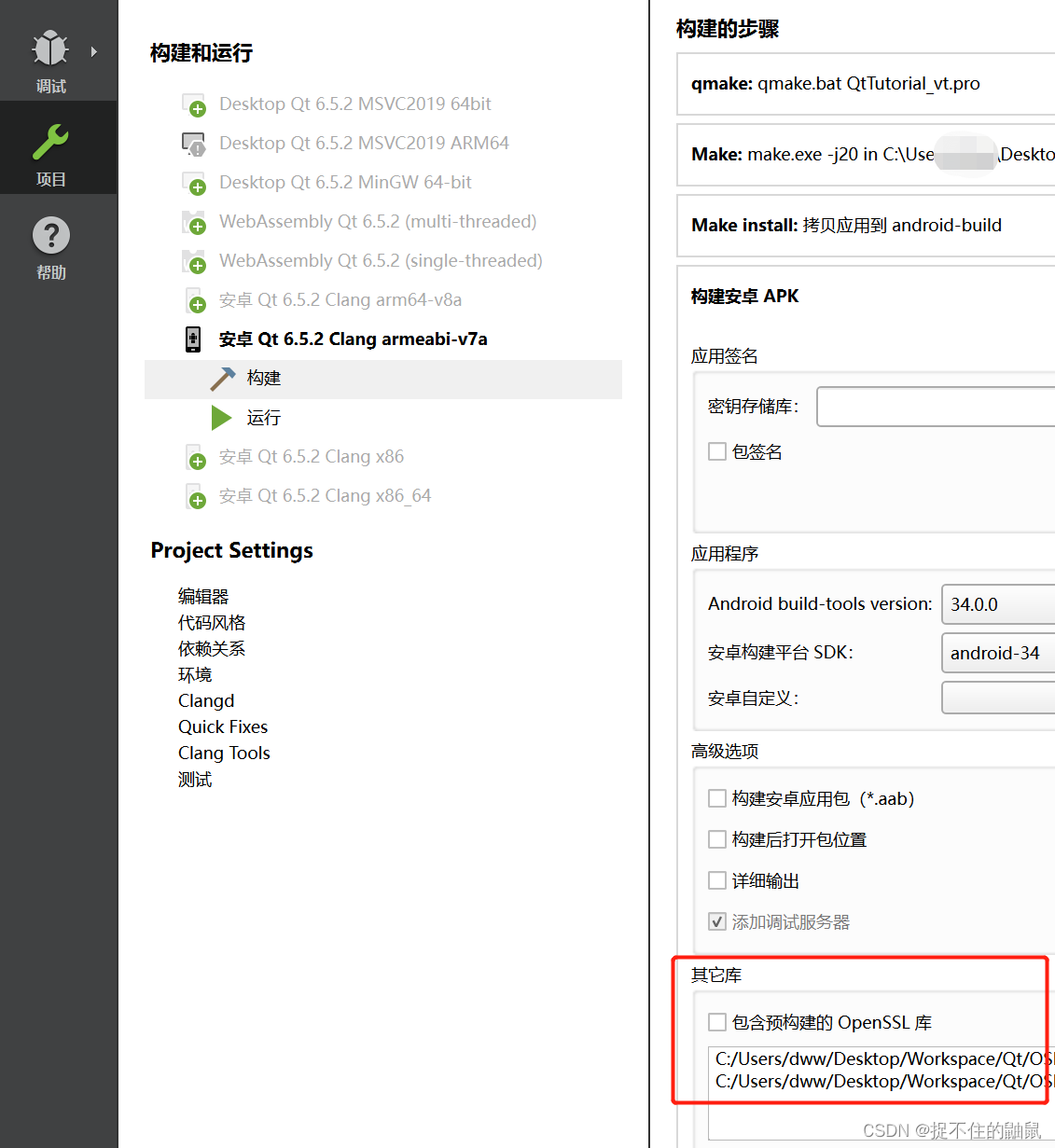
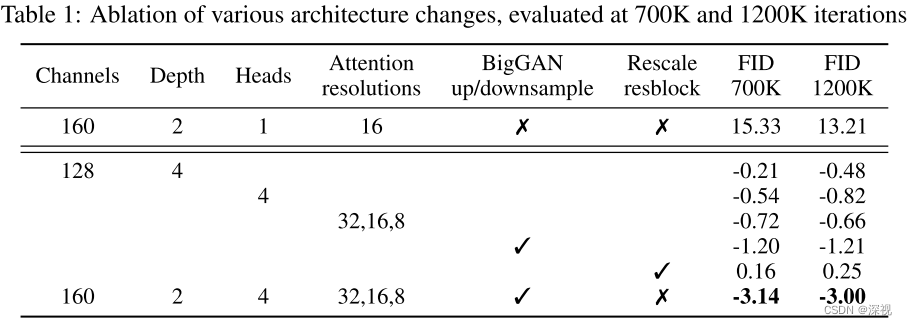
首先,在网络结构方面作者尝试了以下几种改进:1. 增加网络的深度,同时降低每层卷积的通道数,以保持网络的规模不变;2.增加注意力头的数量;3.在多个分辨率条件下使用注意力层;4.使用BigGAN中的残差块用于上采样和下采样;5.对残差链接的特征图进行放缩。经过一系列的消融实验,作者发现除了第5个改进点,其他的改进方案都能一定地提升模型的生成能力,实验结果如下表所示。
除了上述改进,作者还实验了一种称为自适应组规范化(Adaptive Group Normalization, AdaGN)的方法,可以将时间步数和类别信息嵌入到每个残差块中,实现方式如下 A d a G N ( h , y ) = y s G r o u p N o r m ( h ) + y b AdaGN(h,y)=y_sGroupNorm(h)+y_b AdaGN(h,y)=ysGroupNorm(h)+yb其中 y = [ y s , y b ] y=[y_s,y_b] y=[ys,yb], y s y_s ys和 y b y_b yb分别由时间步数和类别嵌入经过一个线性层映射得到, G r o u p N o r m ( ⋅ ) GroupNorm(\cdot) GroupNorm(⋅)表示组规范化层, h h h表示残差块中第一个卷积层输出的特征图。作者实验结果表明,AdaGN能够有效提升样本生成的效果。
此外,作者研究了如何将类别条件引入到扩散模型中,实现类别引导的条件样本生成。其实上文中提到的AdaGN已经可以将类别信息引入到网络模型中了,除此之外,作者又提出一种不同的方式:利用一个分类器 p ( y ∣ x ) p(y|x) p(y∣x)来改善扩散生成器。具体而言,利用带有噪声的图像 x t x_t xt训练一个分类器 p ϕ ( y ∣ x t , t ) p_{\phi}(y|x_t,t) pϕ(y∣xt,t),并使用对数梯度 ∇ x t log p ϕ ( y ∣ x t , t ) \nabla_{x_t}\log{p_{\phi}(y|x_t,t)} ∇xtlogpϕ(y∣xt,t)来引导采样过程,对于DDPM和DDIM其实现过程分别如算法1和2所示

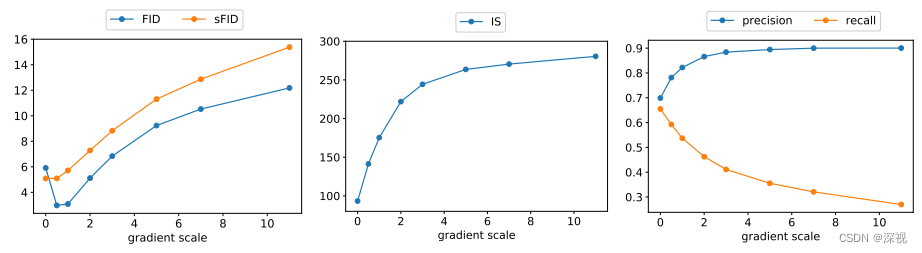
其中的梯度放大系数 s s s控制着生成样本的保真度和多样性,放大系数越大则生成的样本质量越高,保真度越强,但是多样性也会随之下降。如下图所示,由于FID和sFID综合考量了生成样本的保真度和多样性指标(数值越低越好),因此其随着 s s s的增大是先下降再上升的。而IS指标只关注样本生成的保真度(越大越好),因此随着 s s s的增加是逐渐增大的。随着 s s s的增加,Precision和Recall分别增长和降低,但Precision增长到一定上限后,不再继续提升了。
最后,作者在LSUN和ImageNet两个数据集上,将本文改进的方法ADM与其他基于扩散模型的方法和基于GAN的方法进行了比较,其对比结果如下
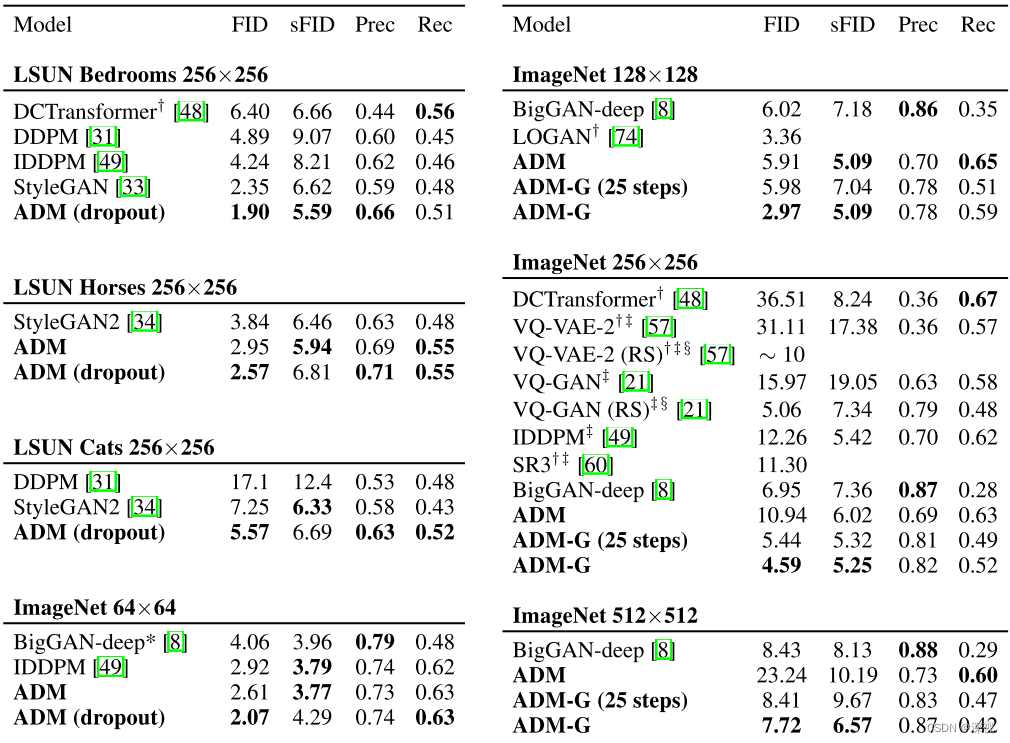
可以看到在多个数据集的多个指标上ADM都取得了不错的结果,尤其是在FID这项指标上,ADM在所有数据集上均取得了最优的性能。