Visual Instruction Tuning
- Abstract
- 1. Introduction
- 2. Related Work
- 3. GPT-assisted Visual Instruction Data Generation
- 4. Visual Instruction Tuning
- 4.1 Architecture
- 4.2 Training
- 5 Experiments
- 5.1 Multimodal Chatchot
- 5.2 ScienceQA
- 6 Conclusion
Abstract
使用机器生成的instruction-following data 对大型语言模型(LLMs)进行指令调优已被证明可以提高新任务的zero-shot能力,但该想法在多模态领域的探索较少。我们首次尝试使用languguage-only GPT-4来生成multimodal language-image instruction-following data。通过对这些生成的数据进行指令调优,我们引入了LLaVA:大型语言和视觉助理(Large Language and Vision Assistant),这是一个端到端训练的大型多模态模型,它将视觉编码器和LLM连接起来,用于通用的视觉和语言理解。为了促进视觉指令跟随的进一步研究,我们构建了****两个具有多样化和挑战性的应用导向任务的evaluation benchmarks。我们的实验表明,LLaVA展示了令人印象深刻的多模态聊天能力,有时在看不见的图像/指令上表现出multimodal GPT-4的行为,与GPT-4在合成(synthetic)的多模态指令遵循数据集上相比,产生了85.1%的相对分数。当在Science QA上进行微调时,LLaVA和GPT-4的协同(synergy)作用达到了92.53%的最新先进水平。我们让GPT-4生成的visual instruction tuning data、我们的模型和代码公开可用。
1. Introduction
人类通过视觉和语言等多种渠道与世界互动,每一种渠道在表达和交流某些概念方面都具有独特的优势,因此有助于更好地理解世界。人工智能的核心目标之一是开发一种通用(general-purpose)的助手,它可以有效地遵循多模态视觉和语言指令,与人类的意图保持一致,在野外完成各种现实世界的任务。
为此(to end this),社区对开发语言增强基础视觉(language-augmented foundation vision models)产生了浓厚的兴趣,这些模型具有强大的开放世界视觉理解能力,如分类、检测、分割和字幕,以及视觉生成和编辑。在这一系列工作中,每个任务由一个单一的大视觉模型独立解决,在模型设计中隐式地(implicityly)考虑任务指令。此外,语言仅用于描述图像内容。虽然这允许语言在将视觉信号映射到语言语义(人类交流的常见渠道)方面发挥重要作用,但它导致模型通常具有固定接口,交互性和对用户指令的适应性有限。
另一方面,大型语言模型(LLM)已经表明,语言可以发挥更广泛的作用:作为通用助手的通用接口,各种任务指令可以显式地用语言表示,并引导端到端训练的神经助手切换到感兴趣的任务来解决它。例如,最近ChatGPT和GPT-4的成功证明了对齐LLM在遵循人类指令方面的强大功能,并激发了开发开源LLM的巨大兴趣。其中,LLaMA是一个与GPT-3性能相匹配的开源LLM。Alpaca , Vicuna , GPT-4-LLM利用各种机器生成的高质量指令遵循示例来提高LLM的对齐能力,与所有的(proprietary)LLM相比,展现了令人印象深刻的性能。重要的是,这一些工作是纯文本的**(text-only**)。
在本文中,我们提出了visual instruction-tuning,这是将visual instruction-tuning扩展到语言-图像多模态空间的第一次尝试,为构建通用的视觉助手铺平了道路(pave the way)。特别地,我们的论文做出了以下贡献:
- Multimodal instruction-following data. 一个关键的挑战是缺乏visual-language instruction-following data 。我们使用ChatGPT/GPT-4提出了一个数据转换视角(reformation perspective)和管道,将图像-文本对转换为适当的instruction-following格式.
- Large multimodal models:我们通过将open-set的视觉编码器CLIP与语言解码器Vicuna连接起来,开发了一个大型多模态模型(LMM),并对我们生成的instruction vision-language decoder进行端到端的微调。我们的实证(empirical)研究验证了使用生成数据进行LMM指令调优的有效性,并提出了构建通用instruction-following visual agent的实用技巧。当与GPT-4集成时,我们的方法在Science QA多模态推理数据集上实现了SoTA。
- Multimodal instruction-following benchmark:我们现在的LLaVA-Bench有两个具有挑战性的基准,有多种选择的配对图像,instruction和详细的注释。
- open-source: the generated multimodal instruction data, the codebase,the model checkpoints以及一个visual chat demo.
2. Related Work
- Multimodal Instruction-following Agents.在计算机视觉中,现有的构建指令跟随agent的工作可以大致分为两类:(i)端到端训练模型,它们分别针对每个特定的研究主题进行探索。例如,视觉语言导航任务(vision-languague navigation task)和Habitat要求嵌入的AI智能体遵循自然语言指令,并采取一系列动作来完成视觉环境中的目标。在图像编辑领域(image editing domain),给定输入图像和告诉agent该做什么的书面指令,InstructPix2Pix通过遵循人类指令来编辑图像。(ii)通过LangChain / LLMs协调各种模型的系统,如Visual ChatGPT、X-GPT、MM-REACT、VisProg和ViperGPT。虽然在构建Instruction-following Agents方面有相同的目标,但我们专注于为mltiple tasksl开发端到端的训练语言视觉多模态模型。
- **Instruction Tuning.**在自然语言处理(NLP)领域,为了使GPT-3、T5、PaLM和OPT等LLM能够遵循自然语言指令并完成现实世界的任务,研究人员探索了LLM指令调优的方法,从而分别产生了指令调优的对应物countpart,如InstructGPT /ChatGPT、FLAN-T5、FLAN-PaLM和OPT- iml。结果表明,这种简单的方法可以有效地提高llm的zero-shot和few-shot的泛化能力。因此,将NLP的思想借用到计算机视觉是很自然的。更广泛地说,基于基础模型的teacher-student distillation已经在图像分类等其他主题中得到了研究。Flamingo可以被看作是多模态域的GPT-3,因为它在zero-shot任务迁移和in-context-leaning方面表现出色。其他在图像文本对上训练的lmm包括BLIP-2、FROMAGe和KOSMOS-1。PaLM-E是一个用于嵌入AI的LMM。基于最近“最好的”开源LLM LLaMA, OpenFlamingo和lama - adapter使LLaMA能够使用图像输入,为构建开源多模态llm铺平了道路。虽然这些模型表现出很好的任务转移泛化性能,但它们没有明确地与视觉语言指令数据进行tuning,并且它们在多模态任务中的性能通常低于(fall short)仅语言任务。本文旨在填补这一空白,并研究其有效性。最后,需要注意的是,视觉指令调优与视觉prompt调优不同:前者旨在提高模型的指令跟随能力,后者旨在提高模型自适应的参数效率。
3. GPT-assisted Visual Instruction Data Generation
社区见证了公共multimodal数据(如图像-文本对)数量的激增,从CC到LAION。然而,当提到multimodal instruction-following data,可用的数量有限,部分原因是,当考虑到人类crowd-scouring筛选时,创建此类数据的过程既耗时又不well-defined。受到最近GPT模型在文本注释任务中的成功的启发,我们提出基于广泛存在的image-pair数据利用ChatGPT/GPT-4进行多模态instruction-following data collection。
对于图像Xv及其相关的captionXc,创建一组指示助手描述图像内容的问题Xq是很正常的。我们prompt GPT-4整理(curate)这样一个问题列表。因此,将图像-文本对扩展到其instruction-following版本的一个简单方法是Human: Xq Xv < STOP> Assistant: Xc< STOP>。虽然构建成本低廉,但这种简单的扩展版本在指令和响应方面缺乏多样性和深度推理。为了缓解这个问题,我们利用仅语言的GPT-4或ChatGPT作为强大的教师(两者都只接受文本作为输入),以创建包含视觉内容的instruction-following data。具体来说,为了将图像编码为视觉特征以提示纯文本GPT,我们使用两种类型的象征(symbolic)表示:(i)Captions:典型地从不同的角度描述视觉场景。(ii)Bounding boxes:通常对场景中的物体进行定位,每个方框对object概念及其空间位置进行编码。如下图所示:

这种象征表示允许我们将图像编码为llm可识别的序列。我们使用COCO图像,生成三种类型的指令跟随数据。如下图所示。对于每种类型,我们首先手动设计一些示例。它们是我们在数据收集过程中唯一的人工注释,并被用作在上下文学习中query GPT-4的种子示例。

我们总共收集了158K个unique的语言图像指令遵循样本,其中对话58K,详细描述23K,复杂推理77k。我们在早期实验中消融了ChatGPT和GPT-4的使用,发现GPT-4持续地提供更高质量的指令跟随数据,例如空间推理。
4. Visual Instruction Tuning
4.1 Architecture
主要目标是有效地利用预训练的LLM和visual模型的能力。网络架构如下图。我们选择Vicuna作为我们的LLM fϕ(·)由ϕ参数化,因为它在公开可用的language tasks checkpoints中具有最佳的instruction following 能力。

对于输入图像Xv,我们利用预训练的CLIP视觉编码器ViT-L/14,它提供视觉特征Zv = g(Xv)。我们的实验利用 了最后一层Transformer前后的网格特征。我们利用一个简单的线性层将图像特征转换到词嵌入空间。具体来说,我们使用一个可训练的投影矩阵W将Zv转换为语言嵌入令牌Hv,它与语言模型中的词嵌入空间具有相同的维数:
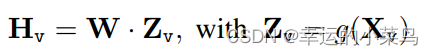
这样,我们就有了一系列视觉标记Hv。请注意,我们的简单投影方案是轻量级的,它允许我们快速迭代以数据为中心的实验。还可以考虑更复杂的方案来连接图像和语言表征,例如Flamingo中的门控交叉注意[2]和BLIP-2中的Q-former[28]。我们将为LLaVA探索更有效、更复杂的架构设计作为未来的工作。
4.2 Training
对于每张图像Xv,我们生成多回合对话数据(X1 q, X1 a,···,XT q, XT a),其中T为总对话数。我们将它们组织成一个序列,将所有的回答视为助手的响应,并将指令Xt指令在第t轮处为:

这引出了多模态指令跟随序列的统一格式表2:

表2 用于训练模型的输入序列。这里只说明了两个对话回合;在实践中,回合数根据指令遵循数据而变化。在我们当前的实现中,我们遵循Vicuna-v0[9]来设置系统消息Xsystem-message,我们设置< stop > = ###。该模型被训练来预测assistabt答案和停止的位置,因此只有绿色序列/令牌用于计算自回归模型中的损失。
我们使用其原始的自回归训练目标对预测令牌执行LLM的指令调优。具体来说,对于长度为L的序列,我们计算目标答案Xa的概率:

其中,θ为可训练参数,xdirective,<i和Xa,<i分别为当前预测令牌xi之前所有回合的指令令牌和回答令牌。对于上述公式中的条件,我们显式地添加了Xv,以强调图像是基于所有答案的事实,并且为了更好的可读性,我们省略了Xsystem-message和所有前面的
- **Pre-training for feature alignment.**为了在概念覆盖率和训练效率之间取得平衡,我们将CC3M过滤到595K图像-文本对。有关过滤过程的详情,请参阅附录。使用第3节中描述的朴素扩展方法将这些数据对转换为跟随指令的数据。每个样本都可以视为单回合对话。为了构造(2)中的输入x指令,对于图像Xv,随机采样一个问题Xq,这是一个语言指令,要求助手对图像进行简要描述。预测答案的ground-truth 是Xa原始的caption。在训练中,我们保持视觉编码器和LLM权值不变,并最大化(3)的似然值,只有可训练参数θ = W(投影矩阵)。这样,图像特征Hv可以与预训练的LLM词嵌入对齐。这个阶段可以理解为为冻结的LLM训练一个兼容的视觉tokenizer。
- **Fine-tuning End-to-End.**我们始终保持视觉编码器权值不变,并不断更新投影层和LLM的预训练权值;即,可训练的参数是θ = {W, ϕ} in(3)。我们考虑两个特定的用例场景:
- **Multimodal Chatbot:**我们通过对第3节中的158K语言图像指令跟踪数据进行微调来开发聊天机器人。在这三种类型的响应中,会话是多回合的,而其他两种是单回合的。它们在训练中被统一采样。
- Science QA:我们在ScienceQA基准上研究了我们的方法,这是第一个大规模的多模态科学问题数据集,它用详细的lecture和解释注释了答案。每个问题都以自然语言或图像的形式提供上下文。Assistant 用自然语言提供推理过程,并从多个选项中选择答案。对于(2)中的训练,我们将数据组织为单回合对话,问题和上下文作为Xinstruct,推理和答案作为Xa
5 Experiments
我们通过两个主要的实验设置分别评估了LLaVA在指令跟随和视觉推理能力方面的性能:多模态聊天机器人和ScienceQA数据集。我们使用8× A100训练所有模型,遵循Vicuna的超参数。我们在过滤后的CC-595K子集上对模型进行了1 epoch的预训练,学习率为2e-3,批大小为128,并对提出的llava - instruction - 158k数据集进行了3 epoch的微调,学习率为2e-5,批大小为32
5.1 Multimodal Chatchot
我们开发了一个聊天机器人演示,以展示LLaVA的图像理解和对话能力,并研究LLaVA在消化视觉输入和展示指令遵循方面的能力。我们首先使用原始GPT-4论文中的示例,如表3所示,这些示例需要深入的图像理解。为了比较,我们从他们的论文中引用了多模态GPT-4的prompt和response,并query了BLIP-2和OpenFlamingo模型检查点来获得它们的回答。