在操作数据库中的表时,需要先使用该数据库:
use database;
新增
创建表
先用 use 指定一个数据库,然后使用 create 新增一个表
比如建立一个学生表
mysql> use goods;
mysql> create table student(-> name varchar(4),-> age int,-> grade decimal(3,1)-> );
通过desc + 表名来查看表结构:
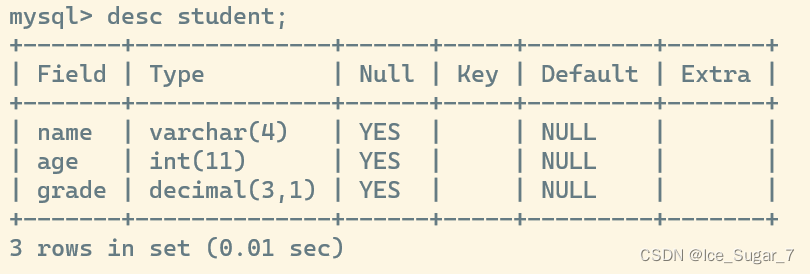
其中的 name、age、grade 就是列(MySQL中的列就是我们平时所说的行);Field、Type 等就是行,其中 Null 中的Yes 表示该列可以为空,如果是 NO 则不可为空,Default 表示该列的默认值
表中各行所表示的含义如下:
插入记录
创建好表之后,使用 insert into 表名 values(列名 列名...) 来插入记录:
mysql> insert into student values("张三",20,98.5);
这里我们把所有列名都插入了,我们也可以指定插入部分列名,只需在表名后面加上要插入的列名就 ok 了:
mysql> insert into student(name,grade) values("李四",90);
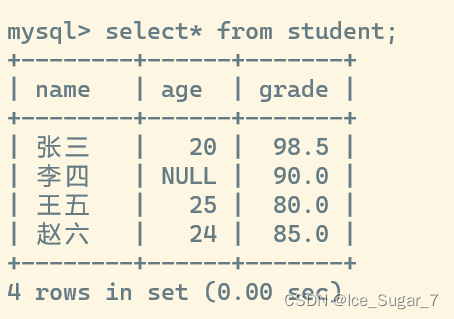
插入后查看表

可以看到 age 那里是 NULL,它表示这条记录的这一列为空
我们现在是一条一条地插入,其实也可以一次插入多条记录:
mysql> insert into student values("王五",25,80),("赵六",24,85);
一次插入10个数据比一次插入一个数据,分10次完成的效率高
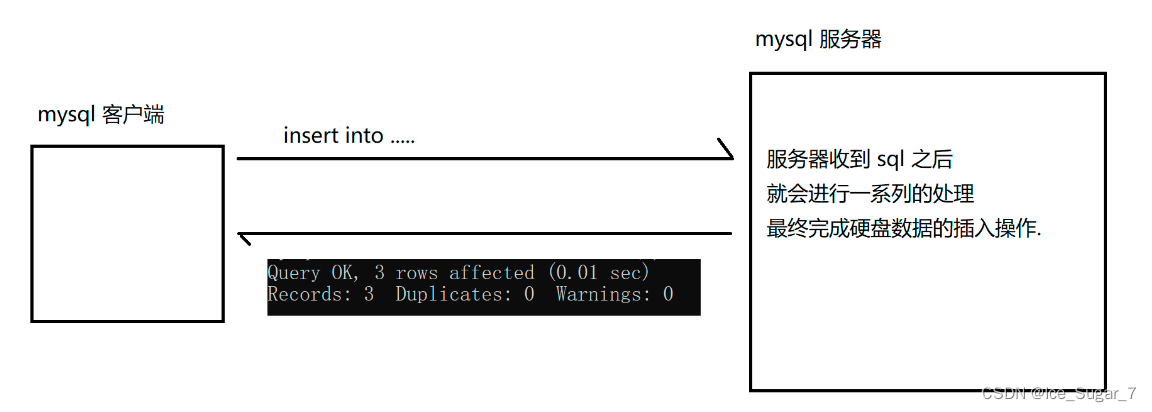
因为每条 sql 都会涉及到下面的交互过程:
-
如果分 10 条 sql 进行,那意味着在这个过程中,就会有10次网络交互
数据库服务器收到请求之后,也要进行 10 次对应的处理,比如检查语法、数据校验、把你要插入的数据的位置在硬盘上进行定位… -
如果只用 1 次完成,虽然单次消耗的时间会更长,但是网络开销、服务器检查的开销都是一份的,这个做法会更高效一些
查询
可以通过 select * from 表名 查询到表中所有数据,比如上面就是通过这条语句来查看数据的
也可以使用select 列名,列名 from 表名来查看指定列的信息
注意:在公司的生产环境服务器上,不要随便敲select* !!!因为数据量很大的话,这个操作会产生大量的硬盘IO和网络IO,可能把硬盘或网卡的带宽给吃满了
而一旦带宽吃满,此时服务器就无法正常响应其他客户端的请求(在其他客户端的视野中,就会认为MySQL服务器是挂了)
除了上面两种查询方式,我们还可以使用表达式查询
就是在查询过程中,指定表达式,把查询出来的每一行,都代入到表达式中进行运算
比如下面的grade-10就是一个表达式
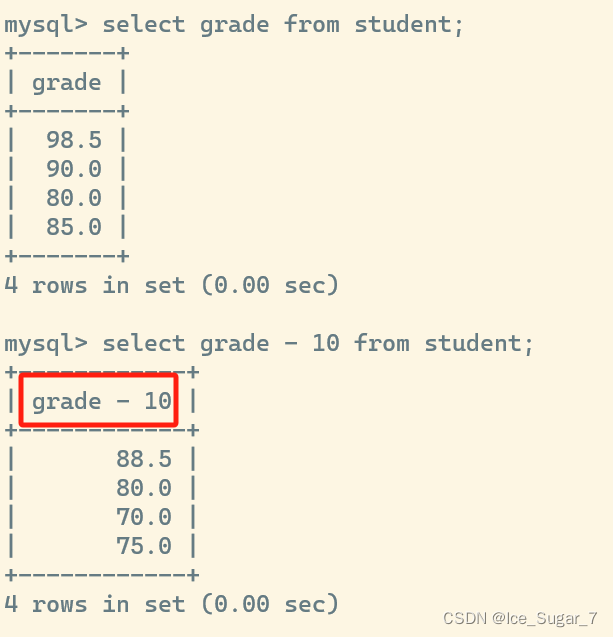 进行表达式查询时,并没有修改硬盘中存储的数据,只是在查询结果的基础上进行运算,得到一份
进行表达式查询时,并没有修改硬盘中存储的数据,只是在查询结果的基础上进行运算,得到一份"临时表",也就是说 select 进行的任何操作都不会修改数据本体
此时查询出来的临时表,为了保证数据的正确性,每个列的类型不再受限于原始表
比如给所有学生的成绩加10

虽然 grade 限定位数为 3 ,但是为了使数据不会出错,所以临时表不会限制位数
查询操作结束后,临时表中的数据就会消散了
小结:有三种查询方式
①查询所有数据
②查询指定列数据
③表达式查询





![TeXiFy IDEA 编译后文献引用为 “[?]“](https://img-blog.csdnimg.cn/direct/464f404a023f4f89a3a2929916f8e404.png)


