文章目录
- 1. http协议
- 1.1 http协议简介
- 1.2 url组成
- 1.3 urlencode与urldecode
- 2. http协议的格式
- 2.1 http协议的格式
- 2.2 一些细节问题
- 3. http的方法、状态码和常见响应报头
- 3.1 http请求方法
- 3.2 http状态码
- 3.3 http常见的响应报头属性
- 4. 一个非常简单的http协议服务端
- 5. http长链接
- 6. http会话保持
1. http协议
1.1 http协议简介
在上一篇文章中我们了解到应用层协议是可以由程序员自己定制的。
计算机领域经过了这么长时间的发展,肯定会出现很多已经写好的协议,我们直接拿来用就可以了的。事实也确实如此,http协议(超文本传输协议)就是其中之一。
这个协议是用于客户端向服务端请求“资源”,包括文本、图片、音频、视频等资源的协议。因为它不只能拿文本资源,所以叫超文本传输协议。
1.2 url组成
我们平常说的网址,其实就是URL,这个URL有很多个部分组成的
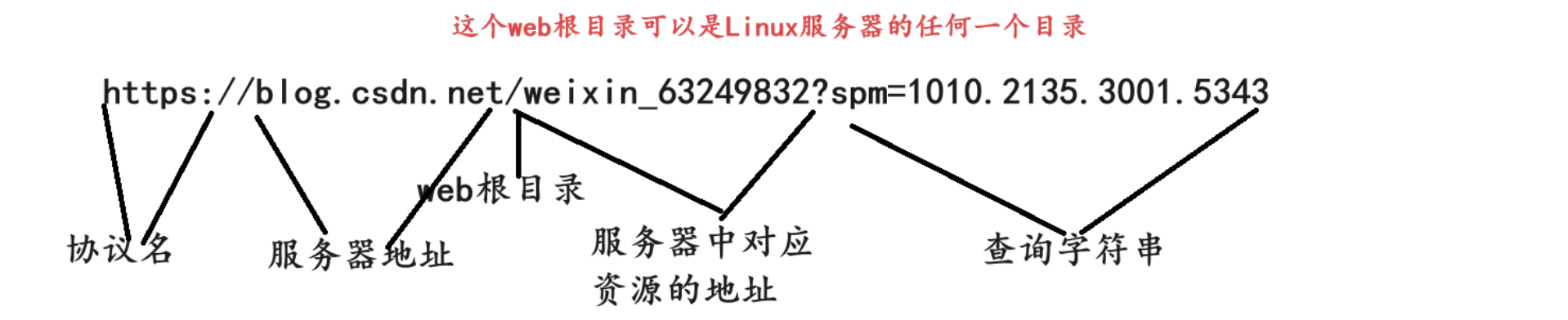
在客户端向服务端发起通信的时候,通过DNS将这个服务器地址转换成IP地址,在其后面应该有端口号的,但是http协议的端口号固定就是80,https端口号固定是443,就能通过这个I P地址+端口号找到指定服务器的指定进程,然后通过对应的资源地址在web根目录下找到对应的资源
1.3 urlencode与urldecode
对于像 / + : ?等字符, 已经被url特殊处理了。比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
转义的规则如下:取出字符的ASCII码,转成16进制,然后前面加上百分号即可。编码成%XY格式。服务器收到url请求,将会对%XY进行解码,该过程称为decode
2. http协议的格式
2.1 http协议的格式
http协议的请求和响应都分为四个部分。对于请求,分为1. 请求行; 2. 请求报头; 3. 一个空行; 4.请求正文;对于响应,分为1. 状态行; 2.响应报头; 3. 一个空行; 4. 响应正文

其中在请求行,有三个部分内容,通过空格来区分,这三个部分分别是1. 请求方法; 2. url 3. http版本,这个版本现在有1.0;1.1;2.0
格式是http/版本号,例如http/1.1
2.2 一些细节问题
1. 请求和响应怎么保证读取完了?
每次可以读取完整的一行 ==> 循环读取每一行,直到遇到空行 ==> 此时就读取了所有的请求报头和请求行 ==> 在请求报头里面有一个属性Content-Length表示正文长度,解析这个长度,然后按照指定长度读取正文即可
2. 请求和响应是怎么做到序列化和反序列化的?
http不用关注json等序列化和反序列化工具,直接发送即可。服务器解析客户端的请求,获取其中的信息填充至响应缓冲区。服务器通过响应报头的方式返回请求的参数,在响应正文中返回请求的资源。
3. http的方法、状态码和常见响应报头
3.1 http请求方法
| 请求方法 | 说明 | 支持的http协议版本 |
|---|---|---|
| GET | 获取资源(表单在url中携带) | 1.0/1.1 |
| POST | 传输实体主体(表单在请求正文中携带) | 1.0/1.1 |
其他方法不常用,这里就不列出来了
我们经常会在网页填写一些内容提交,如果使用GET方法的话,这些内容会被浏览器拼接到url后面(使用?作为分隔符),如果使用PSOT方法的话,这些内容就会在请求正文中
1、GET方法通过URL传递参数。例如http://ip:port/XXX/YY?key1=value1&key2=value2。像百度的搜索就是用的GET方法。GET方法通过url传递参数,参数注定不能太大,例如上传视频等巨长的二进制文件就不适合用GET了。
2、POST提交参数通过http请求正文提交参数。请求正文可以很大,可以提交视频等巨长的文件。
3、POST方法提交参数,用户是看不到的,私密性更高,而GET方法不私密。私密性不等于安全性,POST方法和GET方法其实都不安全!(http请求都是可以被抓到的,想要安全必须加密,使用https协议)
3.2 http状态码
http协议在响应的时候就会在状态行给出本次请求的响应状态,可以理解成是这个请求的“退出码”。
一般来说,http的状态码分为5类
| 类别 | 原因短语 | |
|---|---|---|
| 1xx | Informational(信息性状态码) | 接收的请求正在处理 |
| 2xx | Success(成功状态码) | 接收的请求处理完毕 |
| 3xx | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4xx | Clinet Error(客户端错误状态码) | 服务器无法完成请求 |
| 5xx | Server Error(服务器错误状态码) | 服务器完成请求出错 |
几个比较常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
3.3 http常见的响应报头属性
- Content-Type: 响应正文的数据类型(text/html等)
- Content-Length: 响应正文的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
4. 一个非常简单的http协议服务端
设计思路:我们日常使用的浏览器就是http协议的客户端,我们现在只需要实现服务端即可。既然要实现支持http协议的服务端,那么只需要按照tcp协议的方式构建传输层,然后按照http协议的约定来解析客户端发过来的消息,然后按照约定的响应格式发送数据给客户端
那么其实我们之前实现的socket编程的代码是可以用上的
enum
{USAGE_ERR = 1,SOCKET_ERR,BIND_ERR,LISTEN_ERR
};static const uint16_t gport = 8080;
static const int gbacklog = 5;typedef std::function<bool(const HttpRequest &req, HttpResponse &resp)> func_t;class HttpServer
{public:HttpServer(func_t func, const uint16_t &port = gport) : _port(port), _func(func){}void initServer(){// 1. 创建socket文件套接字对象_listensock = socket(AF_INET, SOCK_STREAM, 0);if (_listensock == -1){exit(SOCKET_ERR);}// 2.bind自己的网络信息sockaddr_in local;local.sin_family = AF_INET;local.sin_port = htons(_port);local.sin_addr.s_addr = INADDR_ANY;int n = bind(_listensock, (struct sockaddr *)&local, sizeof local);if (n == -1){exit(BIND_ERR);}// 3. 设置socket为监听状态if (listen(_listensock, gbacklog) != 0) // listen 函数{exit(LISTEN_ERR);}}void start(){while (true){struct sockaddr_in peer;socklen_t len = sizeof peer;int sock = accept(_listensock, (struct sockaddr *)&peer, &len);if (sock < 0){continue;}pid_t id = fork();if (id == 0){close(_listensock);if (fork() > 0)exit(0);handleHttp(sock); // 这里就是需要服务端执行的内容了(传输层上层的内容)close(sock);exit(0);}waitpid(id, nullptr, 0);close(sock);}}void handleHttp(int sock) // 服务端调用{// 1. 读到完整的http请求// 2. 反序列化// 3. 调用回调函数// 4. 将resp序列化// 5. sendchar buffer[4096];HttpRequest req;HttpResponse resp;ssize_t n = recv(sock, buffer, sizeof(buffer) - 1, 0);if(n > 0){buffer[n] = 0; // 添加一个字符串的结尾req.inbuffer = buffer;req.parse(); // 解析调用的内容_func(req, resp); // req -> respsend(sock, resp.outbuffer.c_str(), resp.outbuffer.size(), 0);}}~HttpServer() {}private:uint16_t _port;int _listensock;func_t _func;
};
在应用层我们就要设计我们服务端的”http协议了“
#pragma once#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>#include <string>
#include <sstream>
#include <iostream>#include "Util.hpp" // 这是工具类,提供了一些工具函数// 一些配置文件,这里写死(可以集成为一个配置文件,在服务器启动的时候加载)
const std::string sep = "\r\n"; // 分隔符
const std::string default_root = "./webroot"; // web根目录
const std::string home_page = "index.html"; // 首页
const std::string html_404 = "404.html"; // 找不到页面显示的页面class HttpRequest // http请求类
{
public:HttpRequest(){}~HttpRequest(){}bool parse() // 解析{// 1. 提取inbuffer中的第一行内容std::string line = Util::getOneline(inbuffer, sep);if (line.empty())return false;// 2. 解析内容 method url httpversionstd::stringstream ss(line);ss >> method >> url >> httpversion;// 3. 添加默认路径path += default_root;path += url;if(path[path.size() - 1] == '/') // 访问不合法资源path += home_page;// 4. 获取path对应的资源后缀(资源类型)auto pos = path.rfind(".");if(pos == std::string::npos)suffix = ".html";elsesuffix = path.substr(pos);// 5. 获取的资源大小struct stat st;int n = stat(path.c_str(), &st);if(n != 0) stat((default_root + html_404).c_str(), &st);size = st.st_size;return true;}public:std::string inbuffer; // 缓冲区,保存接收到的所有内容std::string method; // 浏览器请求方法std::string url; // 相对于default_root的资源路径std::string httpversion; // http协议版本std::string path; // 要访问的资源路径std::string suffix; // 资源后缀int size; // 资源大小
};class HttpResponse // http响应类
{
public:std::string outbuffer; // 这里保存所有序列化之后的结果,最终发送这个outbuffer中的数据即可
};
同时我们需要设计一下服务端的回调函数
/*httpServer.cc*/
#include <memory>
#include <iostream>#include "httpServer.hpp"using namespace Server;
using namespace std;static void Usage(std::string proc)
{std::cout << "\n\tUsage: " << proc << " port\n";
}
static std::string suffixToDesc(const std::string &suffix)
{std::string ct = "Content-Type: ";if (suffix == ".html")ct += "text/html";else if (suffix == "jpg")ct += "application/x-jpg";elsect += "text/html";ct += "\r\n";return ct;
}
bool Get(const HttpRequest &req, HttpResponse &resp)
{cout << "-------------------http start-----------------------" << endl;cout << req.inbuffer << endl;cout << "method: " << req.method << endl;cout << "url: " << req.url << endl;cout << "httpversion: " << req.httpversion << endl;cout << "path: " << req.path << endl;cout << "suffix: " << req.suffix << endl;cout << "size: " << req.size << "字节" << endl;cout << "-------------------http end-----------------------" << endl;std::string respline = "HTTP/1.1 200 OK\r\n"; // 返回的第一行std::string respheader = suffixToDesc(req.suffix); // 协议报头std::string respblank = "\r\n";std::string body;body.resize(req.size + 1);if (Util::readFile(req.path, const_cast<char *>(body.c_str()), req.size)){// 没有指定资源Util::readFile(html_404, const_cast<char *>(body.c_str()), req.size); // 这个页面一定存在}respheader += "Content-Length: ";respheader += std::to_string(body.size());respheader += "\r\n";resp.outbuffer += respline;resp.outbuffer += respheader;resp.outbuffer += respblank;cout << "-------------------http response start-----------------------" << endl;cout << resp.outbuffer << endl;cout << "-------------------http response end-----------------------" << endl;resp.outbuffer += body;return true;
}int main(int argc, char *argv[])
{if (argc != 2){Usage(argv[0]);exit(USAGE_ERR);}uint16_t port = atoi(argv[1]);std::unique_ptr<HttpServer> hsvr(new HttpServer(Get, port));hsvr->initServer();hsvr->start();return 0;
}
同时,这里附上工具类的函数
#pragma once#include <string>
#include <iostream>
#include <fstream>class Util
{
public:static std::string getOneline(std::string &buffer, const std::string &sep) // 获取一行内容{auto pos = buffer.find(sep);if(pos == std::string::npos) return "";std::string sub = buffer.substr(0, pos);buffer.erase(0, pos + sep.size());return sub;}static bool readFile(const std::string &resource, char* buffer, int size) // 二进制方式读取文件{std::ifstream in(resource, std::ios::binary);if(!in.is_open()) return false; // open file failin.read(buffer, size); // 从in中使用二进制读取的方式读取size个字节到buffer中in.close();return true;}
};
运行结果:
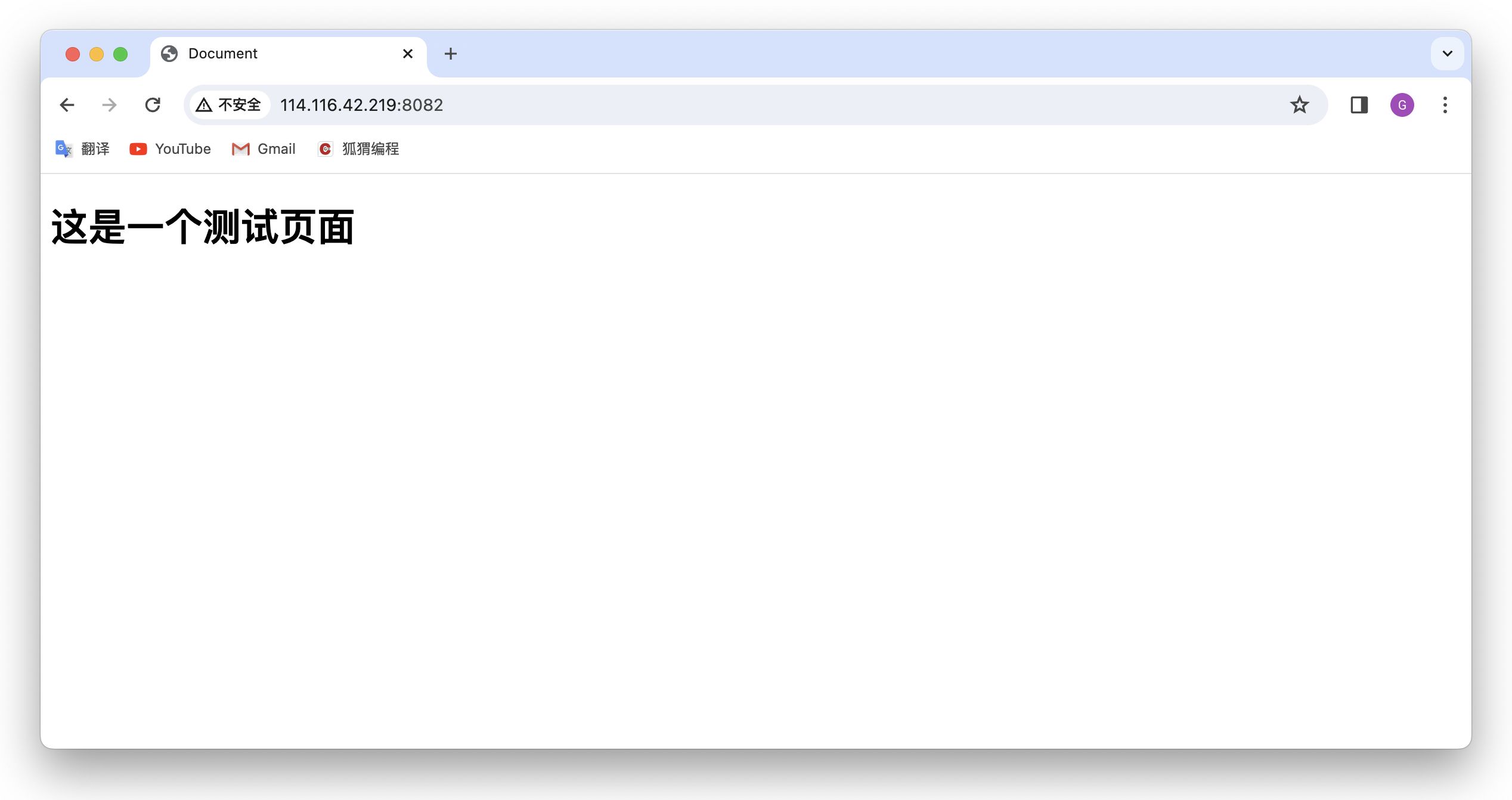
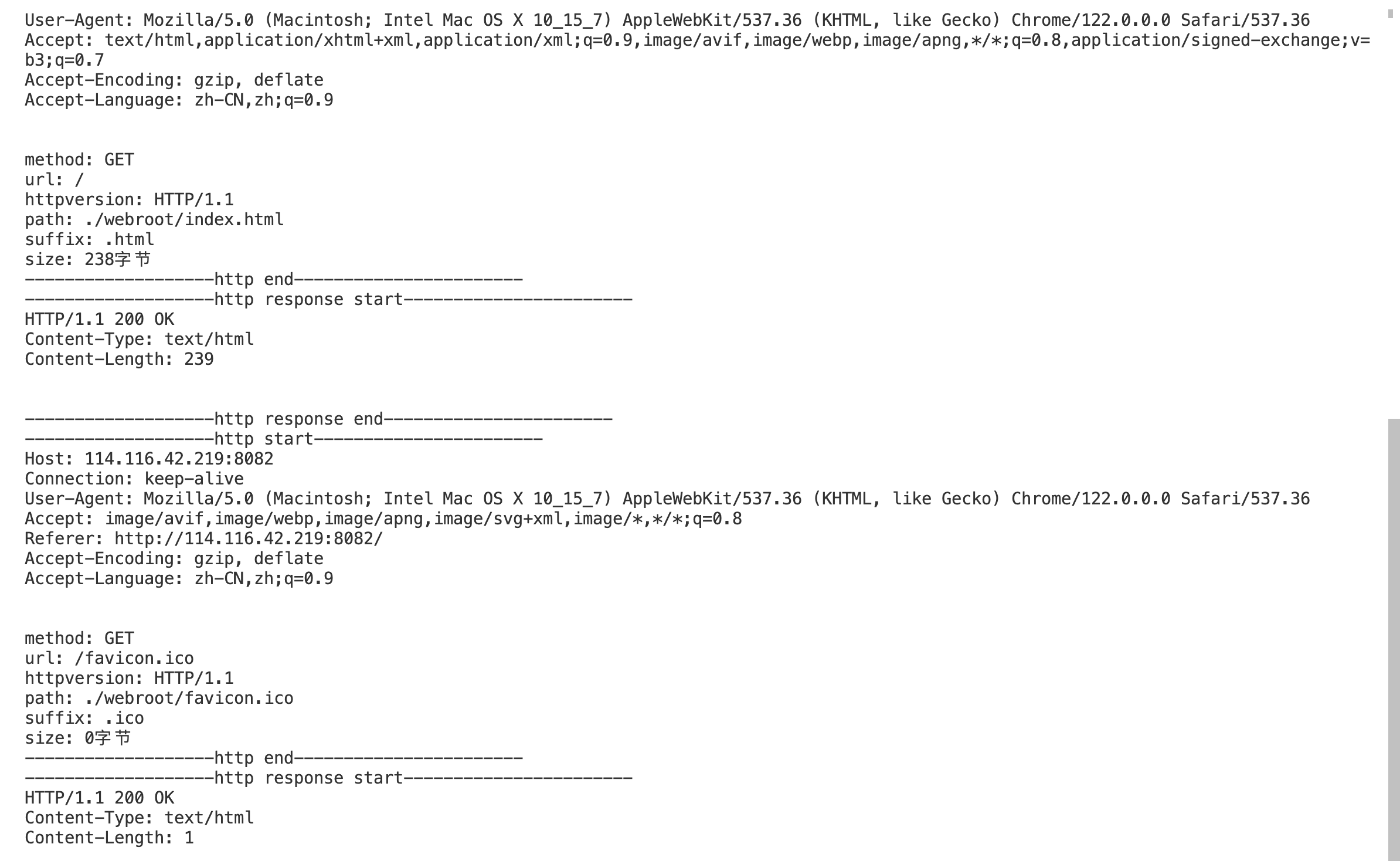
我们在服务端看到了响应结果,会发现客户端的一次点击在服务端会接收到多次请求,这是因为我们看到的网页是由多个资源组合而成的,所以要获取一个完整的网页效果浏览器就需要发起多次http请求,包括我们要请求的index.html网页和相关图标等
一些小细节
- http协议之所以在首行存在httpversion是因为http请求会交换通信双方B/S的协议版本,以明确能够接收/传输的资源类型和支持的协议内容
- 如果没有找到指定访问的资源,webServer会有默认的首页
5. http长链接
我们知道http请求是基于tcp协议的,tcp在通信的过程中需要发起并建立连接。一个网页中可能存在很多个元素,也就是说浏览器在将一个网页显示给用户的时候会经过多次http请求,所以就会面临着tcp频繁创建连接的问题
所以为了减少连接次数,需要客户端和服务器均支持长链接,建立一条连接,传输一份大的资源通过一条连接完成。
在http的请求报头中,可能会看到这样一行内容
Connection: keep-alive
表示支持长链接
6. http会话保持
严格意义上来说,会话保持并不是http天然所具备的,而是在后面使用的时候发现需要的
我们知道,http协议是无状态的,但是用户需要。
首先,用户查看新的网页是常规操作,如果网页发生跳转,那么新的网页是不知道已经登录的用户的身份的,也就需要用户重新进行身份验证。然后每次切换网页都重新输入账号密码着也太扯了,因此人们使用了一个办法:将用户输入的账号和密码保存起来,往后只要访问同一个网站,浏览器就会自动推送保存的信息,这个保存起来的东西就叫做cookie。cookie有内存级和文件级的,这里不做区分和了解。
举个最简单的例子:我们在登录CSDN的时候,只需要一次登录,以后再访问CSDN相关的网页,就会发现我们会自动登录,这就是因为浏览器保存了我们的账号信息,也就是当前网页的cookie信息.
但是本地的Cookie如果被不法分子拿到,那就危险了,所以信息的保存是在服务器上完成的,服务器会对每个用户创建一份独有的sessionid,并将其返回给浏览器,浏览器存到Cookie的其实是session id。但这样只能保证原始的账号密码不会被泄漏,黑客盗取了用户的session id后仍可以非法登录,只能靠服务端的安全策略保障安全,例如账号被异地登录了,服务端察觉后只要让session id失效即可,这样异地登录将会使用户重新验证账号密码或手机或人脸信息(尽可能确保是本人),一定程度上保障了信息的安全。
服务端可以通过在报头加上Set-Cookie: 属性将对应的cookie返回给客户端。往后,每次http请求都会自动携带曾经设置的所有Cookie,帮助服务器的鉴权行为————http会话保持
respHeader += "Set-Cookie: name=12345abcde; Max-Age=120\r\n";//设置Cookie响应报头,有效期2分钟
实际上在浏览器也是能看到对应的cookie的
本节完…





![TeXiFy IDEA 编译后文献引用为 “[?]“](https://img-blog.csdnimg.cn/direct/464f404a023f4f89a3a2929916f8e404.png)




