诸神缄默不语-个人CSDN博文目录
最近更新时间:2023.7.18
最早更新时间:2022.6.27
- 运算符
+-*/- " / “就表示 浮点数除法,返回浮点结果;” // "表示整数除法。
- 取余
%指数** - 等式:
===><>=<= - 不等于:
!=或<>或not - 交并:
and&VS.or| - 所有的二元数学操作符(+、-、*、/、//、%、**)都有与之对应的增强赋值操作符(+=、-=、*=、/=、//=、%=、**=)
- 在Python中,可以同时给多个变量赋值:<变量1>, …, <变量N> = <表达式1>, …, <表达式N>
- 长语句跨行可在第一行末尾加入
\\ inround(浮点数,保留小数点后的位数):返回数字舍入后的结果- Python中的主要序列类型:
- str(字符串):由字符构成的序列;
- list(列表):一个可以修改数据项的序列类型,使用也最灵活;
- tuple(元组):包含0个或多个数据项的不可变序列类型。元组生成后是固定的,其中任何数据项不能替换或删除。
序列类型有12个通用的操作符和函数:
| 操作符 | 描述 |
|---|---|
| x in s | 如果x是s的元素,返回True,否则返回False |
| x not in s | 如果x不是s的元素,返回True,否则返回False |
| s + t | 连接s和t |
| s*n或n*s | 将序列s复制n次 |
| s[i] | 索引,返回序列的第i个元素 |
| s[i: j] | 分片,返回包含序列s第i到j个元素的子序列(不包含第j个元素) |
| s[i: j: k] | 步骤分片,返回包含序列s第i到j个元素以j为步数的子序列 |
| len(s) | 序列s的元素个数(长度) |
| min(s) | 序列s中的最小元素 |
| max(s) | 序列s中的最大元素 |
| s.index(x) | 序列s中第一次出现元素x的位置 |
| s.count(x) | 序列s中出现x的总次数 |
- 字符串:在Python中,字符串是用两个双引号"或者单引号’括起来的一个或多个字符。
当字符串中有引号时,可以使用另外一类引号将字符串括起来,也可以使用转义字符\strip():移除字符串首尾空格endswith(chars:str):返回布尔值,字符串是否以chars作为结尾startswith(chars:str):返回布尔值,字符串是否以chars作为开头split():'管理部,人事部,销售部'.split(',')指定分隔符分隔文本,返回分割后的字符串数组replace(str1,str2):将字符串中所有str1替换成str2format():字符串格式化。比较简单的用法就是在原字符串中用花括号{}指代要用入参来替换的内容,如代码"The sum of 1 + 2 is {0}".format(1+2)返回'The sum of 1 + 2 is 3'。我自己一般都是直接用加号的,所以不用这个函数。(官方文档:https://docs.python.org/zh-cn/3/library/stdtypes.html#str.format)- 字符串直接用
+就可以连接多个字符串。还可以以这种形式将各种对象自动转换为字符串对象插入文本,如:- 字符串
mode='train':"%s_mode_dataset" % mode(用mode替换%s)
- 字符串
find(str):返回入参在原字符串中第一次出现的索引值。如果不包含入参,返回-1join(list):用原字符串来连接入参列表中的每一个元素,如'-'.join('我不想上学')的返回值是我-不-想-上-学upper()和lower():返回一个新字符串,其中原字符串的所有字母都被相应地转换为大写或小写。字符串中非字母字符保持不变。isupper()和islower():如果字符串至少有一个字母,并且所有字母都是大写或小写,方法就会相应地返回布尔值True。否则,该方法返回False。isalpha()返回True,如果字符串只包含字母,并且非空isalnum()返回True,如果字符串只包含字母和数字,并且非空;isdecimal()返回True,如果字符串只包含数字字符,并且非空;isspace()返回True,如果字符串只包含空格、制表符和换行,并且非空;istitle()返回True,如果字符串仅包含以大写字母开头、后面都是小写字母的单词。rjust()、ljust()和center()通过插入空格来对齐文本。 第一个参数是一个整数长度,用于对齐字符串。第二个可选参数将指定一个填充字符,取代空格字符strip()、rstrip()和lstrip()删除空白字符。有一个可选的字符串参数(不能用正则表达式),指定两边的哪些字符应该删除format()<模板字符串>.format(<逗号分隔的参数>)- 字符串前面加
r:防止字符转义1 - 字符串前面加
u:用Unicode格式编码字符串(一般用在中文字符串前,预防源码储存格式导致乱码问题) - 字符串前面加
b:转换为bytes对象 - 字符串前面加
f:格式化
举例:
输出:for i in range(3):print(f"i={i}, i+1={i+1}")i=0, i+1=1 i=1, i+1=2 i=2, i+1=3 - 字符串和bytes对象之间的转换2:
str.encode('utf-8')
bytes.decode('utf-8') - 集合
set():初始化集合对象add(obj):增加单个元素update(series):将整个序列的所有元素一一增加进集合set.intersection(set1, set2 ... etc):返回入参集合的交集- {}会创造一个空字典
universitySet = set(['西南财大', '电子科技大学', '四川大学', '西南交通大学'])
universitySet = {'西南财大', '电子科技大学', '四川大学', '西南交通大学'} - 集合是无序组合,它没有索引和位置的概念,不能分片。
| 操作符 | 描述 |
|---|---|
| S – T 或 S.difference(T) | 返回一个新集合,包括在集合S中但不在集合T中的元素 |
| S-=T或S.difference_update(T) | 更新集合S,包括在集合S中但不在集合T中的元素 |
| S & T或S.intersection(T) | 返回一个新集合,包括同时在集合S和T中的元素 |
| S&=T或S.intersection_update(T) | 更新集合S,包括同时在集合S和T中的元素。 |
| S^T或s.symmetric_difference(T) | 返回一个新集合,包括集合S和T中元素,但不包括同时在其中的元素 |
| S=^T或s.symmetric_difference_update(T) | 更新集合S,包括集合S和T中元素,但不包括同时在其中的元素 |
| S|T或S.union(T) | 返回一个新集合,包括集合S和T中所有元素 |
| S=|T或S.update(T) | 更新集合S,包括集合S和T中所有元素 |
| S<=T或S.issubset(T) | 如果S与T相同或S是T的子集,返回True,否则返回False,可以用S<T判断S是否是T的真子集 |
| S>=T或S.issuperset(T) | 如果S与T相同或S是T的超集,返回True,否则返回False,可以用S>T判断S是否是T的真超集 |
| 函数或方法 | 描述 |
|---|---|
| S.add(x) | 如果数据项x不在集合S中,将x增加到s |
| S.clear() | 移除S中所有数据项 |
| S.copy() | 返回集合S的一个拷贝 |
| S.pop() | 随机返回集合S中的一个元素,如果S为空,产生KeyError异常 |
| S.discard(x) | 如果x在集合S中,移除该元素;如果x不在,不报错 |
| S.remove(x) | 如果x在集合S中,移除该元素;不在产生KeyError异常 |
| S.isdisjoint(T) | 如果集合S与T没有相同元素,返回True |
| len(S) | 返回集合S元素个数 |
| x in S | 如果x是S的元素,返回True,否则返回False |
| x not in S | 如果x不是S的元素,返回True,否则返回False |
- 列表3
count(obj):计算列表中某元素出现的次数append(obj):添加一个对象extend(obj):将另一个集合对象的所有元素逐一添加到列表中(可参考我之前撰写的博文:Python3 list不去重合并)remove(obj):删除一个对象index(obj):返回对象在列表中的索引(第一个对象)- 列表生成式,示例:
[i for i in range(10)] - 列表可以同时使用正向递增序号和反向递减序号,可以采用标准的比较操作符(<、<=、==、!=、>=、>)进行比较,列表的比较实际上是单个数据项的逐个比较。
- 列表也可以包含其他列表值。这些列表的列表中的值,可以通过多重下标来访问。
- 虽然下标从0 开始并向上增长,但也可以用负整数作为下标。整数值−1 指的是列表中的最后一个下标,−2 指的是列表中倒数第二个下标,以此类推。
- 切片
print(li[::-1]) #可以实现列表的反转,但不改变原列表
| 函数或方法 | 描述 |
|---|---|
| ls[i] = x | 替换列表ls第i数据项为x |
| ls[i: j] = lt | 用列表lt替换列表ls中第i到j项数据(不含第j项,下同) |
| ls[i: j: k] = lt | 用列表lt替换列表ls中第i到j以k为步的数据 |
| del ls[i: j] | 删除列表ls第i到j项数据,等价于ls[i: j]=[] |
| del ls[i: j: k] | 删除列表ls第i到j以k为步的数据 |
| ls += lt 或 ls.extend(lt) | 将列表lt元素增加到列表ls中 |
| ls *= n | 更新列表ls,其元素重复n次 |
| ls.append(x) | 在列表ls最后增加一个元素x |
| ls.clear() | 删除ls中所有元素 |
| ls.copy() | 生成一个新列表,复制ls中所有元素 |
| ls.insert(i, x) | 在列表ls第i位置增加元素x |
| ls.pop(i) | 将列表ls中第i项元素取出并删除该元素 |
| ls.remove(x) | 将列表中出现的第一个元素x删除 |
| ls.reverse(x) | 列表ls中元素反转 |
| ls.sort([reverse,key]) | 排序,reverse=True逆序排序 |
| ls.count(x) | 特定值在列表中出现的次数 |
-
元组
- 元组输入时用圆括号()。
- 如果元组中只有一个值,你可以在括号内该值的后面跟上一个逗号,表明这种情况。否则,Python 将认为,你只是在一个普通括号内输入了一个值。逗号告诉 Python,这是一个元组(不像其他编程语言,Python 接受列表或元组中最后表项后面跟的逗号)。
('西南财经大学',) - 使用()创造空元组
- 元组解包:可以一口气将元组赋值给多个变量
employeeInfo = ('10948', '刘利')
empNo, empName = employeeInfo - 可以将元组用作字典的键。
函数的参数是以元组形式传递的。
-
可以切片的基础数据对象:字符串,列表,元组
-
对迭代器iterator的操作:循环,输出下一个对象
next(iterator_object),转换为list对象(list(iterator_object),以便切片、取数等操作)
itertools库可参考我撰写的另一篇博文:itertools:Python3迭代库(持续更新ing…) -
字典
- 字典的键需要是不变的变量(可以是字符串,数字)
- 键:
keys()值:values()返回的是一个可迭代的对象,是一个视图对象,是只读的 - 增加一个键值对:直接使
dict_object[k]=v update(dict_object):将入参字典的键值对更新到原对象中- 字典生成式,示例:
{i:str(i) for i in range(10)} {<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}- 键可以是Python中任意的不可变类型:布尔型、整型、浮点型、元组、字符串,以及其他一些不可变的类型。字典本身是可变的,因此可以增加、删除或修改其中的键值对。字典的键必须保证互不相同。
- 字典是集合类型的延续,各个元素并没有顺序之分。
<值> = <字典变量>[<键>]- 添加键值对:直接添加
del employee['性别']
函数和方法 描述 <d>.keys()返回所有的键信息 <d>.values()返回所有的值信息 <d>.items()返回所有的键值对 <d>.get(<key>,<default>)键存在则返回相应值,否则返回默认值 <d>.pop(<key>,<default>)键存在则返回相应值,同时删除键值对,否则返回默认值 <d>.popitem()随机从字典中取出一个键值对,以元组(key, value)形式返回 <d>.clear()删除所有的键值对 del <d>[<key>]删除字典中某一个键值对 键/值/元组 in <d>setdault()<d1>.update(<d2>)pprint()或pformat() -
字典及其内置函数
-
排序
sorted():返回对象元素排序后的结果sort():对对象进行排序,返回None
-
filter(function,iterable)4:过滤- 示例:
list(filter(None,[None,'1111111','2222222'])):将列表中的空对象删掉,返回['1111111', '2222222']
- 示例:
-
同时迭代多个迭代器,按顺序同时输出多个迭代器里的元素:用
zip()5
举例:L1=['a','b','c','d','e','f','g','h'] L2=['A','B','C','D','E','F','G','H'] for (l1,l2) in zip(L1,L2):print(l1+' '+l2) -
if判断语句
if condition_1:statement_block_1 elif condition_2:statement_block_2 else:statement_block_3 -
while
break:结束循环continue:跳过本轮循环,直接进入下一轮循环
while 判断条件(condition):执行语句(statements)……while <expr>:<statement(s)> else:<additional_statement(s)> -
for循环语句:匿名变量可以用
_指代for <variable> in <sequence>:<statements> else:<statements> -
匿名函数:
<函数名> = lambda <参数列表>: <表达式> -
pass:在需要缩进的部分不写代码(一般都是测试时候不需要跑了),就写个pass顶一下位置。啥也不干 -
eval(str):执行字符串格式的表达式,并返回表达式结果 -
len(object):返回对象的长度 -
all() -
any() -
range(obj:int):返回以0为第一个元素、以obj-1为最后一个元素的迭代器
参数:开始值,末值,步长 -
enumerate(sequence,[start=0]):返回enumerate(枚举)对象,每个元素是一个元组(第一个元素是索引,第二个元素是sequence中对应的元素)6 -
iter(object):返回迭代器 -
map(function,iterable,...):对指定序列做映射,将结果返回
代码:list(map(lambda x: x ** 2, [1, 2, 3, 4, 5]))
输出:[1, 4, 9, 16, 25]
-
try-except语句(else,finally保留字)
except Exception as e -
异常:
raise Exception(message:str)Exception可以替换成其他Exception子类 -
Exception子类:
- ValueException
-
对象的所有属性:
object.__dict__(返回一个字典) -
id() -
del -
检查对象是否具有某一属性:
object.hasattr() -
打印:
print(打印内容)(会自动在末尾添加换行符)
如果打印后不想换行,可以使用参数end- 打印颜色:
"\033[31m本段文字将会显示成红色\033[0m\n"
更多使用方法可参考此篇博文:Python基础之控制台输出颜色_zxnode的博客-CSDN博客
- 打印颜色:
-
input():函数等待用户在键盘上输入一些文本,并按下回车键。这个函数的值为一个字符串,即用户输入的文本。输入参数为显示标识 -
with+上下文管理器:在使用的过程中,可以简单地认为with语句自动设置一种状态的环境,不需要显式控制开始和结束。如
with open('file.txt') as f:语句下包裹的代码运行之间自动打开文件流,运行后自动关闭;with torch.no_grad():语句下包裹的代码自动停止梯度计算。更多细节可参考7 -
装饰器:装饰函数,语法糖。如
@torch.no_grad()。简单实现可参考python3-装饰器_花_城的博客-CSDN博客_python3 装饰器 -
直接转换对象类型:如
- 数字类型转换函数:
float(x)int(x)str(x) list(x)str(x)
- 数字类型转换函数:
-
单行注释以
#开头,多行注释以'''开头和结尾 -
函数入参
位置参数,关键字参数,指定默认参数值
使用*收集位置参数,使用**收集关键字参数(星号本身不是参数)8
列表、元组前面加星号作用是将列表解开成两个独立的参数,传入函数,字典前面加两个星号,是将字典解开成独立的元素作为形参
举例:def add(a, b):return a+bdata = [4,3] print (add(*data)) #输出7 data = {'a' : 4, 'b' : 3} print (add(**data)) #输出7 print (add(*data)) #输出'ab' -
assert:断言
用于判断一个表达式,在表达式条件为 false 的时候触发异常。 -
global -
退出程序运行(仅在脚本运行时起效,在Jupyter Notebook中无效):
exit() -
输出对象类型:
type(obj) -
常见简单bug(比较复杂的有些我会专门写一篇博文)
- Python运行报SyntaxError: Non-UTF-8 code starting with ‘\xe5‘ in file的解决方法_syntaxerror: non-utf-8 code starting with ‘\xe5’ i_秋9的博客-CSDN博客:在Python文件开头加
# coding:utf-8
- Python运行报SyntaxError: Non-UTF-8 code starting with ‘\xe5‘ in file的解决方法_syntaxerror: non-utf-8 code starting with ‘\xe5’ i_秋9的博客-CSDN博客:在Python文件开头加
-
jupyter notebook
The Jupyter Notebook — Jupyter Notebook 6.5.4 documentation- jupyter notebook打开出现
Unreadable Notebook: coda_path\btc-master (16.2)\btc_close_2017.ipynb NotJSONError('Notebook does not appear to be JSON: \'\\ufeff{\\n "cells": [\\n {\\n "cell_typ...')问题,解决方法:用json格式化工具将ipynb文件进行格式化(如https://www.sojson.com/格式化后即可) - 如何设置Jupyter Notebook可远程访问:
设置 jupyter notebook 可远程访问 - Liu-Cheng Xu - CSDN博客
远程访问jupyter notebook - Echo/ - 博客园
服务器(CentOS7)配置Jupyter Notebook远程访问 - 水水 - CSDN博客
如何访问服务器的 Jupyter notebook - 知乎
云服务centos搭建jupyter notebook并通过外网访问_开发工具_taw19960426的博客-CSDN博客
- jupyter notebook打开出现
-
colab教程
教程:Google Colab免费GPU使用教程(一)
colab里面更换GPU/CPU会导致会话重启
https://colab.research.google.com/notebooks/welcome.ipynb
https://colab.research.google.com/notebooks/打开文件 -
简单功能实现
- 删除文本中的中文:
re.sub('[\u4e00-\u9fa5]', '', p1) - 删除文本中的标点符号:
simple_punctuation = '[’!"#$%&\'()*+,-/:;<=>?@[\\]^_`{|}~,。,]' line = re.sub(simple_punctuation, '', linee)- 删除文本中的数字:
re.sub("[0-9]", " ", line)
- 删除文本中的中文:
-
yaml库
- 一个从老版本转换为新版本时会遇到的问题:
TypeError: load() missing 1 required positional argument: 'Loader' in Google Colab

解决方案:将load()改为safe_load()9
- 一个从老版本转换为新版本时会遇到的问题:
-
tqdm库:进度条(官方GitHub项目:tqdm/tqdm: A Fast, Extensible Progress Bar for Python and CLI)
使用pip安装:pip install tqdm
简单用法:用from tqdm import tqdm引入,然后在for语句中加到迭代器上,如for i in tqdm(range(10)),然后在运行循环语句的过程中就会出现进度条:

常用入参:desc:字符串入参+:会出现在进度条前,示例:
-
random库:生成伪随机数
random — Generate pseudo-random numbers — Python 3.11.3 documentation- 设置随机数种子:
random.seed(a) - 生成分布的一个样本(数字)
random.random():生成[0.0, 1.0) 范围内的下一个随机浮点数random.uniform(a, b):生成二数之间的一个随机数。终点 b 可以包括或不包括在该范围内。gauss(mu=0.0, sigma=1.0):高斯分布/正态分布(Python 3.11之后两个属性才有默认值,在此之前都要)random.randrange(stop)
random.randrange(start, stop[, step])
从range(start, stop, step)中随机抽取一个元素,与choice(range(start, stop, step))等价,但并不真的创造一个range对象
- 原地打乱序列顺序:
random.shuffle(x)
- 设置随机数种子:
-
copy库:复制对象
copy库官方文档:copy — 浅层 (shallow) 和深层 (deep) 复制操作 — Python 3.11.0 文档copy.deepcopy(obj):返回对象深度复制后的对象,二者的操作互不影响
-
statistics库:数学统计函数
statistics库官方文档:statistics — Mathematical statistics functions — Python 3.11.1 documentation- 求平均值:
statistics.mean(obj)
- 求平均值:
-
日志
- logging库:日志记录
logging库官方文档:logging — Python 的日志记录工具 — Python 3.11.1 文档
日志常用指引 — Python 3.11.1 文档
使用示例(参考自NeurJudge项目):
logging.basicConfig(format = '%(asctime)s - %(levelname)s - %(name)s - %(message)s',datefmt = '%m/%d/%Y %H:%M:%S',level = logging.INFO) logger = logging.getLogger(__name__)#在每个epoch后: logger.info("Trianing Epoch: {}/{}".format(epoch+1, int(num_epoch)))输出:
12/09/2022 16:28:12 - INFO - __main__ - Trianing Epoch: 1/16
- wandb:可参考我撰写的博文wandb使用教程(持续更新ing…)
- TensorBoard
- TensorBoardX
- fitlog:可参考我撰写的博文fitlog使用教程(持续更新ing…)
- loguru(可参考这篇博文:loguru——Python优雅日志包_loguru.logger_GeekZW的博客-CSDN博客,我是在用textgen包10时知道这个包的)
- nb_log
我有十胜还挺好玩的,虽然我没用过
ydf0509/nb_log: pip install nb_log 各种日志handler和自动转化项目的任意print的效果。日志自动彩色炫酷,可点击控制台的日志自动精确跳转到pycharm的文件和行号。文件日志多进程切割安全。在10个最重要方面全方位超过loguru
- logging库:日志记录
-
warnings库
warnings库官方文档:warnings — Warning control — Python 3.11.2 documentationwarnings.filterwarnings('ignore')11:直接忽略警告
-
发邮件
首先搞个SMTP服务的邮箱账号来发邮件。以网易邮箱为例,开启POP3/SMTP/IMAP服务:

示例代码:import smtplib from email.mime.text import MIMEText from email.utils import formataddr my_sender='xxxxx@yeah.net' # 发件人邮箱账号 my_pass = 'xxxxx' # 发件人邮箱密码(当时申请smtp给的口令) my_user='xxxxx@xx.com' # 收件人邮箱账号 def mail():ret=Truemsg=MIMEText('填写邮件内容','plain','utf-8')msg['From']=formataddr(["发件人昵称",my_sender]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号msg['To']=formataddr(["收件人昵称",my_user]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号msg['Subject']="邮件主题-测试" # 邮件的主题,也可以说是标题server=smtplib.SMTP_SSL("smtp.yeah.net",587)server.login(my_sender, my_pass) # 括号中对应的是发件人邮箱账号、邮箱密码server.sendmail(my_sender,[my_user,],msg.as_string()) # 括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件server.quit()# 关闭连接return retret=mail() -
. 压缩与解压缩文件:zipfile库
zipfile — 使用ZIP存档 — Python 3.11.3 文档- 创建ZipFile对象:
zFile=zipfile.ZipFile(zip_file_path,"r") - 提取ZipFile下的所有文件(返回值是文件名),并解压到对应文件夹中:

- 关闭ZipFile对象:
zFile.close()
- 创建ZipFile对象:
-
文件流处理:os库
os — 多种操作系统接口 — Python 3.8.13 文档os.walk(文件夹路径):返回一个迭代器,每个元素是文件树中的一个文件夹(从本文件夹开始),是一个三元组,第一个元素是文件夹名称,第二个元素是文件夹下的文件夹名称,第三个元素是文件夹下的文件名称。12os.path.exists(path_name):检测文件或文件夹是否存在os.makedirs(path_name):创建文件夹,并创建文件夹所需的所有中间文件夹(举例来说,现在只有home文件夹,但使用这个方法可以直接创建到home/folder1/folder2)os.path.isfile(path_name):检测某个路径是否是一个文件(而不是一个文件夹)os.path.join(path1,path2)os.remove(file_path):删除文件os.removedirs(dir_path):删除空文件夹filename_with_extension = os.path.basename(path):得到文件名(包括扩展名)filename, extension = os.path.splitext(filename_with_extension):得到文件名(不含扩展名)和扩展名os.rename(old_file_name, new_file_name):重命名文件
-
shutil库:高阶文件操作
shutil — 高阶文件操作 — Python 3.11.3 文档
1.shutil.rmtree(path):删除文件夹及其下的所有内容 -
math库
- 开方:
math.sqrt(数字) - 检测数字是否是nan:
math.isnan(数字)
- 开方:
-
SymPy库:科学计算
官方文档:SymPy 1.11 documentation
参考博文:Python科学计算利器——SymPy库 - 简书 -
ordered-set库:有序集合
ordered-set · PyPI
安装方式:pip install ordered-set
使用:
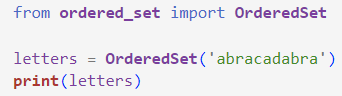
输出:OrderedSet(['a', 'b', 'r', 'c', 'd'])index()add()(都可以以列表为输入)- 和集合一样的:
|&-
-
collections库:特殊容器
官方文档:collections — Container datatypes — Python 3.11.3 documentation- Counter:字典,计数可哈希的对象。对象是key,计数是value(可以是任何整数)
https://docs.python.org/3/library/collections.html#collections.Counter
可以通过可迭代对象或mapping或Counter来进行初始化
KeyError
在Python3.7中有序
- Counter:字典,计数可哈希的对象。对象是key,计数是value(可以是任何整数)
-
cn2an库:在汉字与阿拉伯数字之间进行转换
cn2an官方GitHub项目:Ailln/cn2an: 📦 快速转化「中文数字」和「阿拉伯数字」~ (最新特性:分数,日期、温度等转化)- 将汉字转换为阿拉伯数字:
cn2an.cn2an('3.2万','smart')输出:32000- 第二个入参
'smart':可以接受中英文与阿拉伯数字混合的形式,但是不接受,和空格等符号
- 第二个入参
- 将汉字转换为阿拉伯数字:
-
webssh
-
pipx:包管理工具(可以在隔离环境下安装包)
pypa/pipx: Install and Run Python Applications in Isolated Environments
pipx · PyPI
Linux平台的安装方式:python3 -m pip install --user pipx python3 -m pipx ensurepath -
chardet:检测bytes或bytearray的编码方式
chardet · PyPI
chardet — chardet 5.0.0 documentationimport chardet print(chardet.detect(rawdata))如果rawdata是str格式的话,可能需要写成
rawdata.encode()13(这个似乎是Python版本的问题,我用Python 3.6.8时就需要使用这个) -
从文本中抽取URL(超文本链接/网址)
- urlextract包
pypi网址:urlextract · PyPI
官方文档:Welcome to urlextract’s documentation! — urlextract 1.8.0 documentation
安装方法:pip install urlextract
用法:
from urlextract import URLExtractextractor=URLExtract() urls=extractor.find_urls("Text with URLs. Let's have URL janlipovsky.cz as an example.")结果是一个这样的列表:
['janlipovsky.cz']
这个包的问题在于似乎对中文的处理很糟糕,所以事实上还是建议用下面这个正则表达式:
2. 使用(ChatGPT帮我写的)正则表达式:import re url_pattern=re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+') official_sites=re.findall(url_pattern,'ASPLOS会议的官网是https://www.asplos-conference.org/,2023年论文提交截止时间是2022年10月20日。')得到一个字符串列表,第一个元素就是网址
https://www.asplos-conference.org/ - urlextract包
-
从网址中提取域名:
from urllib.parse import urlparse
urlparse(an_url_string).netloc
- secrets — 生成管理密码的安全随机数 — Python 3.11.3 文档
secrets.token_hex([nbytes=None]):返回十六进制随机文本字符串。字符串有 nbytes 个随机字节,每个字节转换为两个十六进制数码。未提供 nbytes 或为 None 时,则使用合理的默认值。
>>> token_hex(16) 'f9bf78b9a18ce6d46a0cd2b0b86df9da' - 背景任务调度
- schedule包:轻量级的定时任务库
适用场景:有个代码我想要每天早上9点时候运行一遍
schedule包官方文档:schedule — schedule 1.2.0 documentation
安装方式:pip install schedule
示例代码:
import schedule import timedef job():# 这里是你的任务代码print("Task is running...")schedule.every().day.at("09:00").do(job)while True:schedule.run_pending()time.sleep(1)- APScheduler包
APScheduler包官方文档:Advanced Python Scheduler — APScheduler 3.9.1 documentation
示例代码:
from apscheduler.schedulers.background import BackgroundSchedulerdef task():# 这里是你要定时执行的任务print("Task is running...")app = Flask(__name__)if __name__ == "__main__":scheduler = BackgroundScheduler()scheduler.add_job(func=task, trigger="cron", hour=9)scheduler.start()cron触发器,可以让我们按照Cron风格的时间表达式来定时任务
scheduler.start()启动调度器
3. Celery - Distributed Task Queue — Celery 5.3.0 documentation
4. RQ: Simple job queues for Python - schedule包:轻量级的定时任务库
- base64
将Excel文件编码为base6414:
import base64data = open(excel_path, 'rb').read()
base64_encoded = base64.b64encode(data).decode('UTF-8')
- 将字符串限制在6000字节以内(这里主要是考虑多种语言的场景,英语反正一个字母就一个字节):
先将字符串编码为字节串,然后再进行长度检查和切片
def limit_byte_length(s, max_bytes):# 将字符串编码为字节串byte_str = s.encode('utf-8')# 如果字节串的长度超过最大字节长度,进行切片if len(byte_str) > max_bytes:byte_str = byte_str[:max_bytes]# 将字节串解码回字符串s = byte_str.decode('utf-8', 'ignore')return s# 测试
s = "这是一个测试字符串"
max_bytes = 6000
s = limit_byte_length(s, max_bytes)
如果一个字符的一部分字节被切片掉,解码时会产生错误。为了避免这个问题,我们在解码时使用了'ignore'错误处理选项,这会忽略所有无法解码的字节。
这个函数假设你的字符串是UTF-8编码的。如果你的字符串使用其他编码,你需要相应地修改编码和解码的部分。
本文撰写过程中参考的资料:
- Python3 lower()方法 | 菜鸟教程
- Python3 strip()方法 | 菜鸟教程
- Python3 错误和异常 | 菜鸟教程
- Python3 集合 | 菜鸟教程
- Python Set intersection() 方法 | 菜鸟教程
- Python打印对象的全部属性_来玩魔王的咚!的技术博客_51CTO博客
- Python3 List count()方法 | 菜鸟教程
- Python3 find()方法 | 菜鸟教程
- python3利用smtplib通过qq邮箱发送邮件_嗨学编程的博客-CSDN博客
- Python系列文章-Python字符串修饰符总结 | RongXiang
- Python中如何从列表中删除None值_去除列表中的none_word_mhg的博客-CSDN博客
- python 删除文件夹、删除非空文件夹_python删除文件夹_suibianshen2012的博客-CSDN博客
- Python中list列表、元组、字典前面加星号是什么意思?_元祖前面加*_努力改掉拖延症的小白的博客-CSDN博客
- Python list变量加星号,字典变量前面加星号 - 知乎
- 菜鸟教程-Python3函数
- python计算两个日期之间的天数、月数相差_python计算日期之间月份差_Charles.zhang的博客-CSDN博客
- python 字符串去除中文_python 去除中文_luoganttcc的博客-CSDN博客
python3 字符串前面加上’r’的作用_.''r_whatday的博客-CSDN博客 ↩︎
python3 中怎么把类似这样的’\xe5\xae\x9d\xe9\xb8\xa1\xe5\xb8\x82’转换成汉字输出_\xe6_Aidanmomo的博客-CSDN博客 ↩︎
python列表的一些常用方法以及函数 ↩︎
Python3 filter() 函数 | 菜鸟教程 ↩︎
Python3 zip() 函数 | 菜鸟教程 ↩︎
Python3 enumerate() 函数 | 菜鸟教程 ↩︎
浅析Python 3 中的with语句_haosen97的博客-CSDN博客_python3 with ↩︎
Python函数独立星号()分隔的命名关键字参数_python 函数传入参数以作为分割_LaoYuanPython的博客-CSDN博客 ↩︎
python - TypeError: load() missing 1 required positional argument: ‘Loader’ in Google Colab - Stack Overflow ↩︎
textgen教程(持续更新ing…) ↩︎
warnings.filterwarnings(“ignore”)代码解析_我是管小亮的博客-CSDN博客_filterwarnings ↩︎
有输出示例可以看一下:Python中os.walk()的使用方法 - 知乎 ↩︎
python - I use chardet to test encode , but i got error - Stack Overflow ↩︎
python - How to encode an Excel File to base64 - Stack Overflow ↩︎