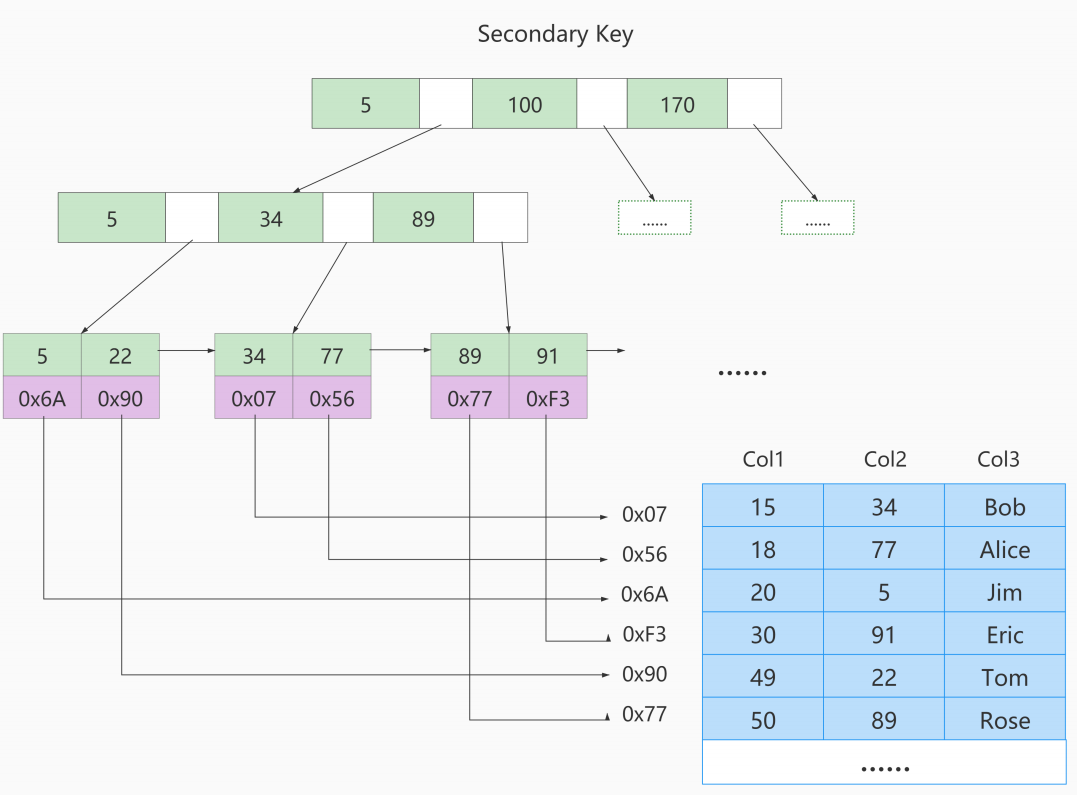
目前分库分表的中间件有三种设计思路,分别是:
- 采用分散式架构,适用于用Java开发的高性能轻量级OLTP应用程序,以Sharding-JDBC为代表。
- 采用中间层Proxy架构,提供了静态输入和所有语言支持,适用于OLAP应用程序和分片数据库的管理和操作情况,以Sharding-Proxy、Mycat 为代表。
- Database Mesh架构,适合k8s环境,以Sharding-Sidecar为代表。
分散式架构
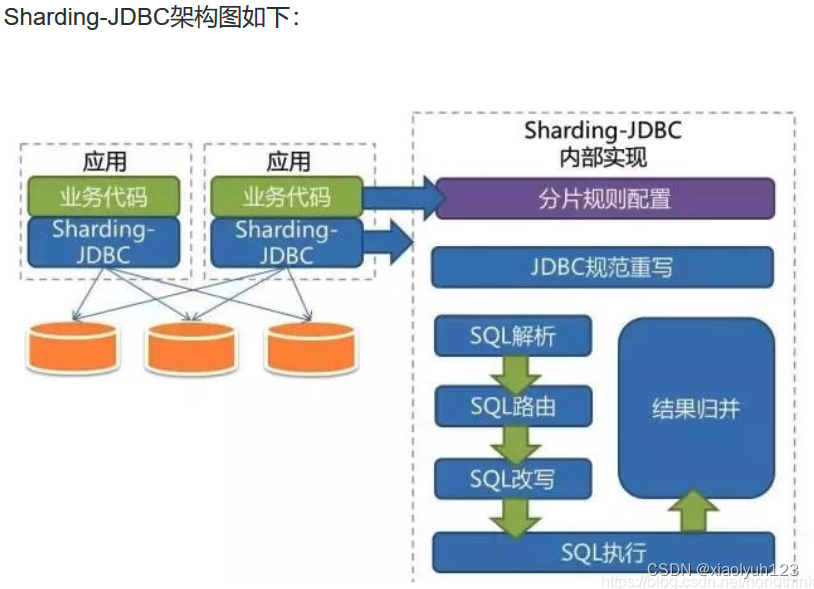
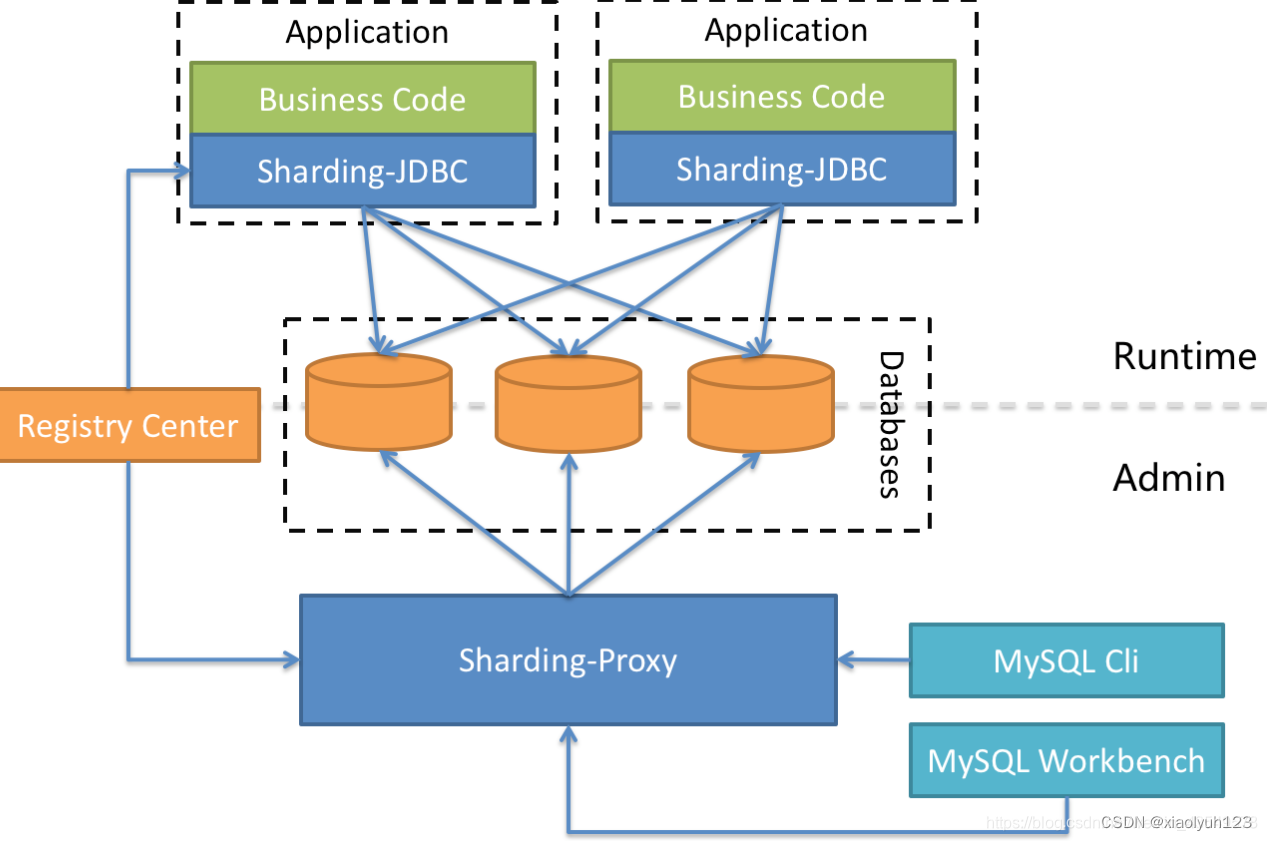
以Sharding-JDBC为例,Sharding-JDBC它定位为轻量级 Java框架,在 Java的 JDBC层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容JDBC和各种 ORM 框架。
优点:
1、轻量,范围更加容易界定,只是 JDBC 增强,不包括 HA、事务以及数据库元数据管理
2、开发的工作量较小,无需关注 nio,各个数据库协议等
3、运维无需改动,无需关注中间件本身的 HA
4、性能高,JDBC 直连数据库,无需二次转发
5、可支持各种基于 JDBC 协议的数据库,如:MySQL,Oralce,SQLServer
中间层Proxy架构
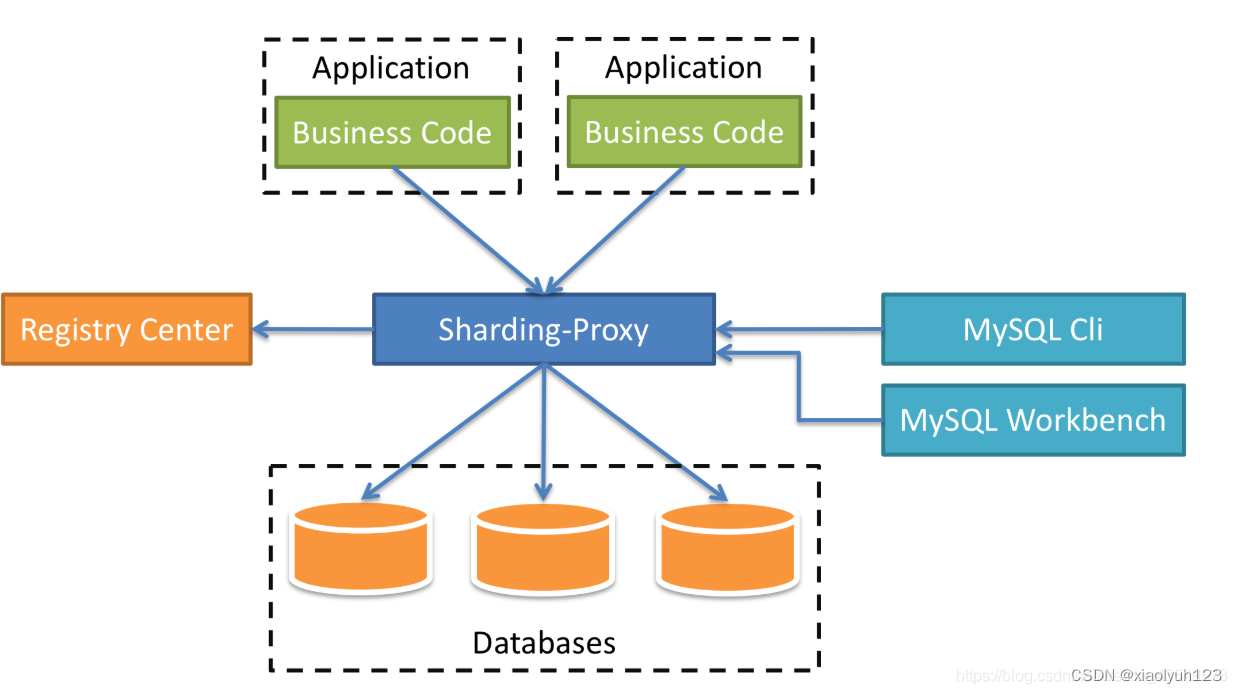
以Sharding-Proxy为例,中间层将自身定义为透明的数据库代理,它提供了一种数据库服务器,该服务器封装了数据库二进制协议以支持异构语言。对DBA友好的是,现在提供的MySQL版本可以使用与MySQL协议兼容的任何类型的终端(例如MySQL Command Client,MySQL Workbench等)。
优点:
1、 对应用程序完全透明,可以直接用作MySQL
2、适用于与MySQL和PostgreSQL协议兼容的任何类型的终端
2、更有效的管理数据库的连接
3、整合大数据思路,将 OLTP 和 OLAP 分离处理
4、夸语言支持比较好
Database Mesh架构
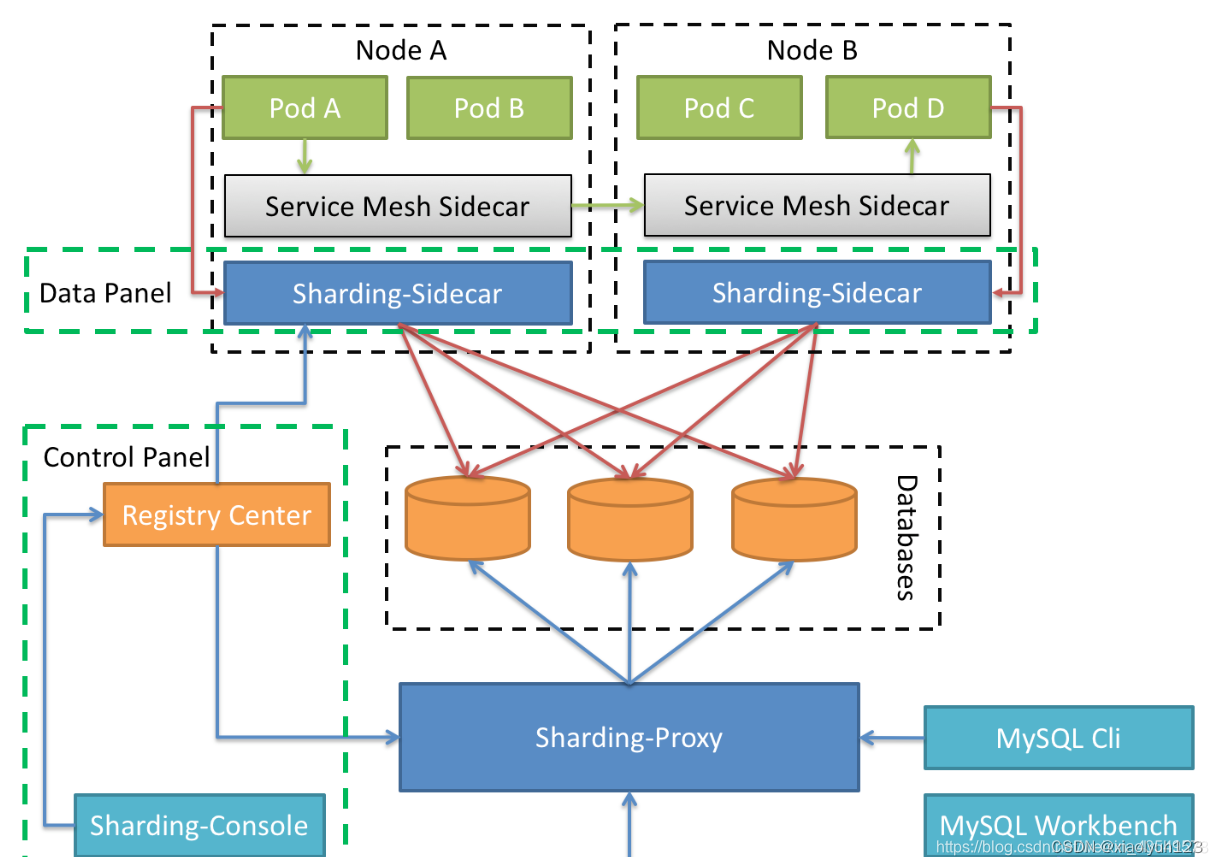
以Sharding-Sidecar为代表。Sharding-Sidecar(TODO)将自己定义为Kubernetes环境的云原生数据库代理,以sidecar的形式负责对数据库的所有访问。它提供了一个与数据库交互的网格层,我们称之为Database Mesh。
Database Mesh强调如何将分布式数据库访问应用程序与数据库连接。着重于交互,它有效地组织了杂乱的应用程序与数据库之间的交互。使用数据库网格访问数据库的应用程序和数据库将形成一个大型网格系统,只需将它们放在相应的正确位置即可。它们都由网格层控制。
混合架构
Sharding-JDBC采用分散式架构,适用于用Java开发的高性能轻量级OLTP应用程序;Sharding-Proxy提供了静态输入和所有语言支持,适用于OLAP应用程序和分片数据库的管理和操作情况。
开源框架对比
| – | Mycat | Sharding-JDBC | Sharding-Proxy | Sharding-Sidecar |
|---|---|---|---|---|
| 官方网站 | 官方网站 | 官方网站 | 官方网站 | 官方网站 |
| 源码地址 | gitcode | gitcode | gitcode | gitcode |
| 官方文档 | Mycat 权威指南 | 官方文档 | 官方文档 | 官方文档 |
| 开发语言 | Java | Java | Java | Java |
| 数据库 | MySQL Oracle SQL Server PostgreSQL DB2 MongoDB SequoiaDB | MySQL Oracle SQLServer PostgreSQL 任何遵循 SQL92 标准的数据库 | MySQL/PostgreSQL | MySQL/PostgreSQL |
| 连接数 | 低 | 高 | 低 | 高 |
| 应用语言 | 任意 | Java | 任意 | 任意 |
| 代码入侵 | 无 | 需要修改代码 | 无 | 无 |
| 性能 | 损耗略高 | 损耗低 | 损耗略高 | 损耗低 |
| 中心化 | 是 | 否 | 是 | 否 |
| 静态入口 | 有 | 无 | 有 | 无 |
| 管理控制台 | Mycat-web | Sharding-UI | Sharding-UI | Sharding-UI |
| 分库分表 | 单库多表/多库单表 | ✔️ | ✔️ | ✔️ |
| 多租户方案 | ✔️ | — | — | — |
| 读写分离 | ✔️ | ✔️ | ✔️ | ✔️ |
| 分片策略定制化 | ✔️ | ✔️ | ✔️ | ✔️ |
| 分布式主键 | ✔️ | ✔️ | ✔️ | ✔️ |
| 标准化事务接口 | ✔️ | ✔️ | ✔️ | ✔️ |
| XA强一致事务 | ✔️ | ✔️ | ✔️ | ✔️ |
| 柔性事务 | — | ✔️ | ✔️ | ✔️ |
| 配置动态化 | 开发中 | ✔️ | ✔️ | ✔️ |
| 编排治理 | 开发中 | ✔️ | ✔️ | ✔️ |
| 数据脱敏 | — | ✔️ | ✔️ | ✔️ |
| 可视化链路追踪 | — | ✔️ | ✔️ | ✔️ |
| 多节点操作 | 分页 去重 排序 分组 聚合 | 分页 去重 排序 分组 聚合 | 分页 去重 排序 分组 聚合 | 分页 去重 排序 分组 聚合 |
| 跨库关联 | 跨库 2 表 Join ER Join 基于 caltlet 的多表 Join | — | — | — |
| IP 白名单 | ✔️ | — | — | — |
| SQL 黑名单 | ✔️ | — | — | — |
| 存储过程 | ✔️ | — | — | — |
结论
综合目前已有资源、业务情况、前期改造投入成本和后期运营成本考虑,我建议选择ShardingSphere,前期只采用分散架构只使用Sharding-JDBC,后期如果有需要可以部署Sharding-Proxy根据业务情况使用混合架构。
参考
https://blog.csdn.net/weixin_43549578/article/details/106709343
https://shardingsphere.apache.org/document/current/cn/overview/
https://blog.csdn.net/vc33569/article/details/133178385